







本文较长,建议点赞收藏,以免遗失。更多AI大模型应用开发学习内容,尽在聚客AI学院。
一. 智能体的基本架构与核心功能
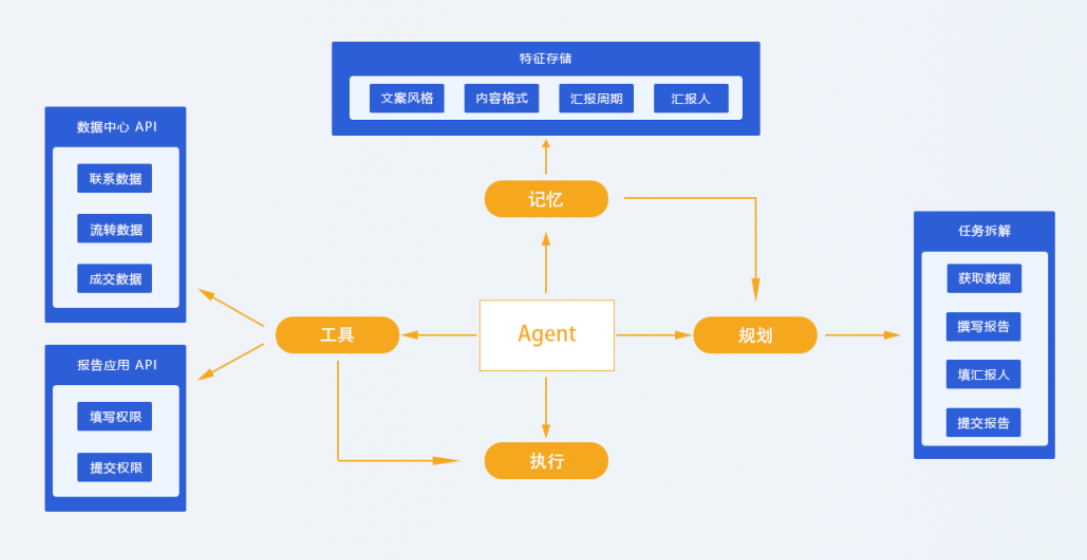
1.1 智能体架构全景图
现代智能体(Agent)通常包含五大核心模块:
规划 → 记忆 → 工具 → 执行 → 反思类比人类认知:
-
规划:制定旅行路线
-
记忆:记住历史经验
-
工具:使用地图APP
-
执行:开车前往目的地
-
反思:评估路线是否最优
二. Agents流程与决策图设计
2.1 典型决策流程
graph TD
A[用户输入] --> B(任务拆解)
B --> C{是否需要工具?}
C -->|是| D[选择工具]
C -->|否| E[直接生成]
D --> F[执行工具]
F --> G[结果解析]
G --> H[综合输出]
H --> I[反思优化]
I --> J[最终响应]2.2 决策优化策略
-
基于LLM的路由:根据输入动态选择工具
-
置信度过滤:仅当置信度>0.7时执行动作
-
备选路径:设置Fallback机制防止流程中断
代码示例:基于LangChain的决策路由
from langchain.agents import Tool, AgentExecutor
from langchain.agents import create_react_agent
tools = [
Tool(
name="Search",
func=search_api,
description="用于搜索实时信息"
),
Tool(
name="Calculator",
func=math_calculator,
description="用于数学计算"
)
]
agent = create_react_agent(llm, tools, prompt_template)
agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True)
agent_executor.invoke({"input": "上海今日气温是多少华氏度?"})三. 规划(Planning)与任务拆解
3.1 规划类型

3.2 任务拆解算法
from langchain_experimental.plan_and_execute import PlanAndExecute
planner = PlanAndExecute(
planner=llm_planner,
executor=executor_chain,
max_iterations=3
)
result = planner.run(
"规划一次北京三日游,包含文化景点和特色美食"
)
print(result)输出示例:
Day1: 故宫参观 → 午餐(炸酱面) → 景山公园观景
Day2: 颐和园 → 午餐(铜锅涮肉) → 798艺术区
Day3: 长城 → 午餐(驴打滚) → 返程四. 反思与改进机制
4.1 自我评估循环
def self_reflect(response):
reflection_prompt = f"""
评估以下回答的质量:
问题:{query}
回答:{response}
评估标准:
- 准确性(1-5分)
- 完整性(1-5分)
- 可读性(1-5分)
输出改进建议:
"""
return llm(reflection_prompt)
# 执行流程
response_v1 = agent_executor.invoke(query)
feedback = self_reflect(response_v1)
response_v2 = agent_executor.invoke(query + "\n优化建议:" + feedback)4.2 外部验证机制
-
代码验证:执行前检查代码语法
import ast
def validate_code(code):
try:
ast.parse(code)
return True
except SyntaxError:
return False
if validate_code(generated_code):
exec(generated_code)
else:
self_reflect("生成的代码存在语法错误")五. 记忆(Memory)系统设计
5.1 记忆类型

5.2 记忆检索优化
from langchain.vectorstores import FAISS
from langchain.embeddings import OpenAIEmbeddings
memory_store = FAISS.from_texts(
texts=["用户偏好素食", "上次旅行选择了文化类景点"],
embedding=OpenAIEmbeddings()
)
# 检索相关记忆
relevant_memories = memory_store.similarity_search("推荐餐厅", k=2)
print([doc.page_content for doc in relevant_memories])
# 输出: ['用户偏好素食', '上次旅行选择了文化类景点']六. 工具使用(Tools)开发实战
6.1 预制工具集(Toolkits)
常用工具类别:
-
信息检索:Google Search API、Wikipedia
-
计算:Wolfram Alpha、Python REPL
-
专业领域:法律条文查询、医疗知识库
代码示例:调用天气API
import requests
@tool
def get_weather(city: str) -> str:
"""获取指定城市当前天气"""
api_key = "YOUR_API_KEY"
url = f"http://api.weatherapi.com/v1/current.json?key={api_key}&q={city}"
response = requests.get(url)
return f"{city}气温:{response.json()['current']['temp_c']}℃"
print(get_weather.invoke("上海")) # 输出: 上海气温:25℃6.2 自定义工具开发
from langchain.tools import tool
@tool
def text_to_speech(text: str) -> str:
"""将文本转为语音文件"""
from gtts import gTTS
import io
tts = gTTS(text=text,)
mp3_file = io.BytesIO()
tts.write_to_fp(mp3_file)
return mp3_file
# 集成到智能体
tools.append(Tool(
name="TTS",
func=text_to_speech,
description="文本转语音工具"
))七. 执行(Action)系统优化
7.1 动作选择策略
-
基于嵌入相似度:计算工具描述与用户请求的余弦相似度
-
强化学习训练:使用PPO算法优化工具选择策略
代码示例:工具选择器
from sklearn.metrics.pairwise import cosine_similarity
def select_tool(query, tools):
query_embed = embed(query)
tool_embeds = [embed(t.description) for t in tools]
similarities = cosine_similarity([query_embed], tool_embeds)[0]
return tools[similarities.argmax()]
selected_tool = select_tool("计算圆的面积", tools)
print(selected_tool.name) # 输出: Calculator7.2 容错执行机制
try:
result = selected_tool.run(inputs)
except Exception as e:
logger.error(f"工具执行失败: {str(e)}")
result = llm(f"工具{selected_tool.name}执行失败,请重新尝试。错误信息:{str(e)}")
注:本文代码需配置OpenAI API密钥及安装:
pip install langchain openai fastapi gtts scikit-learn更多AI大模型应用开发学习内容,尽在聚客AI学院。


















 2255
2255

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











