









演唱会门票,火车票抢票技术你不好奇吗???
一、背景
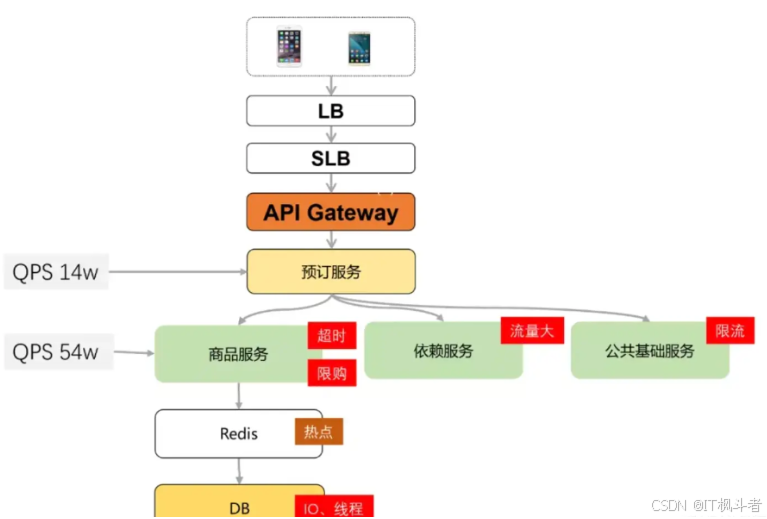
- 今年开始,旅游以及娱乐行业加速了复苏,各种大型演唱会开始紧锣密鼓的举办,同时作为疫情后第一个五一出行人次再创新高,也造就了火车票一票难求的局面。无论是演唱会还是火车票抢票都是一个高并发的场景,应对这种场景我们的系统该怎么去应对才能保障系统的三高(高性能、高并发、高可用)呢 ? 以下是线上预约抢票系统遇到的核心问题,系统的改造过程以及实施的一些经验。这是高并发、高可用场景下,提升系统稳定性的一次实战优化,希望能给面对同样问题的同学提供一些借鉴思路。
二、风险与挑战
-
在活动初期,系统面临以下四类风险:
- 流量大,入口流量瞬间增长500 倍,远超系统承载能力;
- 高并发下,服务稳定性降低;
- 限购错误;
- 热门门票、热门出行日期扣库存热点;
-
-
下面我们一起来看下图上每个问题的影响以及相应的解决策略。
2.1 放票时入口流量增长500倍
2.1.1 问题: 活动开始时入口流量增长500倍,并且当前系统无法通过水平扩展解决问题。
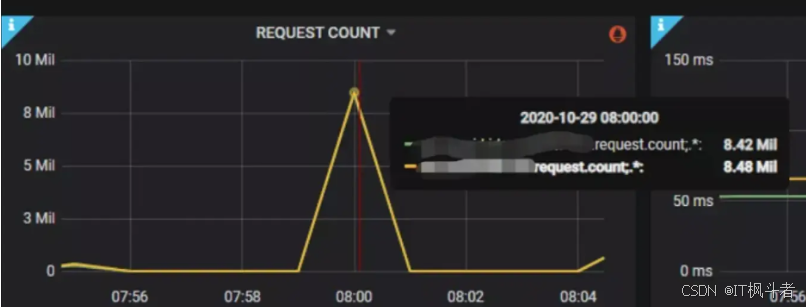
2.1.2 目标: 提升C端应用吞吐能力,并且降低下游调用量。
2.1.3 策略
-
减少依赖
-
去除0元票场景不需要的依赖。例如:优惠、立减,简单来说就是一些不影响正常业务的旁支。
-
合并重复的 IO(SOA/ Redis/DB),减少一次请求中相同数据的重复访问,还比如一些循环中请求的我们是不是可以考虑搞成批量哦。
-

-
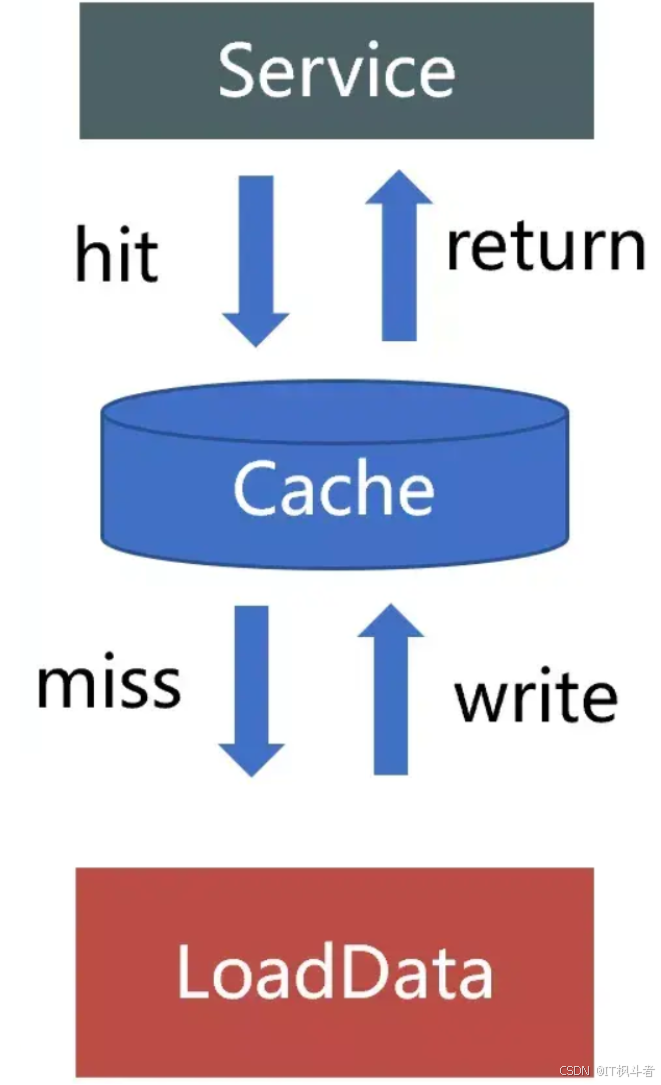
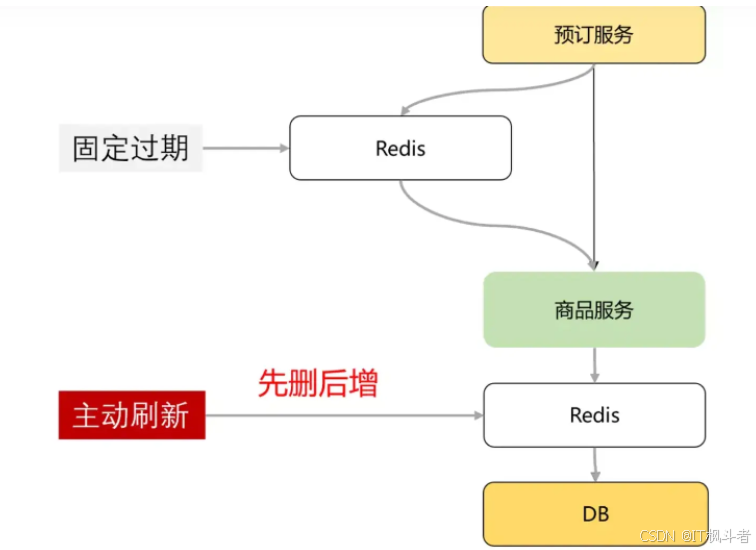
提升缓存命中率 这里说的是接口级缓存,数据源依赖的是下游接口,如下图所示:
-

-
-
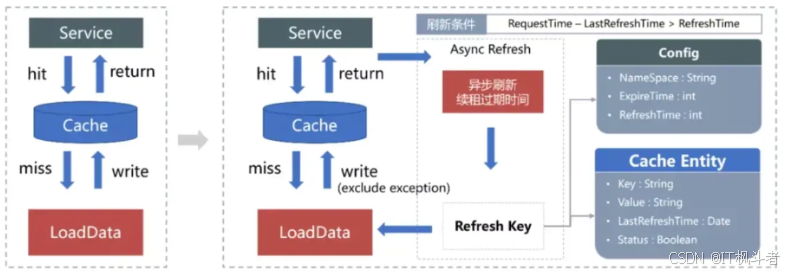
接口级缓存一般使用固定过期+懒加载方式来缓存下游接口返回对象或者自定义的DO对象。当一个请求进来,先从缓存中取数据,若命中缓存则返回数据,若没命中则从下游获取数据重新构建缓存,由于是接口级的缓存,一般过期时间设置都比较短,流程如下图:
-
-
这种缓存方案存在击穿和穿透的风险,在高并发场景下缓存击穿和缓存穿透问题会被放大,下文会分别介绍一下这几类常见问题在系统中是如何解决的。
2.1.4 缓存击穿
- 什么是缓存击穿:缓存击穿是指数据库中有,缓存中没有的场景。例如:在高并发的场景中某个key访问量非常高,属于集中式高并发访问,当这个 key 在失效的瞬间,大量的请求就击穿了缓存,直接请求到下游(接口/数据库),造成下游压力过大。
- 对应解决方案:对缓存增加被动刷新机制,在缓存实体对象中增加上一次刷新时间(加一个字段表示他的过期时间,快到时间的时候再去重新加载一次缓存),请求进来后从缓存获取数据返回,后续判断缓存是否满刷新条件,若满足则异步获取数据重新构建缓存,若不满足,本次不更新缓存。通过用户请求异步刷新的方式,续租过期时间,避免缓存固定过期。
- 例如:商品描述信息,以前缓存过期时间为10min,现在缓存过期时间为24H,被动刷新时间为1min,用户每次请求都返回上一次的缓存,但每1min都会异步构建一次缓存。
2.1.5 缓存穿透
- 什么是缓存穿透:缓存穿透是指数据库和缓存中都没有的数据,当用户不断发起请求,且并发量极高,比如获取id不存在的数据,导致缓存无法命中,造成下游压力过大。
- 对应解决方案:当缓存未命中,在下游也没有取到数据时,缓存实体内容为空对象,缓存实体增加穿透状态标识,这类缓存过期时间设置比较短,默认30s过期,10s刷新,防止不存在的id反复请求下游服务,大部分场景穿透是少量的,但是有些场景刚好相反。例如:某一类规则配置,只有少量商品有,这种情况下我们对穿透类型的缓存过期时间和刷新时间设置同正常的过期和刷新时间一样,防止下游无数据一直频繁请求。
2.1.6 异常降级
- 当下游出现异常的时候,缓存更新策略如下:
- 缓存更新:
- 下游是非核心场景:超时异常写一个短暂的空缓存(例如:30s 过期,10s刷新),防止下游超时,影响上游服务的稳定性。
- 下游是核心场景:异常时不更新缓存,下次请求再更新,防止写入空缓存,阻断了核心流程。
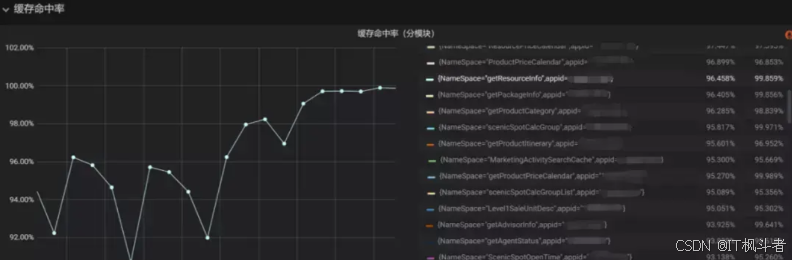
2.1.7 缓存模块化管理
-
将缓存key按照数据源做分类,每一类key对应一个缓存模块名, 每个缓存模块可以动态设置版本号、过期时间和刷新时间,并统一埋点与监控。模块化管理后,缓存过期时间粒度更为细致,通过分析缓存模块命中率监控,可以反推过期和刷新时间是否合理,最终通过动态调整缓存过期时间与刷新时间,让命中率达到最佳。
-
-
缓存模块命中率可视化埋点。 我们可以将以上功能封装为了缓存组件,在使用的时只需要关心数据访问实现,既解决了使用缓存本身的一些共性问题,也降低了业务代码与缓存读写的耦合度。
-
下图为优化前后缓存使用流程对比:
-
2.1.8 效果
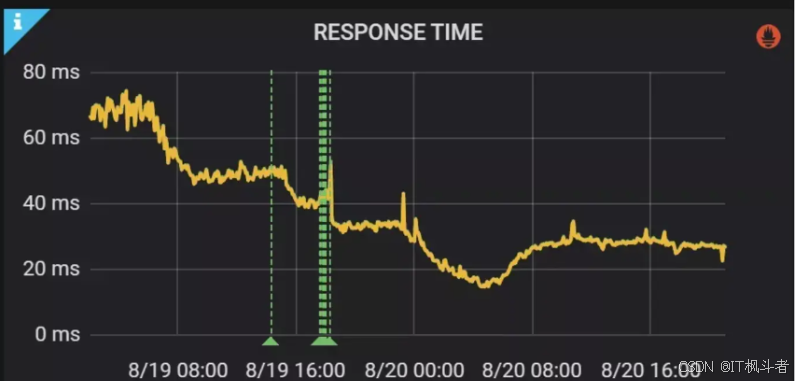
- 通过解决缓存穿透与击穿、异常降级、缓存模块化管理,最终缓存命中率提升到95%以上,接口性能 (RT) 提升60% 以上,上下游调用量比例从1 : 4.1 降低为 1 : 1.5,下游接口调用量降低60%。
2.1.9 本地缓存和Redis缓存同步机制**
-
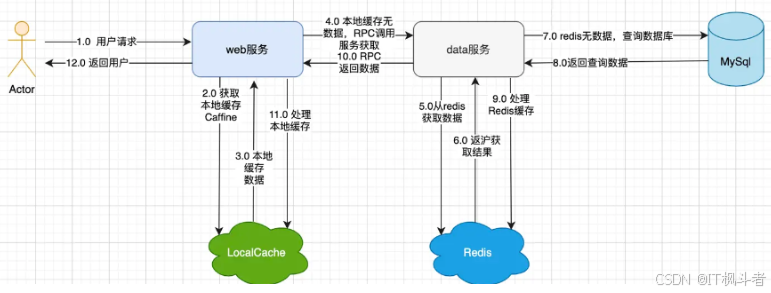
先看下demo业务流程图,属于分布式系统,服务之间的交互通过RPC交互:
-
-
- 首先 web服务是直接和用户交互的,功能和职责只是组装请求和返回数据,不会有和数据库以及Redis的交互,但是由于访问量比较大,所以加了本地缓存。
- data服务就是数据提供服务,和数据库Redis都有交互,也是业务逻辑比较重的部分,同时一些数据用Redis做了缓存。
- 大体的流程就是用户请求web服务,web服务看本地redis缓存是否有数据,如果有数据直接返回,如果没有数据需要RPC调用data服务。
- data服务接收到请求后,如果本地缓存有数据就直接使用,如果没有就需要去数据库查询。
- 在Redis 没有数据的前提下,查询到的数据放入Redis中
- 在LocalCache没有数据的前提下,RPC调用的结果放入LocalCache中
-
上边就是V1版本的整个流程,但是也存在很多弊端,下边就是我在实际环境中遇到的问题。
-
- 如果数据更新了,Redis缓存可以轻松的处理,因为data服务有和数据库交互,也有和Redis交互,也就是在数据变化的时候能够主动的去处理Redis缓存,但是本地缓存怎么处理呢?
- LocalCache 在批量获取的情况下,如果部分本地缓存有数据,部分没有要怎样处理?
- web服务集群的情况下,怎么保证各服务本地缓存同时及时得到更新?
- 不同业务模块的数据在数据变更的情况下,本地缓存怎么区分处理?
-
数据变更后本地缓存怎么同步更新 :
-
由于web服务定位就是仅仅和用户交互组装数据,不会有太多复杂业务处理逻辑,并且在高并发的情况下也是担任起首先抵御流量洪峰的后端服务,如果不做任何优化处理将会给后边服务带来巨大的压力。所以在这个地方使用了本地缓存Caffine,在一定程度上缓解了后端服务压力。Caffine有自带的缓存命中统计,后续线上观察来看web服务本地缓存抗住了90%的用户请求,同时QPS单机扛到了2k(4C8G机器),CPU使用率 50%左右,内存使用率70%(这个要看业务缓存数据大小和相应的过期时间,没有既定的一个标准,需要自己摸索),下边切入正题,数据变更了本地缓存在集群状态下怎么更新呢?
- 基于MQ的异步通知 : 在数据更新并且处理好redis缓存之后发送消息通知
- ZK监听:和MQ机制差不多,这里只是ZK变成了主动监听,而MQ需要业务主动投递消息,比较麻烦这个方案。
- Canel 异步通知:这种就是监听MySql的binlog,通知数据变更情况,目前项目中使用的就是这种。
-
同时腾讯云和阿里云都有对应数据订阅的服务。
-
LocalCache 在批量获取的情况下,如果部分本地缓存有数据,部分没有要怎样处理 本文使用的是Caffine,直接上代码:
-
/** * 容量超过最大值,LRU淘汰 */ private final LoadingCache<Long, Data> normalStockCacheWithBatch = CacheBuilder.newBuilder() .expireAfterAccess(1, TimeUnit.DAYS) .initialCapacity(200) .maximumSize(1000) .concurrencyLevel(10) .build(new CacheLoader<Long, Data>() { @Override public Data load(Long key) throws Exception { return reloadData(key); } @Override public Map<Long, Data> loadAll(Iterable<? extends Long> keys) throws Exception { List<Long> searchKeys = newArrayList(); for (Long key : keys) { searchKeys.add(key); } return reloadDataCacheWithBatch(searchKeys); } }); -
调用端:
-
public Map<Long, Data> getDataBatch(List<Long> ids) { try { Map<Long, Data> mapData = newHashMap(); List<List<Long>> partitionList = Lists.partition(ids, 100); for (List<Long> ids : partitionList) { Map<Long, Data> loadMap = normalDataCacheWithBatch.getAll(ids); mapData.putAll(loadMap); } return mapData; } catch (Exception e) { log.error("getDataBatch refresh local data cachLocalCache failed, ids:{}, exception:{}", ids, ExceptionUtils.getFullStackTrace(e)); } return null; } -
这里getAll先逐个调用get,看是否有值,这个get和之前分析的get不是同一个。对于没有值的key,统一收集起来,调用loadAll方法,loadAll会调用loader的loadAll方法,默认的loader的实现是抛一个UnsupportedLoadingOperationException类型异常,然后这里会catch住,之后便会调用我们前面分析的get方法逐个load。所以默认的loadAll等价于多次load。
-
Controller层添加本地缓存:
-
配置:
-
@Bean("common") @Primary public CacheManager commonCacheManager() { CaffeineCacheManager cacheManager = new CaffeineCacheManager(); cacheManager.setCaffeine(Caffeine.newBuilder() .expireAfterWrite(DEFAULT_LOCAL_CACHE_EXPIRE_MINUTE, TimeUnit.MINUTES) .initialCapacity(DEFAULT_LOCAL_CACHE_CAPACITY) .maximumSize(DEFAULT_LOCAL_CACHE_MAX_SIZE * 3) .recordStats()); return cacheManager; } -
key生成方式:
-
@Component public class MyCacheKeyGenerator implements KeyGenerator { private final static int NO_PARAM_KEY = 0; private String keyPrefix = "store"; protected final static char SP = ':'; @Override public Object generate(Object target, Method method, Object... params) { StringBuilder strBuilder = new StringBuilder(); strBuilder.append(keyPrefix); strBuilder.append(SP); // 类名 strBuilder.append(target.getClass().getSimpleName()); strBuilder.append(SP); // 方法名 strBuilder.append(method.getName()); //参数类型 for (Class<?> parameterType : method.getParameterTypes()) { strBuilder.append(SP); strBuilder.append(parameterType.getSimpleName()); } strBuilder.append(SP); if (params.length > 0) { // 参数值 for (Object object : params) { if (object != null && isSimpleValueType(object.getClass())) { strBuilder.append(object); } else { strBuilder.append(JsonUtil.toJson(object)); } } } else { strBuilder.append(NO_PARAM_KEY); } return strBuilder.toString(); } -
使用:
-
@Cacheable(cacheNames = "getBookmarkCount",cacheManager = "common",keyGenerator ="myCacheKeyGenerator", sync = true) public AjaxResult<DataCountVO> getDataCount(@RequestBody GetDataCountForm getDataCountForm) { retrievePatron(); DataCountModel model = dataBiz.count(getDataCountForm); DataCountVO vo = BizBeanUtils.copyProperties(model, DataCountVO.class); return AjaxResult.createSuccessResult(vo); } -
不同业务模块的数据在数据变更的情况下,本地缓存怎么区分处理
-
这个问题就要靠我们自己对缓存模块进行设计,了解相应业务关联关系,我们可以单独对每个Model 写一个缓存过期的方法。在得到相应业务数据更改的通知之后,根据业务去关联去组装对应的对应本地缓存过期逻辑,实际上就是一个编排的过程。
2.2 高并发下服务稳定性
-
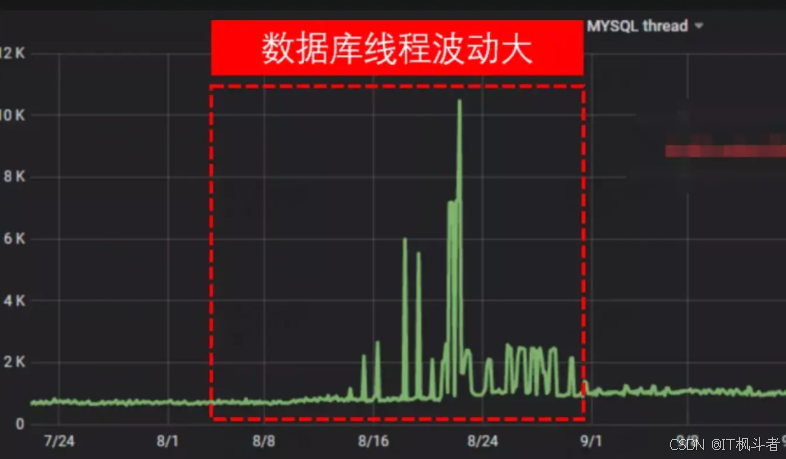
问题 在每天上午10:00 开放抢票活动开始时,DB连接池被打满,线程波动大,商品服务超时。
-
-
数据库线程有明显的波动
2.2.1 思考什么会造成这个问题
-
- DB 连接池为什么会被打满?
- API为什么会超时?
- 是DB不稳定影响了API,还是API流量过大影响了DB?
2.2.2 分析问题
- 1)DB 连接池为什么会被打满呢?从sql监控入手分析。
- Insert 语句过多 – 场景分析:限购记录提交,将限购表单独拆库隔离后,商品API依然超时(排除)
- Update 语句耗时过长 – 场景:扣减库存热点引起(重点排查方向)
- Select 有高频查询 – 场景:商品信息查询
- 2)API为什么会超时?
- 排查日志可以看到,10:00活动开始后,大量热门商品信息查询到DB与Select高频查询一致。
- 3)是DB不稳定影响了API,还是API流量过大影响了DB?
- 后来排查到是由于缓存击穿,导致大量流量穿透到DB。
2.2.3 为什么缓存会被击穿?
-
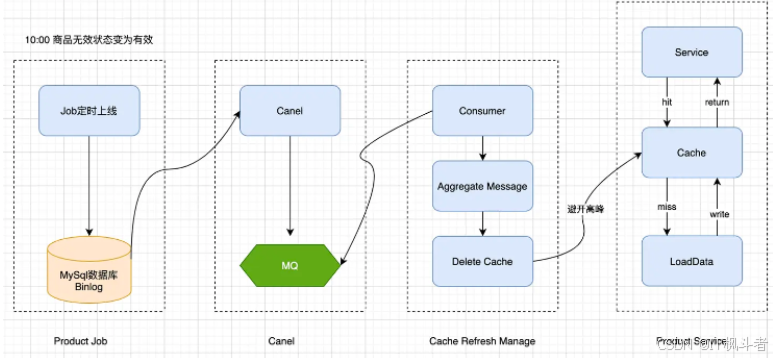
梳理系统架构以及现有业务后发现,由于10:00定时可售通过离线Job控制,10:00 商品上线引发数据变更,数据变更导致缓存被刷新(先删后增),在缓存失效瞬间,服务端流量击穿到DB,导致服务端数据库连接池被打满,也就是上文所说的缓存击穿的现象,相当于热key失效,导致大量请求回源到数据库。
-
-
如下图所示,商品信息变更后主动让缓存过期,用户访问时重新加载缓存:
-
2.2.4 上手段
-
为了防止活动时缓存被删除导致缓存击穿,流量穿透到DB,采用了以下2种策略:
-
1)避开活动时数据更新导致缓存失效
-
我们将商品可售状态拆分商品可见、可售状态。
- 可见状态:8:00提前上线对外可见,避开高峰;
- 可售状态:逻辑判断定时售卖,既解决定时上线修改数据后,导致缓存被刷新的问题,也解决了Job上线后,商品可售状态延迟的问题。
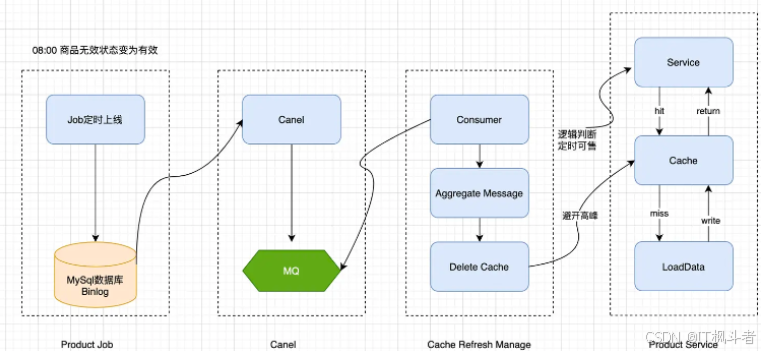
-
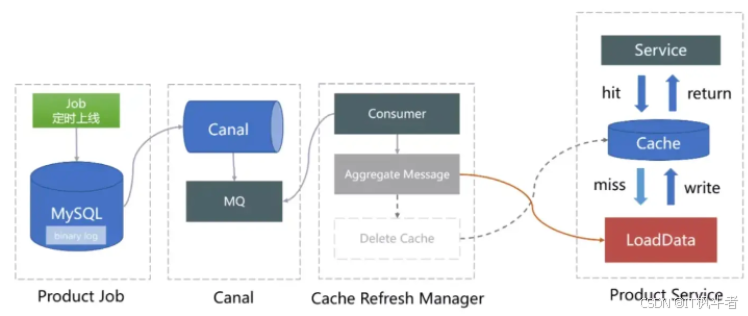
调整缓存刷新策略 原缓存刷新方案(先删后增)存在缓存击穿的风险,所以后面缓存刷新策略调整为覆盖更新,避免缓存失效导致缓存击穿。新缓存刷新架构,通过Canal监听 MySQL binlog 发送的MQ消息,在消费端聚合后,重新构建缓存。
-
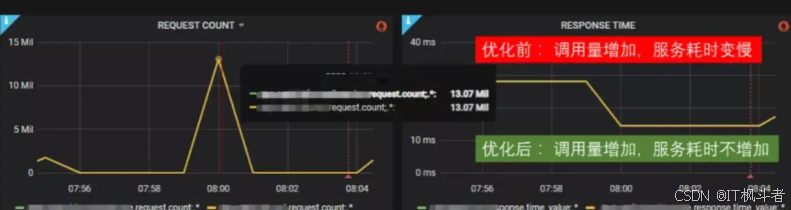
2.2.5 效果
-
服务(RT)正常,QPS提升至21w,单机2k。
-
-
上面两类问题与具体业务无关,下面我们介绍一下两个业务痛点:
- 如何防止恶意购买(限购)
- 如何防止库存少买/超买(扣库存)
2.3 限购
2.3.1 什么是限购?
- 限购就是限制购买,规定购买的数量,往往是一些特价和降价的产品,为了防止恶意抢购所采取的一种商业手段。
- 限购规则(多达几十种组合)例如:
- 1)同一场演唱会,每个人规定买的票数;
- 2)每个订单限制演出票的数量等;
- 3)每个演出场次限制用户购买的票数;
- 4)每个笔交易限制用户购买票数;
2.3.2 问题
- 扣库存失败,限购取消成功(实际数据不一致),再次预订被限购了。
2.3.3 原因
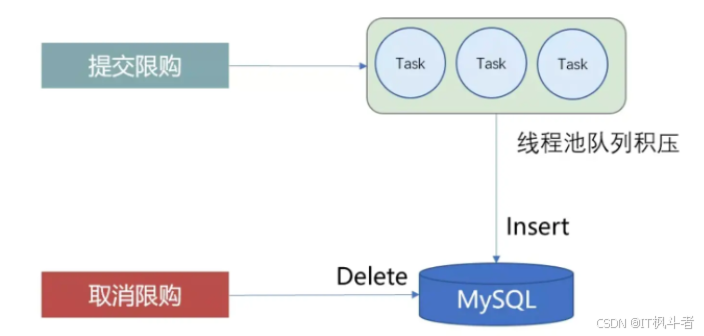
-
限购提交是Redis和DB双写操作,Redis是同步写,DB是线程池异步写,当请求量过大时,线程队列会出现积压,最终导致Redis写成功,DB延时写入。在提交限购记录成功,扣库存失败后,需要执行取消限购记录。
-
如下图所示:
-

-
在高并发的场景下,提交限购记录在线程池队列中出现积压,Redis写入成功后,DB并未写入完成,此时取消限购Redis删除成功,DB删除未查到记录,最终提交限购记录后被写入,再次预订时,又被限购。
-
如下图:
-
2.3.4 目标
- 服务稳定,限购准确。
2.3.5 上手段
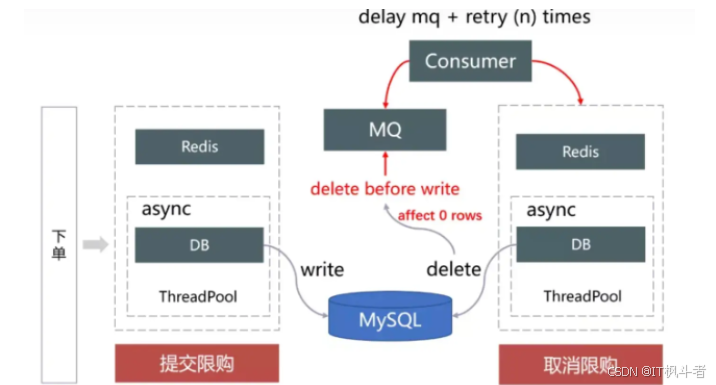
- 确保取消限购操作Redis/DB最终一致。
- 由于提交限购记录可能会出现积压,取消限购时提交限购记录还未写入,导致取消限购时未能删除对应的提交记录。我们通过延迟消息补偿重试,确保取消限购操作(Redis/DB)最终一致。在取消限购的时候,删除限购记录影响行数为0时,发送MQ延迟消息,在Consumer端消费消息,重试取消限购,并通过埋点与监控检测核心指标是否有异常。
- 如下图所示:
2.3.6 效果
- 限购准确,没有误拦。
2.4 扣减库存
2.4.1 遇到问题
- 商品后台显示1w已售完,实际卖出5000,导致库存未售完。
- MySQL出现热点行级别锁,影响扣减性能。
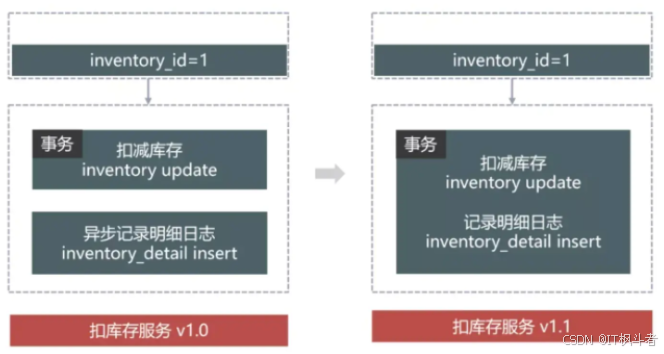
2.4.2 原因
- 扣库存与库存明细SQL不在一个事务里面,大量扣减时容易出现部分失败的情况,导致库存记录和明细不一致的情况。
- 热门演唱会日期被集中预定,导致MySQL出现扣减库存热点。
2.4.3 目标
- 库存扣减准确,提升处理能力。
2.4.4 策略
- 1)将扣减库存记录和扣减明细放在一个事务里面,保证数据一致性。
2.4.5 效果
-
优点:数据一致。
-
缺点:热点资源,热门日期,扣减库存行级锁时间变长,接口RT变长,处理能力下降。
-
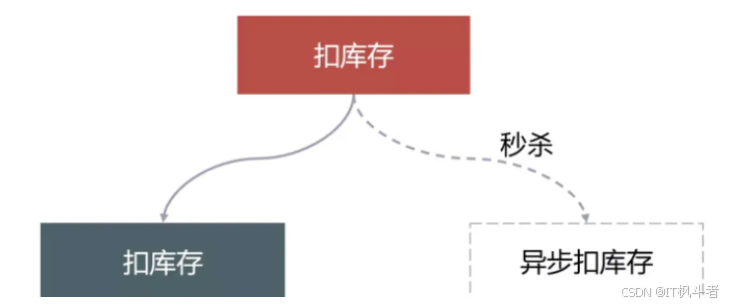
2)使用分布式缓存,在分布式缓存中预减库存,减少数据库访问。
-
秒杀商品异步扣减,消除DB峰值,非秒杀走正常流程。
-
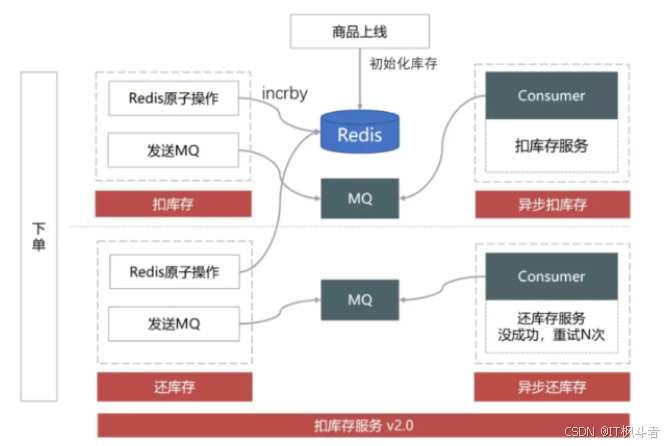
-
商品上线的时候将库存写入Redis,在活动扣减库存时,使用incrby原子扣减成功后将扣减消息MQ发出,在Consumer端消费消息执行DB扣减库存,若下单失败,执行还库存操作,也是先操作Redis,再发MQ,在Consumer端,执行DB还库存,如果未查询到扣减记录(可能扣库存MQ有延迟),则延时重试,并通过埋点与监控检测核心指标是否有异常。
-
2.4.6 效果
- 服务RT平稳,数据库IO平稳
- Redis 扣减有热点迹象
2.4.7 缓存热点分桶扣减库存
-
当单个Key流量达到Redis单实例承载能力时,需要对单key做拆分,解决单实例热点问题。由于热点演出热门日期产生热点Key问题,观察监控后发现并不是特别严重,临时采用拆分Redis集群,减少单实例流量,缓解热点问题,所以缓存热点分桶扣减库存本次暂未实现,这里简单描述一下当时讨论的思路。
-
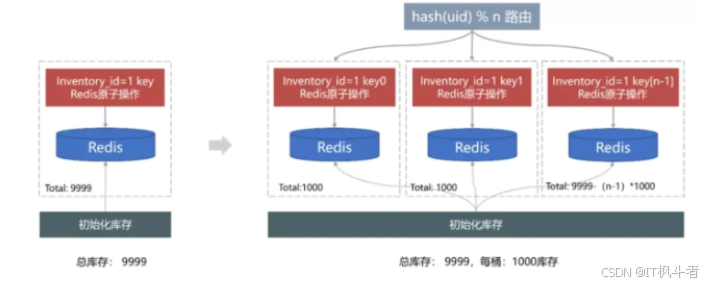
如下图所示:
-
-
分桶分库存:
-
秒杀开始前提前锁定库存修改,并执行分桶策略,按照库存Id取模分为N个桶, 每个分桶对应缓存的Key为Key [0~ N-1],每个分桶保存m个库存初始化到Redis,秒杀时根据 Hash(Uid)%N 路由到不同的桶进行扣减,解决所有流量访问单个Key对单个Redis实例造成压力。
-
桶缩容:
-
正常情况下,热门活动每个桶中的库存经过几轮扣减都会扣减为0。
-
特殊场景下,可能存在每个桶只剩下个位数库存,预订时候份数大于剩余库存,导致扣减不成功。例如:分桶数量为100个,每个桶有1~2个库存,用户预订3份时扣减失败。当库存小于十位数时,缩容桶的数量,防止用户看到有库存,扣减一直失败。
2.4.7 优化前后对比2

三、总要有总结
-
总结以往热门演唱会的经验,后来在重新设计演出系统的时候我们从以下几个方面出发:
-
梳理风险点:包括系统架构、核心流程,识别出来后制定应对策略;
流量预估:根据票量、历史PV、节假日峰值预估活动峰值QPS;
全链路压测:对系统进行全链路压测,对峰值 QPS进行压测,找出问题点,优化改进;
限流配置:为系统配置安全的、符合业务需求的限流阀值;
应急预案:收集各个域的可能风险点,制作应急处理方案;
监控:活动时观察各项监控指标,如有异常,按预案处理;
复盘:活动后分析日志,监控指标,故障分析,持续改进;



















 1580
1580

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











