






点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
添加微信号:CVer111,小助手会拉你进群!
扫描下方二维码,加入CVer学术星球!可以获得最新顶会/顶刊上的论文idea和CV从入门到精通资料,及最前沿应用!发论文/搞科研/涨薪,强烈推荐!

引言
在文档理解任务中,目前的主流方案普遍使用端到端的多模态大语言模型。但是,此类方法对图片的输入分辨率有很高的要求,因此需要较强的视觉基座。这也成为了多模态大语言模型(MLLM)在文档理解任务中的瓶颈。文档理解作为text-rich的任务,实际发挥作用的信息大部分都来自于文字语义及其相对的布局信息。因此,利用成熟的OCR技术获得文字和布局(Layout)信息(即:文字坐标)并轻量级地扩展LLM,使其能够根据语义以及Layout信息来做预测。该方案也是解决文档理解的一条可行道路[1],即Layouts as “Lightweight Visual Information”。

论文地址:https://arxiv.org/pdf/2407.01976
相关工作
LayoutLM[2]是较早期将位置信息融入语言模型的文档理解方法。该方法同时需要借助于OCR工具输出的文本及对应位置信息。但是,其作为Encoder-only的模型,只能完成KIE任务(使用序列标注),在其他任务的泛化能力一般,并且在Free-form形式的问答任务上表现较差。
近期,DocLLM[3]首次提出在LLM的基础上加入布局信息的文档理解方案,将正则化后的数值型坐标作为布局信息,并引入解耦的空间注意力机制,促进文本与布局模态之间的交叉对齐。该方案经过有监督微调(SFT)能够在VQA任务上取得与OCR-free的MLLM相当的性能。此外,得益于融入的布局信息,该方案在KIE任务上提升明显,有效解决了生成式模型在KIE任务上的短板。但是,该方案采用的MLM(Masked Language Model)训练方式使得预训练阶段未能与SFT阶段的任务较好的对齐,因此其SFT后的模型性能也仅能与MLLM的Zero-shot性能相当。
此外,一些工作[4,5]尝试直接将坐标表达为文本Token的形式,即Coordinate-as-Tokens。实验证明,这种表达形式对于KIE任务有明显的提升,但此类方法存在如下弊端: (1)需要语言模型对于数值token有较好的理解,该能力一般要求模型大小在30B以上。(2)使用Coordinate-as-Tokens会显著增加输入序列的长度,导致更昂贵的训练和推理的成本,同时也需要较大的语言模型以保证长距离建模能力。
方法(LayTextLLM)
针对上述问题,我们提出LayTextLLM方案(A Bounding Box is Worth 1 Token: Interleaving Layout and Text in a Large Language Model for Multimodal Document Understanding)
模型设计
1. 模型依然采用Interleave的方式输入文本和布局信息,该方法能最大程度的利用LLM自回归的特性。
2. 与此前工作均不同的是,我们使用Embedding的方式嵌入布局信息,而非文本token的形式。该方法有效的规避了Coordinate-as-Tokens的长序列以及需借助大参数量模型的缺点。
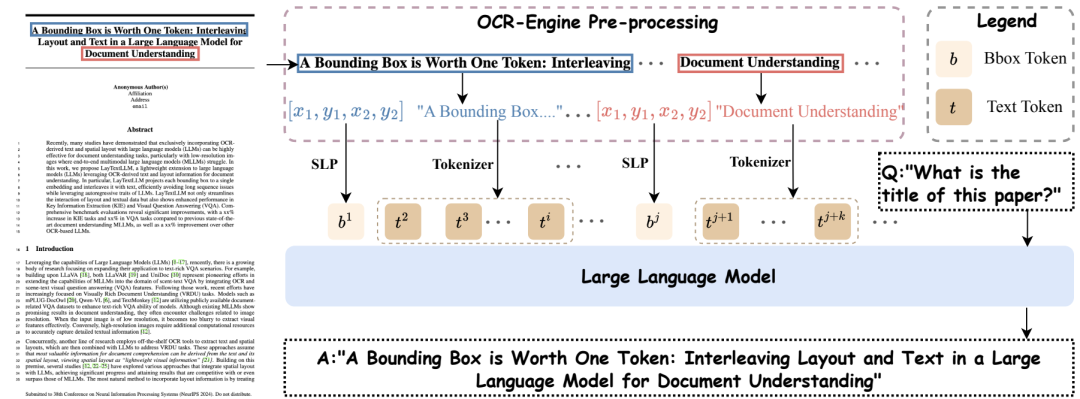
图1 LayTextLLM模型结构
具体的模型整体架构如上图。待处理的文档图像输入给OCR工具完成文本和对应坐标框(采用左上和右下的四维坐标)的识别。其中,文本信息借助于语言模型的Tokenizer处理为对应的文本Token;对于坐标框,我们提出SLP(Spatial Layout Projector),其简单地使用一个Linear Projector将4维的正则化坐标映射成高维(即LLM embedding size)的坐标表示,而后和文字token作交错的拼接并送入语言模型。本文所提出的方法既能高效地表示坐标并减少Token数目,同时利用了语言模型自回归特性。此外,在LLM部分的设计,我们参考了InternLM-Xcomposer2,使用P-LoRA的路由方式,新增参数量较少。
训练方式
1. 预训练(Layout-aware Next Token Prediction)
参考传统LLM的语言模型预训练,本文采用自回归方式预测整个输入的序列。不同于此前的预训练过程,提出的Layout-aware Next Token Prediction预训练方式当遇到需预测坐标占位符的Token时(下图中的"b"),不计算相应Token的损失。在预训练阶段,LLM参数被冻结,仅优化Layout Projector和新增的P-LoRA参数。得益于所提出的Self-supervised的预训练方式,预训练数据非常容易获得。
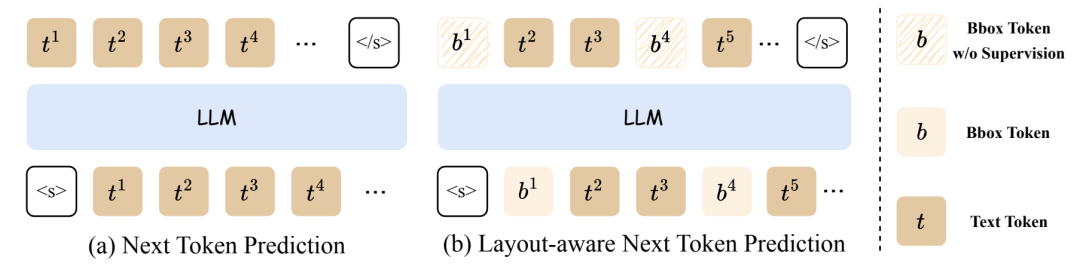
图2 LayTextLLM预训练方式比较
2. 微调(Shuffled-OCR Supervised Fine-tuning)
现有LLM使用的主流位置编码Rotatory Embedding往往倾向于使得在序列上越接近的Token,越容易获得更大的Attention Score。因此,在图3的例子中,如果提问"What is the value of the field Change?"(蓝色框),模型很容易识别出正确结果"1.30",因为它在序列中紧挨“Change”一词。然而,对于一个更具挑战性的问题,如"What is the value of the field Total(RM)? "(红色框),由于"Total(RM)"后有多个紧跟输入的数字文本Token,模型很难确定正确的答案。
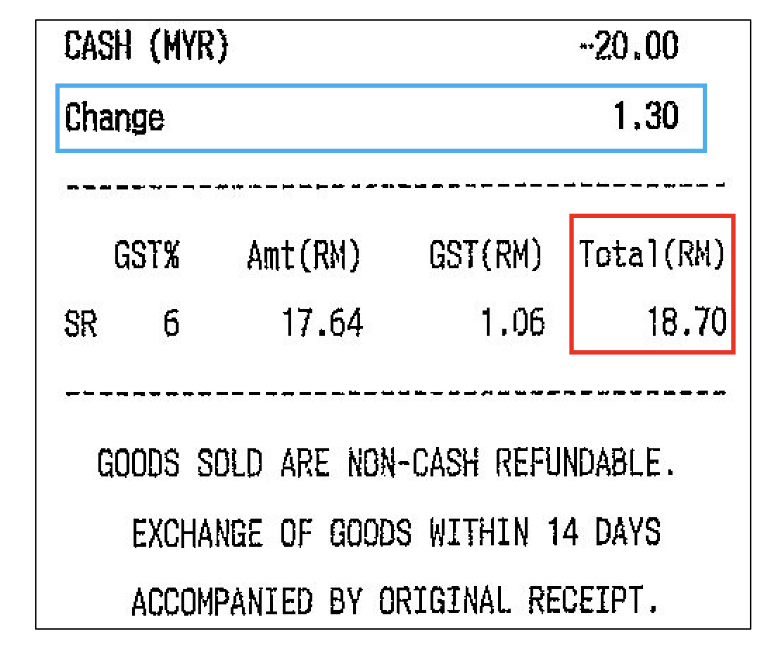
图3 单据布局样例
为了使模型更多的依靠坐标框的布局信息而不是Rotatory Embedding提供的位置信息来预测, 在训练过程中,我们随机打乱了20%样本的OCR输入顺序。其他训练设置与传统LLM的SFT方式基本一致:给定Prompt,自回归预测问题的答案序列,且该阶段全部参数参与训练。
实验结果
实现细节
实验主要基于英文,预训练数据使用DocBank全部数据以及IIT-CDIP Test Collection 1.0随机采样的部分数据,合计约1.5M documents。Zero-shot实验中,数据来自LayoutLLM中提供的Document Dense Description (DDD) and Layout-aware SFT数据,该数据均为GPT4生成的合成数据。SFT实验中,除DDD和Layout-aware SFT数据,我们还引入了下游测试数据对应的训练数据。下游测试数据包含VQA任务(DocVQA, InfoVQA, ChartQA, VisualMRC)和KIE任务(SROIE, CORD, FUNSD, POIE)。对于所有数据集,我们使用原数据集提供的word-level的OCR结果,以确保实验的公平性。
比较OCR-free方案
如图4所示(*代表对应数据集的训练数据被使用),对比OCR-free的MLLM方案,提出的方法在VQA和KIE的任务上均有大幅度提升。其中,VQA任务上,提出的方法甚至可以超过SOTA MLLM使用SFT数据后的性能(+5.1%);KIE任务上,提出的LayTextLLM大幅超过SOTA MLLM模型的Zero-shot性能(+27%)。此外,LayTextLLM经过SFT训练后,其性能大幅度提升, 相比于SOTA MLLM的SFT效果提升近24%。
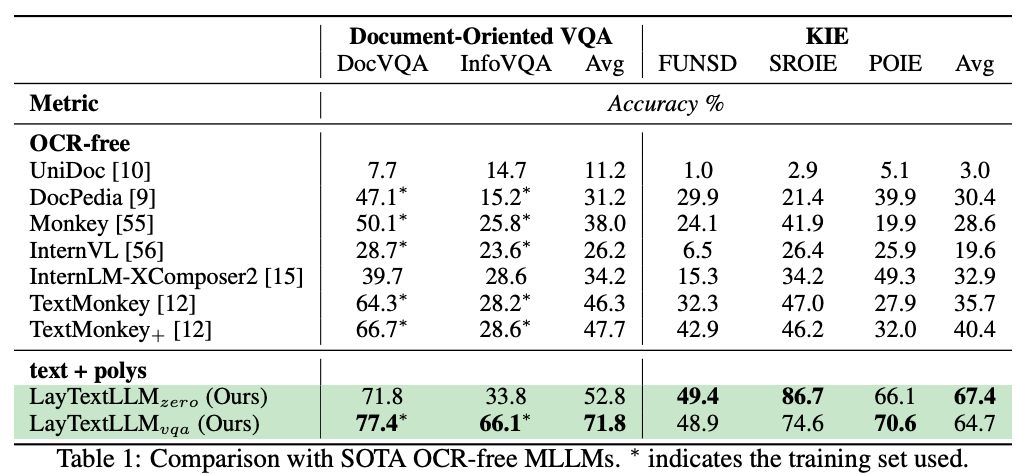
图4 与OCR-free方法的性能比较
比较OCR-based方案
我们还比较了其他OCR-based的方案,例如:DocLLM。如图5所示,在VQA和KIE两个任务上, LayTextLLM的Zero-shot效果均与DocLLM SFT后的模型效果相当。经过SFT后,LayTextLLM在两类数据集上性能均大幅度超过DocLLM。具体地,在KIE任务中,LayTextLLM 相较于DocLLM性能提升超过15%
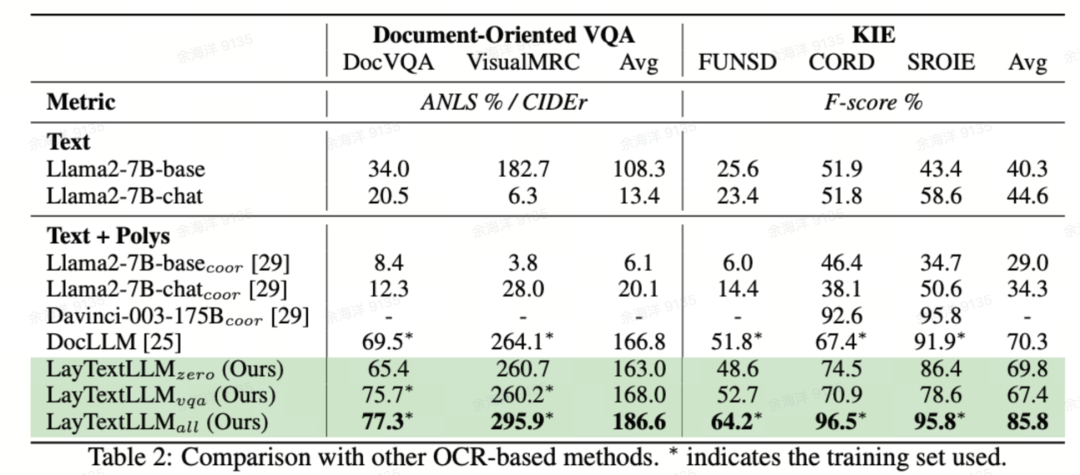
图5 与OCR-based方法的性能比较
输入长度比较
可以看到LayTextLLM的输入长度基本小于或者持平DocLLM,远小于coor-as-tokens的方案。图7能看出,在输入长度最小的情况下,LayTextLLM取得更高的精度。
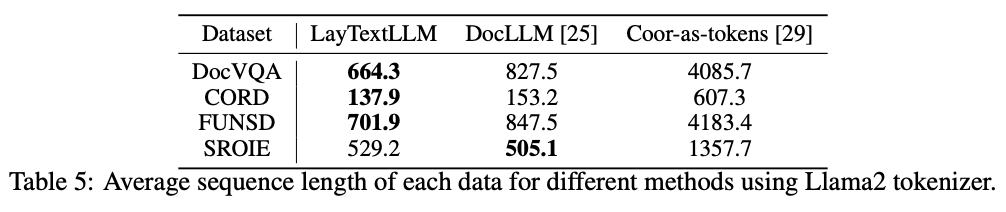 图6 与OCR-based方法的输入长度比较。
图6 与OCR-based方法的输入长度比较。
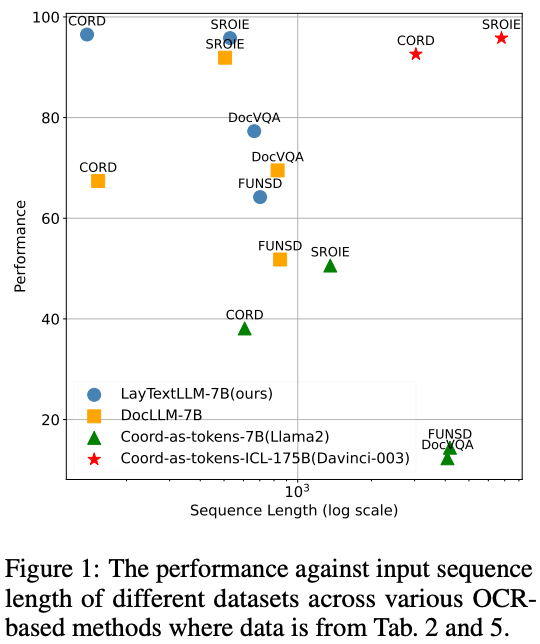
图7 各种方法输入长度against精度。
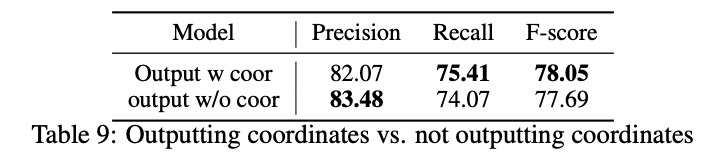
解码回坐标
我们在内部的KIE数据集上测试了LayTextLLM,要求模型以文本格式输出值文本及其对应的边界框,例如 "Oct 10[66,1,70,15]"。我们发现,要求模型输出坐标提高了精确度,如图8所示。我们任务要求输出坐标,强调了模型需要在输入中搜索对应信息,从而缓解了幻觉问题。此外,模型学会了组合和减去坐标。例如,如果输出文本来自两行OCR输入,模型会组合对应的OCR坐标。相反,如果输出是输入OCR文本的子串,模型将相应地输出调整后的坐标。
总结
文本提出 LayTextLLM 用于各类文档理解任务,例如Document-oriented VQA和KIE。在这些任务中,空间布局与文本数据均起至关重要的作用。本文通过引入Spatial Layout Projector,使模型对布局信息的感知更加精确。此外,我们设计了两个定制的训练任务(Layout-aware Next Token Prediction和Shuffled-OCR Supervised Fine-tuning),旨在提高对文档布局的理解。大量的实验结果也表明LayTextLLM 在文档理解任务中的有效性。
参考文献
[1] Wang, D., Raman, N., Sibue, M., Ma, Z., Babkin, P., Kaur, S., Pei, Y., Nourbakhsh, A. and Liu, X., 2023. DocLLM: A layout-aware generative language model for multimodal document understanding. arXiv preprint arXiv:2401.00908.
[2] Xu, Y., Li, M., Cui, L., Huang, S., Wei, F. and Zhou, M., 2020, August. Layoutlm: Pre-training of text and layout for document image understanding. In Proceedings of the 26th ACM SIGKDD international conference on knowledge discovery & data mining (pp. 1192-1200).
[3] Wang, D., Raman, N., Sibue, M., Ma, Z., Babkin, P., Kaur, S., Pei, Y., Nourbakhsh, A. and Liu, X., 2023. DocLLM: A layout-aware generative language model for multimodal document understanding. arXiv preprint arXiv:2401.00908.
[4] Perot, V., Kang, K., Luisier, F., Su, G., Sun, X., Boppana, R.S., Wang, Z., Mu, J., Zhang, H. and Hua, N., 2023. LMDX: Language Model-based Document Information Extraction and Localization. arXiv preprint arXiv:2309.10952.
[5] He, J., Wang, L., Hu, Y., Liu, N., Liu, H., Xu, X. and Shen, H.T., 2023. ICL-D3IE: In-context learning with diverse demonstrations updating for document information extraction. In Proceedings of the IEEE/CVF International Conference on Computer Vision (pp. 19485-19494).
何恺明在MIT授课的课件PPT下载
在CVer公众号后台回复:何恺明,即可下载本课程的所有566页课件PPT!赶紧学起来!
ECCV 2024 论文和代码下载
在CVer公众号后台回复:ECCV2024,即可下载ECCV 2024论文和代码开源的论文合集CVPR 2024 论文和代码下载
在CVer公众号后台回复:CVPR2024,即可下载CVPR 2024论文和代码开源的论文合集Mamba、多模态和扩散模型交流群成立
扫描下方二维码,或者添加微信号:CVer111,即可添加CVer小助手微信,便可申请加入CVer-Mamba、多模态学习或者扩散模型微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer、NeRF、3DGS、Mamba等。
一定要备注:研究方向+地点+学校/公司+昵称(如Mamba、多模态学习或者扩散模型+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群▲扫码或加微信号: CVer111,进交流群
CVer计算机视觉(知识星球)来了!想要了解最新最快最好的CV/DL/AI论文速递、优质实战项目、AI行业前沿、从入门到精通学习教程等资料,欢迎扫描下方二维码,加入CVer计算机视觉(知识星球),已汇集上万人!
▲扫码加入星球学习▲点击上方卡片,关注CVer公众号
整理不易,请赞和在看














 399
399

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









