







 本文介绍了在排查Hadoop集群性能问题时,如何发现并解决JournalNode引起的延迟问题。详细讨论了JournalNode在YARN中的角色,以及QuorumJournalManager(QJM)的管理机制,强调了JournalNode的重要性。通过源码分析,阐述了Active Namenode与StandBy Namenode之间通过JournalNode同步editlog的过程,并提供了源码分析的GitHub链接。
本文介绍了在排查Hadoop集群性能问题时,如何发现并解决JournalNode引起的延迟问题。详细讨论了JournalNode在YARN中的角色,以及QuorumJournalManager(QJM)的管理机制,强调了JournalNode的重要性。通过源码分析,阐述了Active Namenode与StandBy Namenode之间通过JournalNode同步editlog的过程,并提供了源码分析的GitHub链接。
前言
最近在排查公司Hadoop集群性能问题时,发现Hadoop集群整体处理速度非常缓慢,平时只需要跑几十分钟的任务时间一下子上张到了个把小时,起初怀疑是网络原因,后来证明的确是有一部分这块的原因,但是过了没几天,问题又重现了,这次就比较难定位问题了,后来分析hdfs请求日志和Ganglia的各项监控指标,发现namenode的挤压请求数持续比较大,说明namenode处理速度异常,然后进而分析出是因为写journalnode的editlog速度慢问题导致的,后来发现的确是journalnode的问题引起的,后来的原因是因为journalnode的editlog目录没创建,导致某台节点写edillog一直抛FileNotFoundException,所以在这里提醒大家一定要重视一些小角色,比如JournalNode.在问题排查期间,也对YARN的JournalNode相关部分的代码做了学习,下面是一下学习心得,可能有些地方分析有误,敬请谅解.
JournalNode
可能有些同学没有听说过JournalNode,只听过Hadoop的Datanode,Namenode,因为这个概念是在MR2也就是Yarn中新加的,journalNode的作用是存放EditLog的,在MR1中editlog是和fsimage存放在一起的然后SecondNamenode做定期合并,Yarn在这上面就不用SecondNamanode了.下面是目前的Yarn的架构图,重点关注一下JournalNode的角色.
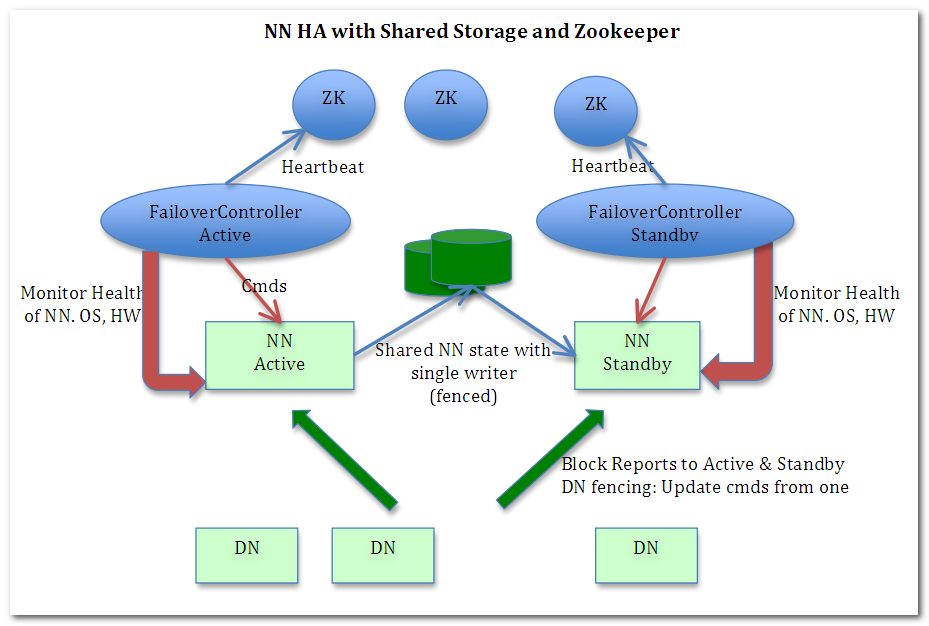
上面在Active Namenode与StandBy Namenode之间的绿色区域就是JournalNode,当然数量不一定只有1个,作用相当于NFS共享文件系统.Active Namenode往里写editlog数据,StandBy再从里面读取数据进行同步.
QJM
下面从Yarn源码的角度分析一下JournalNode的机制,在配置中定义JournalNode节点的个数是可多个的,所以一定会存在一个类似管理者这样的角色存在,而这个管理者就是QJM,全程QuorumJournalManager.下面是QJM的变量定义:
/**
* A JournalManager that writes to a set of remote JournalNodes,
* requiring a quorum of nodes to ack each write.
* JournalManager可以写很多记录数据给多个远程JournalNode节点
*/
@InterfaceAudience.Private
public class QuorumJournalManager implements JournalManager {
static final Log LOG = LogFactory.getLog(QuorumJournalManager.class);
// Timeouts for which the QJM will wait for each of the following actions.
private final int startSegmentTimeoutMs;
private final int prepareRecoveryTimeoutMs;
private final int acceptRecoveryTimeoutMs;
private final int finalizeSegmentTimeoutMs;
private final int selectInputStreamsTimeoutMs;
private final int getJournalStateTimeoutMs;
private final int newEpochTimeoutMs;
private final int writeTxnsTimeoutMs;
// Since these don't occur during normal operation, we can
// use rather lengthy timeouts, and don't need to make them
// configurable.
private static final int FORMAT_TIMEOUT_MS = 60000;
private static final int HASDATA_TIMEOUT_MS = 60000;
private static final int CAN_ROLL_BACK_TIMEOUT_MS = 60000;
private static final int FINALIZE_TIMEOUT_MS = 60000;
private static final int PRE_UPGRADE_TIMEOUT_MS = 60000;
private static final int ROLL_BACK_TIMEOUT_MS = 60000;
private static final int UPGRADE_TIMEOUT_MS = 60000;
private static final int GET_JOURNAL_CTIME_TIMEOUT_MS = 60000;
private static final int DISCARD_SEGMENTS_TIMEOUT_MS = 60000;
private final Configuration conf;
private final URI uri;
private final NamespaceInfo nsInfo;
private boolean isActiveWriter;
//远程节点存在于AsyncLoggerSet集合中
private final AsyncLoggerSet loggers;
private int outputBufferCapacity = 512 * 1024;
private final URLC 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 952
952

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









