






大家好,我是有思。最近大家刷短视频自媒体的时候,是不是经常看到很多动漫卡通类、情感文案类的图文,就如下面这种图非常多,最重要的是用户觉得不错,点赞评论收藏更是满满。


漫画卡通人物搭配有趣的文案,看起来非常可爱有趣。大家看图片不难发现,很多应该都是AI生成的,现在我教大家一个简易版的制作方法,使用扣子Coze制作。
打开扣子Coze,工作空间——资源库。
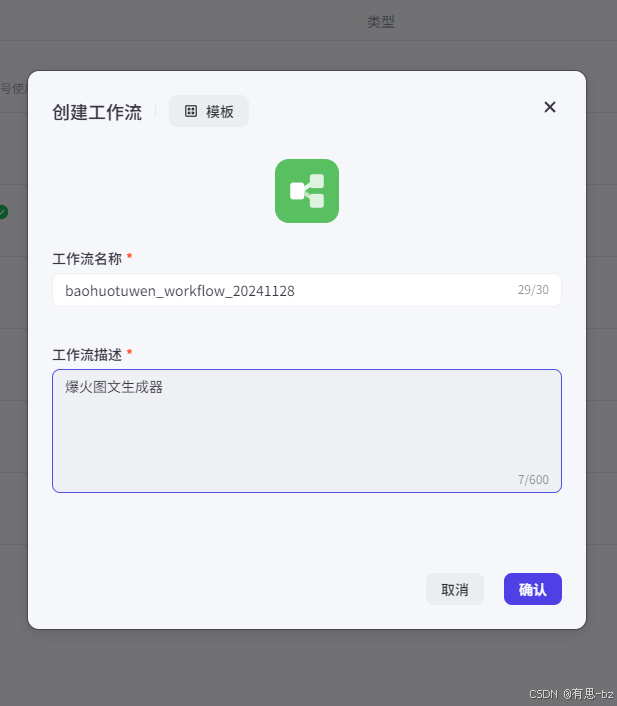
右上角资源,创建一个工作流。
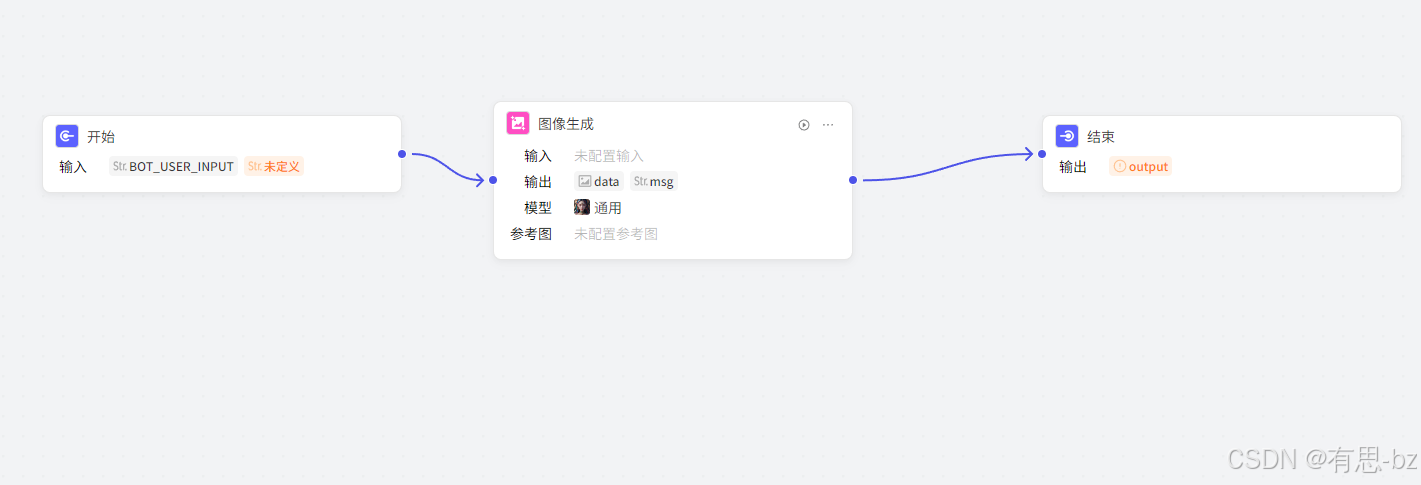
选择图片生成,将开始,结束,图片生成节点串联。
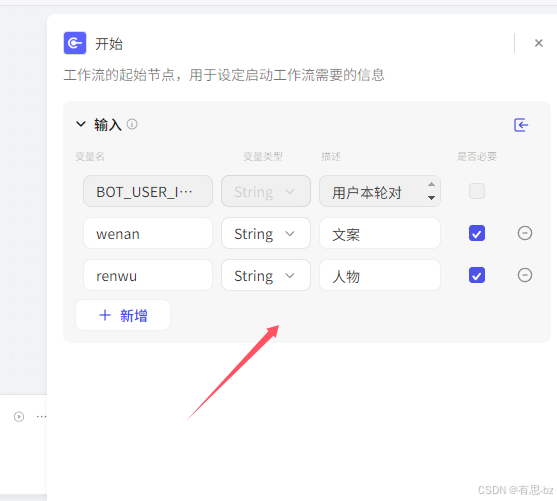
开始节点新增2个变量,一个wenan,一个renwu:
图像生成节点中设置模型,输入参数,引用开始的renwu,正向提示词{{input}}。
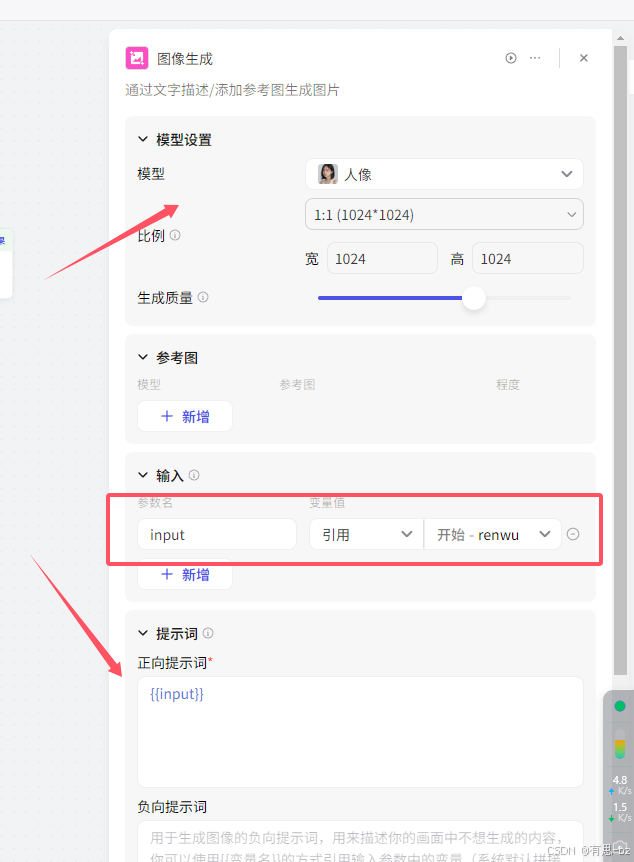
再添加一个画板,将图片和文字结合。
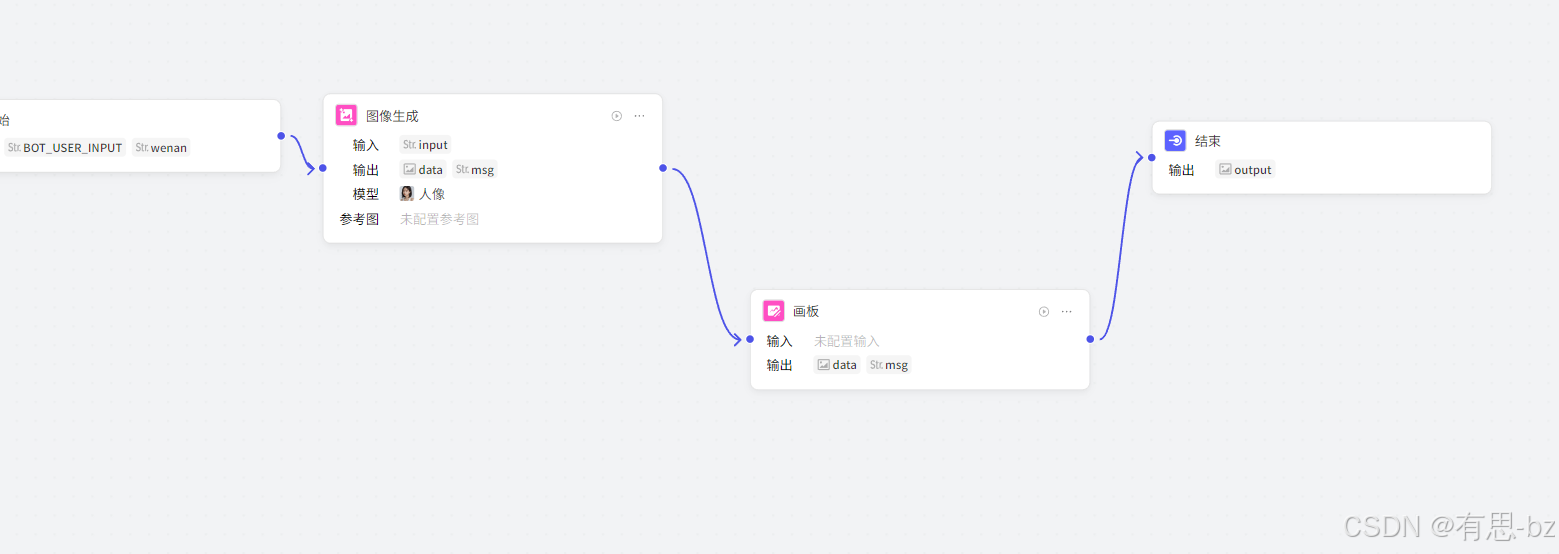
重新调整节点,将图像生成——画板——结束串联,流程在脑海中过一遍。
画板设置,引入文案和图片元素,在画板中可以看到
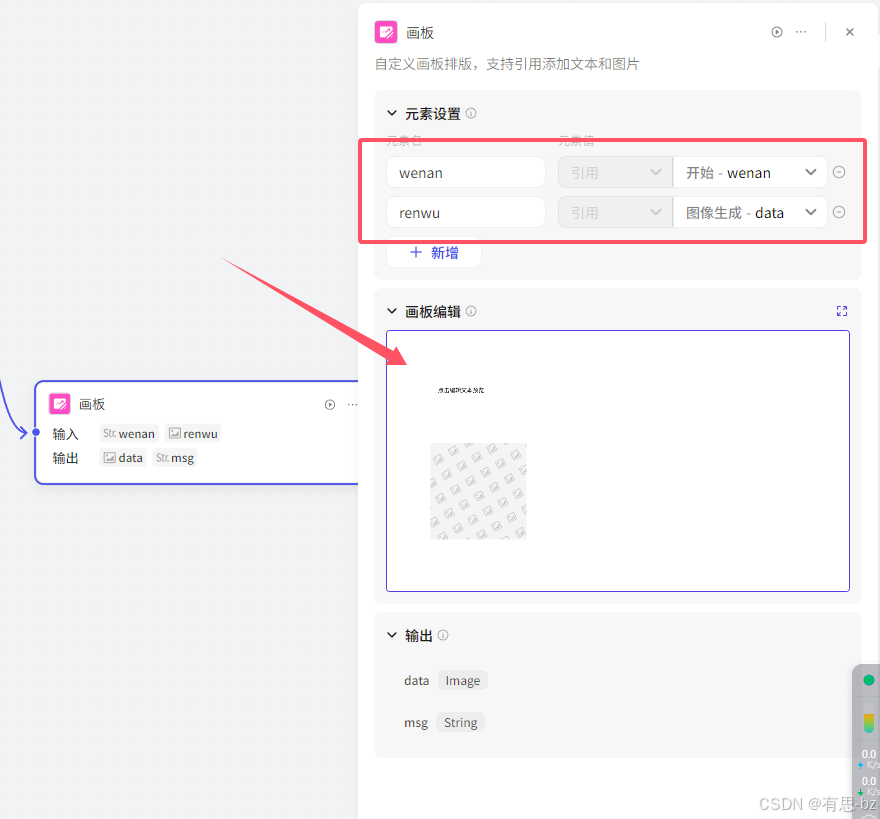
双击画板编辑,在窗口中调整画板大小,字体大小等等:
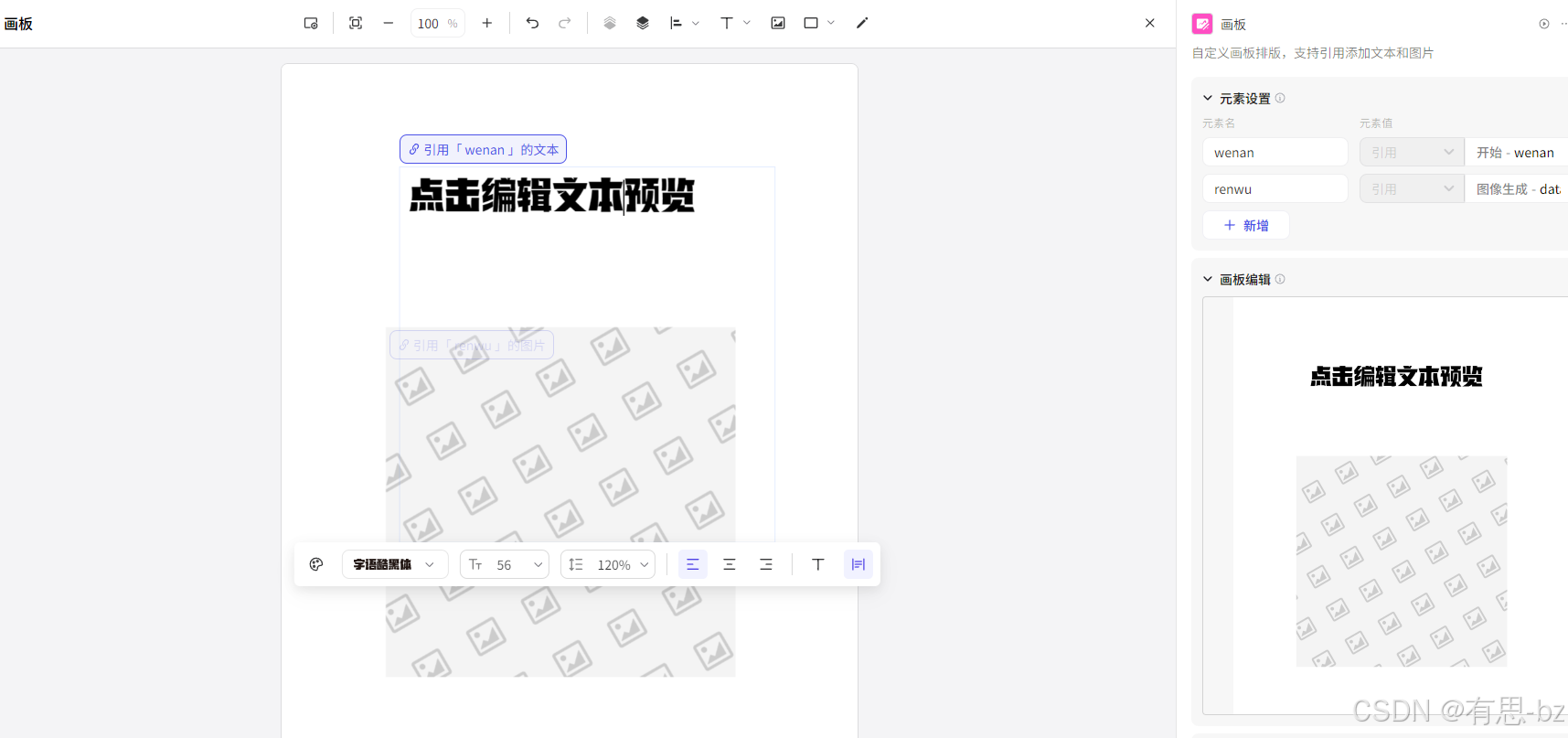
结束节点引入画板data,完成输出操作。

最后试运行,我们输入图片人物描述:一个慈祥的老爷爷;文案内容:小朋友,记住,你是去上班的,不是去受气的。
完整流程跑完如下图:
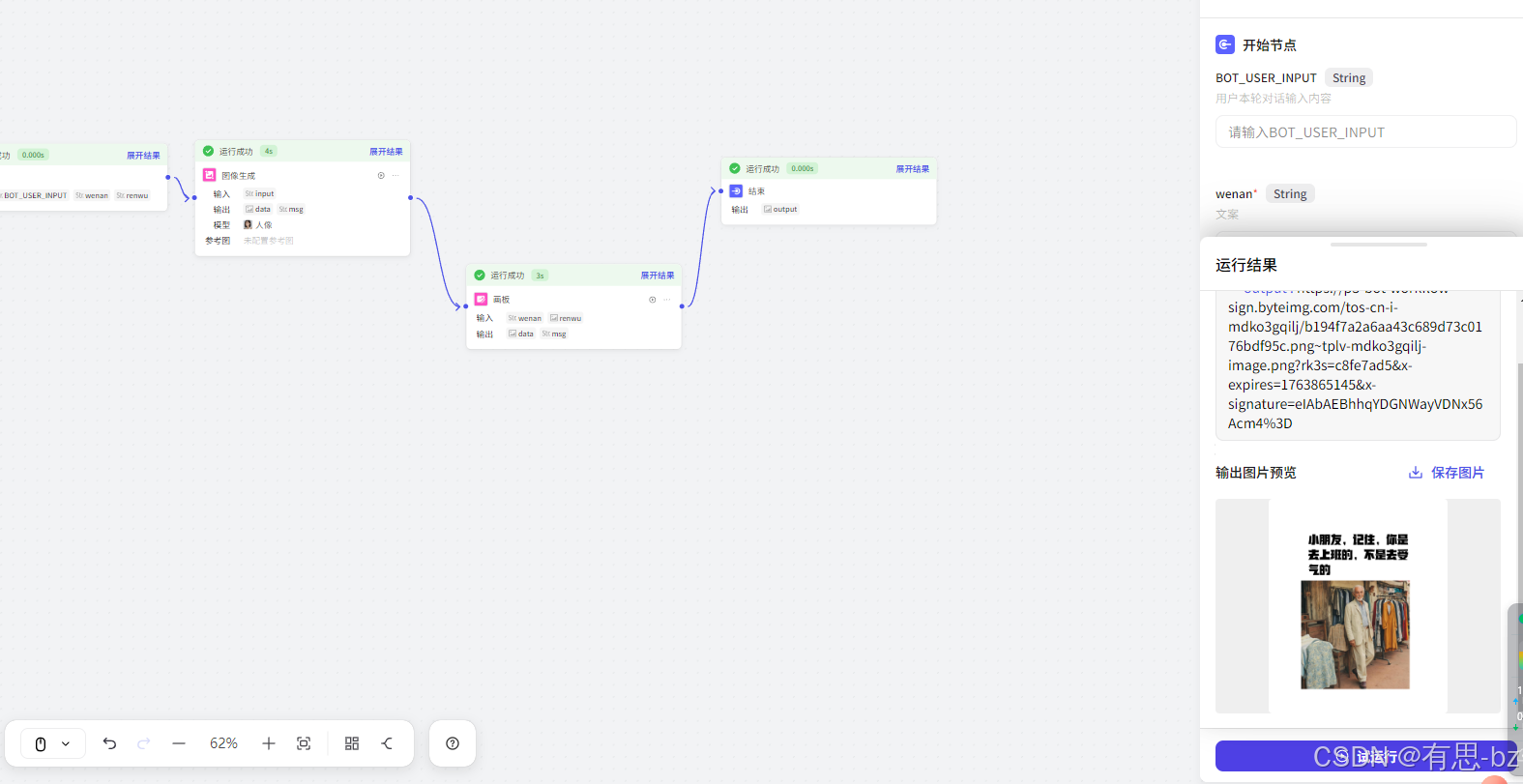
点击看到我们的结果图文结合。这是一个demo示例,想要更好的效果,大家可以自行调优提示词,这样效果才能符合我们的心理预期。

除此之外,我在小绿书——【花漾时光记】中有很多作品,里面的内容是通过AI文生图、图文的方式做出来的,看起来效果不错,有想要学习的朋友,可以看一下。感谢大家支持!


















 220
220

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









