




大家好,我是斜杠君。
👨💻 最近有很多同学想让我写一篇小红书健康养生赛道图文生成的教程,使用工作流可以批量生成图文。
今天斜杠君就带大家一起搭建一个智能体,可以快速批量的生成健康养生赛道的图文内容。
工作流智能体作用:
输入一个主题,例如「湿气越吃越少10种食物」或者「易瘦体质的8个习惯」等健康类主题,工作流自动批量生成图文。
首先我们来看一下生成图文的效果:


🎥 本期视频教程已上传至知识星球,有更详细的代码和提示词,欢迎大家加入和斜杠君学习,🧑🚀还有星球VIP群和大家一起讨论噢~
🤹 接下来,话不多说,斜杠君用最简单的方式教给大家。💖大家可以关注收藏,以免之后找不到,而且也不会错过我后面的教程。
一、创建工作流
1、首先新建一个工作流。
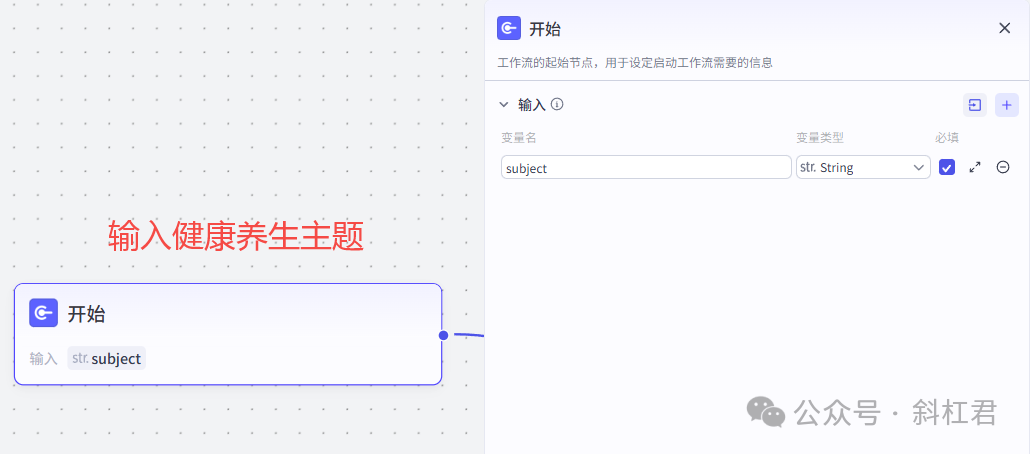
2、开始节点
开始节点设置一个变量,输入健康养生主题。
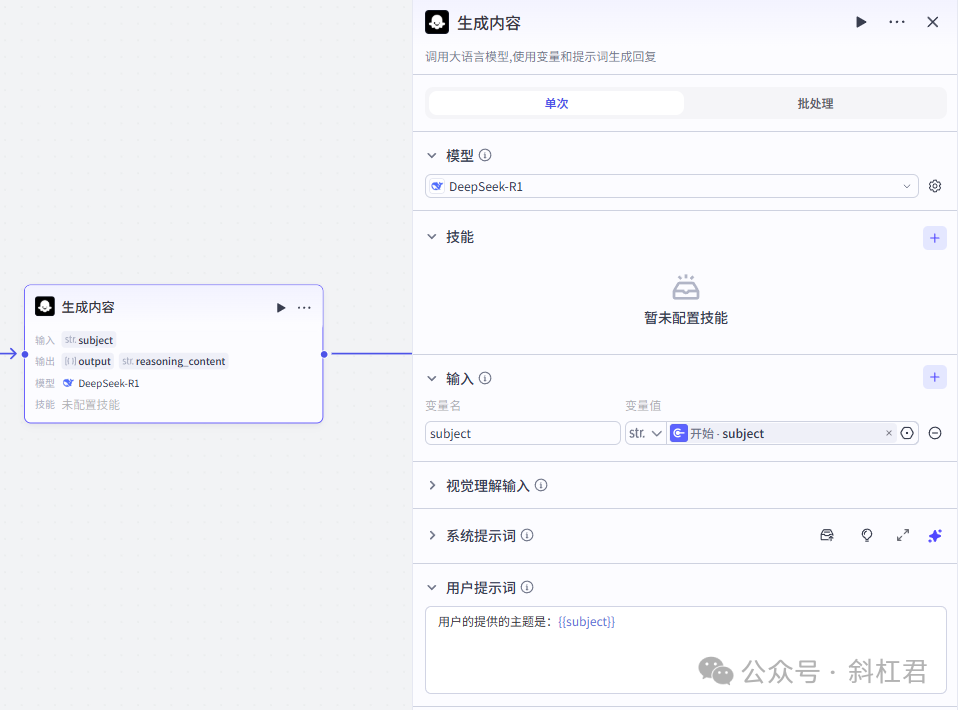
3、大模型节点
使用Deepseek-R1模型为需要生成的图文准备内容。
注意,这里大模型输出的内容要是一个json格式的数组对像,方便后面的批处理节点进行调用。
之前有很多同学提问,为什么批处理节点引用不到大模型节点输出的内容,就因为批处理节点的输入变量需要是一个数组,如果不是数组的话,是引用不到的。
4、批处理节点
批处理节点的作用是引用大模型节点输出的内容,批量生成图片。
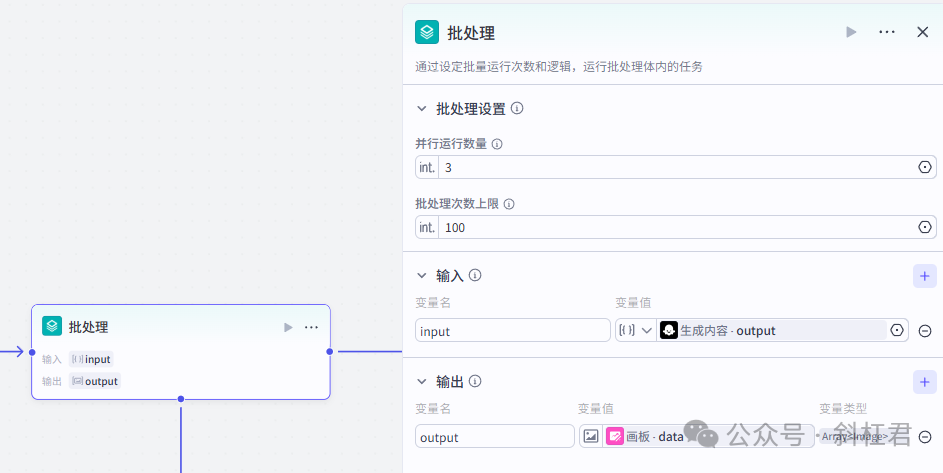
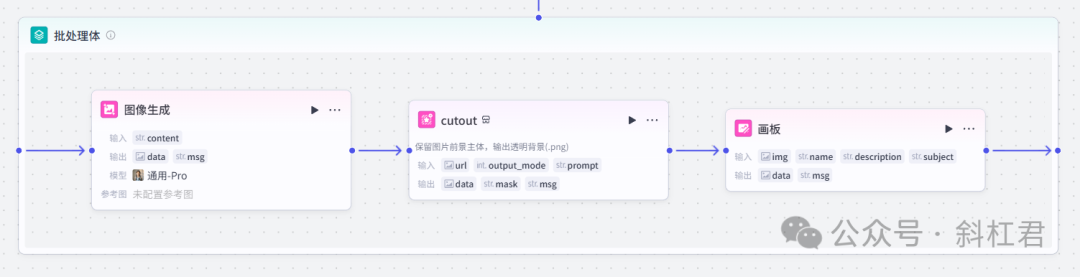
5、批处理体
批处理体中使用了三个图像插件用来处理图片。
分别是图像生成,抠图插件和画板。
画板用来把内容组合成最后的图文内容。
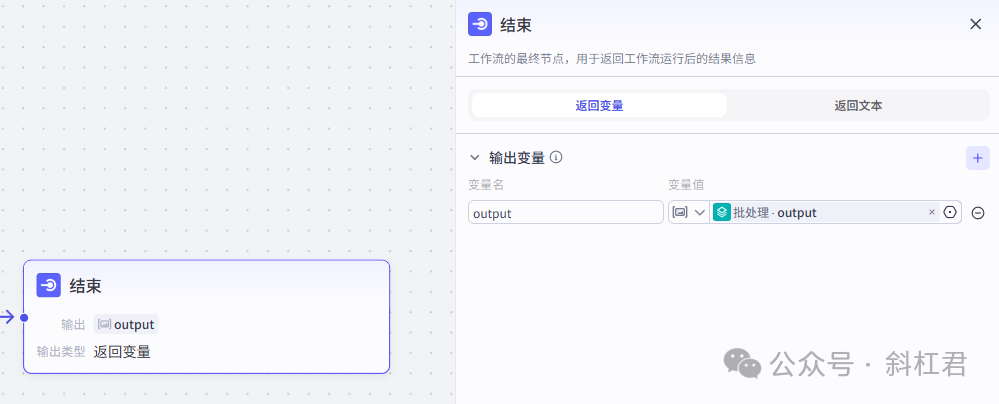
6、结束节点
结束节点用来把「批处理节点」生成的图文内容进行输出,输出的内容是一个图片的数组。
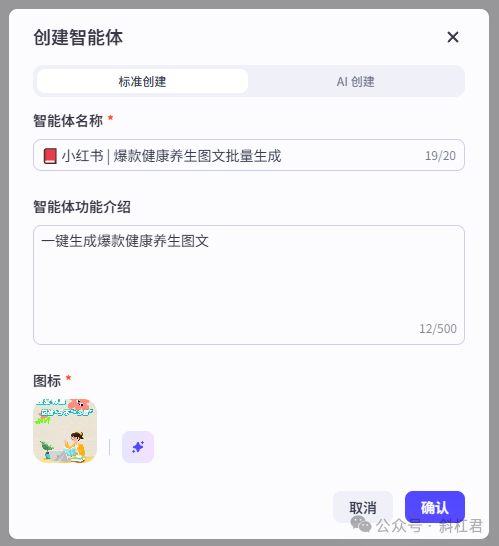
二、创建智能体
1、创建一个智能体
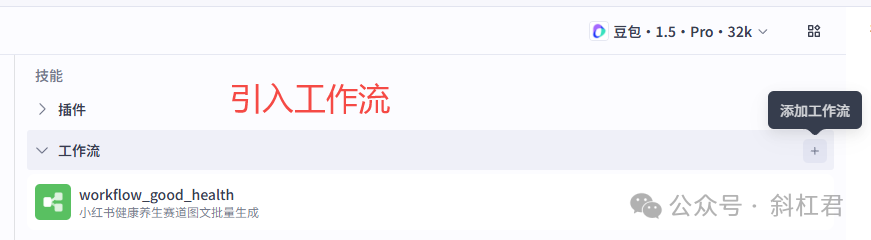
2、引入工作流
3、绑定卡片
绑定一个卡片,用来显示工作流输出的图片。
关于卡片的使用和绑定方法,可以参考以下这篇教程:
👉️ 点击这里查看:最新扣子(Coze)实战案例:卡片系列教程之图片列表卡片,卡片的使用详细讲解,手把手教学,完全免费教程
3、效果展示
到这里,小红书健康养生图文的智能体就搭建好了,大家快动手试试吧~
🎥 本期视频教程已上传至知识星球,有更详细的代码和提示词,欢迎大家加入和斜杠君学习,🧑🚀还有星球VIP群和大家一起讨论噢~
💖大家可以关注收藏,以免之后找不到,而且也不会错过我后面的教程噢~
原文地址_加入免费扣子学习群:最新扣子(Coze)案例教程:爆款小红书健康养生赛道图文,Deepseek+Coze工作流,3分钟批量生成100篇,完全免费教程


















 503
503

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









