









-
一、NESMA简介
NESMA方法是1989年由荷兰软件度量协会提出的,最新版本为2018年发布的2.3版本。该版本中,使用高级别功能点分析(High Level Function Point Analysis)代替估算功能点计数(Estimated Function Point Count);使用外部逻辑文件(External Logic File,ELF)代替外部接口文件(External Interface File,EIF)。NESMA估算法由IFPUG而来。相对于IFPUG功能点分析,NESMA对功能点计数进行了分级,以便在估算的不同时期选择不同的算法进行估算。
-
二、NESMA估算法分类
NESMA估算法有三种类型的功能点估算,包括:预估功能点分析法、估算功能点分析法、详细功能点分析法;分别对应项目的前期,中后期的功能点估算需求,同时估算出来的功能点也是越来越细化和精准。当然操作难度和复杂度也是越来越高。对于一般软件或项目,我们主要是使用预估功能点分析和估算功能点分析法即可,两种方法的主要区别就在于计算公式的不同,一个粗放,一个则较精细,两种都可以使用,可以根据自身项目的具体要求和所处阶段来进行选择。
在讨论预估分析法和估算分析法之前,我们先了解一下功能点的分类。NESMA从用户对应用系统的功能需求出发,把系统功能分为两大类:即对最终用户可见的事务功能(Transaction Function)和对最终用户不可见的数据功能(Data Function)。
事务功能可分为3种类型:外部输入(External Input,EI)、外部查询(ExternalinQuiry, EQ) 和外部输出 (External Output, EO)。外部输入(EI)是指应用程序对来自其边界以外的数据或控制信息的基本处理。外部输出(EO)是指应用程序向其边界之外提供数据或控制信息的基本处理,这种处理逻辑中可能包含数学计算或衍生数据等。外部查询(EQ)是指应用程序向其边界之外提供数据或控制信息的基本处理,与外部输出(EO)不同的是,处理逻辑中既不可以包含数学计算也不产生衍生数据,处理过程中不可以维护内部逻辑文件,也不可以改变系统行为。
数据功能分为2种类型:内部逻辑文件(Internal LogicFile, ILF)和外部接口文件(External Interface File,EIF)。内部逻辑文件(ILF)是指可由用户确认的、在应用程序内部进行维护的、逻辑上相关的数据块或控制信息。外部接口文件(EIF)是指可由用户确认的、由被度量的应用程序引用但在其他应用程序内部进行维护的、逻辑上相关的数据块或控制信息。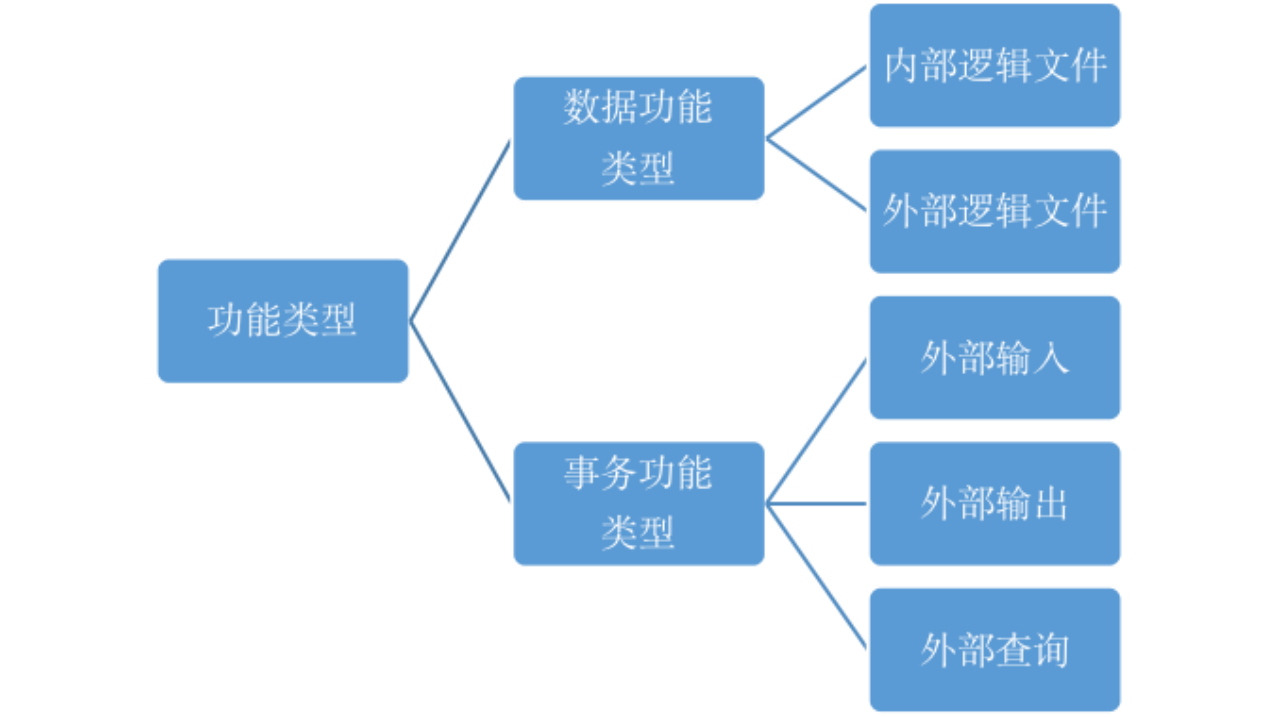
-
三、NESMA功能点分析法
-
1.预估功能点分析法
预估功能点分析是在度量时,只用识别软件的数据功能数量,根据经验公式得出软件规模模。预估功能点公式:ILF*35+EIF *15。其中,ILF是内部逻辑文件的数量,EIF是外部逻辑文件的数量。预估功能点公式的假设基于以下依据:数据功能采用“低”级复杂度,事务功能采“中”级复杂度,所以ILF、EIF、EI、EO、EQ分别是7、5、4、5、4。 -
计算因子 “35”假设每个内部逻辑文件对应3个外部输入(新增、更改、删除)、2个外部输出、1个外部查询和一些通用功能。因此,内部逻辑文件的规模是7fp,事务功能的平均规模是26fp(3 ×4+2×5+4),通用功能是 2fp.
计算因子 “15”假设每个外部逻辑文件对应1个外部输出和1个外部查询。外部逻辑文件的规模为5fp,外部输出为5fp,外部查询为4fp,以及一些通用功能1fp。
-
2.估算功能点分析法
-
估算功能点分析是指在确定每个功能部件(数据功能部件或事务功能部件)的复杂性程度时使用标准值:数据功能全部采用“低”级复杂性程度,事务功能全部采用“中”级复杂性程度计量。
-
估算步骤如下:
-
(1)确定每个功能的功能类型(ILF、EIF、EI、EO、EQ)。
-
(2)为所有的数据功能选择“低”级复杂性程度,事务性功能选“中”级复杂性程度。所以,ILF、EIF、EI、EO、EQ分别是7、5、4、5、4。
-
(3)计算整体未调整功能点。
-
该方法与详细功能点分析的唯一区别是不用为每个功能识别分配的复杂性程度,而是采用“默认值”。
-
估算功能点公式:UFP=(7*ILF+5*EIF+4* EI+5*EO+4*EQ)
-
3.详细功能点分析法
-
详细功能点分析法跟IFPUG的功能点计算方法已经基本一样。详细功能点估算的基本步骤如下:
-
(1)确定每个功能的功能类型(ILF、EIF、EI、EO、EQ)。
(2)为每个功能测量复杂性程度级别(低、中、高)。
(3)计算整体未调整功能点。
-
NESMA方法复杂度矩阵如下:
| 复杂度级别 | 功能类别 | ||||
| ILF | EIF | EI | EO | EQ | |
| 低 | 7 | 5 | 3 | 4 | 3 |
| 中 | 10 | 7 | 4 | 5 | 4 |
| 高 | 15 | 10 | 6 | 7 | 6 |
-
四、识别功能点复杂度
详细功能点分析不同于预估功能点分析和估算功能点分析,它要测量每个功能点的复杂度级别。这里对如何计算功能点复杂度进行说明。
-
1.基本概念
复杂性程度分为低、中、高3级别。对数据功能来说,复杂性程度取决于两个因素:一是看逻辑文件所包含的数据元素类型个数(Data Element Types, DET),二是看用户可以识别的记录元素类型的个数(Record Element Types,RET)。对于事务功能,复杂性程度取决于交易时所引用的所有逻辑文件的个数(File Type Referenced, FTR),以及交易处理过程中输入/输出所涉及的数据元素类型个数。具体来说,EI取决于所引用的逻辑文件的个数(FTR)和外部输入的数据元素类型个数;EO和EQ取决于所引用的逻辑文件的个数(FTR)和外部输出的数据元素个数。ILF、EIF和EI、EO、EQ的复杂程度级别如下表所示:
| 记录元素类型(RET) | 数据元素类型(DET) | ||
| 1~19 | 20~50 | ≥51 | |
| 1 | 低 | 低 | 中 |
| 2~5 | 低 | 中 | 高 |
| ≥6 | 中 | 高 | 高 |
表4.1 内部逻辑文件和外部接口文件的复杂度级别
| 引用的文件类型个数(FTR) | 数据元素类型(DET) | ||
| 1~4 | 5~15 | ≥16 | |
| 0~1 | 低 | 低 | 中 |
| 2 | 低 | 中 | 高 |
| ≥3 | 中 | 高 | 高 |
表4. 2 外部输入的复杂性程度级别
| 引用的文件类型个数(FTR) | 数据元素类型(DET) | ||
| 1~5 | 6~19 | ≥20 | |
| 0~1 | 低 | 低 | 中 |
| 2~3 | 低 | 中 | 高 |
| ≥4 | 中 | 高 | 高 |
表4. 3 外部输出和外部查询的复杂性程度级别
-
2.RET、DET识别规则
ILF、EIF的复杂度取决于RET(Record element type)和DET(Data element type)的数量。一个DET是一个以用户角度识别的、非重复的、有业务逻辑意义的字段。一个RET就是一个ILF或EIF内用户可识别的一组对象的集合。 - DET的计算规则:
- 比如, 添加订单时需要保存“订单号码、订单日期、地址、邮编”,那么对于订单来说它的DET就是4个。
- 再比如,保存订单的同时也要保存订单明细,订单作为主表、订单明细作为子表。订单明细中的订单编号作为外键与主表的单号关联。对用户来讲,保存订单是不可分割的最小操作,因为DET的不可重复性,那么订单编号在这里只能作为一个DET。
- 当两个应用程序维护和/或引用相同的ILF/EIF,但是每个应用程序分别维护/引用它们相应的DET时,这些DET在这两个应用程序的维护或引用中将单独计算。例如一个应用程序的两个基本处理过程都需要使用到“地址”的信息,地址的信息又可以细分为“国家、城市、街道、邮编”。那么对于其中一个基本处理过程来说,他将整个地址信息作为一个整体进行处理,那就只算一个DET,另外一个基本处理过程使用每个地址的详细信息,那么DET就是4个。
- RET的计算规则:
- 在一个ILF/EIF中每一个可选或必选的集合都被计算为一个RET。
- 如果一个ILF/EIF没有子集合,则ILF/EIF被计算为一个RET。 例如:在外贸订单系统中添加一个订单时会保存“订单信息、客户的ID、部门的ID”。那么订单系统ILF中RET为: 1、订单信息(必选的) 2、客户信息(必选的) 3、部门信息(可选的) 因此ILF中RET的个数为3个。
-
五、适用范围
NESMA估算只适合特定类型的产品,不是任何产品都适合。
比如以数据和交互处理为中心的;以功能多少为主要造价制约因素的(如电子政务,业务管理系统,办公自动化,ERP等系统)适用NESMA估算法;
而包含大量复杂算法;创意型软件;以非功能性需求为主(如视频和图像处理软件,杀毒软件,网络游戏,性能优化任务等)等则不适用NESMA估算法。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









