







一次讲清楚什么是指针与内存地址对齐
什么是指针?
先看看什么是内存地址
首先,我们要搞清楚数据结构在计算机里面到底怎么存取?怎么描述它们。
任何数据结构(struct)以及组成数据结构的基本数据类型,一旦分配了内存空间,那么就会有两个部分来描述这块内存:内存的地址(红色部分,不占用实际空间,相当于门牌号,用于寻址)与内存的值(绿色部分,是实际的信息存储部分,占用内存空间,以byte为单位)。就像下面这张图:
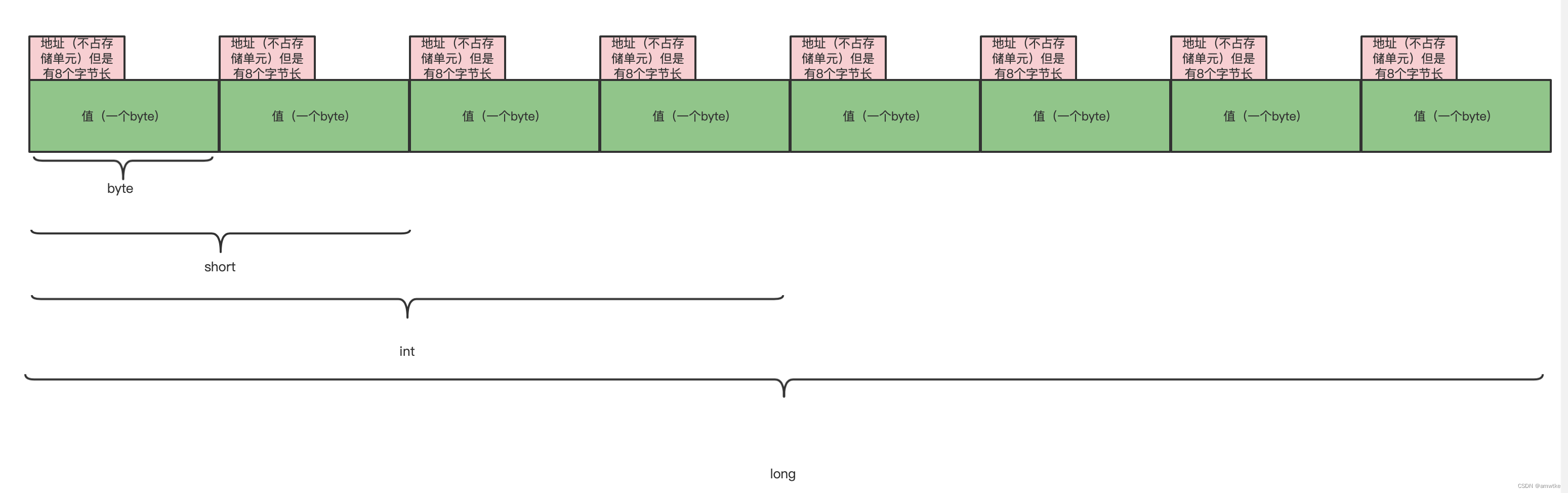
所以一块内存,或者一个符号(编程语言的符号其实就代表了一块内存,所以它们代表同一个意思)有两个重要的属性:
- 内存或者符号的地址;
- 内存或者符号的值。
这两个属性如同一个事物的两面,不可分割,形影不离。
有时候,如果对事情的本质进行深挖的话,你可能对一些基本概念有更深刻的理解。比如,到这里,如果你理解了内存或者编程语言的符号有两个基本的属性:地址与值,那么你就可以理解C/C++中的&与=操作符的含义。
&作用在一个符号上的底层含义就是——获取这个符号的两个重要属性之一——符号的地址。=作用在一个符号上的底层含义就是——获取这个符号的两个重要属性之一——符号的内存值。int a=1;含义就是获取符号a的内存值,并将内存值赋值成1。
可以推断出,从CPU的角度,或者编程语言底层来看,没有数据类型的概念,任何数据都是一块块连续的、长短不一的内存存储单元而已,就像上图所画。那么问题就变成了,怎么描述这块内存呢?
答案是:内存的起始地址+长度。比如下面这个结构:
struct test {
int a;
short b;
}
对于test这个结构,怎么描述它?
答案是:struct test是——符号a的内存地址+6个字节长度的数据块,如果要读取或者写入test某个部分(a或者b),编译器至少要编译两条指令:1、获取test也就是a符号的地址,2、根据类型定位偏移量就行了。这就是数据结构的本质了。
那么对数据结构成员变量的访问就很容易理解了:
test.a就可以被编译成符号a的地址+向高地址取4个字节的内存块。test.b就可以看成符号a的地址向高地址偏移4个字节+向高地址取2个字节的内存块。
是不是有点类似数学中的极坐标系的概念。而实际上系统确实是这么做的。
站在编译器的角度看看符号与变量
指针在C与C++中很难理解,但是又是重要的构成部分,没有了指针其实就发挥不出语言的光芒了。因为指针是很自然的事物,它是承接CPU取址与程序可读性的关键概念,理解了它就既能看穿机器的运行,又能写出合理的优雅的代码去描述业务。
要真正理解指针或者更普遍的意义来说,理解符号,就得将自己想象成编译器去读代码,这样一切都会变得理所当然的容易起来。
我们看到的程序都是由变量符号组成的,本质上符号代表一块内存,比如上面的结构体就有三个变量符号或者简称符号:test,a,b。每个符号其实都对应一块型如下图的内存块:
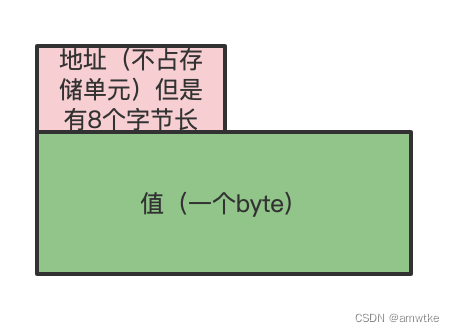
再来看看这个代码片段
typedef struct test {
int a;
short b;
} Test;
Test t;
t.a =1;
t.b =2;
Test* t_ptr = &t;
t_ptr->a = 3;
Test t:如果“我”是编译器,看到这行代码,我获得的信息是:t是一个符号,它有两个维度的信息:1、地址是&t;2、长度是sizeof(Test) = 6(不考虑对齐)。而且我会自动补全表达式为Test t = 0初始化t代表的这块内存。生成的底层代码应该做这些:1、给符号t分配一个内存地址,地址一共6个byte长度;2、将这6个byte的地址的值都填充为0。t.a = 1:语义是给符号a的值,赋值1。符号a的地址就是t的地址,符号a的长度4个字节,=的含义就是获取a的内存值,最后将int 1填充到这4个字节的内存中,完成赋值。t.b = 2:语义是给符号b的值,赋值2。符号b的地址是t的地址往高处偏移a的长度;同时符号b的值的长度是2个字节,=就是获取b的内存值,最后将short 2填充到这2个字节的内存中,完成赋值。- 再看看复杂点的
Test* t_ptr = &t;:t_ptr是个符号,它有地址与值两个属性。Test*修饰部分用来描述t_ptr的长度,这里的Test*说明t_ptr的值是一块内存的起始地址,长度为8字节(x64平台)。这就是按照编译器的角度解释指针:不管*号前面是什么类型(task_struct* ptr还是int* ptr还是char* ptr)被修饰的符号长度永远就是8个字节的地址。而t_ptr = &t就是将符号t_ptr的值赋值成符号t的地址——就是t_ptr这个符号的地址开始连续8个byte的内存填入符号t的地址值。 - 看了指针的本质,我们来看看对指针的操作指令:
t_ptr->a = 3。=的本质是获取符号a的值进行赋值;而找到a的地址比较复杂,先要拿到t_ptr符号的值,也就是&t,然后在t的地址基础根据a的偏移找到a的地址,这里偏移是0,a的地址等于t的地址。然后根据a的类型int将int 3赋值到这4个字节上就行了。
看看Linux内核中的例子——container_of宏
container_of宏是linux内核中常用的功能,用于实现一个逆面向对象取值的功能。面向对象的取值是:现获取对象,才能访问对象中的数据结构,也就是说,对象的成员变量只能通过对象来访问。而,逆面向对象指的是,通过成员变量来获取对象的实例。比如:
void wake_up_q(struct wake_q_head *head)
{
struct wake_q_node *node = head->first;
while (node != WAKE_Q_TAIL) {
struct task_struct *task;
task = container_of(node, struct task_struct, wake_q); //通过成员变量wake_q的地址获取task_struct对象的地址。
BUG_ON(!task);
/* Task can safely be re-inserted now: */
node = node->next;
task->wake_q.next = NULL;
/*
* wake_up_process() executes a full barrier, which pairs with
* the queueing in wake_q_add() so as not to miss wakeups.
*/
wake_up_process(task);
put_task_struct(task);
}
}
task = container_of(node, struct task_struct, wake_q); 就是container_of的典型用法。这个宏有三个参数:
node是指向成员变量wake_q的指针,传入成员变量的地址;struct task_struct是对象的类型,传入大结构体的类型信息;wake_q是node符号指向的wake_q_node类型的成员在task_struct结构中的符号名称。
那么container_of的功能是怎么实现的呢?起始就跟内存 = 其实地址 + 偏移长度这个公式密切相关。因为:
- 成员变量的定义在编译器底层就是通过
偏移来描述的,访问成员变量就是:首先获得类的首字节地址,然后加上成员变量相对首字节地址的偏移,来获得成员变量的首字节地址;最后根据成员变量的类型来确定成员变量的长度就可以了; - 所以,要向通过成员变量的地址获取
类的首字节地址,其实就是1.过程的逆运算。首先,获取成员变量相对类首字节地址的相对偏移,这在GCC编译的时候就确定了;然后,根据成员变量符号的地址 + 这个偏移 =类的首字节地址了。
我写了一段小程序来模拟这个过程:
#include <stdio.h>
#include <stdlib.h>
typedef struct test
{
int a;
long long b;
char c;
short d;
} My;
int main(int argc, char *argv[])
{
My my;
my.a = 1;
my.b = 2L;
my.c = 'a';
my.d = 4;
printf("size of my:%d\n", sizeof(My));
printf("address of my is:%x\n", &my);
//cc这个符号的值是一个地址,是my对象中c成员的地址。
char *cc = &my.c;
long delta = (long)(&(((My *)0))->c); // 将数字0强制转为My*类型,相当于定义了一个指向My结构的指针,指针变量的值是0。然后,取这个位置向下的第'c'个成员的地址,将地址转成long就是c这个成员的偏移。其实就是骗了gcc,gcc就是用的偏移来为数据类型赋值的,这是原理。
printf("delta:%d\n", delta);
printf("c's address is:%x\n", cc);
void *mycAddress = cc; //将cc这个符号的值,也就是my对象c成员的地址,赋值给mycAddress符号的值。
printf("之前value of d =%d\n", my.d);
my.d = 10;
int value_of_d = ((My *)(mycAddress - delta))->d; // 根据delta值,与mycAddress符号的值,计算获得my结构的地址。然后,将符号切换成my对象中的d成员。再将d符号的值,赋值给value_of_d符号的值。
printf("之后value of d =%d\n", value_of_d);
return 0;
}
关键的步骤是获取成员变量相对类的首字节偏移量:long delta = (long)(&(((My *)0))->c);。其实就是”欺骗“GCC,以一个0地址的My对象作为基准,然后c成员变量的地址就是相对0地址的相对偏移地址了。有了这个delta获取其他成员变量的地址就容易了,比如:int value_of_d = ((My *)(mycAddress - delta))->d;。
所以这进一步验证了,底层系统软件是没有所谓的类型信息的,他们读取与解释内存的方式就是这个公式:内存 = 内存的起始地址+长度 。
到这里我们可以推敲一下指针的本质了
接着上面的例子,我们已经分析了t_ptr的内存布局,它的值是一个地址。问题就来了,你想过没有,如果一个符号,它的值保存了一个地址,我对他能做什么操作?我们知道,如果t_ptr的值是int、long,我就能用CPU的算术模块对它们进行“加减乘除”,这样是有意义的,因为我在做代数运算。那么对一个地址,显然,做加减乘除运算是没有意义的。我们唯一能对地址做的有意义的操作就是找到这块地址,对这个地址对应的内存进行操作,这才是地址类型数据的意义。
因为对地址进行普通意义上的四则运算是没有代数意义的,所以,C语言为地址数据类型(指针)增加了两个操作符*与->。
*就是切换符号的含义,如*ptr = 3那么=获取的内存值,并不是ptr这个符号本身的值,而是ptr的值所对应的内存地址的内存值。相当于将符号ptr的含义进行了切换,切换到了新的目标内存地址;->也是切换符号含义,但是不是切换到ptr指向的大内存块,而是里面的小内存块,可以理解成切换成对成员变量的符号的内存访问。
看看Linux中一些指针操作——二重指针
看个Linux内核中的例子,这是mcs spinlock的加锁操作
static inline
void mcs_spin_lock(struct mcs_spinlock **lock, struct mcs_spinlock *node)
{
struct mcs_spinlock *prev;
/* Init node */
node->locked = 0;
node->next = NULL;
prev = xchg(lock, node); //相当于把mcslock.next = node;同时返回*lock修改之前的值。
if (likely(prev == NULL)) { //原来*lock指向NULL。也就是现在链表还没形成,没有竞争。
return;
} // 如果有值说明有竞争,要排队。所以直接插入最后就行了。prev就是最后一个元素。
WRITE_ONCE(prev->next, node);
/*这里是个spin loop。在percpu自身的lock上面自旋,等待变成1,获取锁。
*/
/* Wait until the lock holder passes the lock down. */
arch_mcs_spin_lock_contended(&node->locked);
}
-
struct mcs_spinlock **lock是什么呢?书上会说指向指针的指针,这么说没错,但是对很多刚刚接触到C语言的人来说其实很难理解,很难对应到实际内存中的样子。不如,一步步拆解这条语句的含义。- 首先,我们要先找到符号,符号才是内存,才有意义。显然这里描述的符号是
lock; - 符号就是一块内存,是内存就有
地址与值,那么lock的值的信息可以从它的类型来推断出来,struct mcs_spinlock **就是类型信息,它的主要作用是描述lock的值有多长。那么有多长呢?看到*就不用看struct mcs_spinlock了,就是一个地址,另一个符号的地址,8个字节长,保存在了lock符号的值里面。 struct mcs_spinlock **的含义是什么呢?这是一个递归定义。根据前面对*运算符的解释,struct mcs_spinlock **可以展开成这种形式(struct mcs_spinlock *)(*lock)。*lock的含义是切换符号,假设切换成了(struct mcs_spinlock *)_lock符号,_lock符号的地址是lock的值,而_lock的值又是一个地址,一个struct mcs_spinlock *类型的地址。如下图:
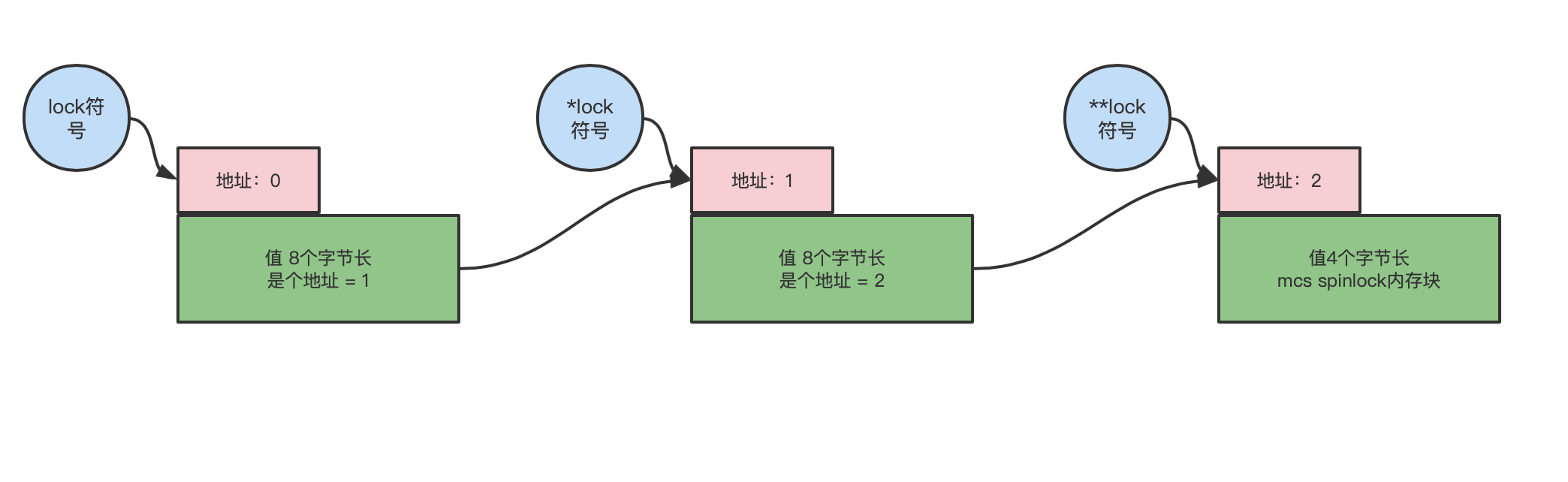
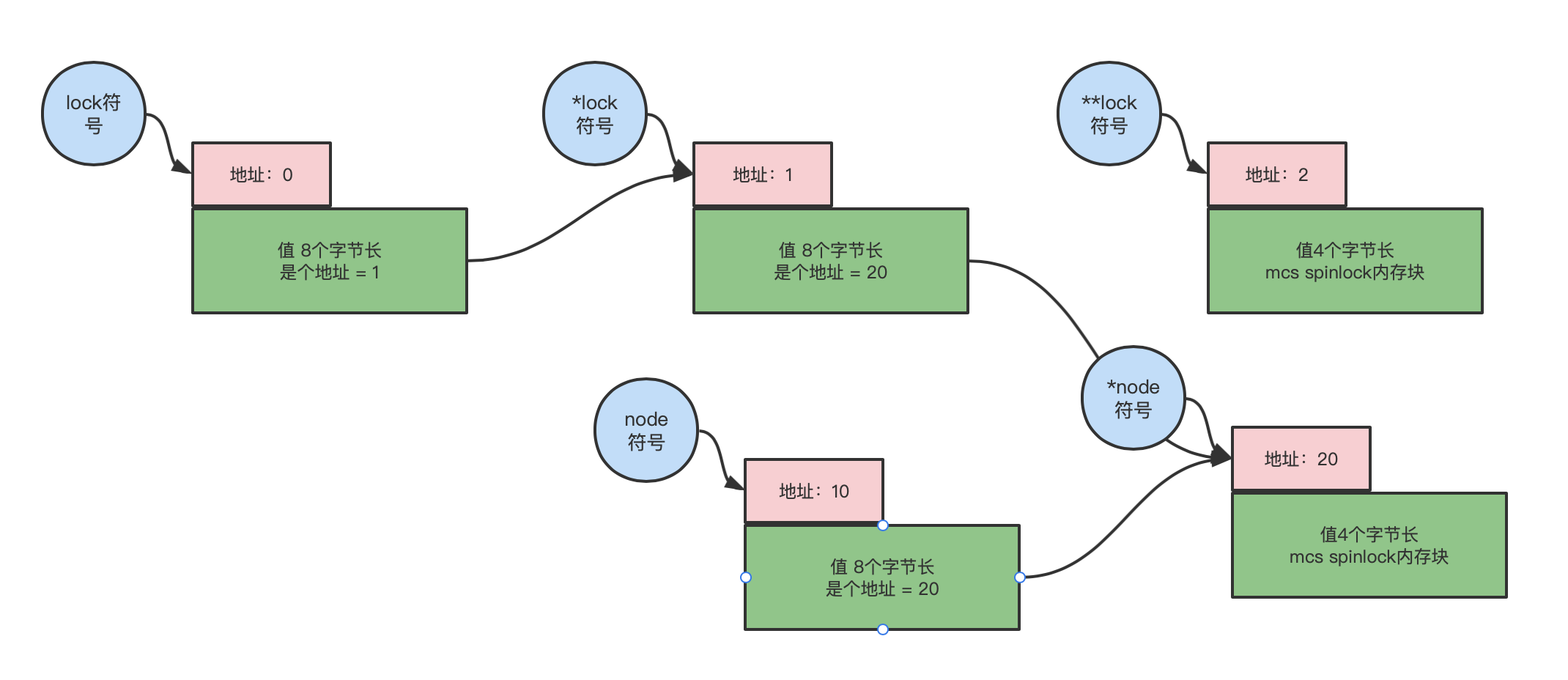
- 而
*lock = node;的含义就是:将符号node的值赋给*lock符号的值。
所以,不管多少个
*都可以递归化简了。比如:
T *** t = &node;这个表达式:因为,加*就是增加一层符号转换; 所以,我们用_t符号表示*t;用__t符号表示*_t; 最后,T*** t = T** _t = T* __t; 增加的两个符号_t (=*t)与__t(=*_t=**t) 都是真实存在的内存块。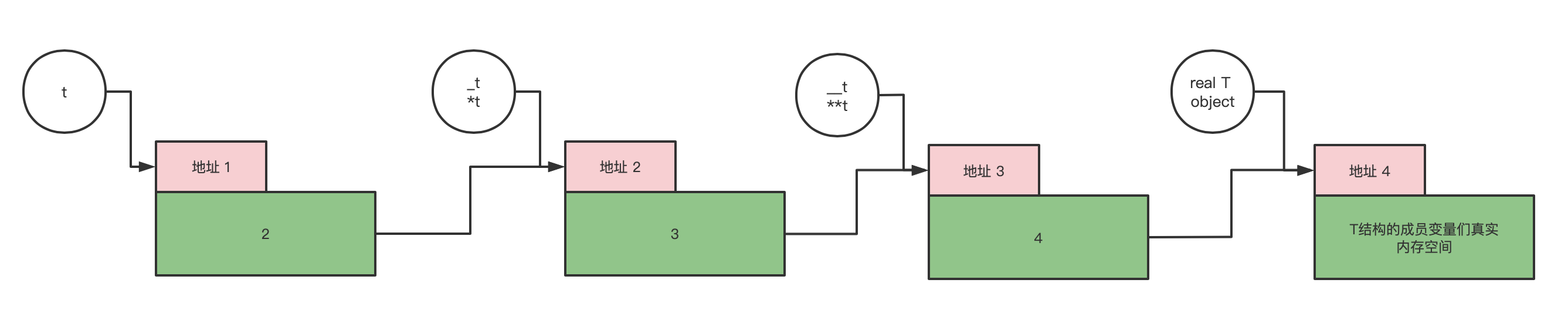
看看Linux中一些指针操作——链表操作
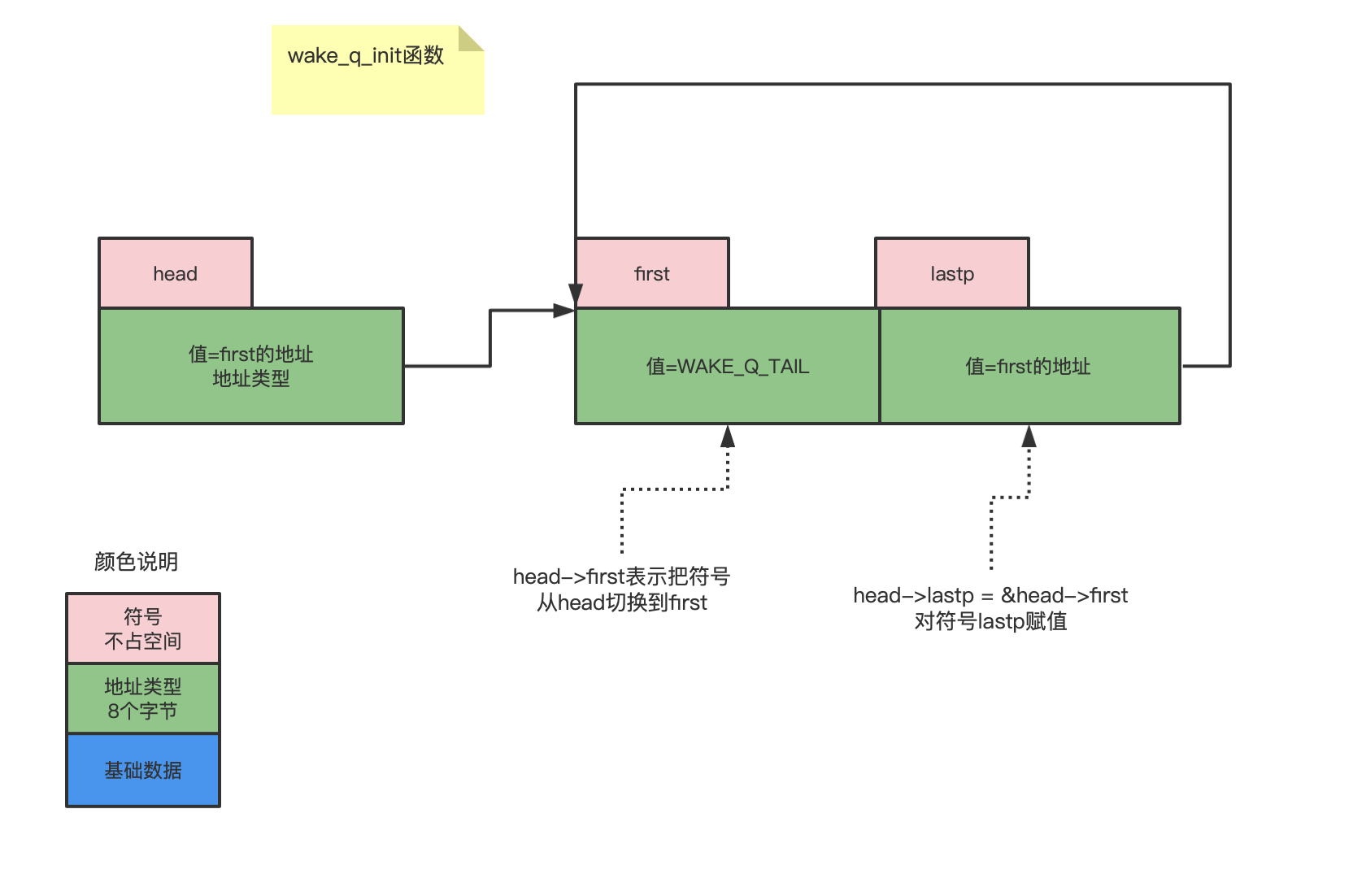
//链表头指针 struct wake_q_head { struct wake_q_node *first; struct wake_q_node **lastp; }; struct wake_q_node { struct wake_q_node *next; };//初始化链表头 static inline void wake_q_init(struct wake_q_head *head) { head->first = WAKE_Q_TAIL; // #define WAKE_Q_TAIL ((struct wake_q_node *) 0x01) head->lastp = &head->first; }先看看wake_q_init函数
- 首先,我们要先找到符号,符号才是内存,才有意义。显然这里描述的符号是
-
head->first的含义是:将被操作的对象从head符号转变到first符号(first的地址从head来) -
first = WAKE_Q_TAIL的含义就是获取first的内存值,然后把它设置成WAKE_Q_TAIL常数 -
head->lastp的含义是:将被操作符号从head切换到lastp -
&head->first的含义是:将被操作数从head切换到first然后用&取first符号的地址; -
最后
lastp = &head->first的含义是:将first符号的地址赋值给lastp符号的值。
再来看看wake_q_add函数
//添加新元素
static bool __wake_q_add(struct wake_q_head *head, struct task_struct *task)
{
struct wake_q_node *node = &task->wake_q;
/*
* Atomically grab the task, if ->wake_q is !nil already it means
* it's already queued (either by us or someone else) and will get the
* wakeup due to that.
*
* In order to ensure that a pending wakeup will observe our pending
* state, even in the failed case, an explicit smp_mb() must be used.
*/
smp_mb__before_atomic();
if (unlikely(cmpxchg_relaxed(&node->next, NULL, WAKE_Q_TAIL)))
return false;
/*
* The head is context local, there can be no concurrency.
*/
*head->lastp = node;
head->lastp = &node->next;
return true;
}
struct wake_q_node *node:在栈上分配一块内存,用符号node表示,node的值是一个8字节的地址。task->wake_q:将操作数从task符号切换成task里的wake_q&task->wake_q:获取wake_q符号的地址值;node = &task->wake_q:将node符号的值更新成wake_q符号的地址。*head->lastp = node;:将操作符号从head切换成lastp*head->lastp:就相当于*lastp,将操作符号切换成lastp符号的值所指向的内存块*head->lastp = node;(有两次符号切换):就等价于将lastp符号的值所指向的内存块的值,赋值为,node符号的值。因为,lastp符号的值是first符号的地址(init时候赋值的),所以这条语句的含义就是将first符号的值修改成node符号的值;而node符号的值是wake_q符号的地址;所以这里的含义就是将first符号的值指向wake_q符号的地址。- 再来看看
head->lastp = &node->next;的含义: &node->next:先切换符号到next,然后获取next的地址;head->lastp:切换符号到lastp- 最后将
lastp符号的值更新为next符号的地址。
如下图描述:所以这个add函数就做了两件事:
- 将
first符号的值设置成wake_q符号的地址; - 将
lastp符号的值更新为wake_q->next符号的地址。
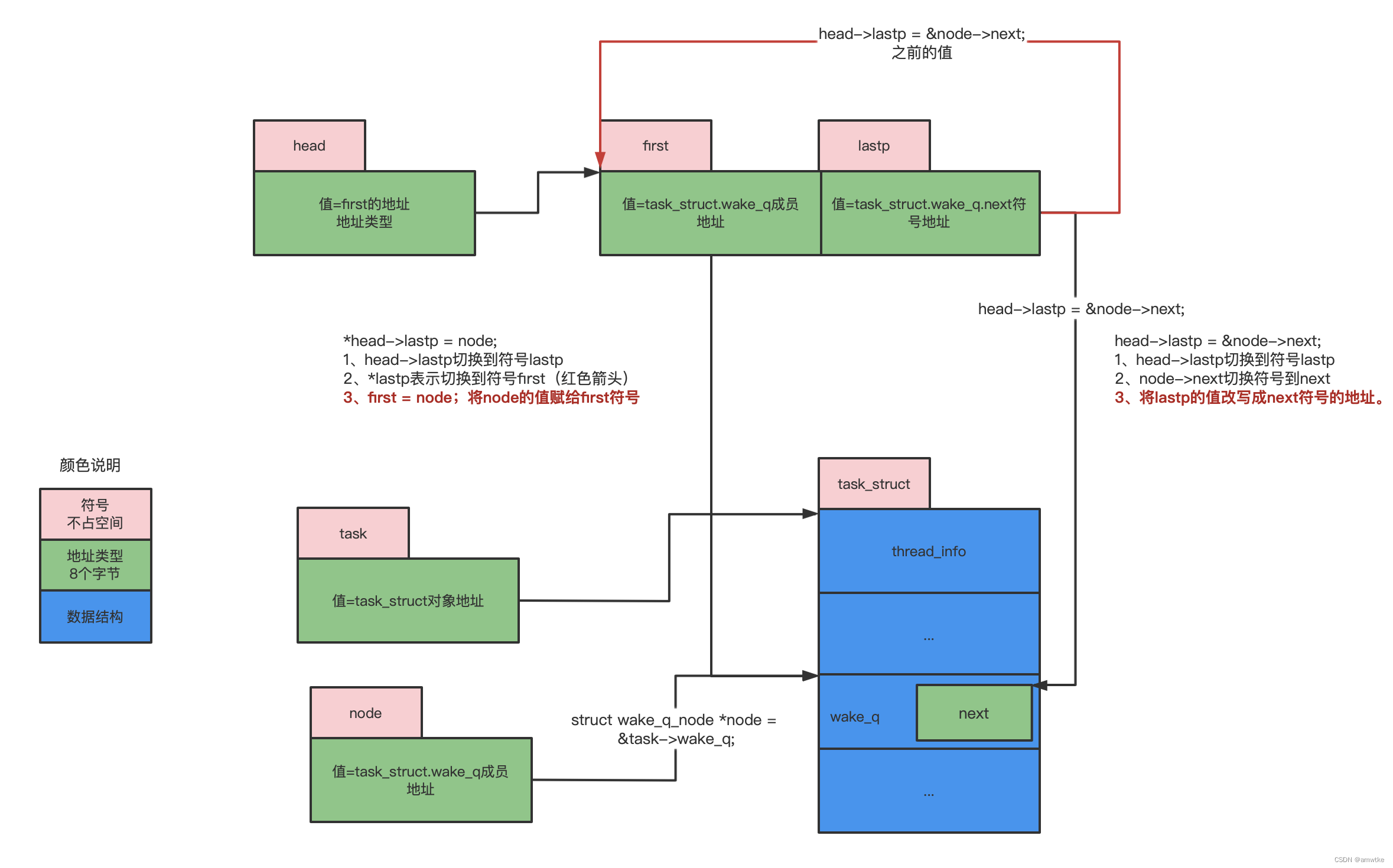
- first指向task_struct中的成员wake_q;指向队列的第一个元素;
- lastp指向task_struct的成员wake_q的成员next;next也是一个指针;
再添加一个元素:
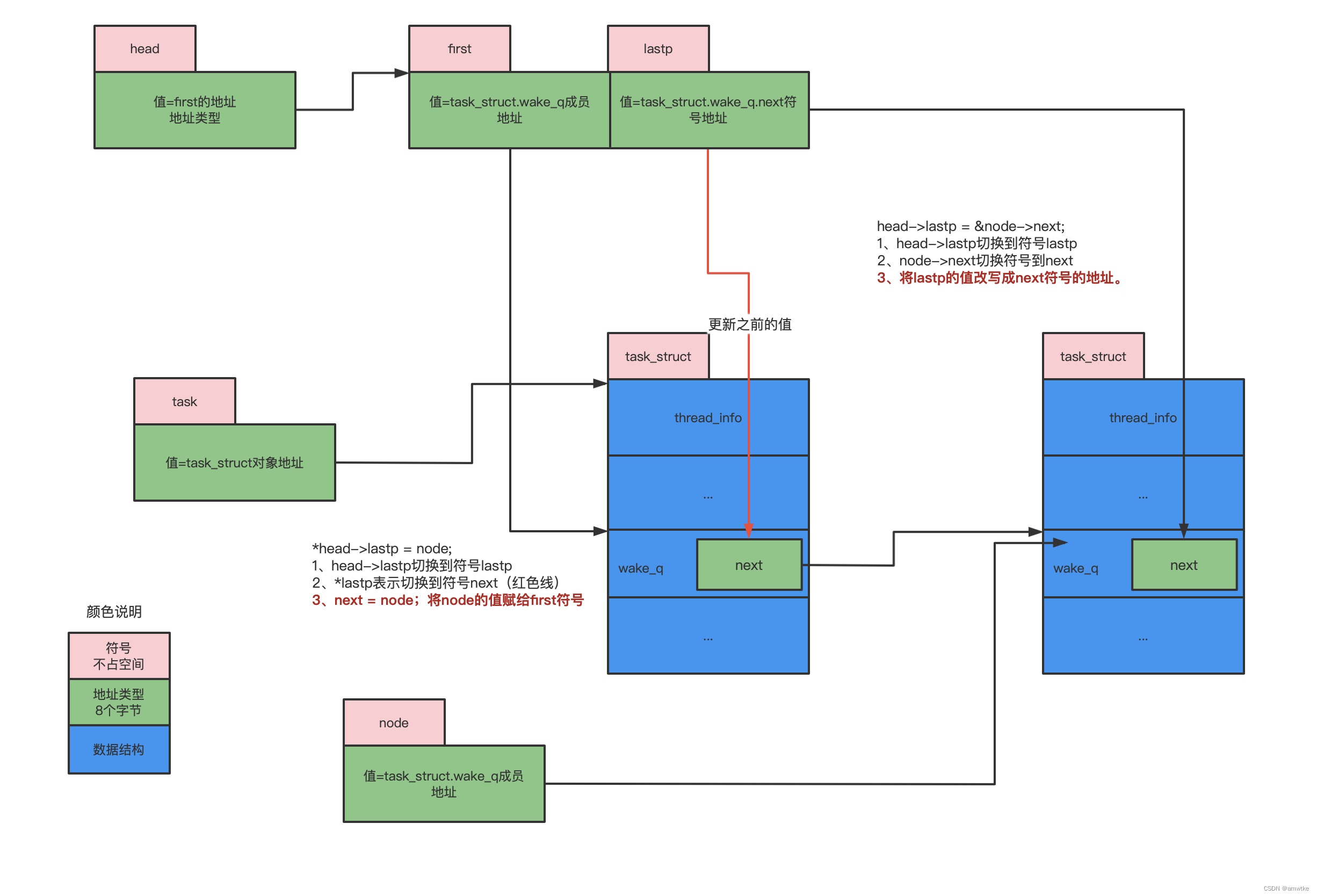
-
first始终指向第一个元素;
-
lastp始终指向最后一个元素的next符号。
关于指针你只要记住
- 看到表达式先找到
符号; 符号就等同于内存空间;符号有地址与值两个维度的属性,脑子中画一个上面的图来帮助理解;*、->这些操作符就是从一个符号切换到另一个符号,从一块内存切换到另一块;&与=就是操作符号的内存值。
- 看到表达式先找到
理解了指针就能更进一步理解内存对齐了
内存对齐应该叫做内存的虚拟地址对齐,讲的是如果我们为一个数据结构——抽象来讲就是一块内存——分配一个地址的时候,需要满足的规则。那么规则有哪些?我们可以先列出来:
基本数据类型(int,short,char,byte,long,float,double)的变量的首字节地址必须是类型字节数的整数倍;- 结构体(首字节地址)必须是最大成员变量数据类型的整数倍(编译器维护);
- 结构体中每个成员变量的首字节地址,必须是成员类型的整数倍,如果不是,则编译器填充实现;
- 结构体的总体长度必须是最大成员变量类型长度的整数倍,如果不是,编译器在结构体最后一个字节末尾填充
0实现。
下面具体说明下这些规则都是什么意思。
基本数据类型的首地址必须是类型字节数的整数倍
还是这个代码片段:
#include<stdio.h>
#include<stdlib.h>
typedef struct test {
short b;
int a;
} Test;
int main(){
printf("Test size is:%ld\n",sizeof(Test));
Test* t_ptr = (Test*)malloc(sizeof(Test));
t_ptr->a = 1;
t_ptr->b = 2;
printf("a is:%d\n",t_ptr->a);
printf("b is:%d\n",t_ptr->b);
}
为了迎合这个问题,我们调换了a,b符号在结构体中出现的顺序。之前我们假设sizeof(Test)是6,但是真的如此吗?我们看看运行的结果:
Test size is:8
a is:1
b is:2
其实是8个字节。为啥呢?就是因为int a要符合基本数据类型的首地址必须是类型字节数的整数倍这条规则,所以编译器会在b与a之间插入2个字节的0,使得a的首字节地址是int的整数倍;变成:
typedef struct test {
short b;
short invisible_padding; //实际看不见
int a;
} Test;
反汇编验证下:
t_ptr->a = 1;
119c: 48 8b 45 f8 mov -0x8(%rbp),%rax /*拿到符号t_ptr的地址*/
11a0: c7 40 04 01 00 00 00 movl $0x1,0x4(%rax) /*执行 = 操作符,给符号a的内存赋值*/
t_ptr->b = 2;
11a7: 48 8b 45 f8 mov -0x8(%rbp),%rax /*拿到符号t_ptr的地址*/
11ab: 66 c7 00 02 00 movw $0x2,(%rax) /*执行 = 操作符,给符号b的内存赋值*/
可以从反汇编看到a的内存地址从偏移地址0x4开始,而b从偏移地址0x2开始,而padding是放在t_ptr的开始位置的,这跟我的猜想有点出入,但是并不破坏规则,因为int a的首字节地址依然变成了4的整数倍。如下图:
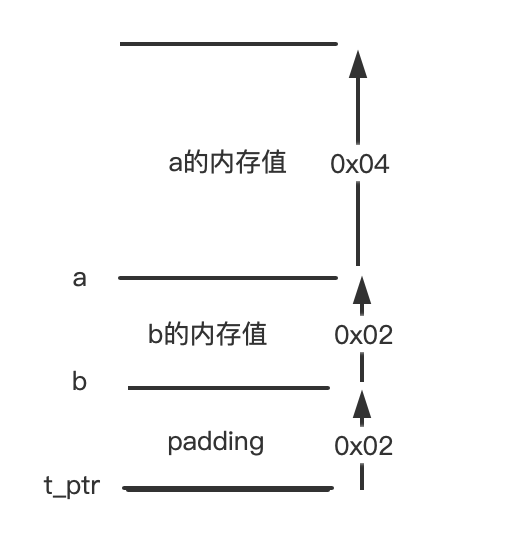
那么问题就来了,为什么要填充呢?本质的原因是什么?
从CPU角度看看为什么要对齐
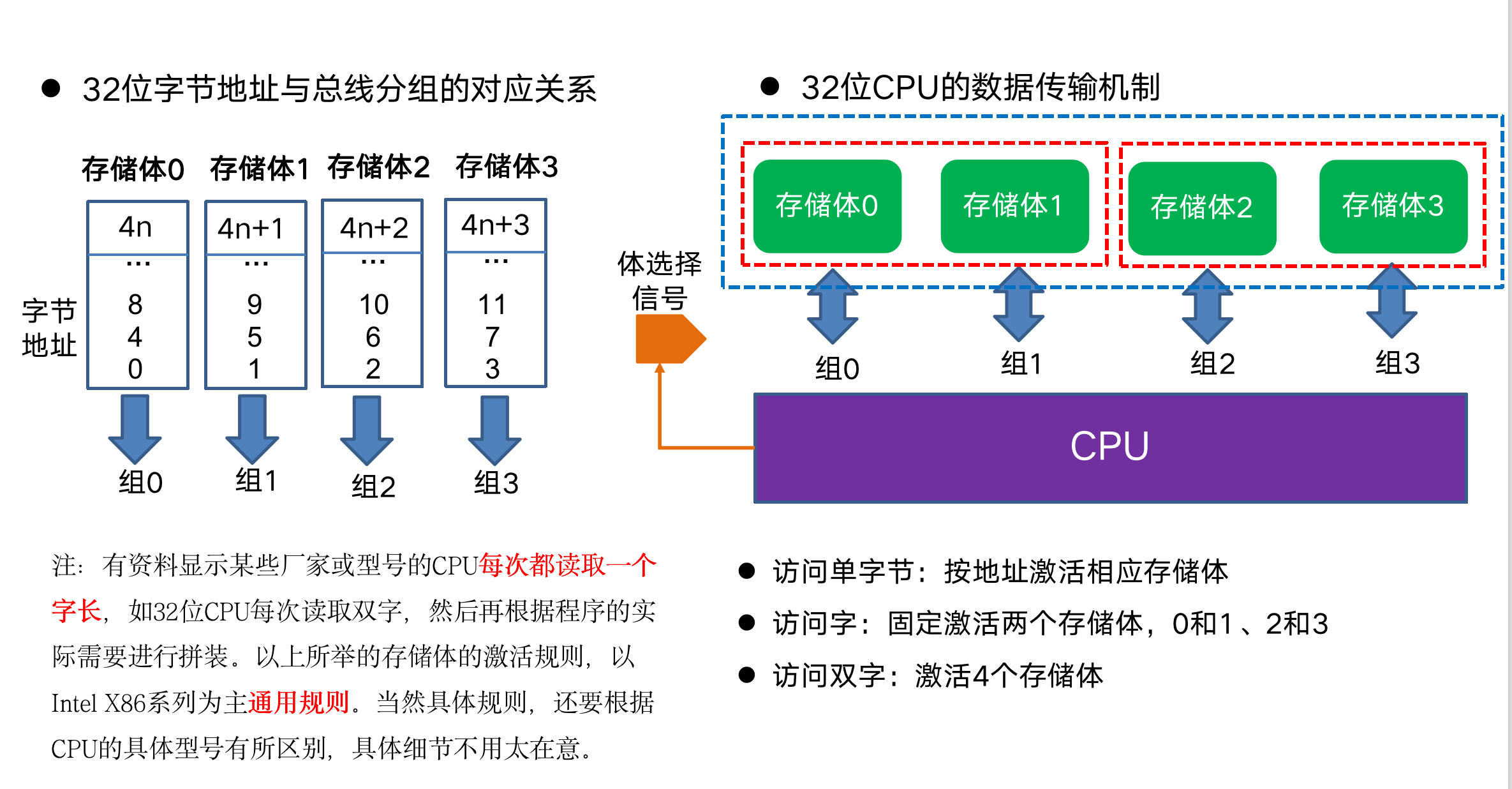
一图胜千言:
解释:
- 内存的访问真的没有程序员想的那么简单,而是分组读取的,也就是总线32位宽,其实不是连续的,而是分成了4组,每组读取1个字节,然后拼成一个双字的数据块;x64就分成8个组;
- 可以把组看成一个通道,CPU可以一次激活最多4个(32位)或者8个(64位)通道,一次读取可以看成一个transaction;
- 每个通道一次读取一个字节的数据;
- 每个通道读取的地址是有规律的,比如1号通道(0,4,8,12,16…)二号通道(1,5,9,13,…)依次类推;
- 数据读取性能跟所需的transaction数量相关,越少性能越高;
- 根据以上的事实,内存对齐的定义其实就是——让数据结构的
首字节地址始终在通道1上就是对齐的数据,否则,就不是; - 符号首地址是n字节对齐的含义是:**符号首字节地址是n字节的倍数。**比如,下图,
int a就是4字节对齐的,第二个int a’是6字节对齐的。 - 数据不对齐会比对齐的数据,在访问时,多1次内存的开销。
一图胜千言,上图:
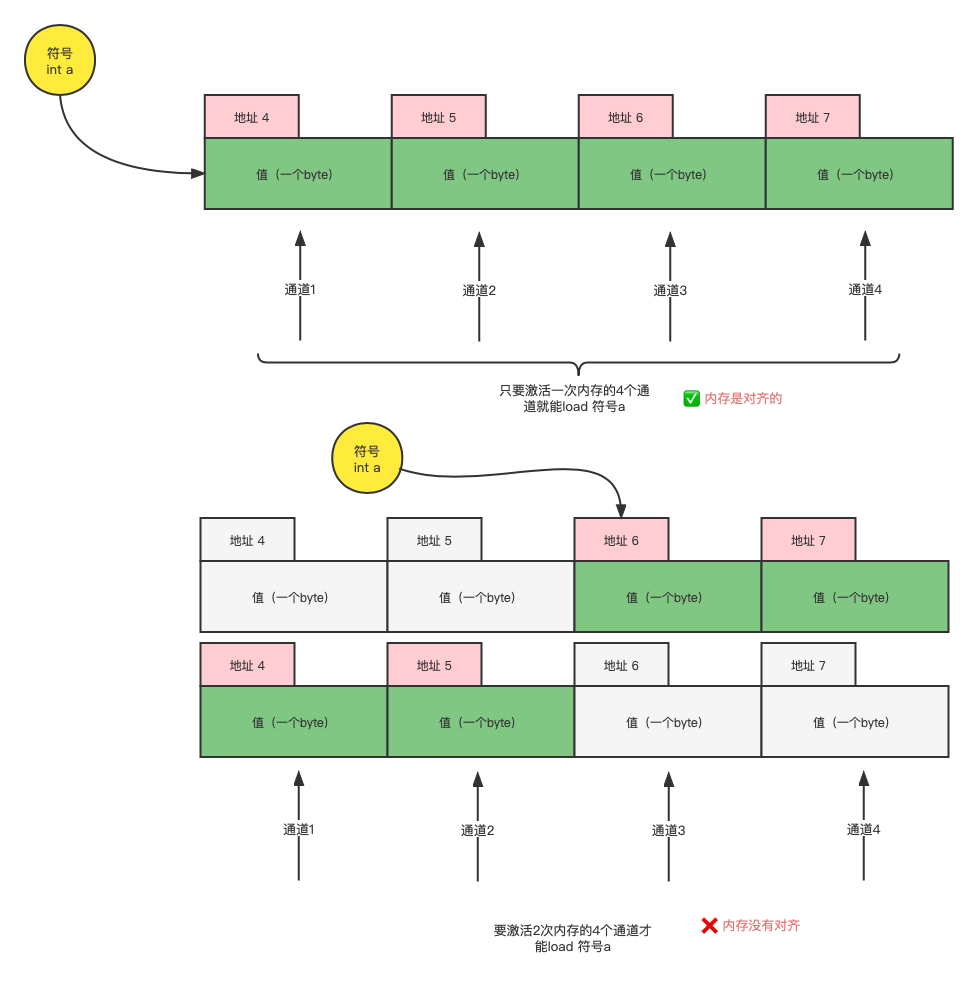
所以,内存必须对齐,不然同样的数据结构,没对齐比对齐后的内存要多一次内存的开销。
不要小看这一次内存访问的开销,因为:
- CPU可以说每时每刻都在以超高并发量访问内存,假如1秒1千次的内存访问,如果都多一次,一秒就是2千次,性能会下降50%。
- 根据性能金字塔,内存的访问可是在底层,延迟是很大的,所以在CPU这种高并发的场景下,特别是多核的SMP系统,性能问题就会更加严重。
关于结构体的三条规则
-
结构体(首字节地址)必须是最大成员变量数据类型的整数倍(编译器维护);
-
结构体中每个成员变量的首字节地址,必须是成员类型的整数倍,如果不是,则编译器填充实现;
-
结构体的总体长度必须是最大成员变量类型长度的整数倍,如果不是,编译器在结构体最后一个字节末尾填充
0实现。
其中2.就是基本数据类型的首地址必须是类型字节数的整数倍的推论,或者说是等价的,不需要证明。
关于1.与3.的证明,需要引入一个推论:如果符号的首地址是n字节对齐的,那么一定是n/2对齐的,也一定是n/4对齐的,依次类推下去。
举个例子来说就是:符号a的首地址如果是8字节对齐,那么一定也是4字节对齐,一定也是2字节对齐的。其实很容易证明:如果a的地址是x,x%8 = 0;那么x = b×8;x%4 = b×4×2 %4=0;所以也是4字节对齐的。
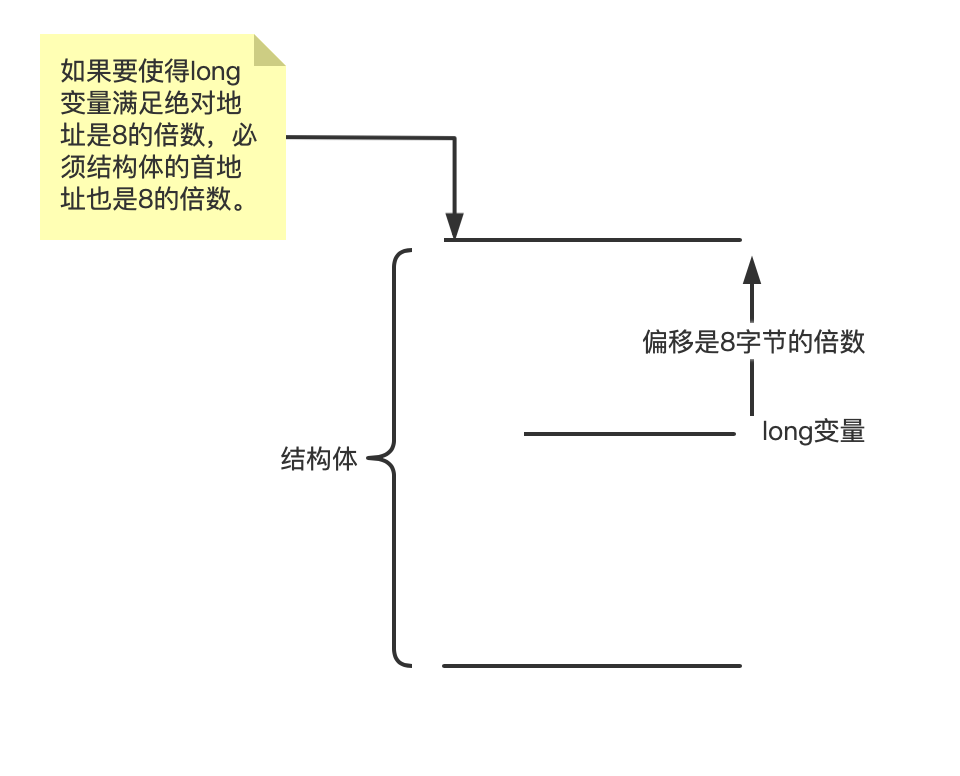
结构体(首字节地址)必须是最大成员变量数据类型的整数倍的证明
可以由2.推导而来。步骤是:
1、假设结构体中的最大成员变量的长度是long8个字节;那么,根据2.可知,这个变量前面的变量的长度总和,必须是8的整数倍;
2、所以,如果结构体的首字节地址不是8的整数倍,那么就算最大成员变量之前的所有成员变量长度和满足了是8的整数倍,也不能保证2.的成立;
3、所以结构体的首字节地址必定是最大成员长度的整数倍,也就是8字节对齐的。
结构体的总体长度必须是最大成员变量类型长度的整数倍证明
这个主要是考虑数组的情况。在单个结构体中对齐的数据,必须在数组情况下也是对齐的,如果最大的成员变量是对齐的,则所有其他成员变量都是对齐的。证明如下图:
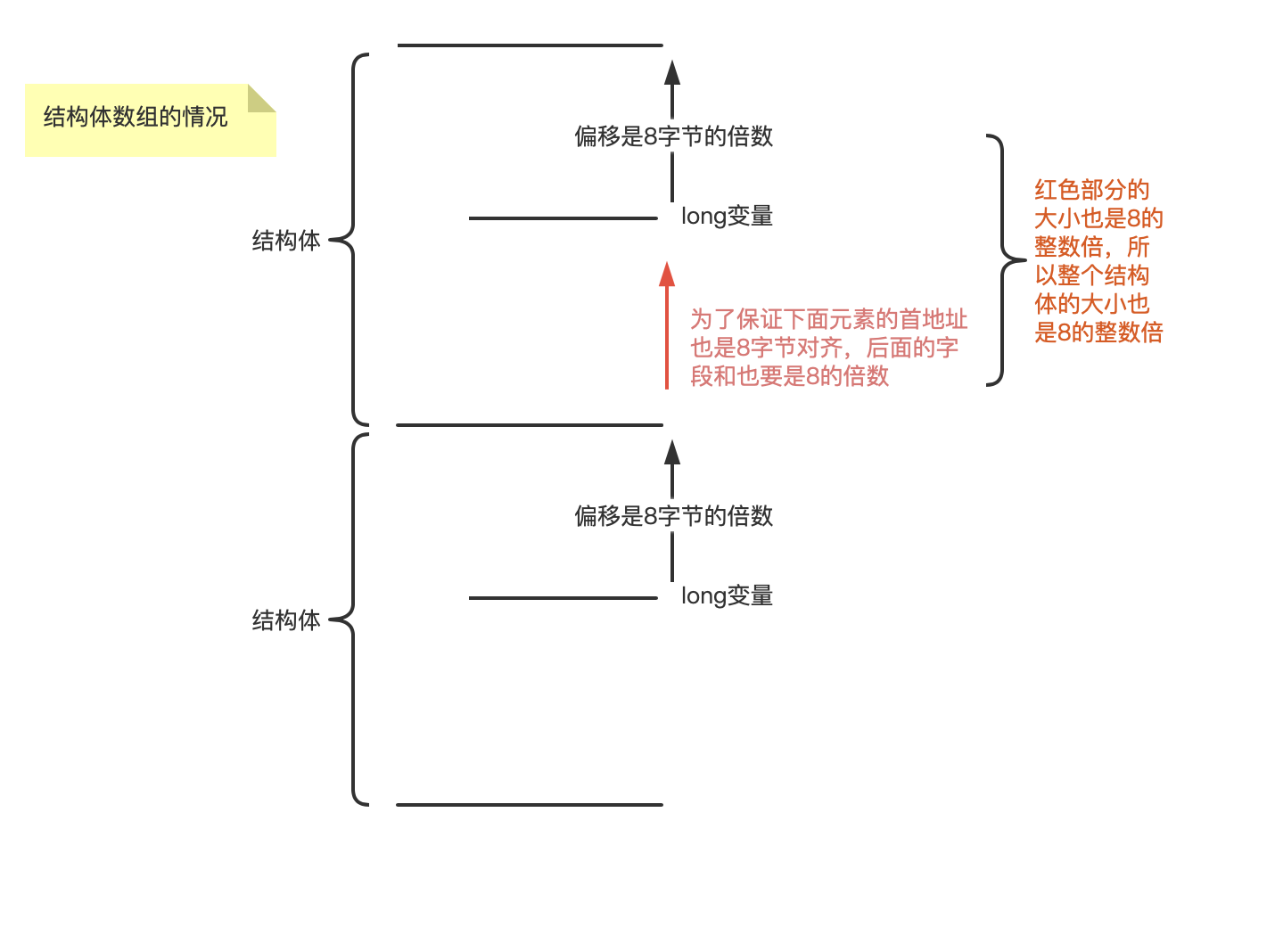
以一个例子总结
#include <stdio.h>
#include <stdlib.h>
typedef struct test
{
int a; // 4
// padding 4
long long b; // 8 b要8字节对齐,也就是前面的字节数要是8的倍数,而前面只有4字节,所以要padding4个字节
char c; // 1
// padding 1
short d; // 2 同样d前面的字节数要是2的倍数,所以padding 1个字节
// padding 4 前面整体的test结构只有20个字节,而整体的大小也要是最大元素的整数倍,因为如果是数组,那么两个my的元素那么第二个my的b变量位于28的位置,不是8的整数倍,所以结尾再padding4个字节。凑成24个字节。
} My;
int main(int argc, char *argv[])
{
//栈上分配
My my;
my.a = 1;
11ab: c7 45 e0 01 00 00 00 movl $0x1,-0x20(%rbp)
my.b = 2L;
11b2: 48 c7 45 e8 02 00 00 movq $0x2,-0x18(%rbp)
11b9: 00
my.c = 'a';
11ba: c6 45 f0 61 movb $0x61,-0x10(%rbp)
my.d = 4;
11be: 66 c7 45 f2 04 00 movw $0x4,-0xe(%rbp)
*/
My my;
my.a = 1;
my.b = 2L;
my.c = 'a';
my.d = 4;
printf("size of my:%d\n", sizeof(My));
printf("address of my is:%x\n", &my);
//堆上分配
/*
11f8: bf 18 00 00 00 mov $0x18,%edi
11fd: e8 8e fe ff ff call 1090 <malloc@plt>
1202: 48 89 45 c0 mov %rax,-0x40(%rbp)
my_on_heap->a = 1;
1206: 48 8b 45 c0 mov -0x40(%rbp),%rax
120a: c7 00 01 00 00 00 movl $0x1,(%rax)
my_on_heap->b = 2L;
1210: 48 8b 45 c0 mov -0x40(%rbp),%rax
1214: 48 c7 40 08 02 00 00 movq $0x2,0x8(%rax)
121b: 00
my_on_heap->c = 'a';
121c: 48 8b 45 c0 mov -0x40(%rbp),%rax
1220: c6 40 10 61 movb $0x61,0x10(%rax)
my_on_heap->d = 4;
1224: 48 8b 45 c0 mov -0x40(%rbp),%rax
1228: 66 c7 40 12 04 00 movw $0x4,0x12(%rax)
*/
My* my_on_heap = (My*)malloc(sizeof(My));
my_on_heap->a = 1;
my_on_heap->b = 2L;
my_on_heap->c = 'a';
my_on_heap->d = 4;
printf("address of my is:%x\n", my_on_heap);
}















 1456
1456











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









