







前言
之前的文章中谈论了几个最近几年HDFS中比较重要的特性(比如异构存储),本文继续探讨另一重大特性-Snapshot.Snapshot就是快照的意思.Snapshot是一个非常好的东西,一个形象的比喻,快照就好像拍风景照时的那一个瞬间的投影,过了那个时间点之后,又会有新的一个瞬间投影.所以其实Snapshot快照用一个更好的词来形容就是”瞬间映像“.
Snapshot快照概念
在进一步分析HDFS内部的快照管理之前,需要先了解Snapshot快照的概念.首先一个很根本的原则:
快照不是数据的简单拷贝,只做差异的复制这一原则在其他很多系统快照概念中都是遵守的,比如磁盘快照,也是不保存真实数据的.因为不保存实际的数据,所以快照的生成往往非常的迅速.在HDFS中,如果对其中一个目录比如/A下创建一个快照,则快照文件中将会有与/A目录下完全一样的子目录文件结构以及相应的属性信息,通过fs -cat也能看到里面的具体的文件内容,但是这并不意着snapshot对此数据进行完全拷贝,这里遵循一原则,对于大多不变的数据,你所看到的数据其实是当前物理路径所指的内容,而发生变更的INode才是会被snapshot额外拷贝,其实是一个差异拷贝.
HDFS中的快照相关命令
我们首先从hdfs暴露给客户端使用的命令为一个切入点,看看在HDFS中,至少存在以下所列的快照操作:
$ hadoop fs
Usage: hadoop fs [generic options]
[-createSnapshot <snapshotDir> [<snapshotName>]]
[-deleteSnapshot <snapshotDir> <snapshotName>]
[-renameSnapshot <snapshotDir> <oldName> <newName>]还有hdfs命令下的几个:
$ hdfs
Usage: hdfs [--config confdir] [--loglevel loglevel] COMMAND
where COMMAND is one of:
snapshotDiff diff two snapshots of a directory or diff the
current directory contents with a snapshot
lsSnapshottableDir list all snapshottable dirs owned by the current user
Use -help to see options以上2部分总共包含了6个客户端命令,通过命令的名称以及对应的解释,我们也能大概明白其作用.这些命令的具体使用方法不是本文的重点,具体用法可点此HDFS Snapshots.
如果读者仔细观察上述的6个命令,可以看出其中主要围绕着2个概念:
- 1.Snapshottable Directories, 快照目录
- 2.Snapshot: 具体快照
在逻辑上的对应关系如下:
一个快照目录下可以有多个快照文件,快照目录可以创建,删除自身目录下的快照文件,同时快照目录本身又被快照目录管理器所管理.这里面就引出了更深层次的内容:HDFS内部的快照管理机制.
HDFS内部的快照管理机制
Snapshot结构关系
针对上一小节中提到的对应关系,在源码层面是如何表现的呢?
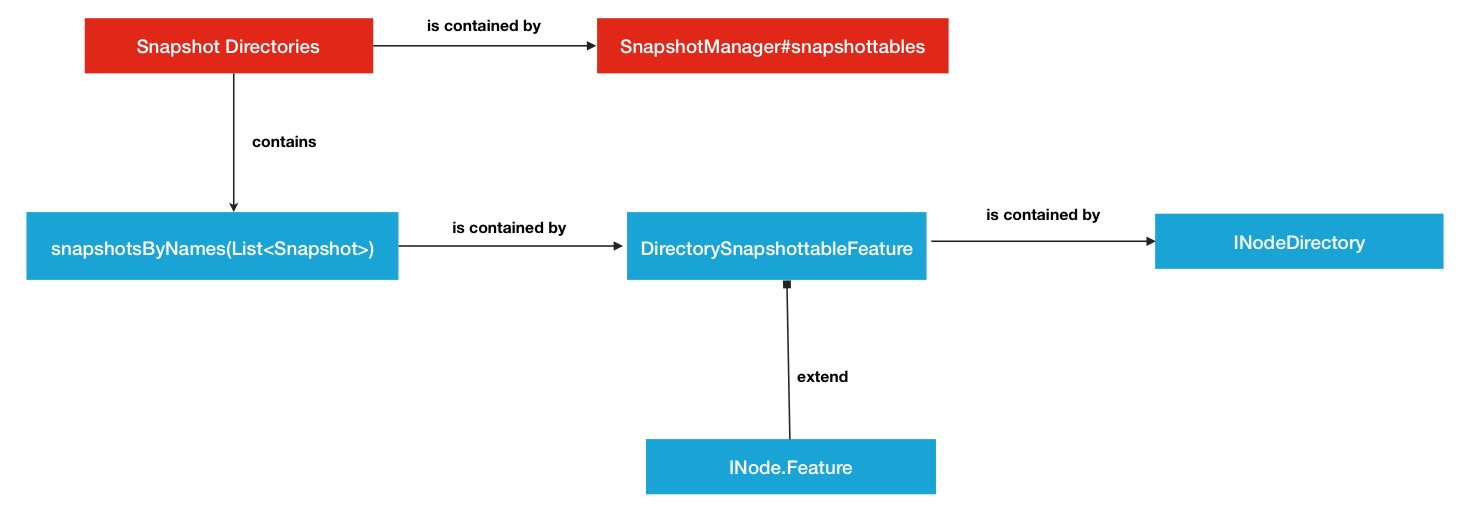
1.快照管理器管理多个快照目录.
public class SnapshotManager implements SnapshotStatsMXBean { //... /** All snapshottable directories in the namesystem. */ private final Map<Long, INodeDirectory> snapshottables = new HashMap<Long, INodeDirectory>(); ...所以其实每个快照目录就是我们非常熟悉的INodeDirectory类.
2.一个快照目录拥有多个快照文件. Snapshot快照在快照目录中的存放就不是很明显了.他是作为一个Feature特性存在于INodeDirectory的父类INodeWithAdditionalFields中(INodeWithAdditionalFields存放的基本是最基本的一些变量,例如name,permission,modificationTime等等),代码中定义如下:
public abstract class INodeWithAdditionalFields extends INode implements LinkedElement { ... /** An array {@link Feature}s. */ private static final Feature[] EMPTY_FEATURE = new Feature[0]; protected Feature[] features = EMPTY_FEATURE; ...而snapshot列表是存在于其中一个叫DirectorySnapshottableFeature的Feature继承子类中,源码中定义如下:
public class DirectorySnapshottableFeature extends DirectoryWithSnapshotFeature { ... /** * Snapshots of this directory in ascending order of snapshot names. * Note that snapshots in ascending order of snapshot id are stored in * {@link DirectoryWithSnapshotFeature}.diffs (a private field). */ private final List<Snapshot> snapshotsByNames = new ArrayList<Snapshot>(); ...
下面用一张结构关系图来复述一下前面 提到的2大存放关系,这相当于是所有关系的一个大背景.
Snapshot调用流程
下面我们来学习一下snapshot快照的调用过程,整个过程我们以SnapshotManager为一个处理中心.
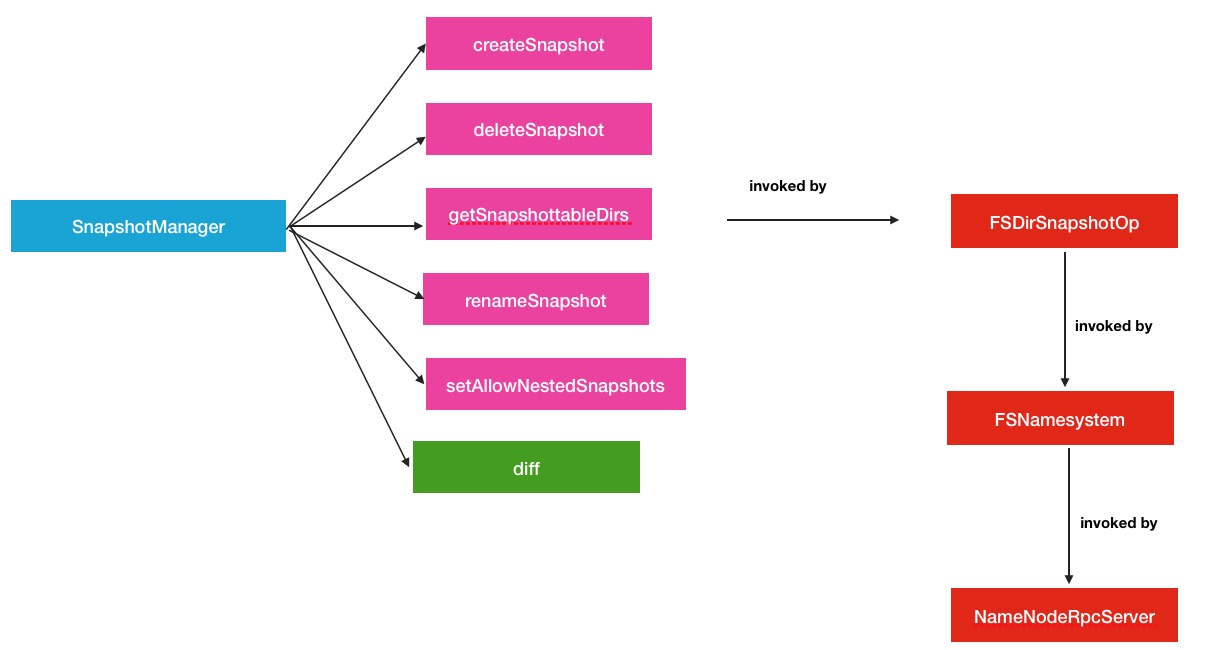
SnapshotManager负责接收snapshot操作请求,继而调用相关类进行处理这里的相关类就是INodeDirectory中的Feature继承类了.所以全部过程分为如下2部分:
- 1.上游请求的接收.如图:
- 1.请求的下游处理.如图:
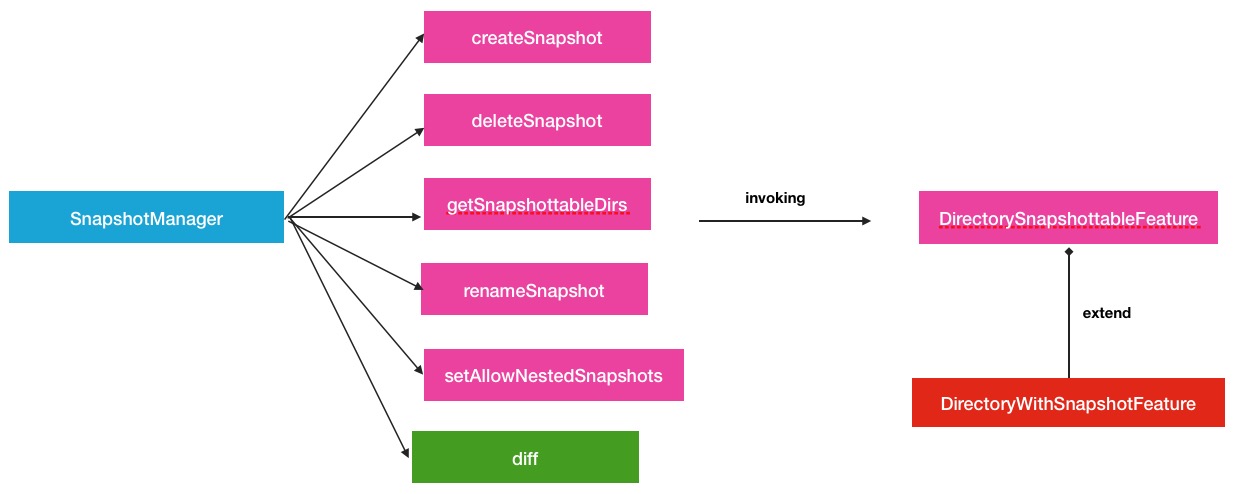
其中,在上游的请求接收阶段中,与以往直接接收NameNode RPC请求方式略有不同,中间还经过了一层FSDirSnapshotOp,在这个类中,才调用了SnapshotManager的操作方法.这样做还是有益处的,可以在FSNamesystem的众多操作里很好的辨别和区分操作的类型.
Snapshot原理实现分析
前面篇幅的部分主要从大的角度来讲HDFS的快照管理,相反地,这一小节将要探讨的内容是Snapshot的内部原理实现,将会从更细粒度的层面去分析其中的原理实现,这其中的部分逻辑还是有些复杂的.Snapshot快照的实现,我们关系的主要有2点:
- 1.Snapshot快照如何生成的,如何能够做到元数据的完全一致的?
- 2.Snapshot快照之间是如何做diff比较出不同的?
这2个问题中的每个问题实现起来都不是那么的简单,大家阅读完下面的分析,只要理解就行了.
Snapshot的生成
Snapshot的创建操作是基于hadoop fs的-createSnapshot命令触发的,需要传入2个参数,快照所在父目录名和快照名称.所以在创建快照之前,需要先有快照目录,就是要让哪些目录下能够有创建快照的权利.这就需要对目标目录执行allowSnapshot操作.在此操作执行的时候,记住一个原则:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 4888
4888











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









