







参考文献:
http://www.cnblogs.com/fly1988happy/archive/2012/04/01/2429000.html
http://blog.csdn.net/v_july_v/article/details/7109500
我的数据挖掘算法:https://github.com/linyiqun/DataMiningAlgorithm
我的算法库:https://github.com/linyiqun/lyq-algorithms-lib
算法介绍
在信息搜索领域,构建索引一直是是一种非常有效的方式,但是当搜索引擎面对的是海量数据的时候,你如果要从茫茫人海的数据中去找出数据,显然这不是一个很好的办法。于是倒排索引这个概念就被提了出来。再说倒排索引概念之前,先要理解一下,一般的索引检索信息的方式。比如原始的数据源假设都是以文档的形式被分开,文档1拥有一段内容,文档2也富含一段内容,文档3同样如此。然后给定一个关键词,要搜索出与此关键词相关的文档,自然而然我们联想到的办法就是一个个文档的内容去比较,判断是否含有此关键词,如果含有则返回这个文档的索引地址,如果不是接着用后面的文档去比,这就有点类似于字符串的匹配类似。很显然,当数据量非常巨大的时候,这种方式并不适用。原来的这种方式可以理解为是索引-->关键词,而倒排索引的形式则是关键词--->索引位置,也就是说,给出一个关键词信息,我能立马根据倒排索引的信息得出他的位置。当然,这里说的是倒排索引最后要达到的效果,至于是用什么方式实现,就不止一种了,本文所述的就是其中比较出名的BSBI和SPIMI算法。
算法的原理
这里首先给出一个具体的实例来了解一般的构造过程,先避开具体的实现方式,给定下面一组词句。
Doc1:Mike spoken English Frequently at home.And he can write English every day.
Doc2::Mike plays football very well.
首先我们必须知道,我们需要的是一些关键的信息,诸如一些修饰词等等都需要省略,动词的时态变化等都需要还原,如果代词指的是同个人也能够省略,于是上面的句子可以简化成
Doc1:Mike spoken English home.write English.
Doc2:Mike play football.
下面进行索引的倒排构建,因为Mike出现在文档1和文档2 中,所以Mike:{1, 2}后面的词的构造同样的道理。最后的关系就会构成词对应于索引位置的映射关系。理解了这个过程之后呢,可以介绍一下本文主要要说的BSBI(基于磁盘的外部排序构建索引)和SPIMI(内存单遍扫描构建索引)算法了,一般来说,后者比前者常用。
BSBI
此算法的主要步骤如下:
1、将文档中的词进行id的映射,这里可以用hash的方法去构造
2、将文档分割成大小相等的部分。
3、将每部分按照词ID对上文档ID的方式进行排序
4、将每部分排序好后的结果进行合并,最后写出到磁盘中。
5、然后递归的执行,直到文档内容全部完成这一系列操作。
这里有一张示意图:
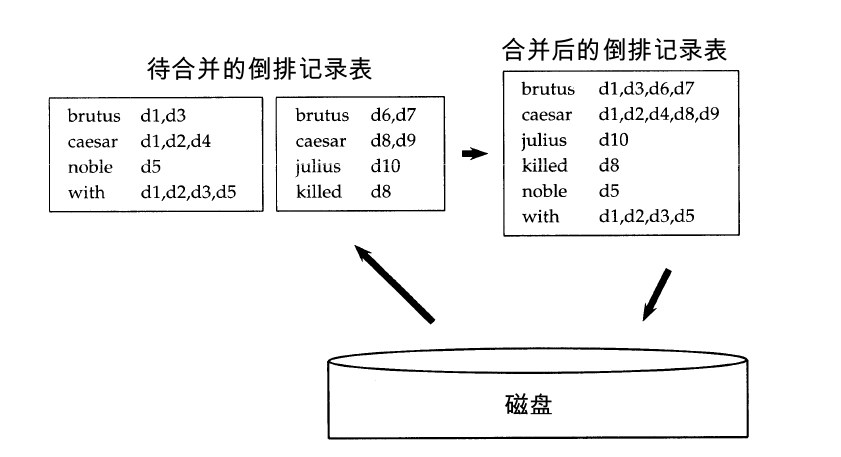
在算法的过程中会用到读缓冲区和写缓冲区,至于期间的大小多少如何配置都是看个人的,我在后面的代码实现中也有进行设置。至于其中的排序算法的选择,一般建议使用效果比较好的快速排序算法,但是我在后面为了方便,直接用了自己更熟悉的冒泡排序算法,这个也看个人。
SPIMI
接下来说说SPIMI算法,就是内存单遍扫描算法,这个算法与上面的算法一上来就有直接不同的特点就是他无须做id的转换,还是采用了词对索引的直接关联。还有1个比较大的特点是他不经过排序,直接按照先后顺序构建索引,算法的主要步骤如下:
1、对每个块构造一个独立的倒排索引。
2、最后将所有独立的倒排索引进行合并就OK了。
本人为了方便就把这个算法的实现简洁化了,直接在内存中完成所有的构建工作。望读者稍加注意。SPIMI相对比较的简单,这里就不给出截图了。
算法的代码实现
首先是文档的输入数据,采用了2个一样的文档,我也是实在想不出有更好的测试数据了
doc1.txt:
Mike studyed English hardly yesterday
He got the 100 at the last exam
He thinks English is very interestingdoc2.txt:
Mike studyed English hardly yesterday
He got the 100 at the last exam
He thinks English is very interesting
package InvertedIndex;
import java.io.BufferedReader;
import java.io.File;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.FileReader;
import java.io.IOException;
import java.io.PrintStream;
import java.util.ArrayList;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* 文档预处理工具类
*
* @author lyq
*
*/
public class PreTreatTool {
// 一些无具体意义的过滤词
public static String[] FILTER_WORDS = new String[] { "at", "At", "The",
"the", "is", "very" };
// 批量文档的文件地址
private ArrayList<String> docFilePaths;
// 输出的有效词的存放路径
private ArrayList<String> effectWordPaths;
public PreTreatTool(ArrayList<String> docFilePaths) {
this.docFilePaths = docFilePaths;
}
/**
* 获取文档有效词文件路径
*
* @return
*/
public ArrayList<String> getEFW 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1554
1554

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









