






YOLO的有点(摘自YOLO原文):
1、YOLO检测框架速度非常快,Tian X可以达到45帧/s,
2、比起其他实时检测框架具有更高的精度
3、背景检测错误低
4、对艺术图像依然有很好的检测效果
缺点:
检测精度比低于当前最好的检测框架
统一检测:
1、将图像分成S*S的网格,物体中心落在某一个网格中,则该网格负责预测该物体
2、每一个网格对预测B个边框和置信度,若网格中没有目标则置信度输出为0
3、每个边框包括5个预测值:x,y,w,h和confidence. 其中x,y表示相对于网格的边框中心,w,h是归一化后的边框长和宽,confidence是置信度
4、每个网格单元还需要预测C个类别信息的概率,表示一个网格单元包含目标的概率
5、文中设定每个网格预测B个边框,讲网格划分为7*7的大小,VOC数据集上有20个类别,因此每个网格单元需要预测20个类别概率
网络设计
1、卷积层负责提取图像特征,全连接层负责预测输出的概率和坐标
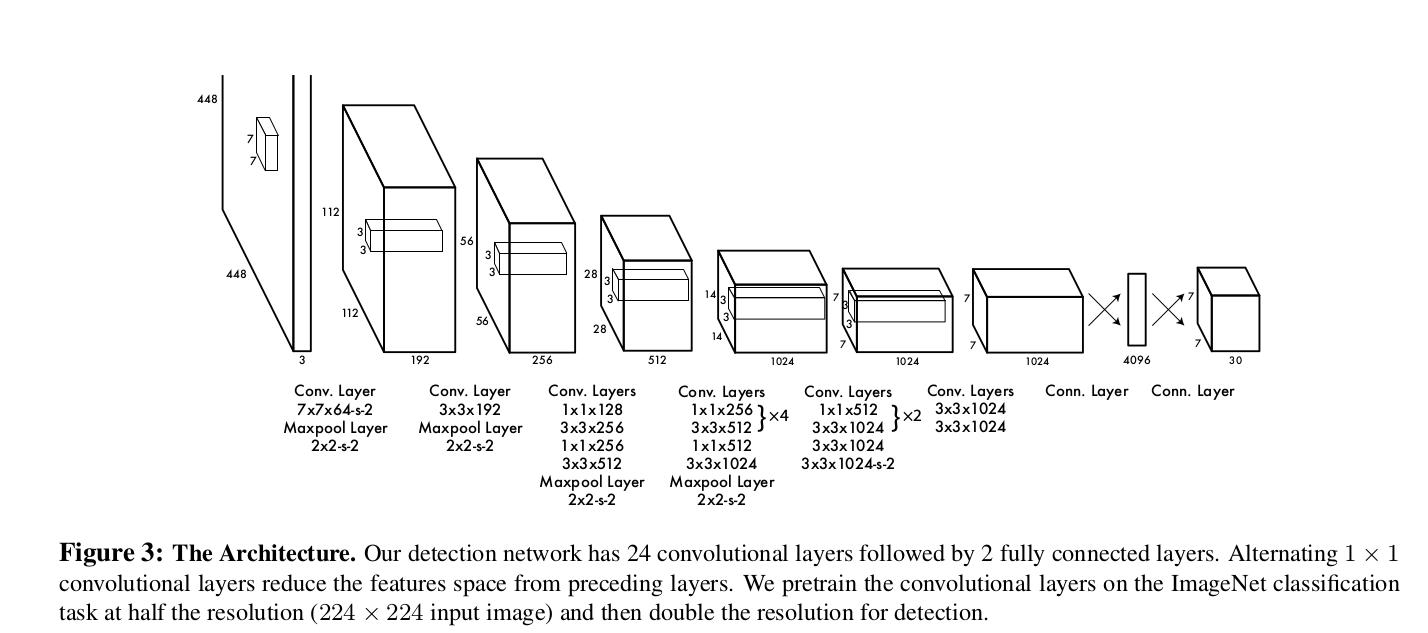
2、网络由24个卷积层和2个全连接层组成,网络结构如下图所示:
训练网络
1、使用ImageNet一千类的数据对网络进行了与训练,网络输入为448*448
2、网络最后一层负责预测类别概率和边框的坐标,边框的宽和高通过使用了输入图像宽和高进行了归一化处理。(x,y)是归一化后网格位置的偏移
3、网络最后一层使用了现行激活函数,其他层使用的系数为0.1的liaky ReLU激活函数
4、使用平方误差对网络进行优化,因为平方误差容易优化,但是平方误差存在的问题是:8维的信息坐标和20为的类别概率被认为是同等重要,这并不是理想的处理方式。并且网格中可不能不包含目标,这将导致置信度为零,在训练初期可能导致网络发散。因此通过设置两个参数来纠正这个问题,增加8维的信息坐标的权重
5、每个网格负责预测B个bounding boxes,而在训练的过程中,只需要IOU最大的那个预测
6、损失函数如下图所示:

YOLO 的缺点:
1、如果两个物体落在同一个网格单元,YOLO模型只能预测出一个目标结果
2、对训练集中不包含的长宽比检测效果比较差















 316
316

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









