







 本文介绍了HDFS跨集群数据合并的另一种解决方案——ViewFileSystem,它提供视图文件系统的概念,允许逻辑上的数据统一而无需实际数据迁移。ViewFileSystem通过挂载点管理和路径解析,实现在多个HDFS集群间的路由。文章详细阐述了ViewFileSystem的内部工作原理,包括目录挂载、请求处理和性能优化,并给出了配置和使用方法。
本文介绍了HDFS跨集群数据合并的另一种解决方案——ViewFileSystem,它提供视图文件系统的概念,允许逻辑上的数据统一而无需实际数据迁移。ViewFileSystem通过挂载点管理和路径解析,实现在多个HDFS集群间的路由。文章详细阐述了ViewFileSystem的内部工作原理,包括目录挂载、请求处理和性能优化,并给出了配置和使用方法。
前言
在很多时候,我们会碰到数据融合的需求,比如说原先有A集群,B集群,后来管理员认为有2套集群,数据访问不方便,于是设法将A,B集群融合为一个更大的集群,将他们的数据都放在同一套集群上.一种办法就是用Hadoop自带的DistCp工具,将数据进行跨集群的拷贝.当然这会带来很多的问题,如果数据量非常庞大的话.本文给大家介绍另外一种解决方案,ViewFileSystem,姑且可以叫做视图文件系统.大意就是让不同集群间维持视图逻辑上的唯一性,不同集群间还是各管各的.
传统数据合并方案
为了形成对比,下面描述一下数据合并中常用的数据合并的做法,就是搬迁数据.举例在HDFS中,也会想到用DistCp工具进行远程拷贝.虽然DistCp本身就是用来干这种事情的,但是随着数据量规模的升级,会有以下问题的出现:
- 1.拷贝周期太长,如果数据量非常大,在机房总带宽有限的情况,拷贝的时间将会非常长.
- 2.数据在拷贝的过程中,一定会有原始数据的变更与改动,如何同步这方面的数据也是需要考虑的方面.
以上2点,是我想到的比较突出的问题.OK,下面就要隆重介绍一下ViewFileSystem的概念了,可能还不是被很多人所熟知.
ViewFileSystem: 视图文件系统
前言中也部分提到了ViewFileSystem的概念,首先要明白一个核心原则
ViewFileSystem不是一个新的文件系统,只是逻辑上的一个视图文件系统,在逻辑上是唯一的.这句话怎么理解呢,ViewFileSystem就帮大家做了一件事情
将各个集群的真实文件路径与ViewFileSystem的新定义的路径进行关联映射上面这句话的意思就好比文件系统中的mount,挂载的意思.进一步地说,ViewFileSystem会在每个客户端中维护一份mount-table挂载关系表,就是上面说的集群物理路径->视图文件系统路径这样的指向关系.但是在mount-table中,关系当然不止1个,会有很多个.比如下面所示的多对关系:
/user -> hdfs://nn1/containingUserDir/user
/project/foo -> hdfs://nn2/projects/foo
/project/bar -> hdfs://nn3/projects/bar前面是ViewFileSystem中的路径,后者才是代表的真正集群路径.所以你可以理解为ViewFileSystem真正干的事情就是路径的路由解析.下面给出简单的原理图:
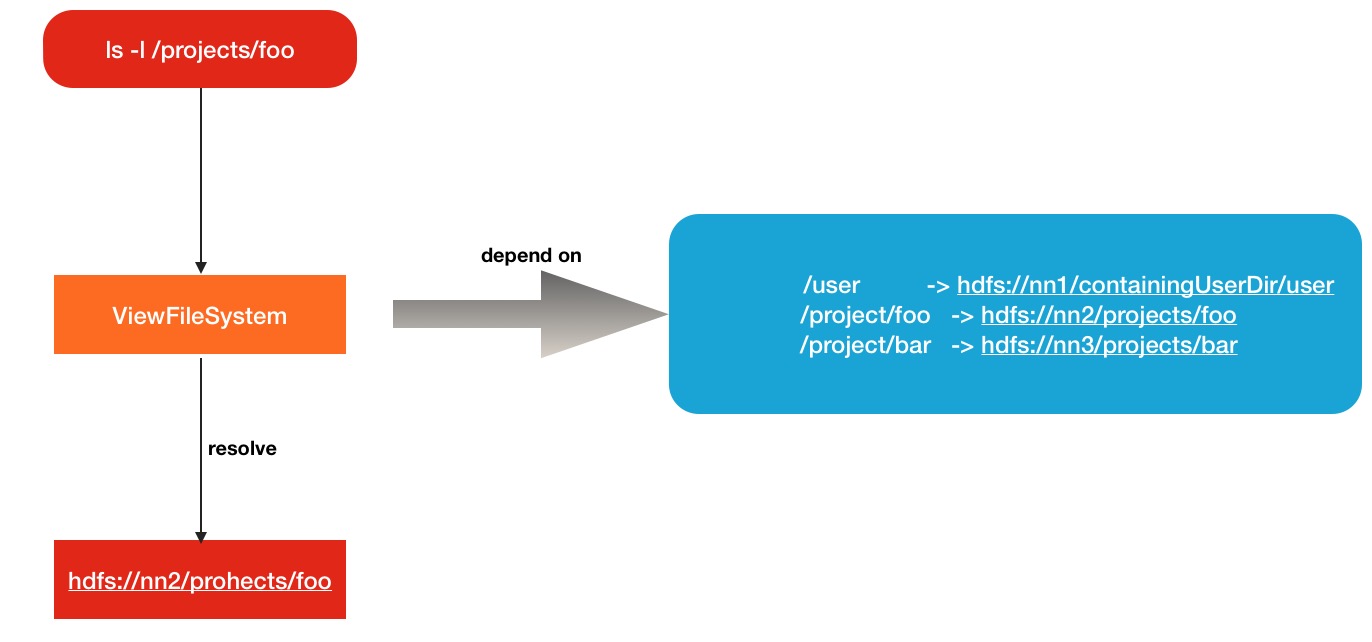
具体如何进行配置使用会在下文中给出使用方法.
ViewFileSystem内部实现原理
在上文中我们已经基本了解到了ViewFileSystem的作用基本是一个路由解析的角色,真实的请求处理还是在各自真实的集群上.这小节探讨的内容是ViewFileSystem内部是如何实现这个”路由解析“的角色呢?继续往下看.
目录挂载点
因为要做的是路由解析,所以挂载点的设计就显得非常重要了.下面看一下ViewFileSystem中是如何定义此类的.
static public class MountPoint {
// 源路径
private Path src; // the src of the mount
// 目录指向路径,也就是真实路径,可以为多个
private URI[] targets; // target of the mount; Multiple targets imply mergeMount
MountPoint(Path srcPath, URI[] targetURIs) {
src = srcPath;
targets = targetURIs;
}
Path getSrc() {
return src;
}
URI[] getTargets() {
return targets;
}
}一般情况下,挂载节点是一对一的,但是如果存在不同集群间有相同名称目录的情况,也是可以进行一对多的,在Hadoop中叫做MergeCount,不过这个功能目前尚未完成,还在开发中, 相关issueHADOOP-8298.
挂载点的解析与存放
在ViewFileSystem初始化操作中,挂载点的解析与存放其中一个非常重要的过程.其中的过程执行又是在下面这个变量中进行的:
InodeTree<FileSystem> fsState; // the fs state; ie the mount table进入ViewFileSystem的initialize实现:
public void initialize(final URI theUri, final Configuration conf)
throws IOException {
super.initialize(theUri, conf);
setConf(conf);
config = conf;
// Now build client side view (i.e. client side mount table) from config.
final String authority = theUri.getAuthority 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 931
931

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









