






点击上方关注 “终端研发部”
设为“星标”,和你一起掌握更多数据库知识毫无疑问,那必须是开源,让AI的子弹再飞一会。
前几天,DeepSeek席卷全球,140余国下载量第一!
1月20日DeepSeek-R1模型正式发布以来,DeepSeek已于1月26日同时登顶苹果App Store和谷歌Play Store全球下载榜首,上线18天内,累计下载量已突破1600万次,在覆盖的140个市场中持续保持领先地位。

在印度,DeepSeek获得了跨平台下载量的15.6%,显示了其在发展中国家市场的巨大潜力。
与此同时,DeepSeek在美国Android Play Store中同样占据了榜首位置,数据显示,自1月初发布以来,DeepSeek在前18天内获得了1600万次下载,几乎是OpenAI的ChatGPT首次发布时900万次下载量的两倍。

具体表现
高效训练与低成本
DeepSeek使用由英伟达H800 GPU驱动的数据中心进行训练,仅用两个月的时间就完成了训练,成本仅为550万美元,远低于其他顶尖AI项目所需的投资。
具体来说,这款模型的完整训练耗时278.8万个GPU小时,仅使用2048张英伟达H800 GPU(H100的特供版),这一数据与Meta的Llama-3.1相比,后者则动用了超过16000张H100 GPU,成本高达数亿美元。

通过优化算法和高效利用硬件资源,DeepSeek实现了高性能与低成本的完美结合,打破了AI领域高投入高产出的传统模式。
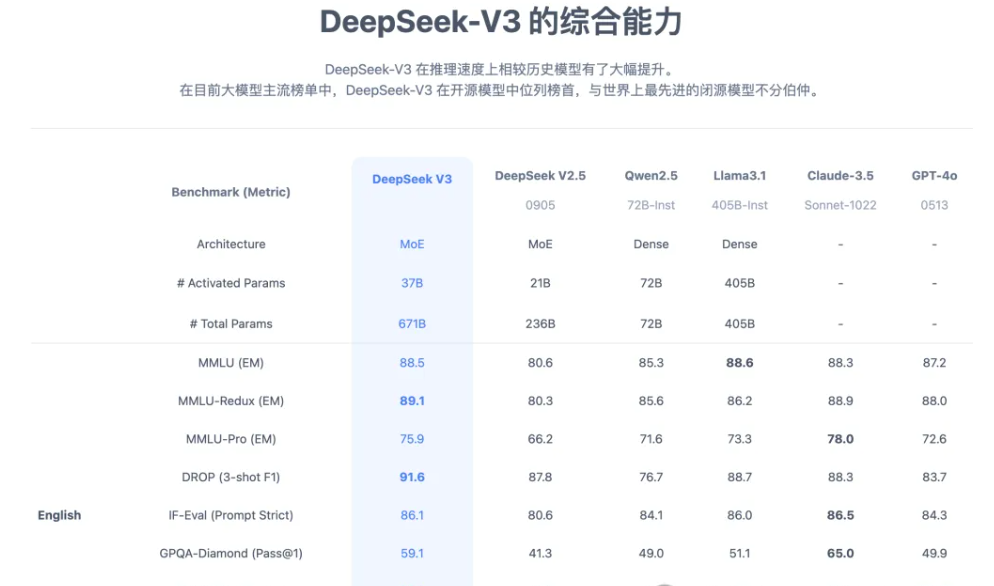
DeepSeek V3 架构图
DeepSeek-R1是一个大型混合专家(MoE)模型。它包含了令人印象深刻的6710亿个参数——比许多其他流行的开源LLM多10倍——支持128000个Token的大输入上下文长度。
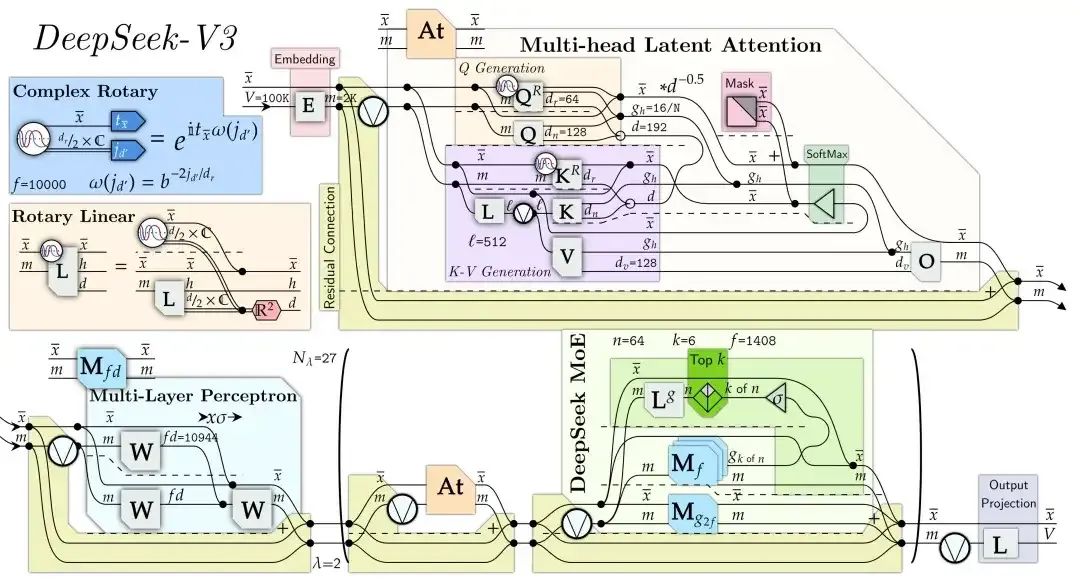
该模型还在每个层中使用了极多的专家。R1的每一层都有256位专家,每个Token并行路由到八个不同的专家进行评估。
英伟达网站介绍称,DeepSeek-R1模型是最先进、高效的大型语言模型,在推理、数学和编码方面表现出色。
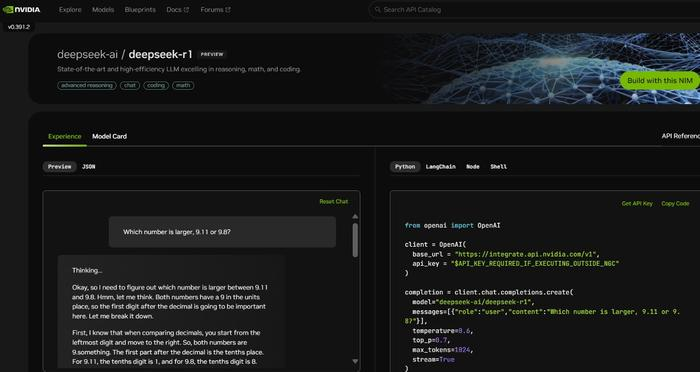
据说,在性能优化上,DeepSeek-R1的技术创新在于开发了GRPO算法以优化策略网络,避免了高计算开销,同时设计了多层次奖励机制和“思考-回答”双阶段训练模板,确保模型推理的高效性

如今的DeepSeek,他的开源,让AIGC又前进了一步。可以这么说,他它早已不是什么“副业”,尽管一些媒体仍然这样描述。即便考虑到美国出口管制因素,他们在GPU方面的投资已超过 5亿美元(约35亿元人民币)。
开源使得中小企业和个人开发者能够以1%的成本部署顶级AI模型,想象一下,如果每个人都能用DeepSeek的技术,创造出自己的“智能工具”,那这个世界会变得多么智能、多么高效。
对于是否开源,奥特曼的回复更像是罪己诏,贪婪虚伪的小人嘴脸。开源又闭源进行商业化的产品大多命运多舛,这个也算是冥冥之中自有定数。
看来国内的创造力还是数一数二的。

回复 【idea激活】即可获得idea的激活方式
回复 【Java】获取java相关的视频教程和资料
回复 【SpringCloud】获取SpringCloud相关多的学习资料
回复 【python】获取全套0基础Python知识手册
回复 【2020】获取2020java相关面试题教程
回复 【加群】即可加入终端研发部相关的技术交流群
阅读更多
一款vue编写的功能强大的swagger-ui,有点秀(附开源地址)
相信自己,没有做不到的,只有想不到的
在这里获得的不仅仅是技术!


喜欢就给个“在看”


















 594
594

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











