






Generative models
Supervised vs. Unsupervised
Discriminative Model vs. Generative Models vs. Conditional Generative
Discriminative: only label compete for probability mass, no competition between images
Generative: images compete with each other for probability mass
usage
Discriminative:
- Feature learning
- Assign labels to data
Generative:
- detect outliers
- feature learning
- sample to generate new data
Conditional Generative:
- assign labels while rejecting outliers
- generate new data conditioned on input labels
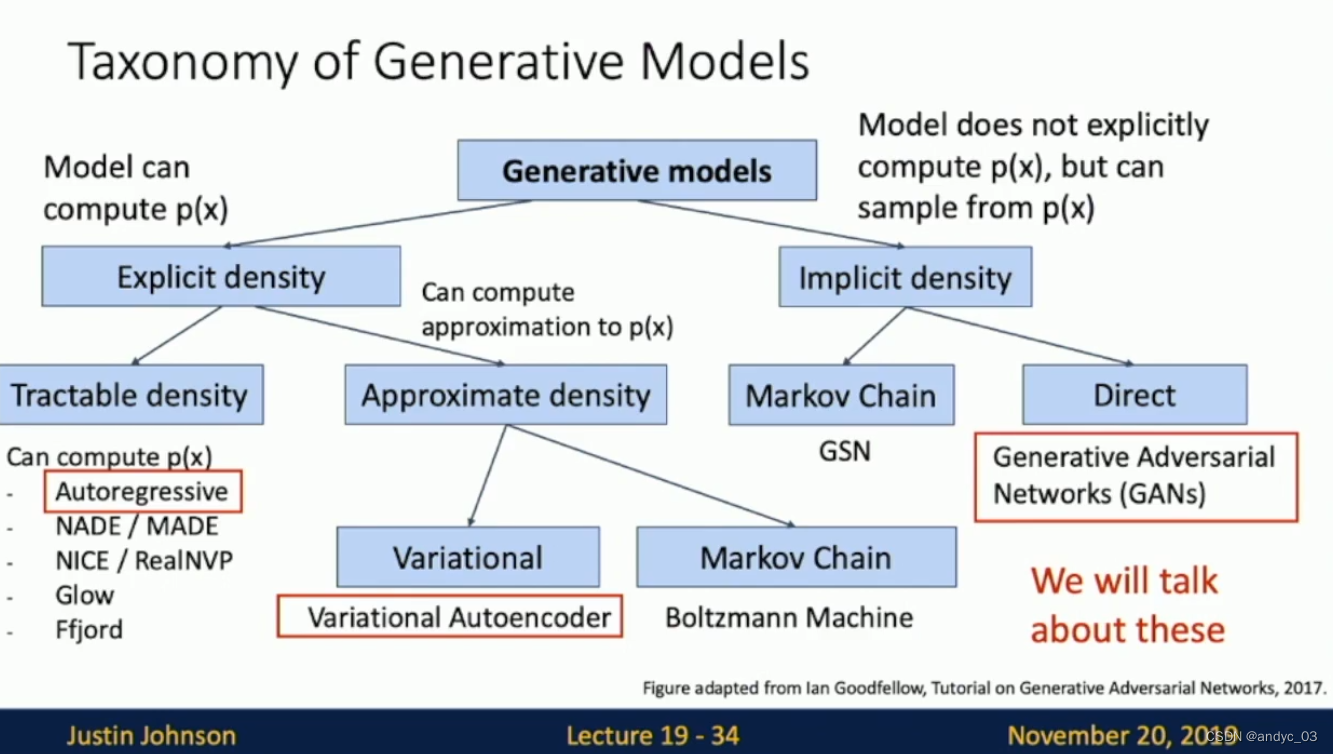
Autoregressive
Goal: Write down an explicit function for p ( x ) = f ( x , W ) p(x) = f(x,W) p(x)=f(x,W)
We can break down the probability function to get p ( x ) = p ( x 1 , x 2 , . . . , x T ) = Π t = 1 T p ( x t ∣ x 1 , x 2 , . . . x t − 1 ) p(x) = p(x_1,x_2,...,x_T) = \Pi_{t=1}^Tp(x_t|x_1,x_2,...x_{t-1}) p(x)=p(x1,x2,...,xT)=Πt=1Tp(xt∣x1,x2,...xt−1)
We can use RNN to train a density function
PixelRNN
generate image pixels one at a time, staring at the upper left corner
compute a hidden state for each pixel that depends on hidden state and RGB values from the left and above (LSTM recurrence)
h x , y = f ( h x − 1 , y , h x , y − 1 , W ) h_{x,y} = f(h_{x-1,y},h_{x,y-1},W) hx,y=f(hx−1,y,hx,y−1,W)
At each pixel, predict red, then blue, then green
Each pixel depends implicitly on all pixels above and to the left
Problem: Really slow both training and testing
PixelCNN
Dependency on previous pixel now modeled using a CNN over context
on new CIFAR images
Autoregressive Models: PixelRNN/CNN
Pros:
- can explicitly compute likelihood
- gives good evaluation metric
- good samples
Cons:
- sequential generation -> slow
Variational Autoencoders
VAE define an intractable density.
we can optimize a lower bound on this density instead.
(non-variational) Autoencoders
Features should extract useful information that can use for downstream tasks
Problem: how can we learn this feature transform from raw data?
idea: use the features to reconstruct the input data with a decoder
loss: L2 distance between input and reconstructed data
Variational Autoencoders
- learn latent features z from raw data
- sample from the model to generate new data

How to train this model: maximize the likelihood of data
However, we can’t get full access to all the x
so, we need to find a computable lower bound of the likelihood
Hopefully, with the growing of lower-bound, the real likelihood will increase

Process:
- run input data through encoder to get a distribution over latent codes
- encoder output should match the prior p ( z ) p(z) p(z)
Here, we assume the distribution we learn and the prior p ( z ) p(z) p(z) are both diagonal Gaussian distribution for computational convenience.
- sample code z from encoder output
- run sampled code through decoder to get a distribution over data samples
- original input data should be likely under the distribution output from step 4
Step 2, 5 are the two terms of loss we try to minimize
Generative Adversarial Networks
Setup: Assume we have data x x x drawn from distribution p d a t a ( x ) p_{data}(x) pdata(x). We want to sample from p d a t a ( x ) p_{data}(x) pdata(x).
Idea: Introduce a latent variable z with simple prior p ( z ) p(z) p(z).
sample z from p ( z ) p(z) p(z) and pass to a Generator Network x = G ( z ) x = G(z) x=G(z)
Then x is a sample from the generator distribution p G p_G pG , we want p G = p d a t a p_G = p_{data} pG=pdata
We train the Generator Network to convert z into fake data x sampled from p G p_G pG
by fooling the discriminator D
Train D to classify data as real or fake
We will train the two networks jointly, they are fighting against each other.
loss

problem: At the beginning of training, vanishing gradients for G
solution: change minimize log(1-D(G(z))) to maximize -log(D(G(z))) then G gets strong gradients at the beginning of training ! nice idea
We can do some math calculations to prove GAN can get the optimal p d a t a p_{data} pdata.
But there are still caveats about the capability of our fixed architecture to reach the optimal and its convergence.
DC-GAN
interpolating between points in latent z space
We can even do latent vector math!
Conditional GANs
we can use conditional Batch Normalization
learn parameters for different labels
Spectral Normalization
we can generate images in specific labels
…















 2062
2062

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









