







目录
redis 的作用
redis安装与登录
- 默认安装目录:usr/local/bin
- 在redis存放的目录,备份原系统的 redis.conf,新建一个 redis.conf
- 修改配置文件内容如下
1 默认daemonize no 改为 daemonize yes
2 默认protected-mode yes 改为 protected-mode no
3 默认bind 127.0.0.1 改为 直接注释掉(默认bind 127.0.0.1只能本机访问),否则影响远程IP连接
4 添加redis密码 改为 requirepass 你自己设置的密码
-
启动redis,并登录
- 在安装目录:usr/local/bin下执行
redis-server 自定义配置文件的路径启动redis服务 - 默认的redis服务端口是6379(可改)
- 紧接着输入
redis-cli -a 配置文件中设置的requirepass的值orredis-cli -a 配置文件中设置的requirepass的值 -p redis端口号 - 中文乱码问题,只需要在上面的登录指令后面加上
--raw
- 在安装目录:usr/local/bin下执行
-
退出登录
- 退出从客户端
quit后,可以关闭redis服务redis-cli -a requirepass 的值 shutdownorredis-cli -p 6379 shutdown - 或者直接在客户端输入
shutdown,然后再退出quit
- 退出从客户端
redis 持久化
RDB(Redis DataBase)
-
什么是RDB
- 在指定的条件下对redis中的所有键值对数据以快照的形式保存到磁盘中,形成dunmp.rdb文件
-
启动/关闭RDB:修改配置文件 redis.conf 根据配置文件中提示(配置文件中的SNAPSHOTTING模块)修改
- 关闭:
save “”or 登录redis客户端reids-cli config set save "" - 启动:
save 60 1000只要60s内,有超过1000个key发生改变,则开始产生快照
- 关闭:
-
RDB 其它配置项
dbfilename生成的 rdb 文件的名字dir生成的rdb文件的存放目录stop-writes-on-bgsave-error yes/no用于保证数据一致性,当备份过程中出现问题是否停止写入,默认是yesrdbcompressiong yes/nordb文件的压缩存储,默认为开启yesrdbchecksum yes/no存储快照后是否用CRC64算法来进行数据校验,默认开启yesrdb-del-sync-files在没有持久性的情况下删除主从复制中使用的RDB文件,默认情况下no,此选项是禁用的
-
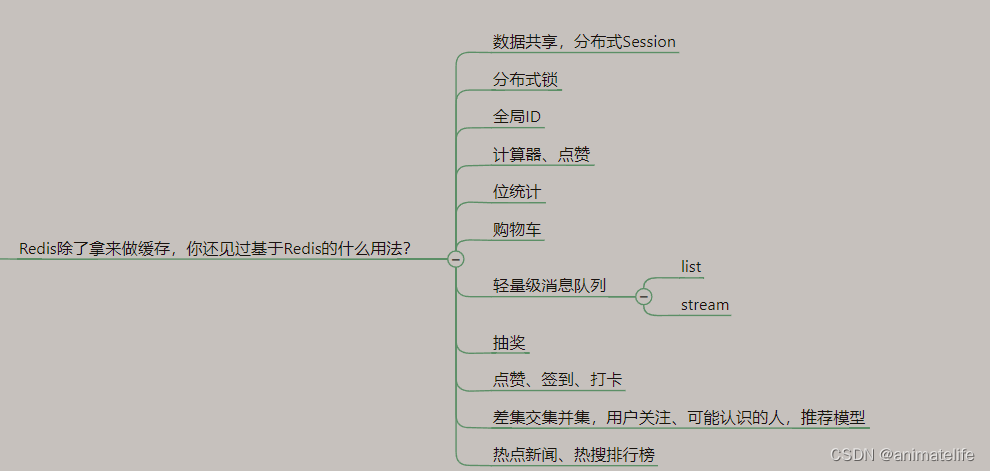
触发RDB的情况(redis 回写)

-
关于
save/bgsave命令save不建议使用(同步回写)

bgsave命令(默认,异步回写)
-
RDB优势

-
RDB 劣势(数据丢失)

-
修复RDB文件
redis-check-rdb rdb文件命
AOF(Append Only File)

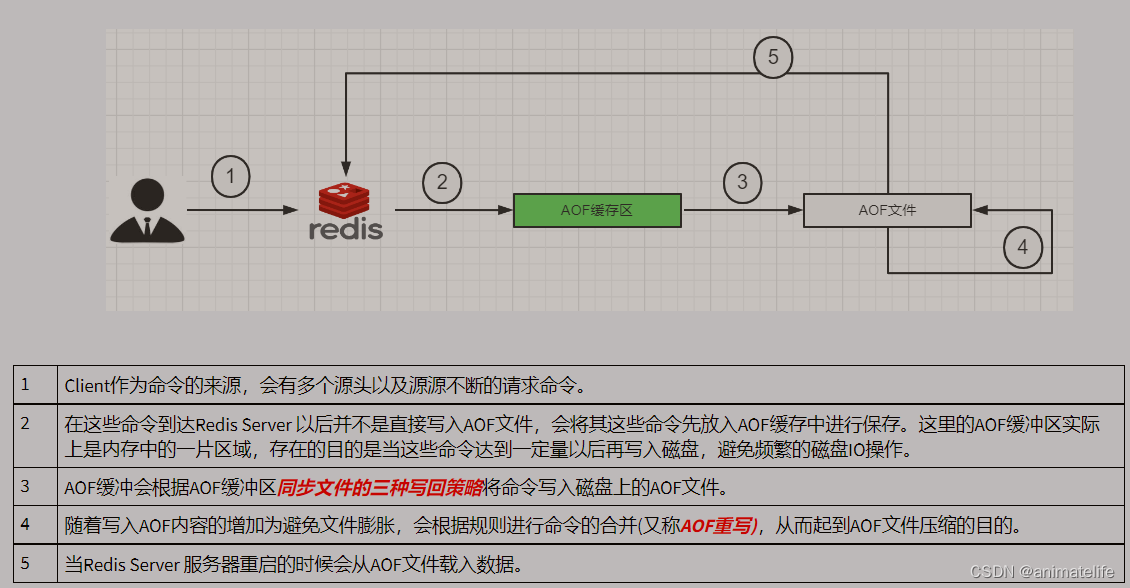
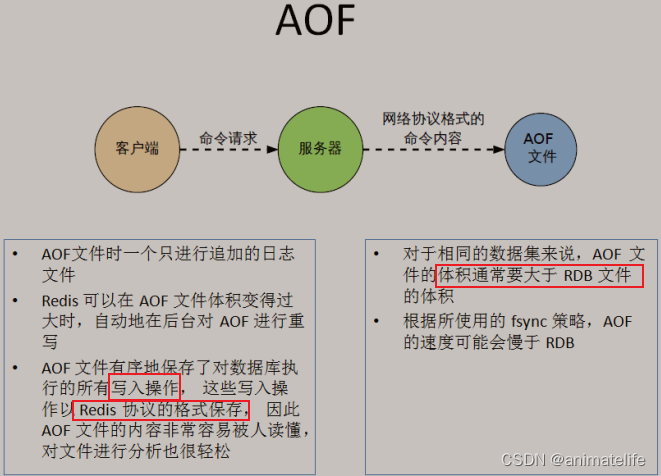
- AOF 的工作流程
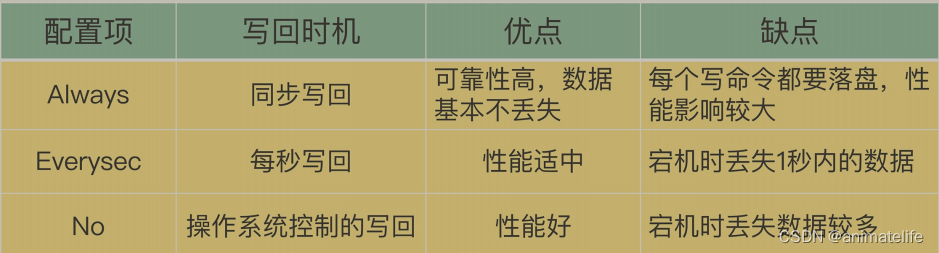
- 三种写回策略对比(推荐使用Everysec)
- AOF的配置(配置文件的APPEND ONLY MODE模块中)
- 启动配置
appendonly yes,默认是关闭no - 写回策略配置
appendfsync everysec,默认是每秒 - AOF 重写机制设置,改变如图所示三项
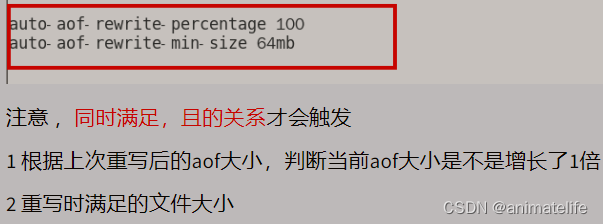

.aof文件的保存目录 = rdb 的保存目录(dir) /自定义的.aof文件目录(appenddirname "xxxxx")- 设置
.aof文件的保存文件名- redis 6 及之前的
.aof文件只有一个 - redis 7 及之后的
.aof文件有3个
appendfilename "appendonly.aof"配置的是.aof文件的前缀,后面还要跟redis 设置的有关序列和类型的附加信息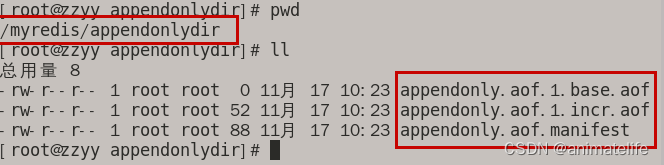
- 关于 序列 涉及到 AOF 的重写机制,重写就是当一个
.aof文件太大时,需要执行的操作
- redis 6 及之前的
- 启动配置
- AOF 的重写机制


!
- 重写过程展示
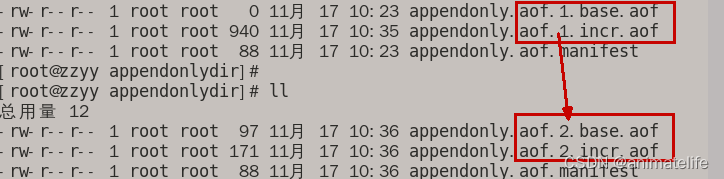

- 重写过程展示
- AOF 的紧急恢复
- AOF 记录的都是写指令,所以当不小心使用了
flushdb,只要 AOF 文件没有发生重写,就可以通过手动删除 AOF 文件中的flushdb,然后重启redis 服务就能恢复数据 - AOF 文件的修复
redis-check-aof --fix 增量AOF文件名
- AOF 记录的都是写指令,所以当不小心使用了
- AOF总结

RDB-AOF混合持久
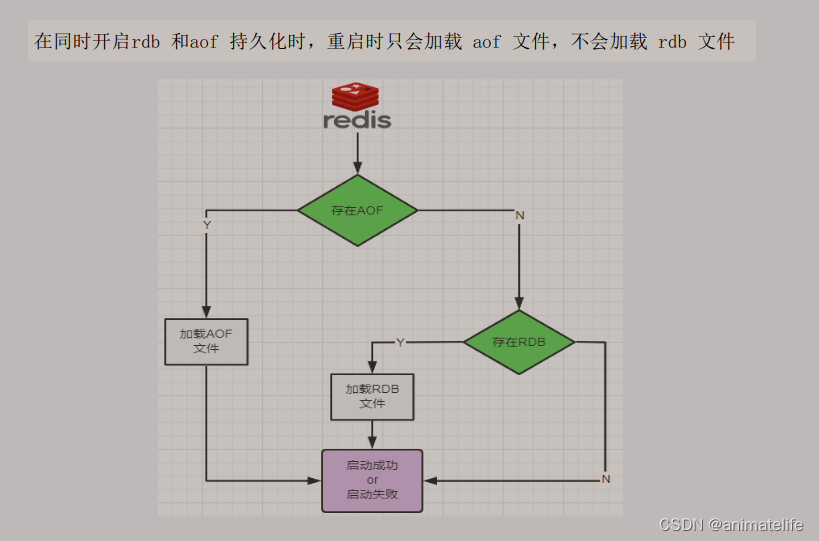


纯缓存模式
- 同时关闭 RDB、AOF
redis 的 key

redis 的数据类型和常见应用场景
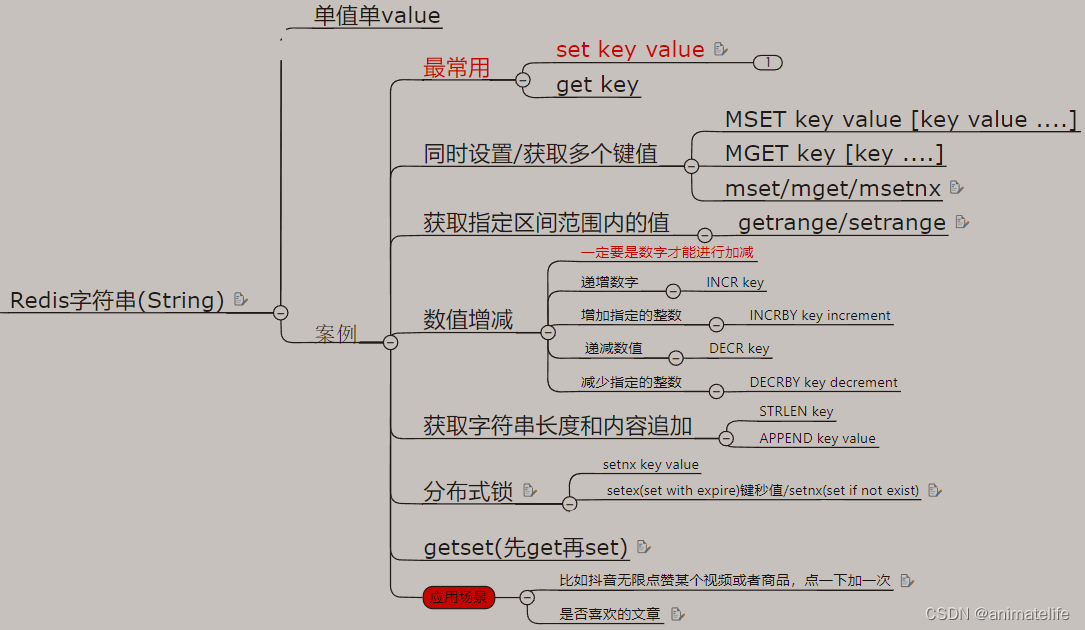
String
List
- 当涉及到范围时,起始为0,终止是-1时,表示整个 list 范围
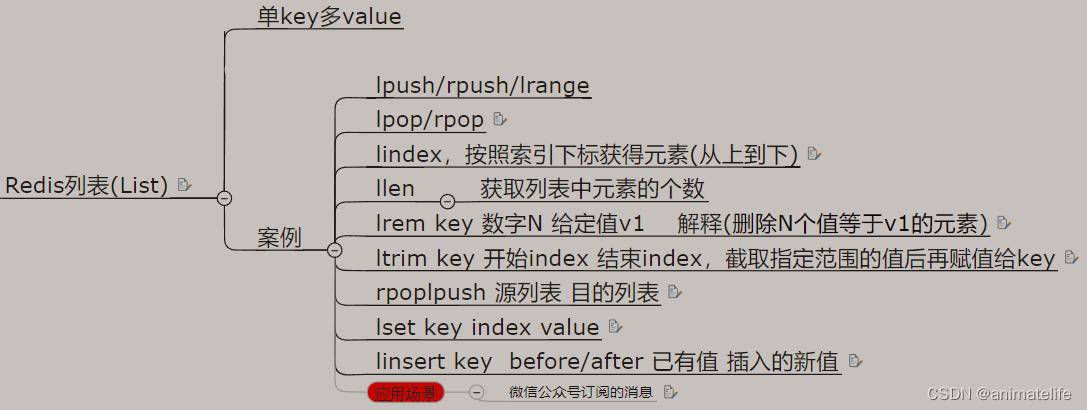
- 应用场景:分页数据的缓存
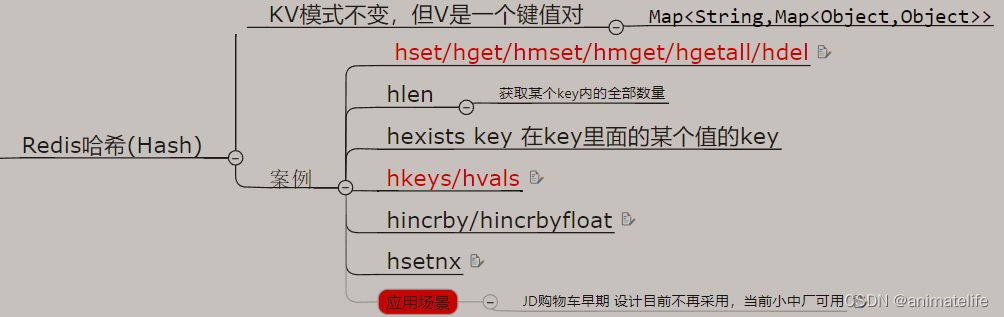
HashMap
Set集合

ZSet有序集合

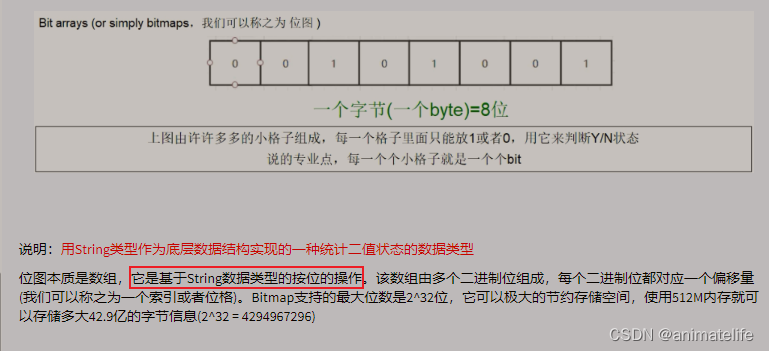
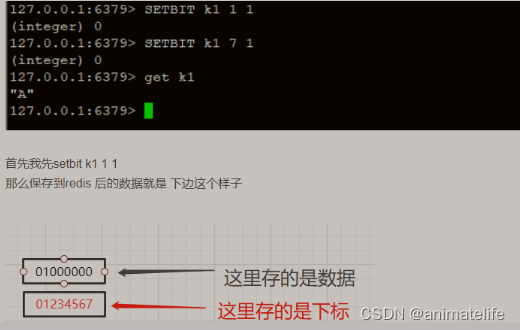
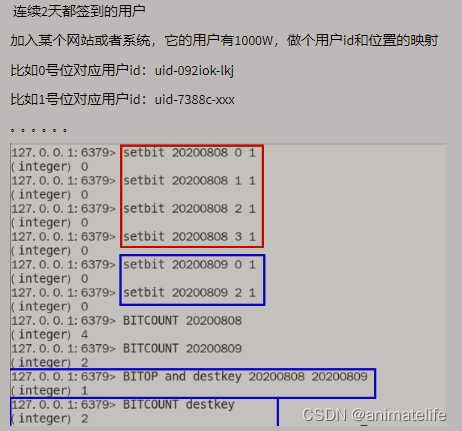
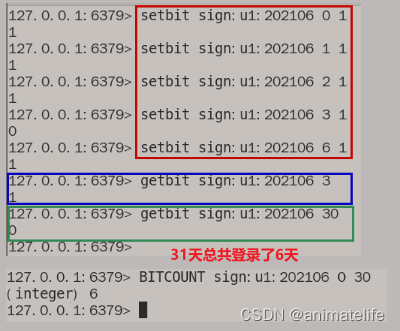
bitmap 位图
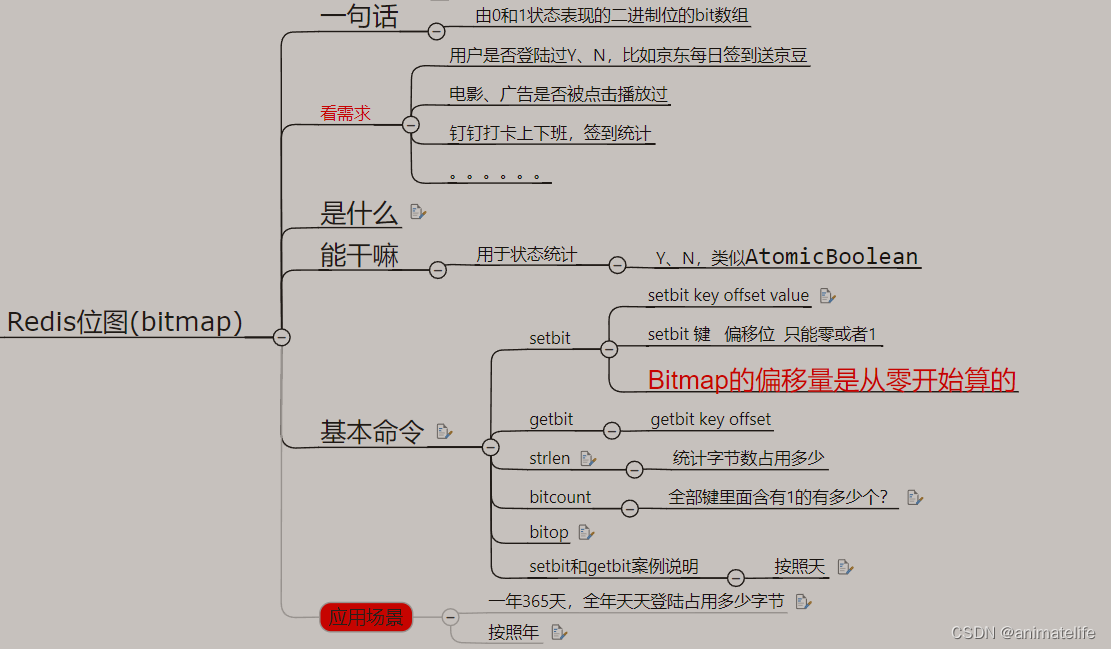
- bitmap 底层的编码是 Ascii



HyperLogLog 基数统计
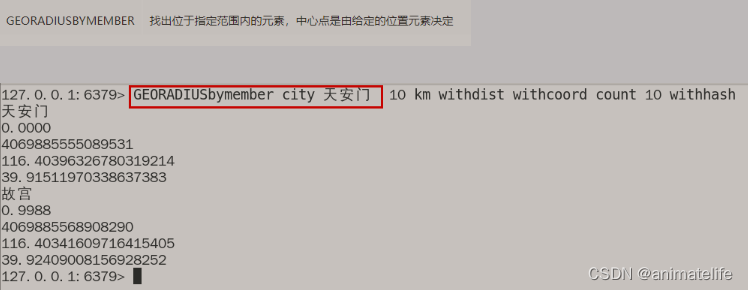
GEO 地理空间
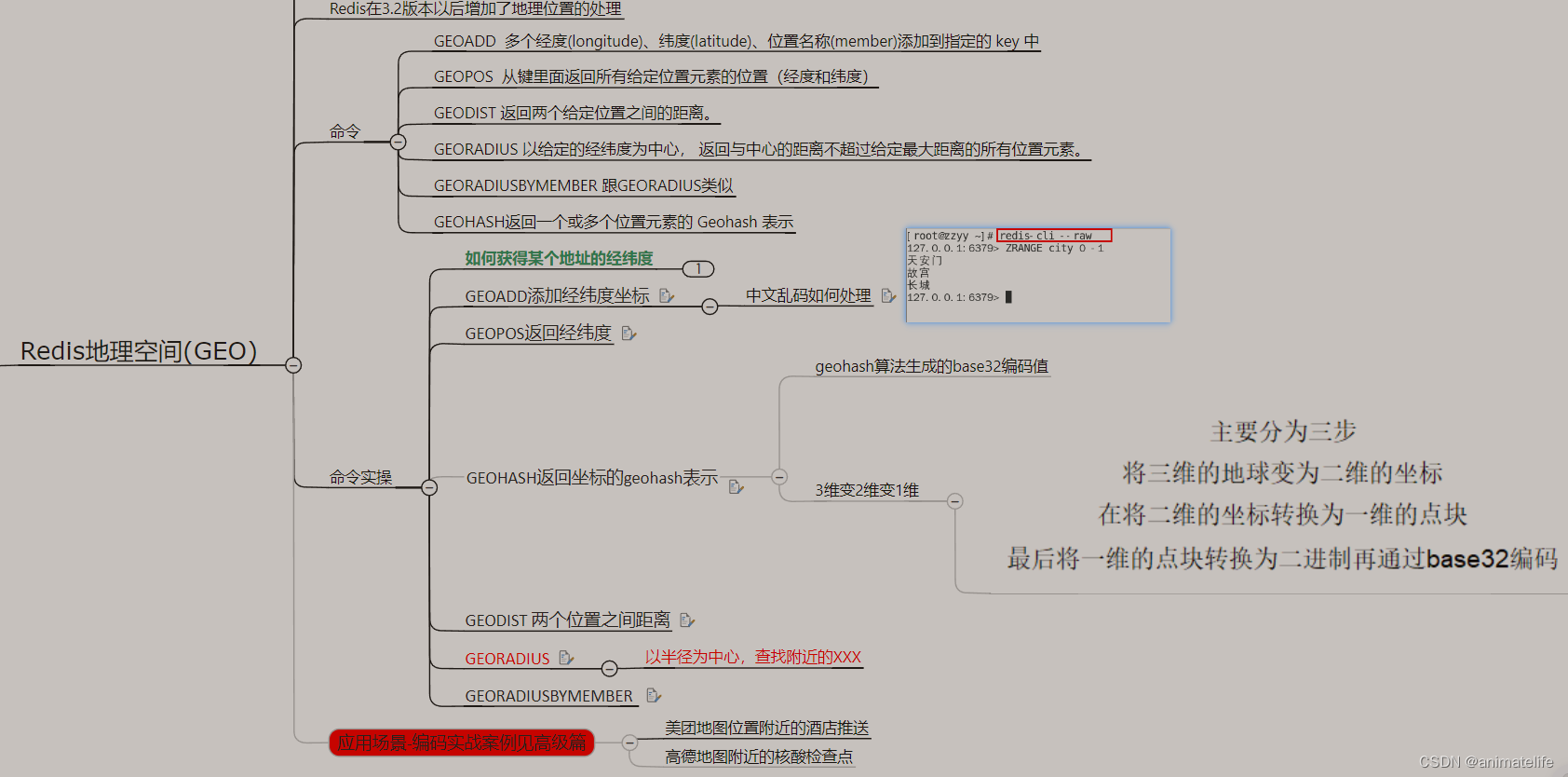
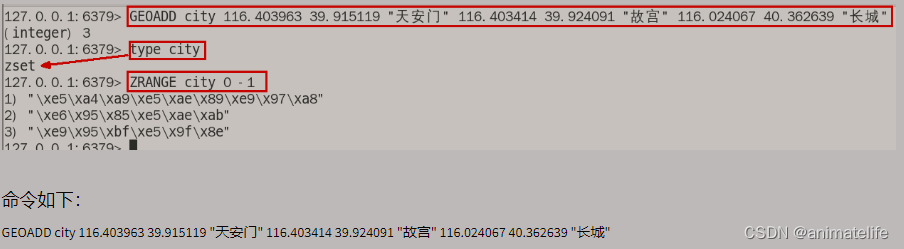


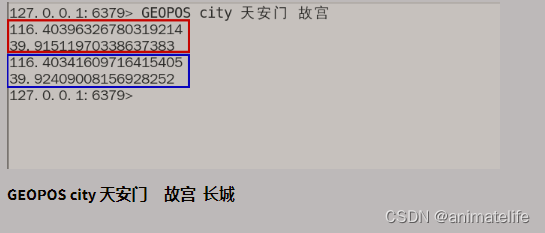
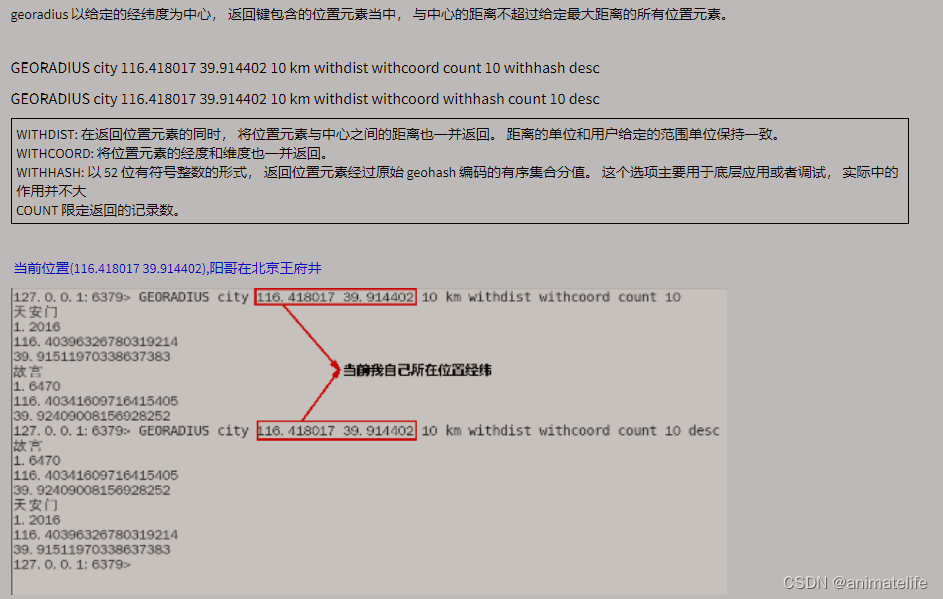
Stream 流



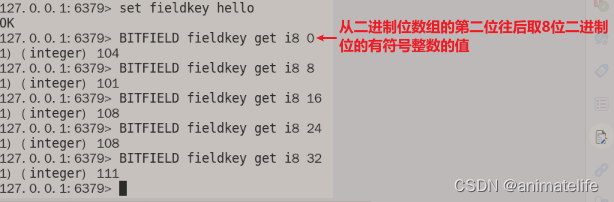
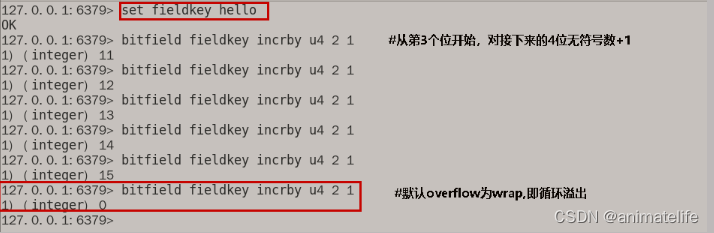
bitfiled
redis 事务
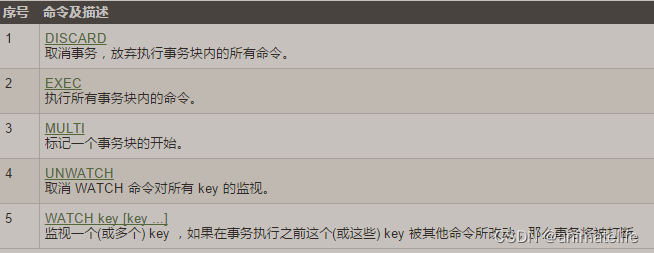
- 一个事务中的所有指令,都会先加入一个队列,然后执行事务的时候,再依次取出顺序执行

- redis 命令执行是单线程架构

- redis 事务以
MULTI开始,以DISCARD/EXEC结束,然后才是 redis 服务器执行事务中的指令

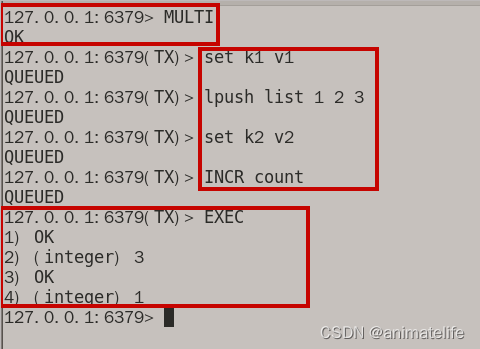
事务的正常执行的情况
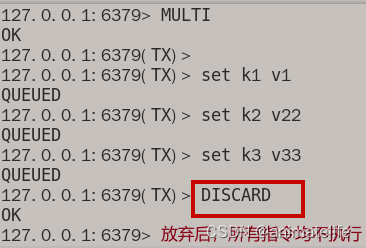
事务放弃的情况
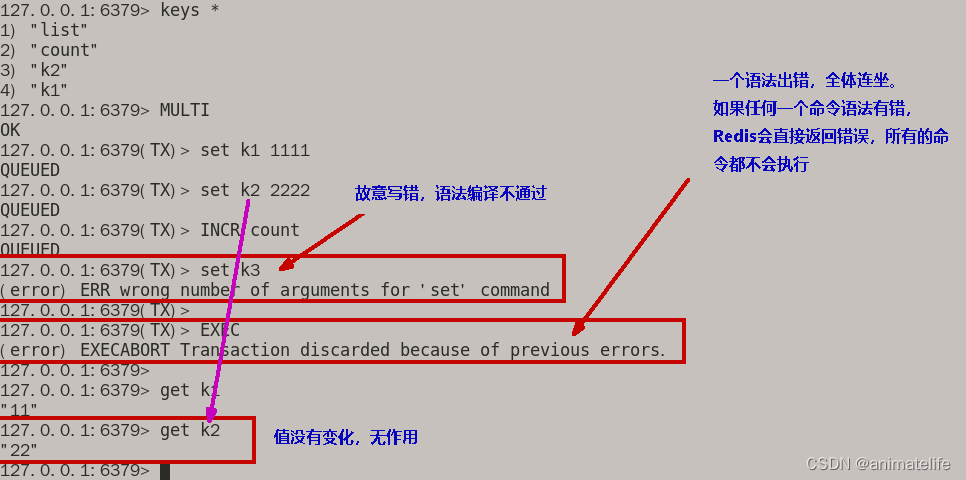
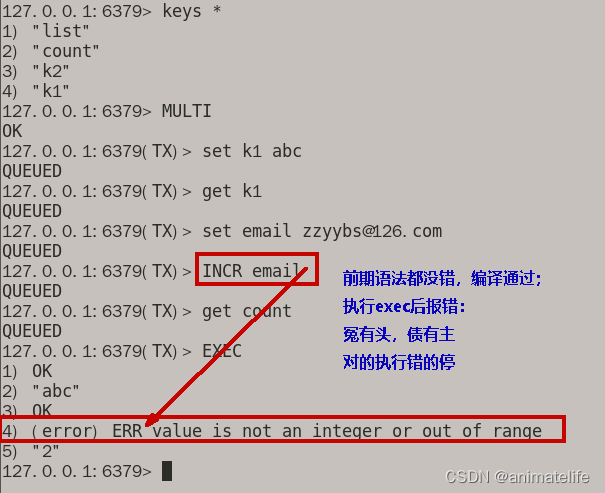
EXEC之前发生异常
EXEC之后发生异常

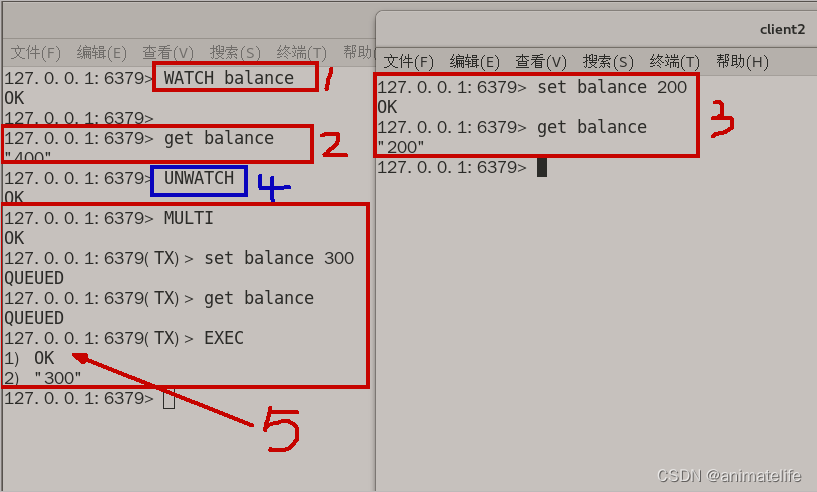
使用 WATCH/UNWATCH



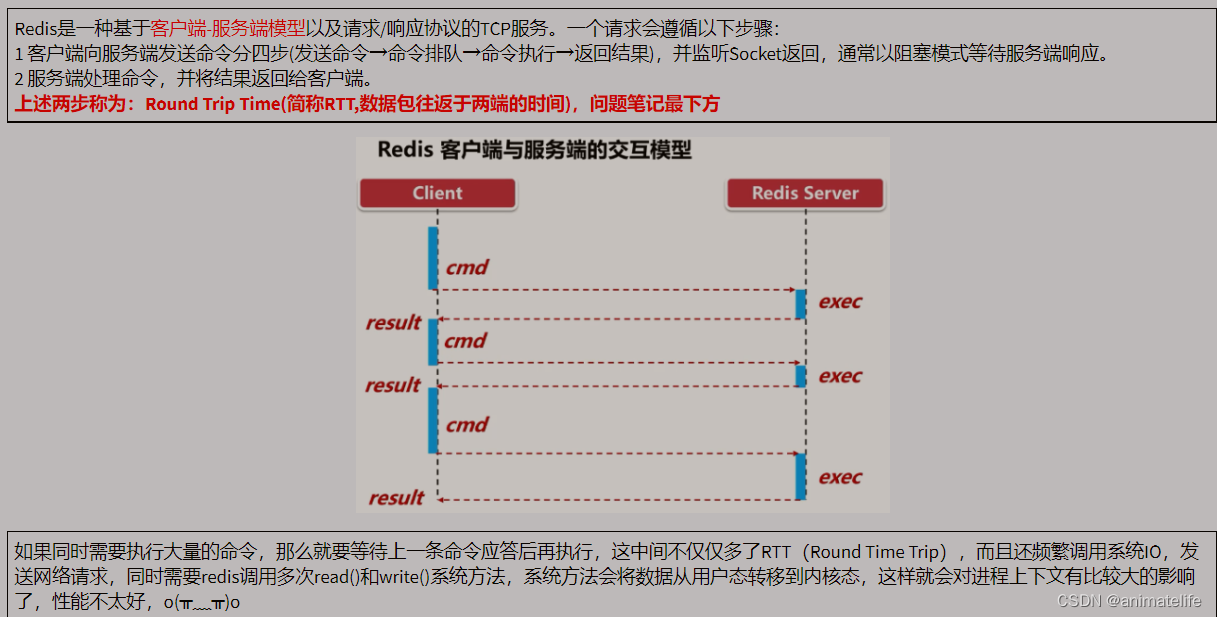
redis 管道
- 管道 专注于 批量执行 一组指令,但是不是事务,因为redis 命令执行是单线程架构,中间 redis 线程可以去处理其它请求,意味着这一组指令执行过程中可以被中途插入执行其它指令



redis高可用
redis 复制(replica)


主从都有的配置(修改配置文件,开放port为6379的redis为例)
- 开启
daemonize

- 注释掉
bind,或改成bind 0.0.0.0
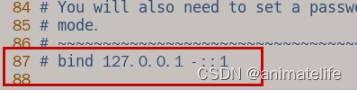
- 指定端口
port,不同机器,指定的端口不同

- 指定工作目录(RDB文件存放目录)
dir,配置文件和myredis目录都在redis存放目录
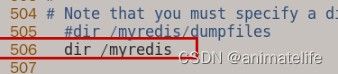
- pid文件
pidfile

- 日志文件存放目录(用于排查问题)
logfile,日志文件、配置文件和myredis目录都在redis存放目录
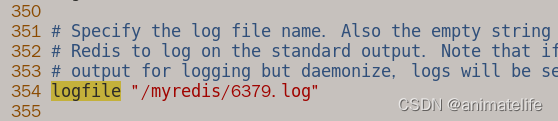
- rdb文件的名字
dbfilename,rdb文件存放在myredis目录中,二者又都在redis存放目录
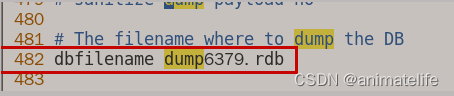
- 关闭保护模式
protected-mode

- 开启aof可选(因为已经有主从复制了)
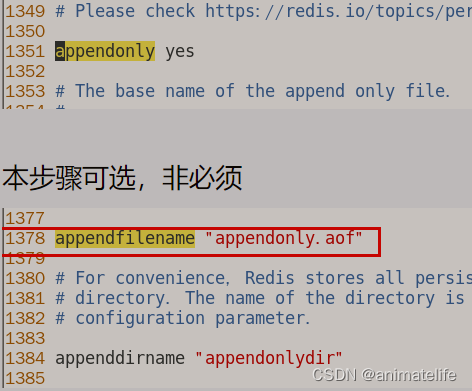
主库的配置(测试环境设定开放端口为6379的redis为主库)
- 添加密码

从库的配置
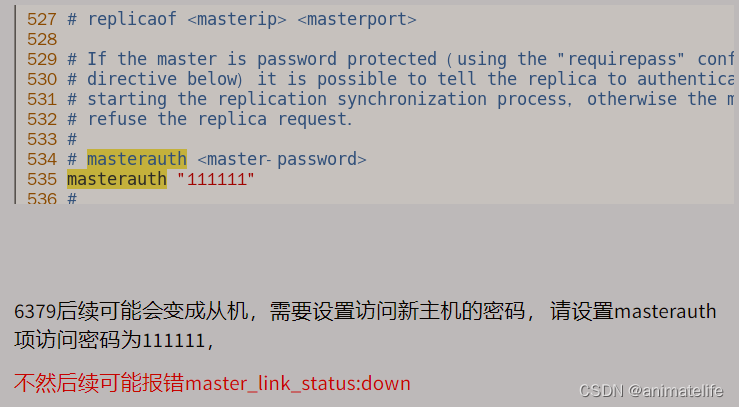
- 从库访问主库的同行密码
masterauth,值为主库的 requirepass 的值
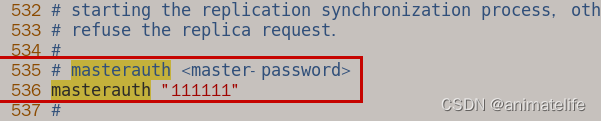
- 告诉从库需要跟随的主库地址和端口
- 通过配置文件这种方式就算从库重启也依然有效

- 通过指令的形式(先启动后,再指定)
slaveof 主库IP 主库端口号,这种方式可用于更换(更换后前一个主库的数据会被清除)或指定主库,但是从库重启后需要重新设定
- 通过配置文件这种方式就算从库重启也依然有效
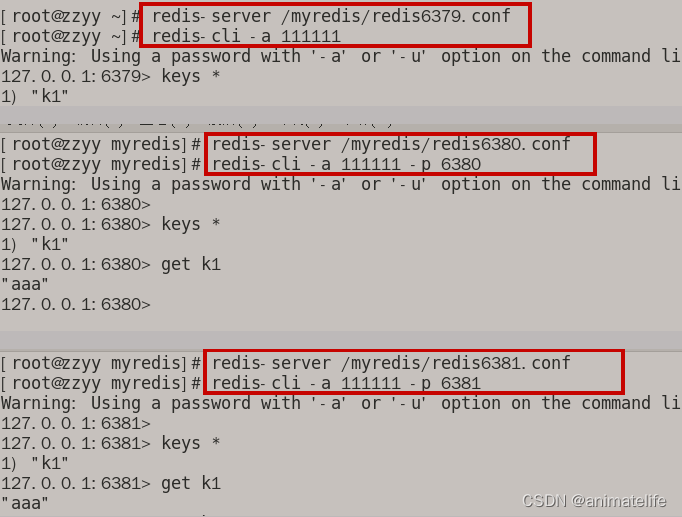
启动一主二从
- 注意:需要提前设置防火墙开放对应的端口,保证三台机器之间能够
ping通 - 从库登录redis客户端时,需要指定端口号(虽然配置文件已经修改了端口号,redis 的默认端口号是6379)
- 从库的密码,可以和主库不一样,这里懒得设置,就都一样了
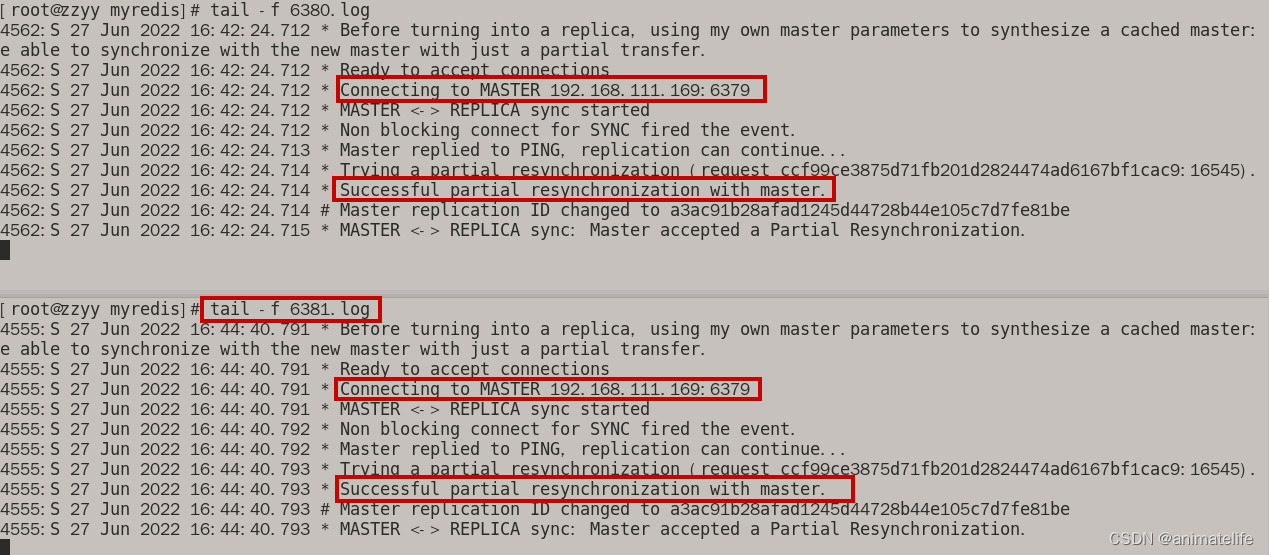
主从的日志观察
- 主库日志上看从库的信息
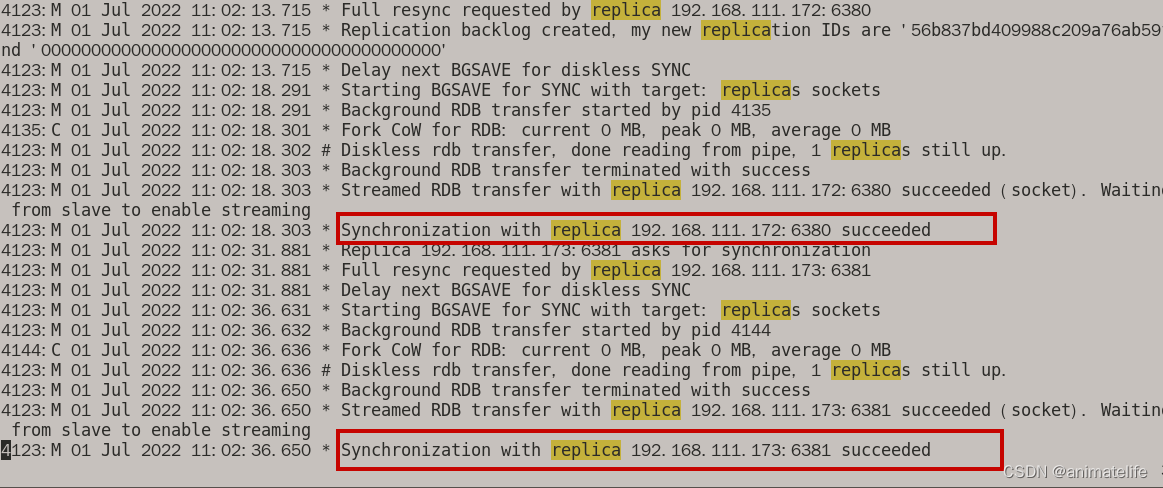
- 在从库日志上看主库的信息
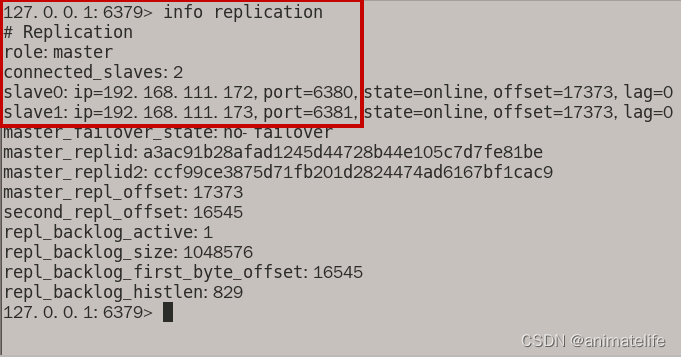
查询主从的信息(info replication)
- 主库上查询
- 从库上查询
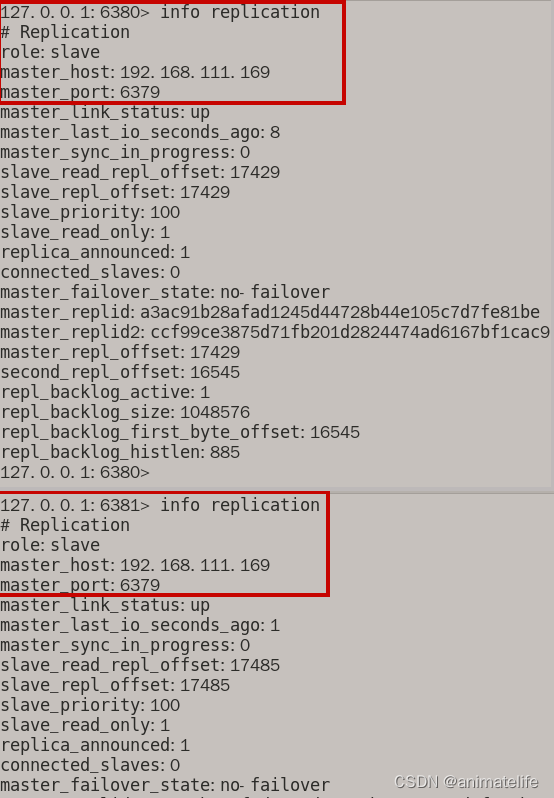
常见问题
- 从机不可以执行写命令
- 不管从库连上主库的时间是什么什么时候,都遵循以下规律

- 不管主库因为何原因shutdown,主从关系都会一直保持,从库的数据可以正常访问

主从传递

从库升级为主库
- 修改从库配置文件,注释掉
replicaof后重启,如果是通过注释实现主从关联的,直接重启 - 通过指令
slaveof no one,使当前从库停止与其他数据库的同步,转成主数据库
主从复制的缺陷
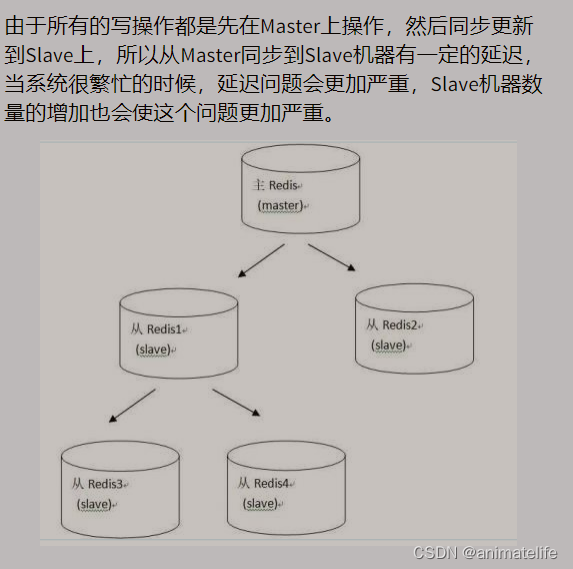
- 默认情况下,主节点出现问题,不会在slave节点中重新选一个master节点,需要人工干预
redis 哨兵(sentinel)
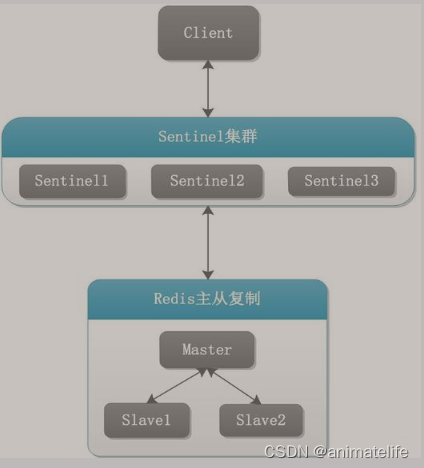


redis 主从搭建
- 参照 redis 复制,唯一需要改动的是原来主库的配置文件
哨兵的搭建


- 哨兵节点数,一般三台足够
- 哨兵节点虽然也是 redis,但是只负责监控等功能,不存放数据
- 可以同时监控多个主节点,如下图所示(来源官网)

哨兵的配置文件
- 在 redis 的存放目录,按照惯例,复制一份到同目录的/myredis,保留原样的配置文件
- 参数的配置,参照 redis 复制中的 主从都有的配置,哨兵节点的port默认为26397,以下为专属哨兵节点的配置内容

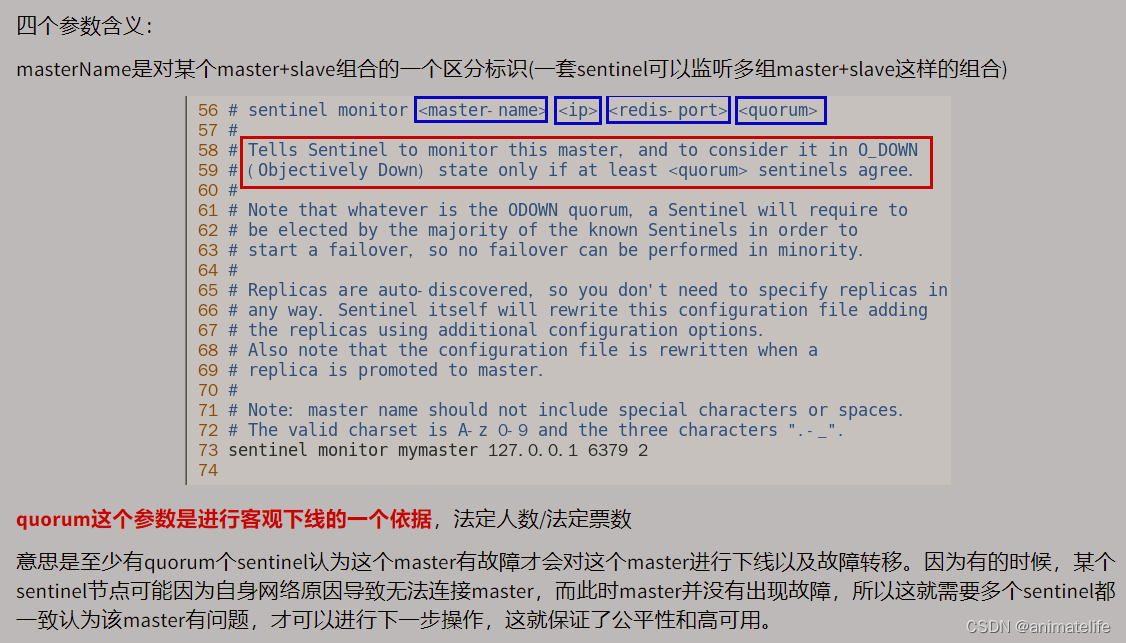
- 以下的配置项脚本相关可以不用理会

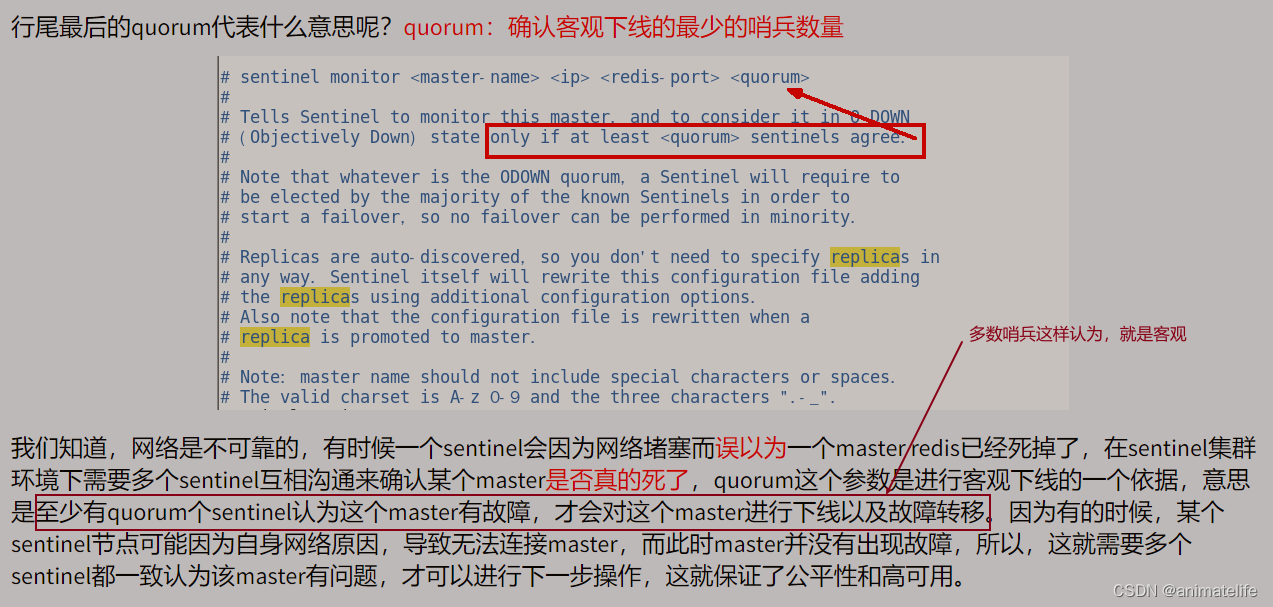
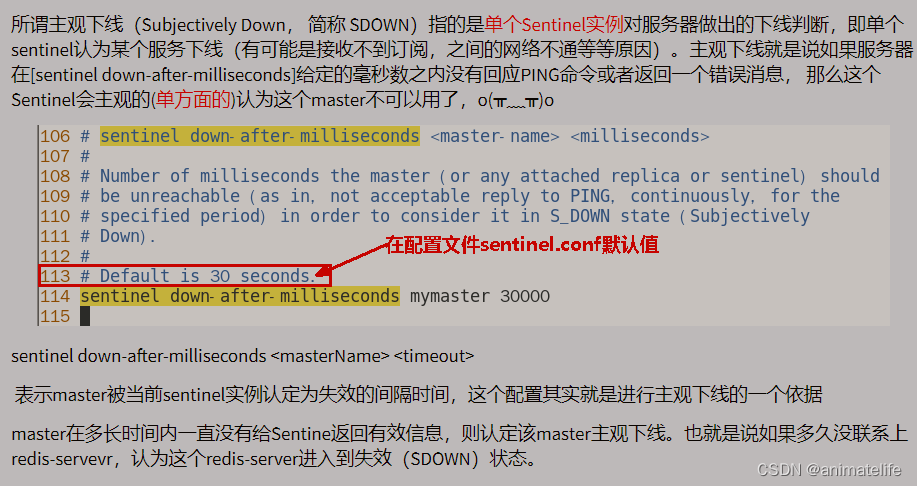
主观下线和客观下线

哨兵节点的启动
- 配置文件名,也说明了它们各自配置的端口

发生主从节点切换


- 兵王日志内容展示,其它哨兵日志内容相同
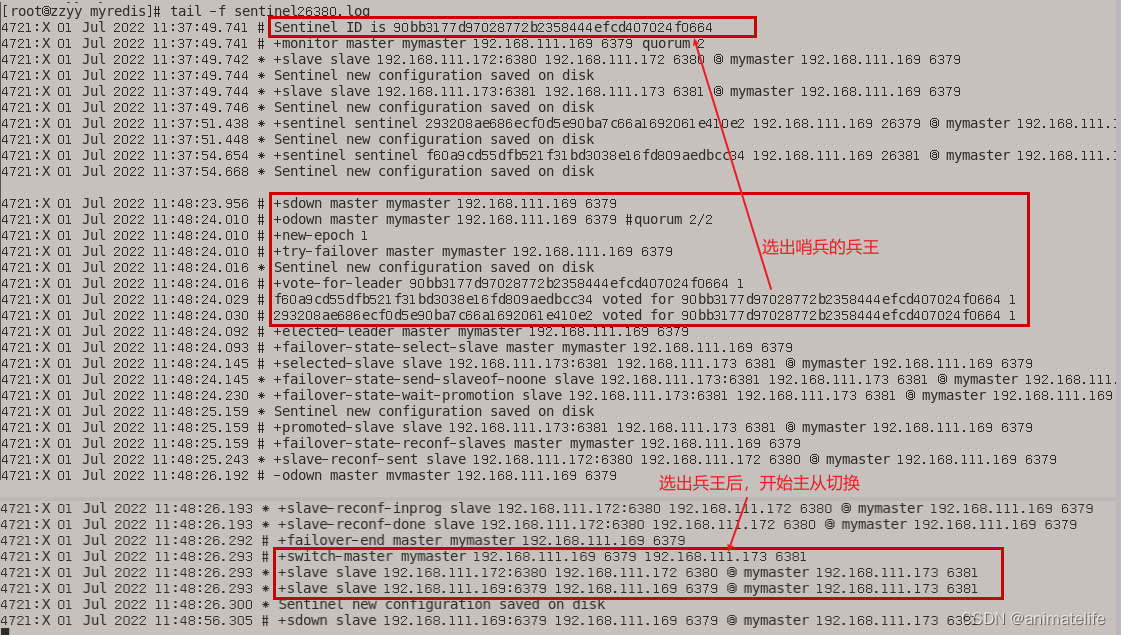
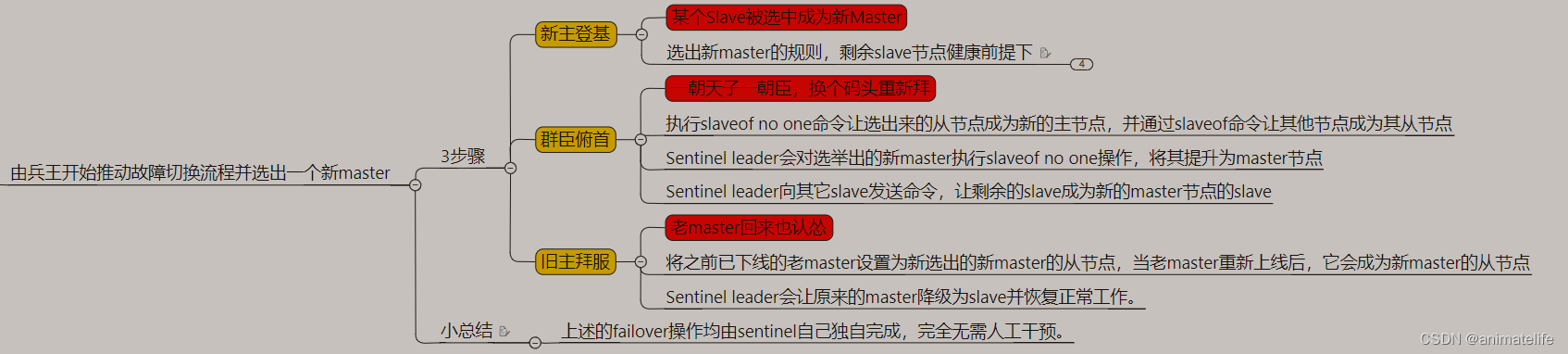
- 完成新的主节点切换后,可以发现哨兵节点、原来的主从节点配置文件均发生了变化
- 哨兵节点的配置文件中,监控的节点改成了新的主节点
- 新的主节点配置文件中,新增了改变为主节点的配置
- 旧的主节点配置文件中,原来的主节点配置被去掉,新增从节点的配置
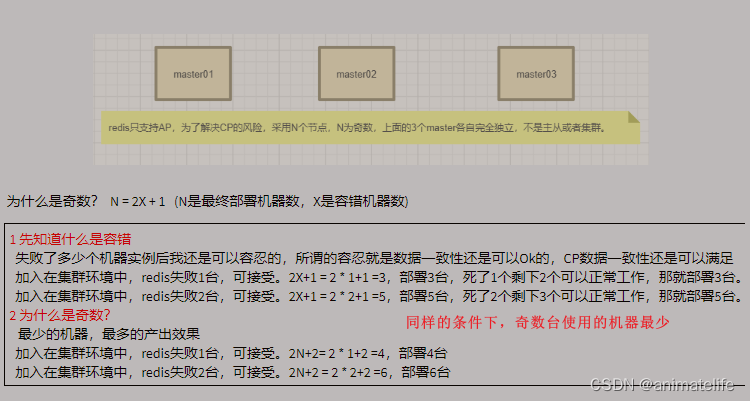
redis 集群(cluster,AP)

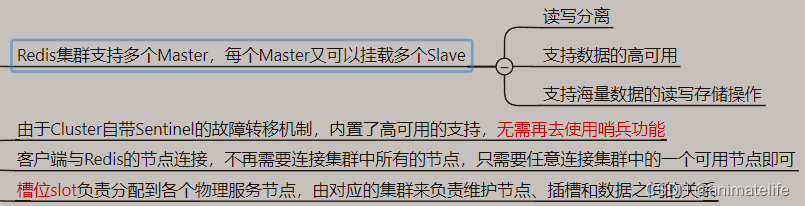

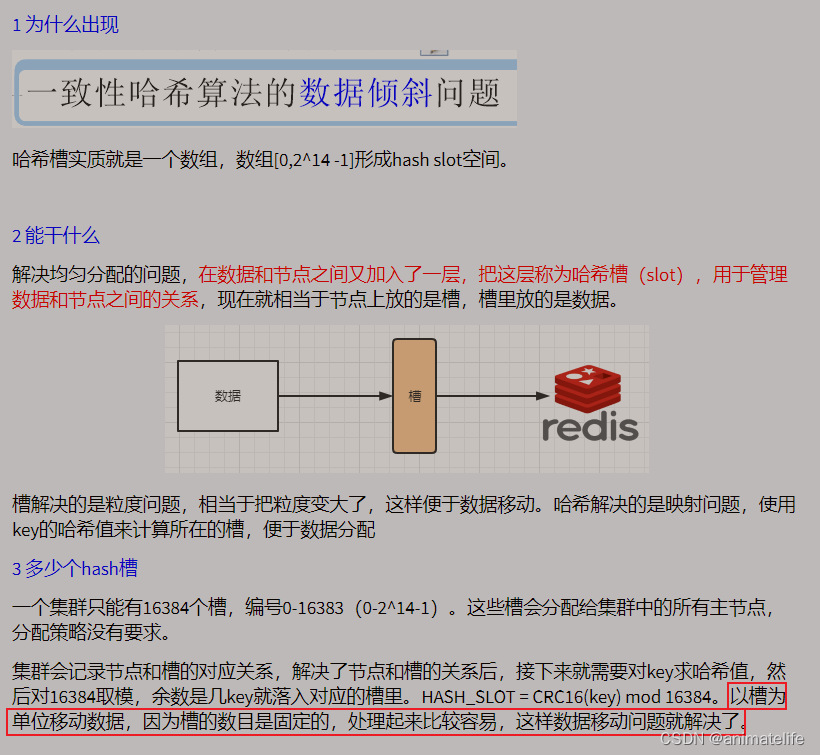
redis 集群的 slot 槽
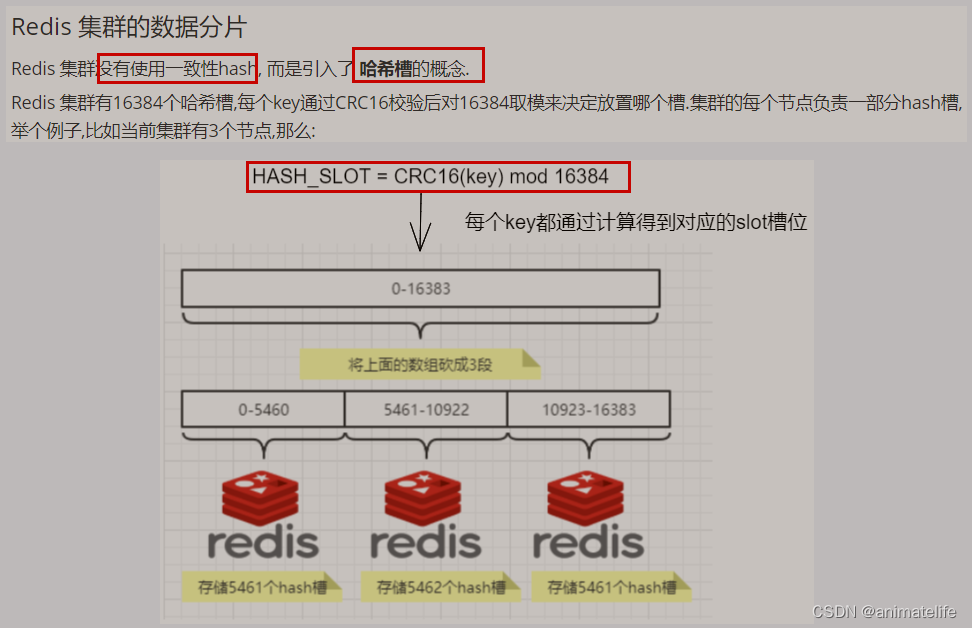

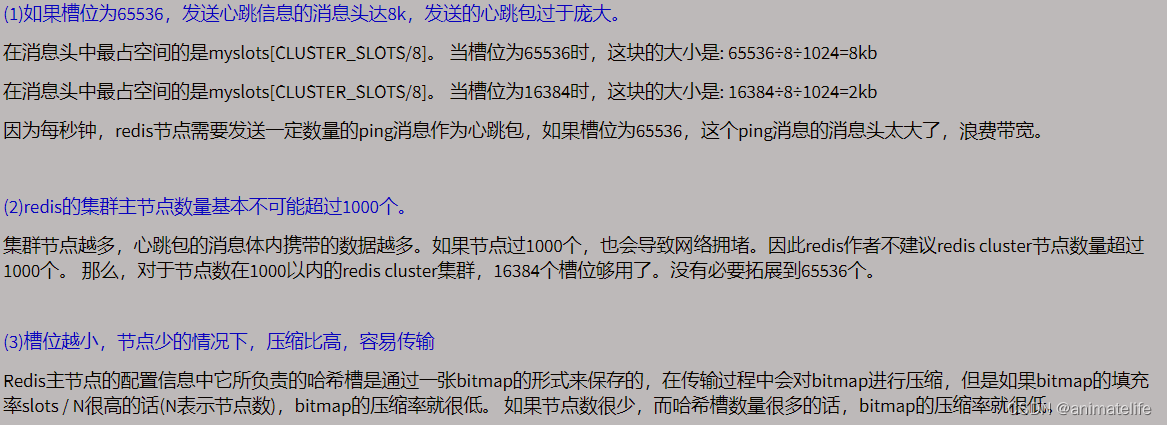
为什么 redis 集群的最大槽数 16384 个?
- CRC16算法产生的hash值有16bit,该算法可以产生2^16=65536个值
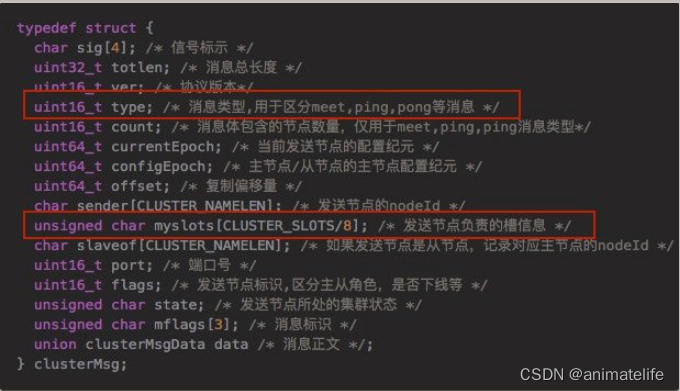
slot 槽位映射的三种常见方法
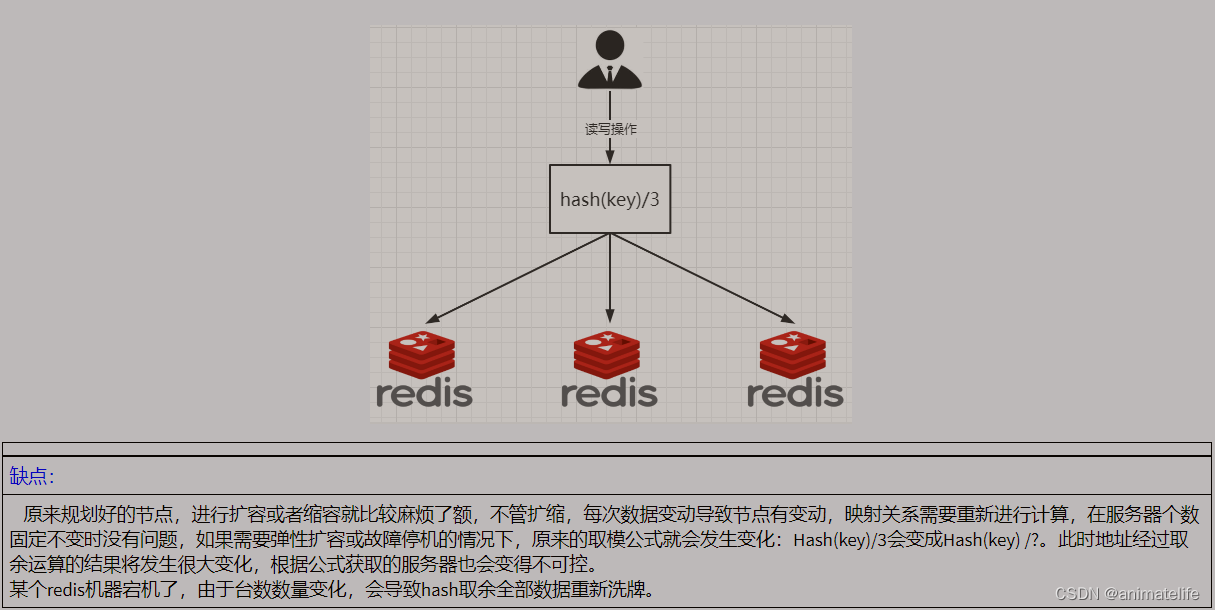
Hash取余
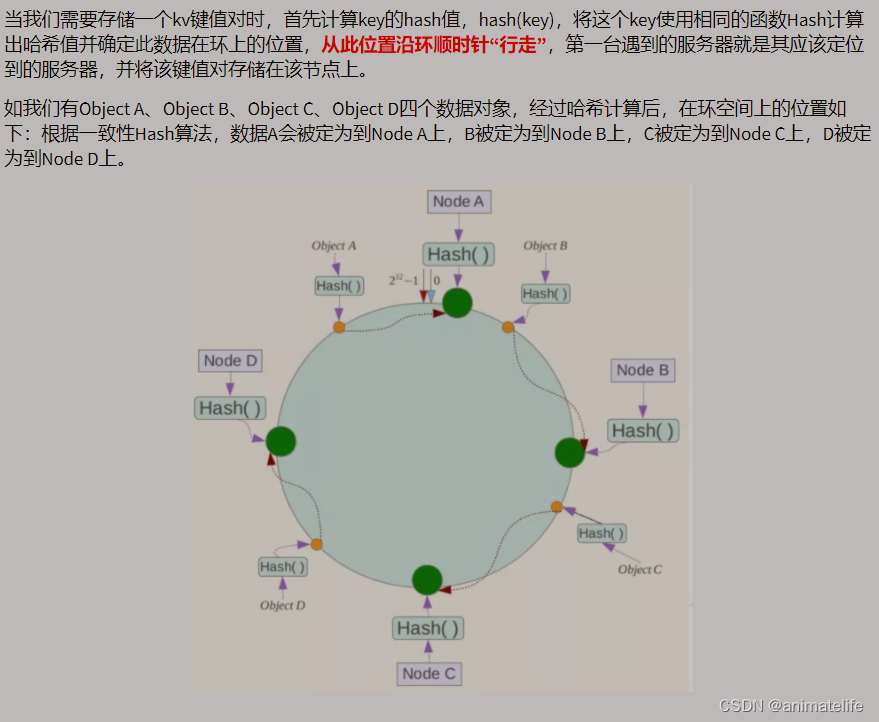
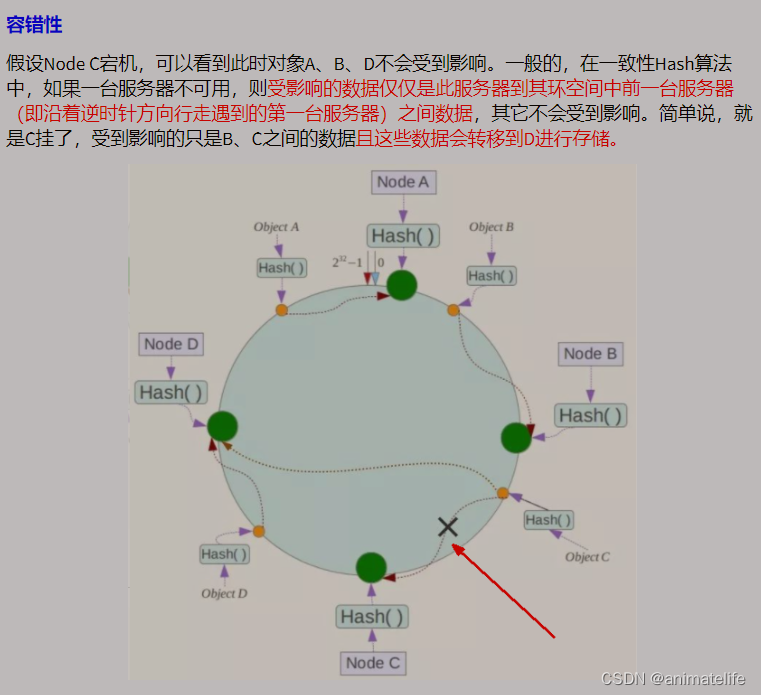
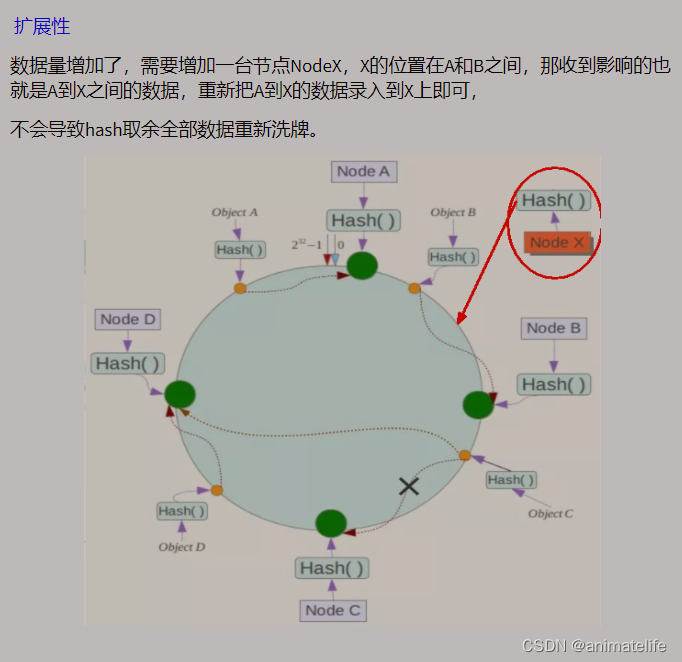
一致性Hash算法

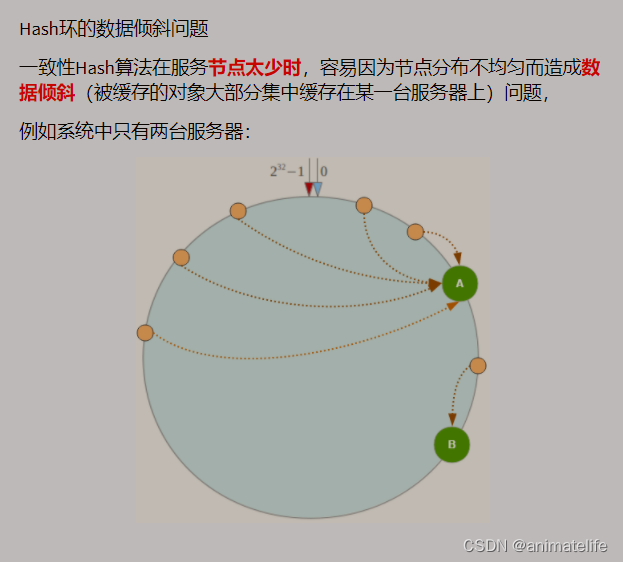
Hash槽分区
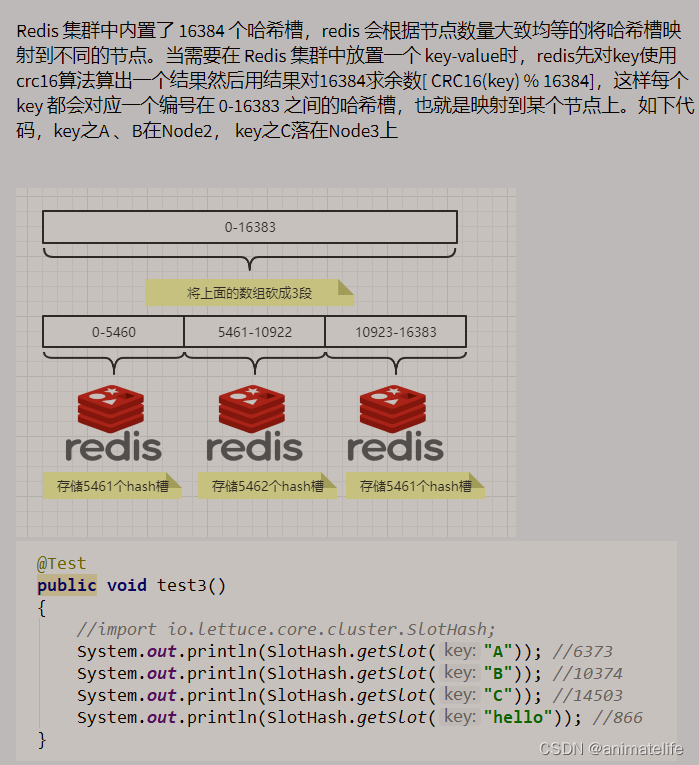
三主三从 redis 集群搭建
- 修改配置文件,一共六个,都参照 redis 复制 中的主从都有的配置修改(注意配分原来的配置文件)
- 为每一个配置文件新增如下修改,配置文件名随意,最好是有规律,node-redis端口号.conf 下面的步骤执行成功后会自动在每个 redis 实例的工作目录中生成(设置的rdb目录)

- 为每一个配置文件新增如下修改,配置文件名随意,最好是有规律,node-redis端口号.conf 下面的步骤执行成功后会自动在每个 redis 实例的工作目录中生成(设置的rdb目录)
- 启动6台 redis 实例
redis-server /redis存放目录/自定义目录/redisCluster+端口号.conf,在每台redis实例执行对应的指令
- 构建三主三从
- 在 需要搭建 redis 集群中的任意一个服务器上输入
redis-cli -a 密码 --cluster create --cluster-replicas 1 IP1:端口1 IP2:端口2 IP3:端口3 IP4:端口4 IP5:端口5 IP6:端口6 --cluster-replicas 1表示为每个主节点创建一个从节点- 一共6个IP+端口号,模拟6个 redis 服务
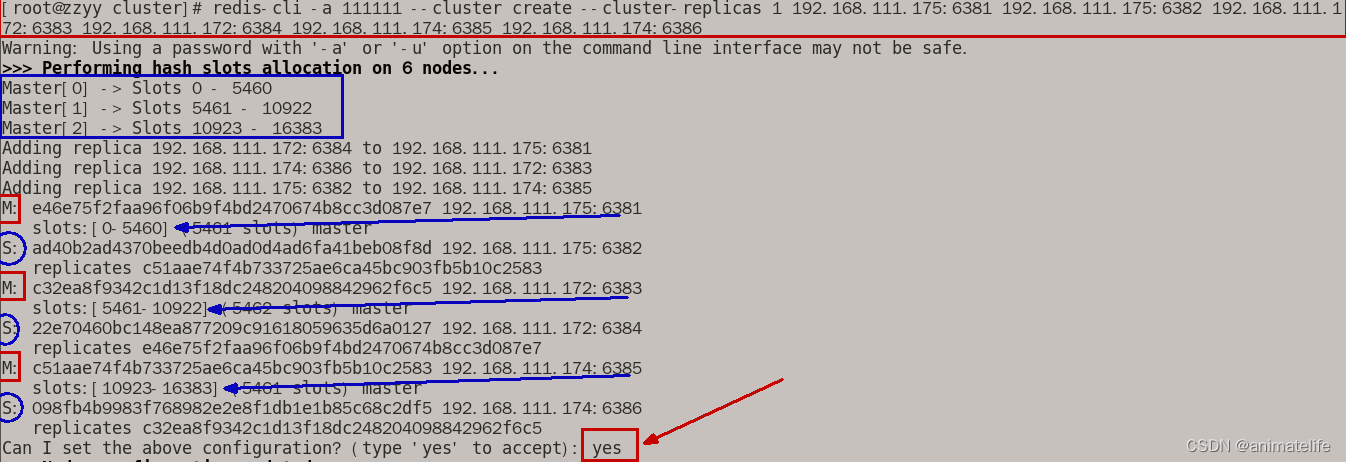
- 在 需要搭建 redis 集群中的任意一个服务器上输入
- 以其中一台 redis 实列为切入点 登录,查看 集群状态
-
登录
redis-cli -a 密码 -p redis端口号 -c,加上-c是为了让 redis 执行指令时,自动路由到对应的 slot 槽,不加的话,在当前 redis 实例 执行了 写入 了不属于 当前 redis 实例 对应 slot 槽分区 的键值对时会报错
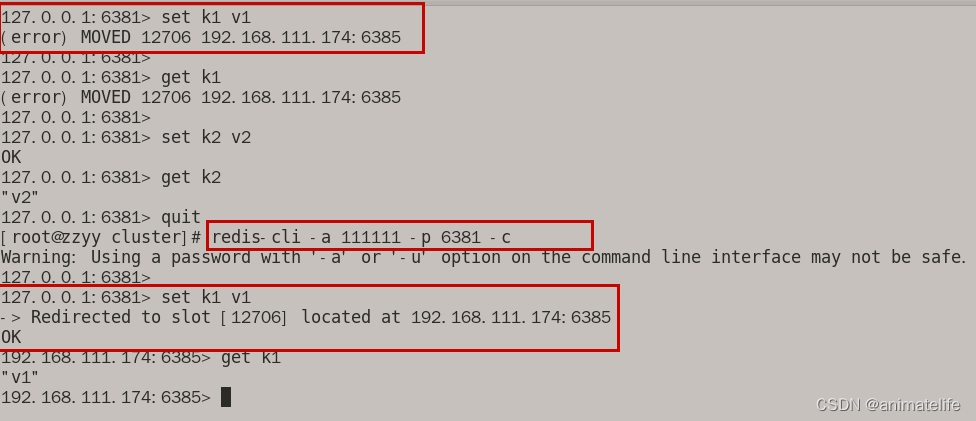
-
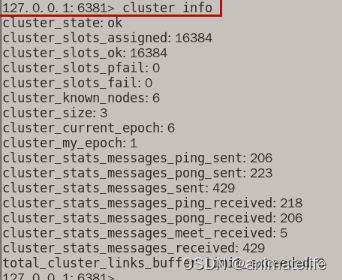
查看集群状态和信息
cluster nodes,显示所有 redis 实例的 ID信息和从属关系

-
redis 集群 读写
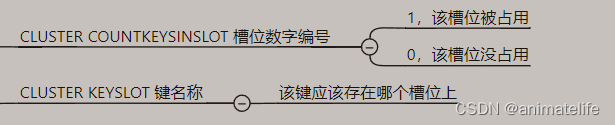
- 查看集群中某个 key 的 slot 槽位值
CLUSTER KEYSLOT key名

主从容错切换(自动故障转移)
- 自动进行,主库挂了,从库自动成为主库,旧的主库恢复后,自动成为新主库的从库
- 节点从属调整(手动故障转移):原来的主库因为 redis 集群自动 容错切换(自动故障转移),导致从属关系发生了改变,可以登录原来的主库(现在的从库),执行指令
cluster failover,回复原来的从属关系
主从动态扩容
- 对新加入的两台 redis 实例 修改配置文件,参照 集群中的其它 redis 实例配置
- 启动新加入的两台 reids 实例,暂时不构建从属关系,此时它们都是主库,启动指令参照 集群中的其它 redis 实例
- 输入指令
redis-cli -a 密码 --cluster add-node 新加入redis实例的IP:端口号 集群中任意一个redis实例的IP:端口号,为集群新加入一个主节点
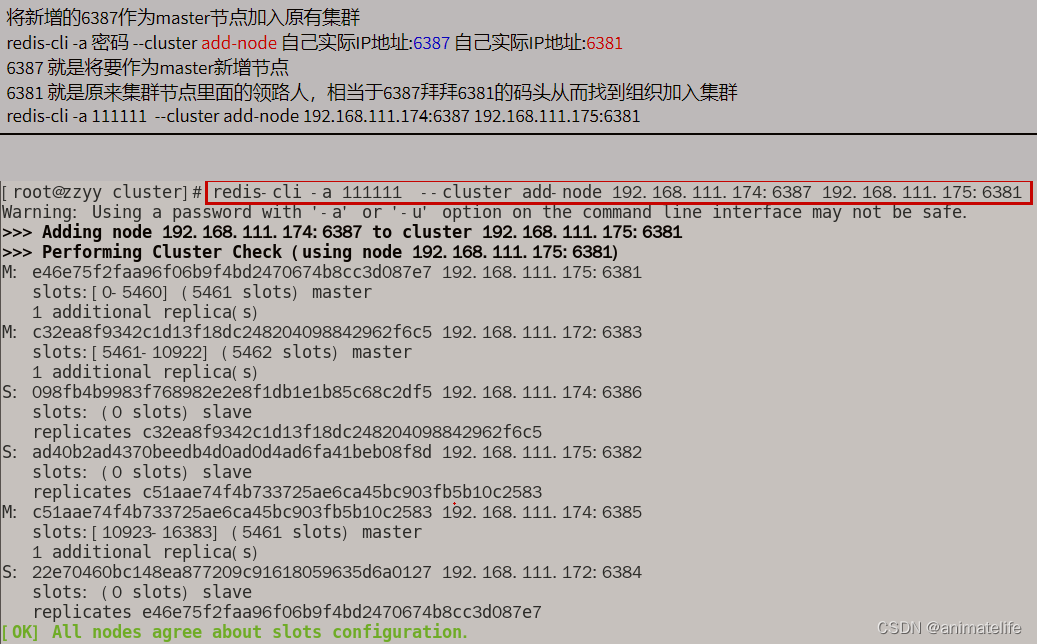
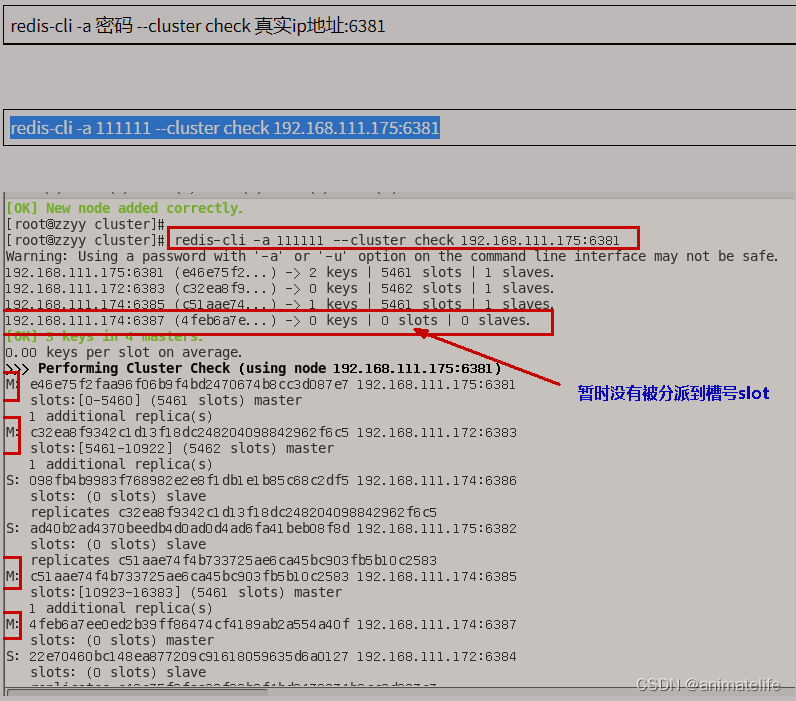
- 通过随意一个 redis 实例 执行指令
redis-cli -a 密码 --cluster check 集群中任意一个redis实例的IP:端口号查看 集群中 slot 槽的分配情况
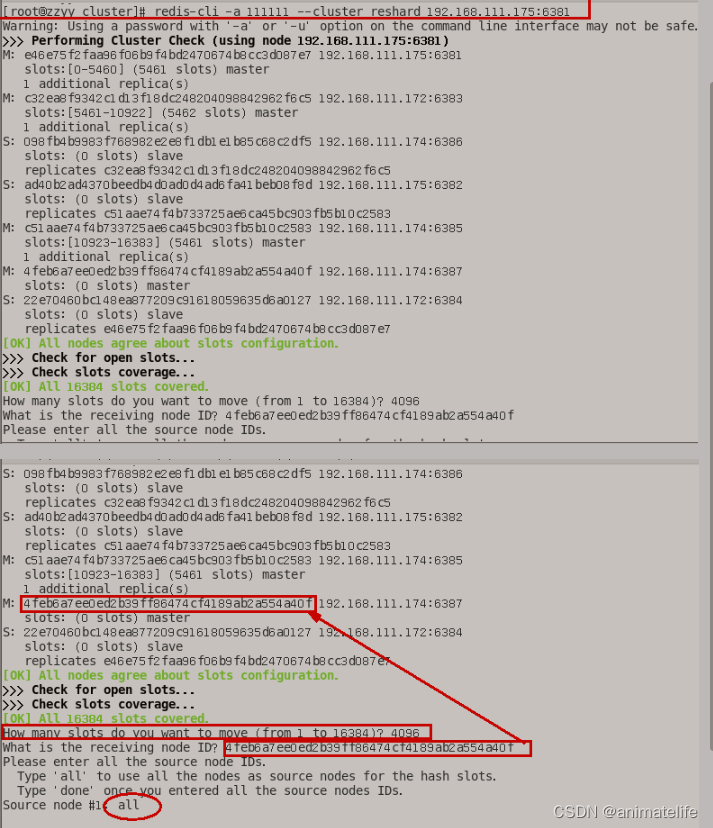
- 重新分派槽号
redis-cli -a 密码 --cluster reshard 新添加的redis实例的IP地址:端口号,集群中 其它 redis 实例 会匀出适当数量的 slot 槽给新加入的 redis 实例
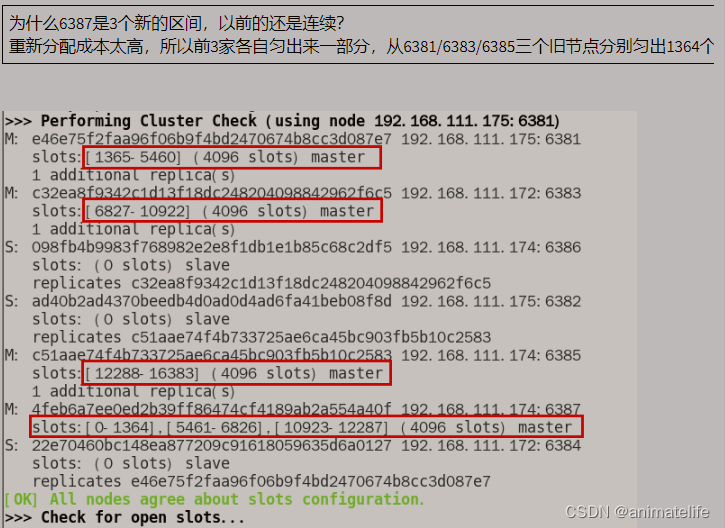
- 为新的主节点添加子节点
redis-cli -a 密码 --cluster add-node 新Slave的IP:端口 新master的IP:端口 --cluster-slave --cluster-master-id 新master的ID
主从动态缩容
- 先获取要下线的 redis 从节点 的 ID
redis-cli -a 密码 --cluster check 192.168.111.174:6388
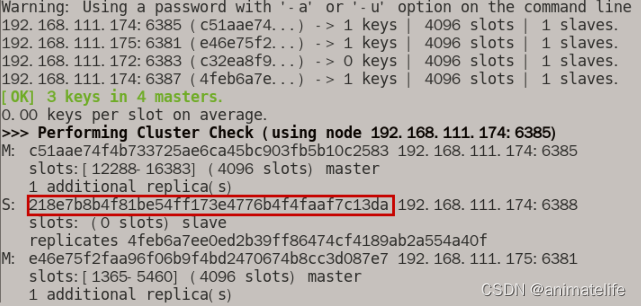
- 删除要下显得从节点
redis-cli -a 111111 --cluster del-node 192.168.111.174:6388 218e7b8b4f81be54ff173e4776b4f4faaf7c13da - 将已经删掉的从节点的 主节点 的 slot 槽 清空(转给集群中其它主节点)
redis-cli -a 111111 --cluster reshard 192.168.111.175:6381,指令中 redis 实例的IP和端口号可以是集群中任意一个 redis 实例 的IP和端口,主要目的是执行如下如所示的 reshard,按照提示进行即可
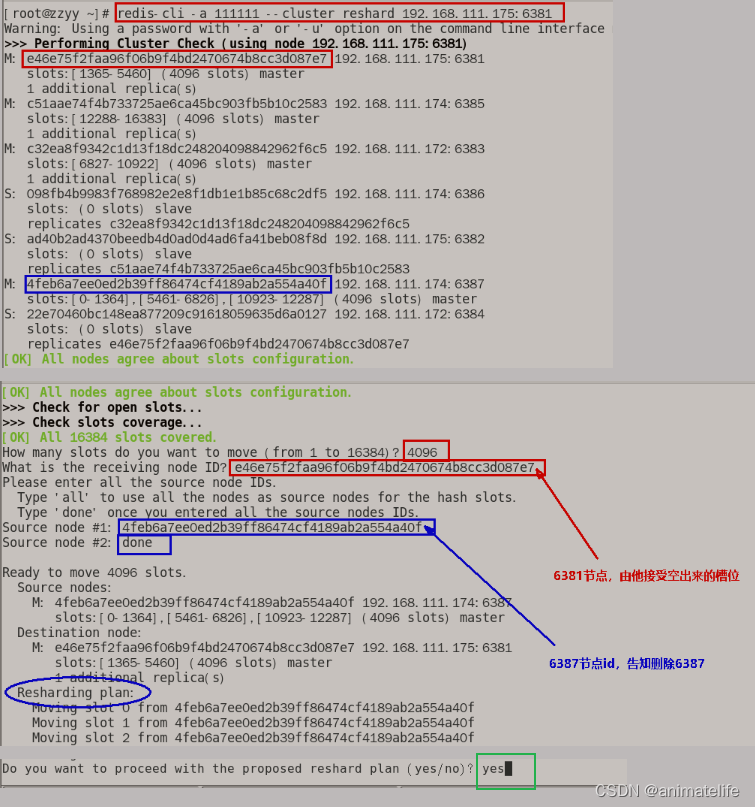
- 清空 要删除的 主节点的 redis 实例 的 slot 槽以后,直接执行指令
redis-cli -a 111111 --cluster del-node 192.168.111.174:6387 4feb6a7ee0ed2b39ff86474cf4189ab2a554a40f删除该主节点
集群常用指令总结
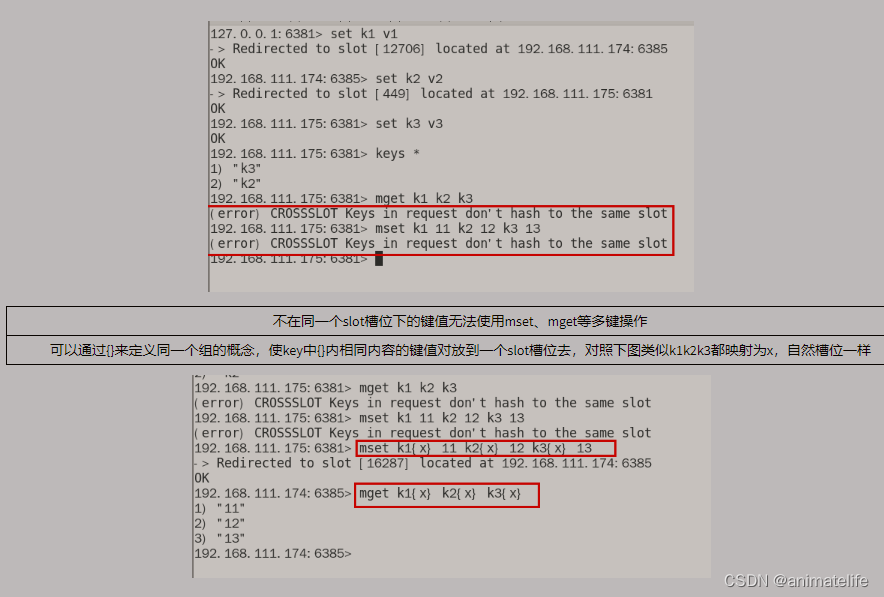
redis-cli -a 密码 --cluster check 192.168.111.174:6388通过集群的任意一个 redis 实例查看集群所有 redis 的ID、分配的 slot 槽等信息、从属关系cluster nodes查看集群所有 redis 的ID、从属关系cluster info
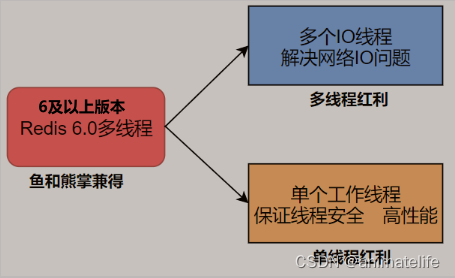
redis 的线程与IO
redis 的线程
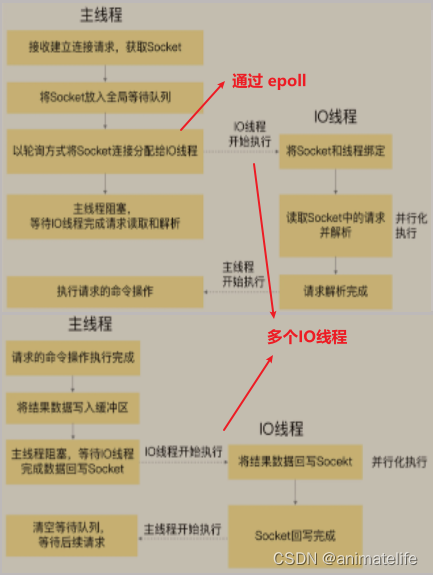
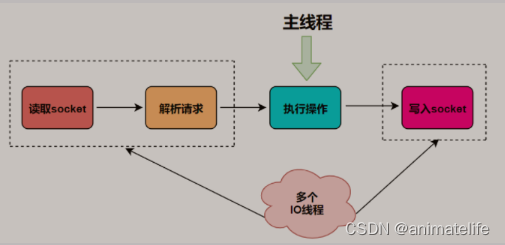
- 单线程:主线程只负责执行指令,除了部分指令执行时指定了通过异步的方式(如
unlink key、flushdb async等) - 多线程:多线程负责处理各种IO操作,如网络IO、rdb与aof持久化操作、异步删除、集群数据同步等
redis 的IO
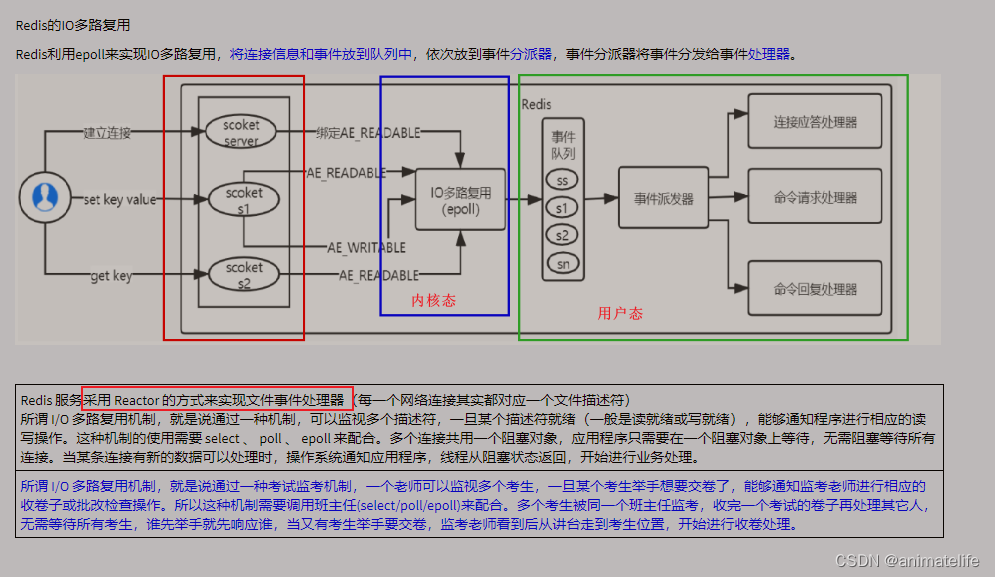
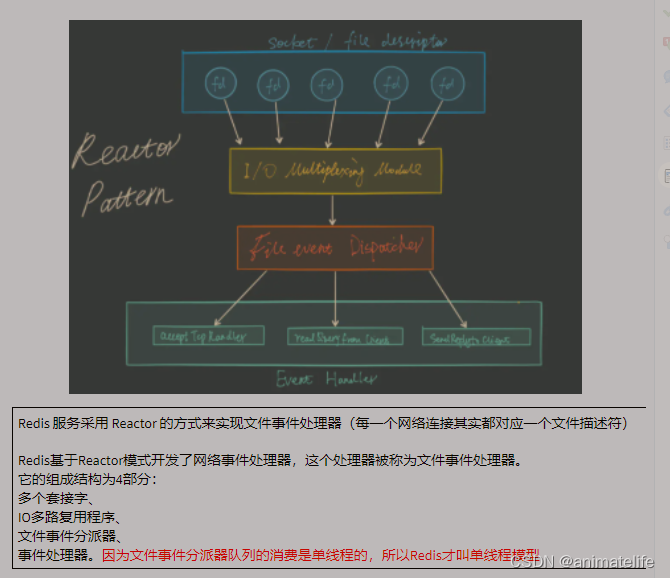

总结 redis 为什么这么快
- 使用 IO多路复用 和 非阻塞 IO
- 使用 epoll 函数 和 基于 Reactor 模式的文件事件处理器
- 所有操作都是基于内存
redis 默认单线程
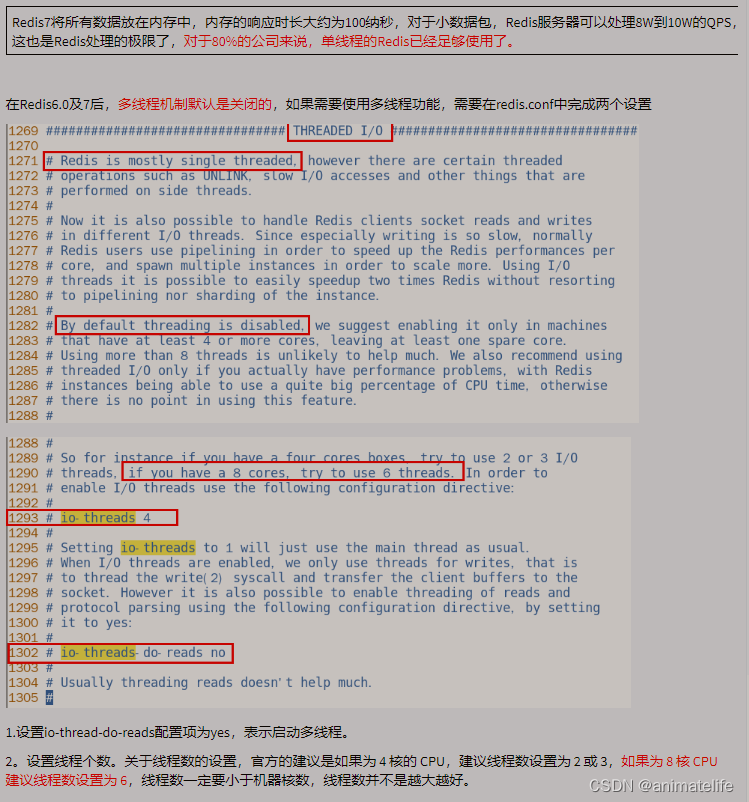
redis BigKey
MoreKey
插入大批量的数据
for((i=1;i<=100*10000;i++)); do echo "set k$i v$i" >> /tmp/redisTest.txt ;done;
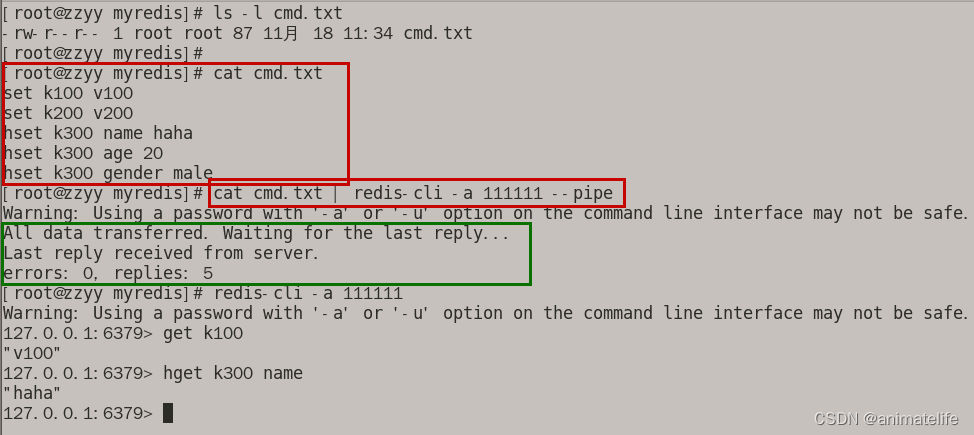
cat /tmp/redisTest.txt | redis-cli -h 127.0.0.1 -p 6379 -a 111111 --pipe
危险命令的禁用
- 关于
keys *、flushdb、flushall都是阻塞型命令 以及 危险命令(flushdb、flushall清空数据,虽然可以指定Async)
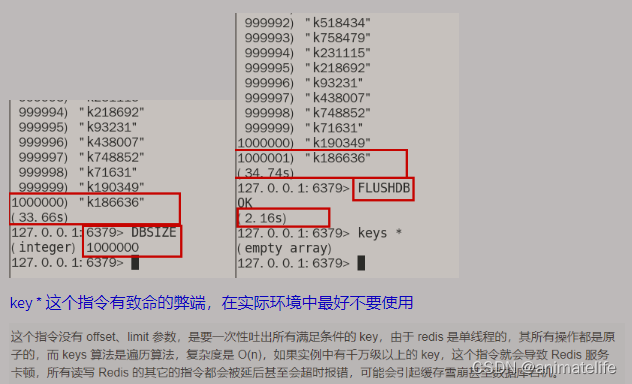
- 禁用的方法,修改 redis 的存放目录中的 redis.conf 中的 SECURITY 模块
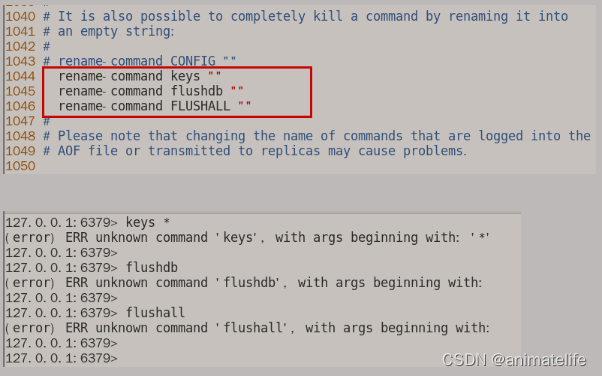
keys *的替代命令
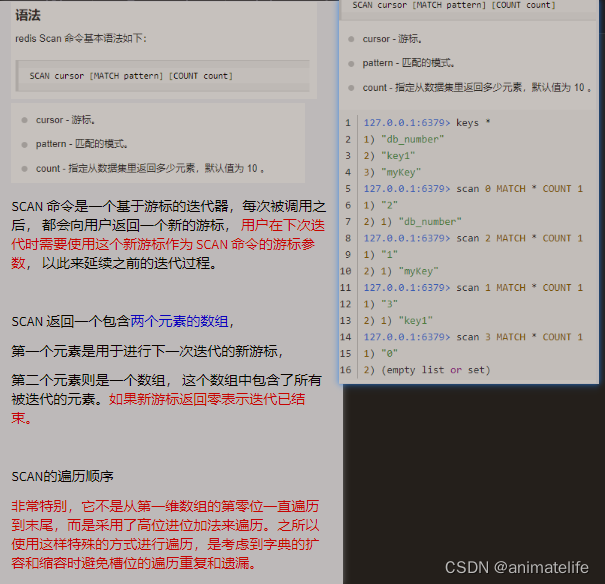
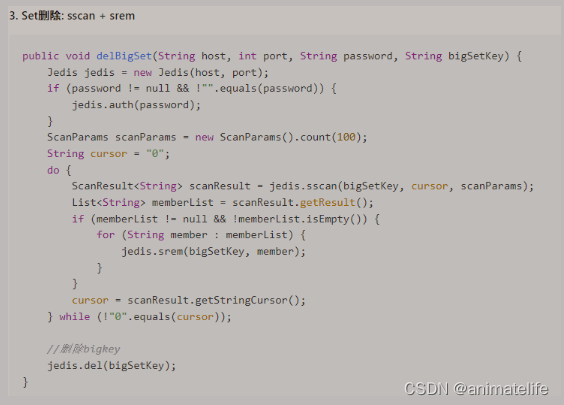
BigKey

危害 与 产生
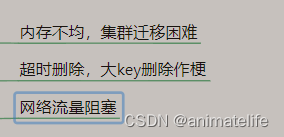

发现
- 通过命令
redis-cli -h 127.0.0.1 -p 7001 --bigkeys
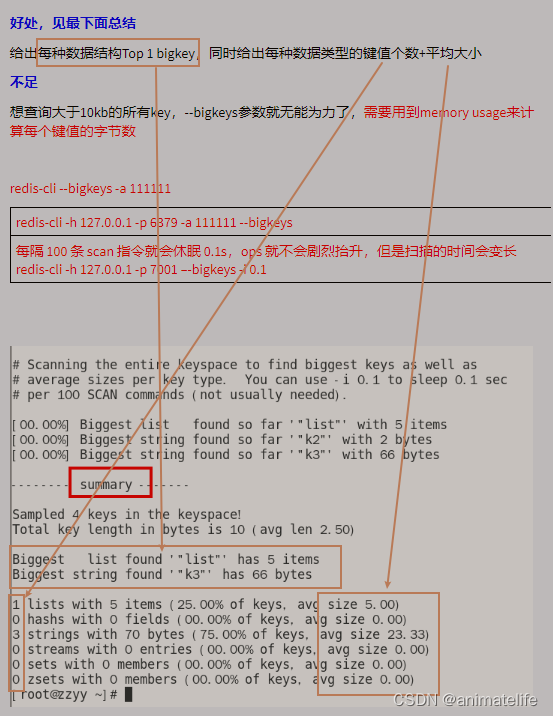
- 通过命令

删除
- 对于 String 类型的,通过
unlink key - 对于 hash

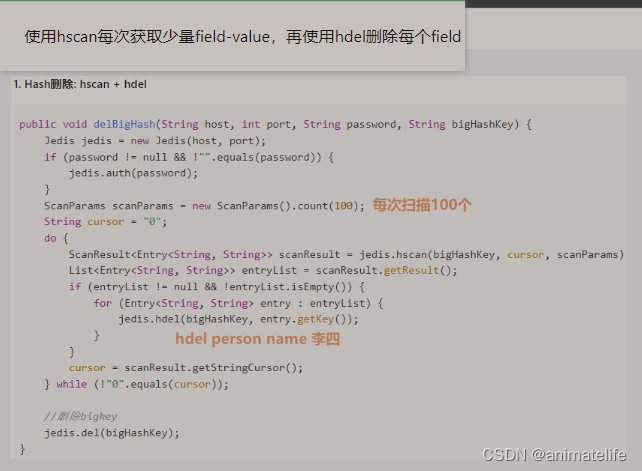
- 对于 list
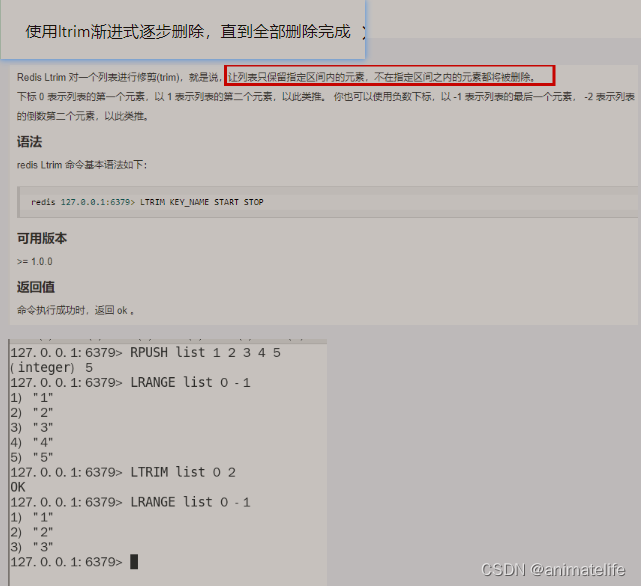
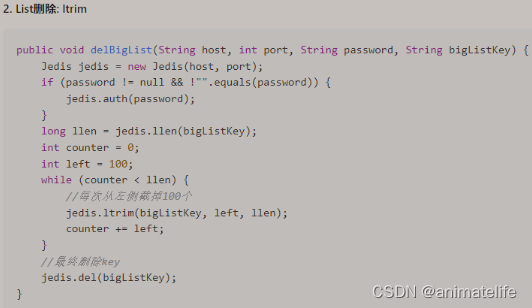
- 对于 set

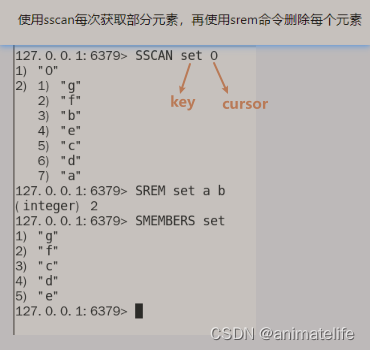
- 对于 zset


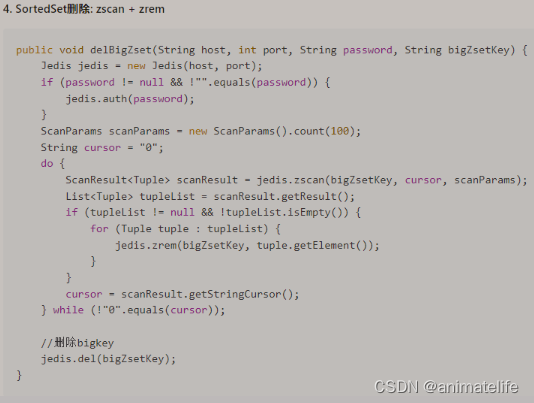
BigKey 生产调优 lazyfree
- 这些配置都是将 删除相关指令,自动改成异步的模式

数据库 & 缓存双写一致性
- 双写:即同时写入/更新数据到数据库和缓存
- 一致性:缓存和数据库的数据始终保持相同
需要一致性的场景
- 只读缓存不需要关注一致性,因为不需要和数据库保持实时一致
- 读写缓存,两种情况
- redis 中有数据,则需要和数据库中的值保持一致
- redis 中无数据,需要从数据库将最新值同步到 redis
- 总结:读写缓存 需要 和数据库 保持数据同步,就会需要关注一致性
一致性策略
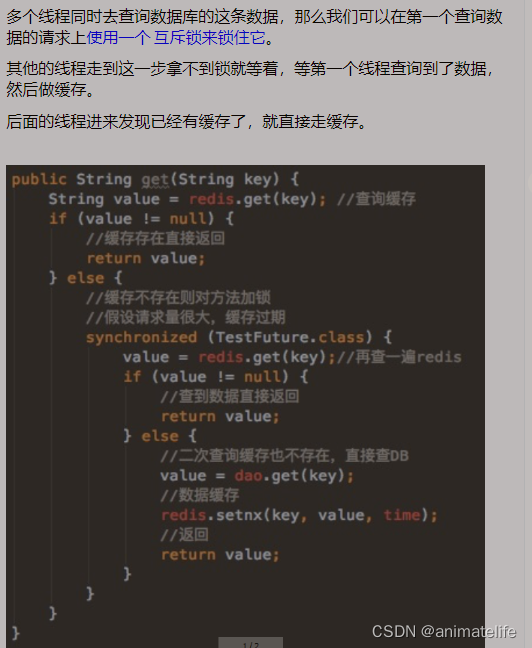
双检加锁
- redis 采用 IO多路复用 + 集群部署,所以可以承受大量的并发请求
- 数据库是不行的,涉及到事务、锁、连接池中的连接数量等限制,无法承受太大的并发请求
- 所以使用 双检加锁(单例模式也有同样的实现方案)
一致性写

一致性写的实现
- 分布式系统下的一致性,都是最终一致性,意味着数据更新过后,依然有可能会从缓存中读取到旧值
应用停机更新
- 这种算是异步缓写策略了,一般是业务最不活跃的时间,且使用单线程将数据同步到缓存(因为这种数据变更的累积同步,一般数据量不会小)
先更新数据库,再更新缓存
- 更新数据库,不会出现太大问题,更新失败则直接返回,多个线程并发修改数据库,因为 连接池 + 事务的特性 + 锁,不会产生脏数据
- 更新缓存,可能遇到的问题
- 缓存更新失败,但是数据库已经更新完成
- 缓存更新的请求出现延迟,并发场景下,时间顺序靠后的请求先被 redis 接收到,导致 redis 执行更新指令的顺序出现倒置,旧值覆盖新值
先更新缓存,再更新数据库
- 这个方案不理解,数据库作为数据的保底依据,一定要保证数据库的数据是最新的
- 先更新缓存,可能出现的情况
- 更新缓存失败,直接返回
- 在这里还有可能产生 旧值覆盖新,所以更新的同时还需要做一定的乐观锁措施
- 更新数据库
- 更新失败,直接返回,但是缓存更新成功
先删除缓存,在更新数据库
- 删除缓存,不会有太大的问题产生,删除失败直接返回,或者删除失败后,把失败消息交给MQ,后续重试
- 更新数据库
- 更新失败,直接返回
- 更新成功,缓存中的值有可能为 空 或者 旧值
- 为空的时候,由 双检加锁 保证同步更新缓存
- 为旧值的时候,有两种情况
- 前面删除缓存失败,但是没有直接失败返回,用 MQ 重试,这种情况不会存在太长时间,由 MQ 兜底
- 在删除缓存 到 更新数据库完成期间,有别的线程通过 双检加锁,将数据库的旧值重新写回到了 缓存,所以针对这种情况 提出了 延迟双删 的方法
延迟双删
- 双删是指,在完成前面步骤的情况下,即数据库更新完成后,再删除一次缓存(开头已经删过一次了)
- 需要注意的是,为了保证一定能在 旧值被写入缓存后被删除,即出现上述的情况后,能够有效删除缓存的旧值,就必须估算出一个请求完成 双检加锁 的大概时间
- 延迟就是指,延迟这个估算出来的大概时间,再多个几百毫秒后,再次删除缓存
- 延迟的时间虽然不高,但是对吞吐量还是有一定影响的,可以通过异步线程的方式完成最后的延时删除(吹毛求疵,这点吞吐量才多少)
先更新数据库,再删除缓存
- 更新数据库,失败直接返回,成功继续下一步
- 删除缓存
- 删除成功,但是再删除成功之前,已经有请求命中缓存,读走了旧值(客户端提示刷新解决)
- 删除失败,将失败的消息发送到 MQ ,通过 MQ 重试兜底
强一致性同步
- 通过 canal,读取 mysql 的 binlog,将更新同步到缓存
- 只能针对 热点数据 使用
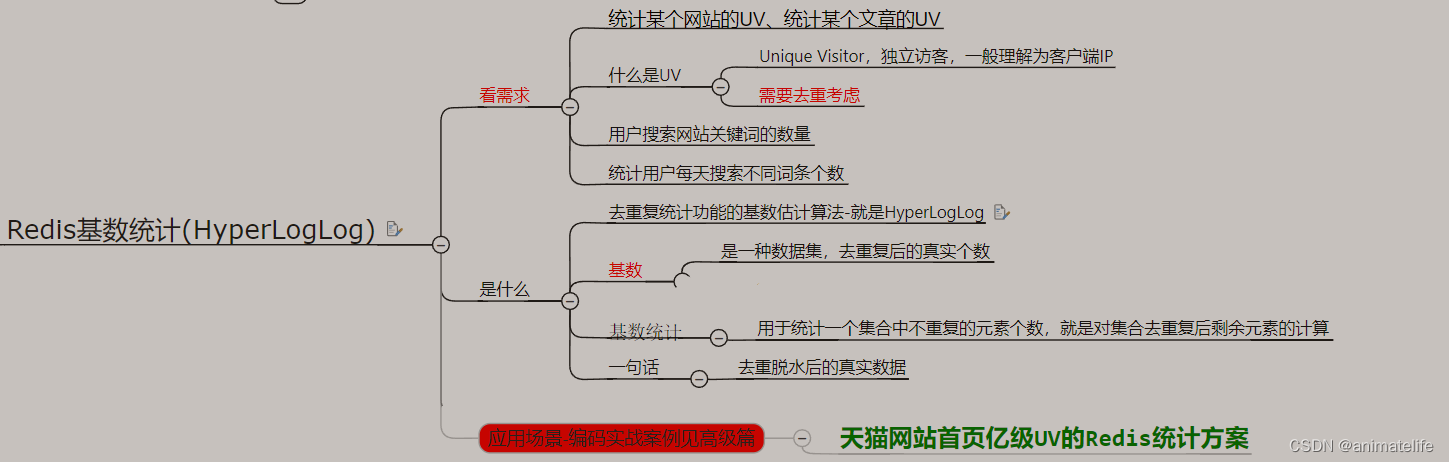
redis 统计应用(大数据分析)

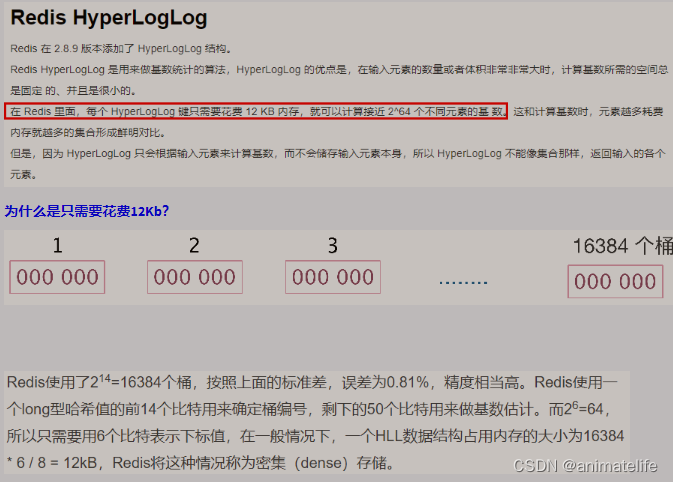
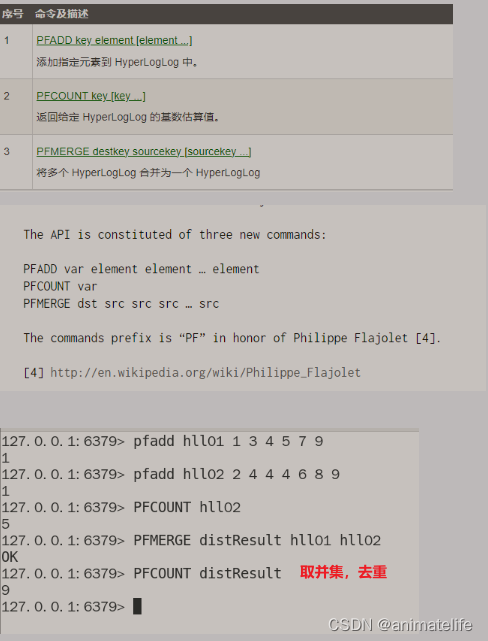
基数统计 HyperLogLog
- 基数统计 HyperLogLog 用于去重统计
- 放入多条记录,仅返回去重后的记录条数
- 通过牺牲准确率来换取空间,对于不要求绝对准确率的场景下可以使用,因为概率算法不直接存储数据本身
- HyperLogLog 就是一种概率算法的实现
- 误差在 0.81% 左右
- 能用于去重统计还有 HashSet、bitmap,但不适用于大体量数据的去重统计
UV、PV、DAU、MAU

二值统计 bitmap 布隆过滤器

- 布隆过滤器(Bloom Filter) 是一种专门用来解决去重问题的高级数据结构,实质就是一个大型 位数组 和几个不同的无偏hash函数(无偏表示分布均匀)
- 由一个初值都为零的 bit 数组(就是 bitmap)和多个哈希函数构成,用来快速判断某个数据是否存在
- 跟 HyperLogLog 一样,它也一样有那么一点点不精确,也存在一定的误判概率

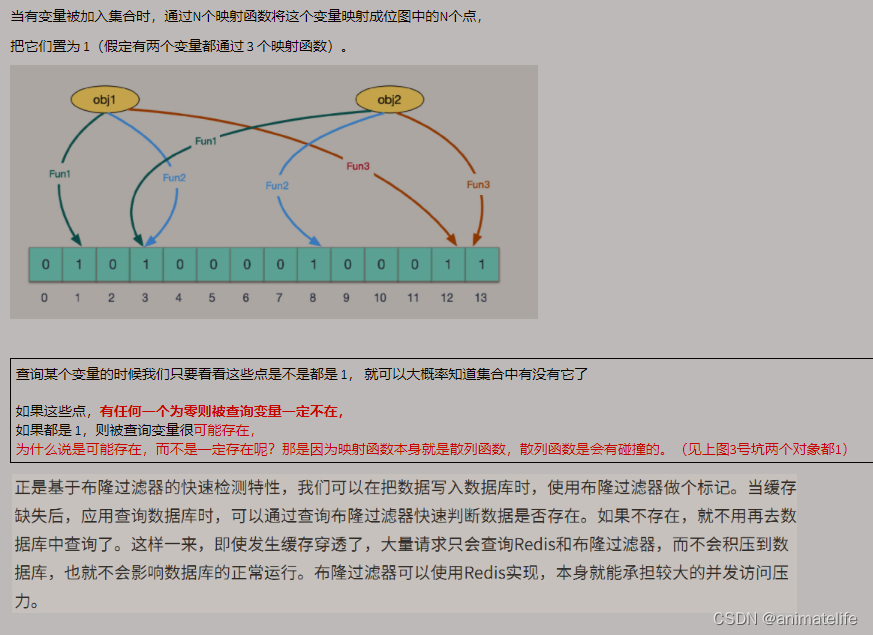
- 通过上图可以得知,一个元素存储到BloomFilter 的过程,就是先通过 N 个不同的 Hash 函数对存入的元素进行 Hash 运算,运算过后对得到的 N个值 分别和 bitmap 的长度 取余,得到对应于该元素的多个 位置,然后将这些位置的二进制位都置为1(true),这就是映射函数的大致执行过程(中间一般会有别的处理,因为计算得到的 hash 值可能为负数,这个时候需要取绝对值)
- 映射的核心就是 Hash 函数计算 hash 值,Hash 是有概率发生 Hash 碰撞的
- 所以使用 布隆过滤器进行数据存在与否的判断,也会有误判
- 综上判断一个元素是否在一个大集合中,有两种情况
- 根据映射函数得到该元素在 bitmap 中的多个二进制位的位置,然后判断是否都为1,如果都为1,那说明该元素大概率存在
- 如果多个二进制位中,不全为1,那么该元素一定不存在于集合中
- 使用 BloomFilter 需要注意 bitmap 的初始长度,不要让实际元素数量,超过初始化数量,避免扩容
- 实际元素数量:即实际添加到 布隆过滤器 的元素数量
- 初始化数量:根据映射函数,可以知道存储一个元素需要多少个二进制位,按照这个关系设置 bitmap 的长度
- 为什么避免扩容:bitmap 长度也会参与映射函数的计算过程,如果此时需要扩容,意味着参与映射函数计算的常量也发生了改变,映射关系就发生了改变
- 当实际存储的元素数量,超过初始化数量时,扩容应该是创建更长的 bitmap ,然后将原来 布隆过滤器 中的元素都重新 add 到新的 bitmap 构成的布隆过滤器
- 布隆过滤器 不能删除元素,因为有可能多个元素共用相同的二进制位 或 使用的二进制位有交集,删掉一个元素意味着删掉了不定数量的元素 并且 还有可能改变其他元素的存在状态,因为删除意味着将相应的 bitmap 中的 二进制位置为0(false)
- 为了解决布隆过滤器不能删除元素的问题,产生了一种新的过滤器,布谷鸟过滤器
- 布隆过滤器的应用场景

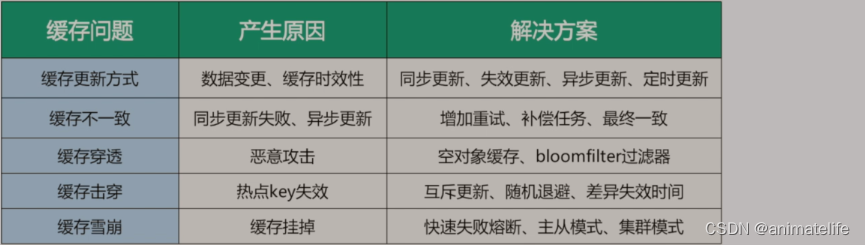
缓存问题
缓存预热
- 缓存预热:就是让需要的数据提前存到 redis ,增加用户体验,而非通过用户访问应用时,利用 双检加锁 将数据同步到 redis
- 在应用启动时通过添加了
@PostConstruct的方法,随着 bean 对象的生成而将需要存到 redis 的数据也随之同步到 redis - 由内部人员提前触发 双检加锁 ,将数据同步到 redis
- 在应用启动时通过添加了
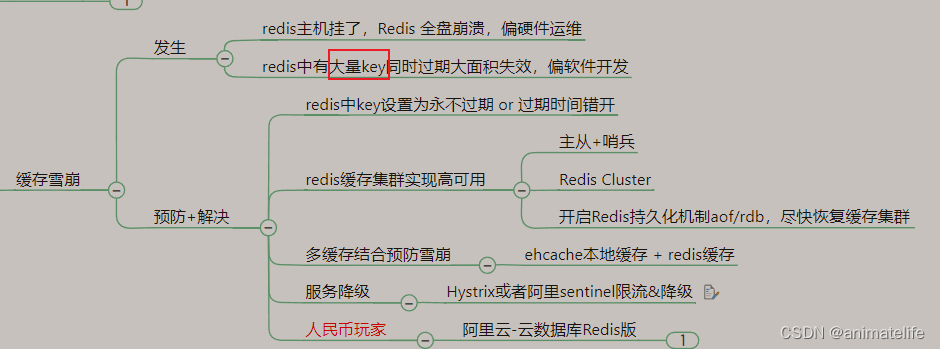
缓存雪崩
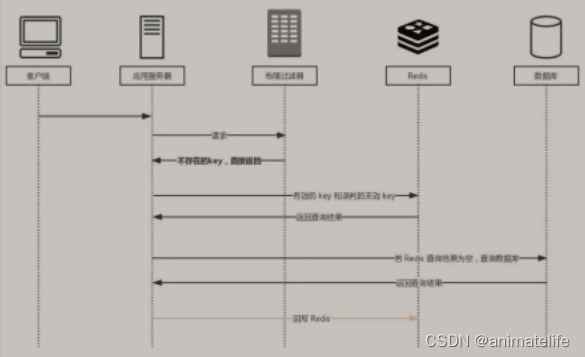
缓存穿透
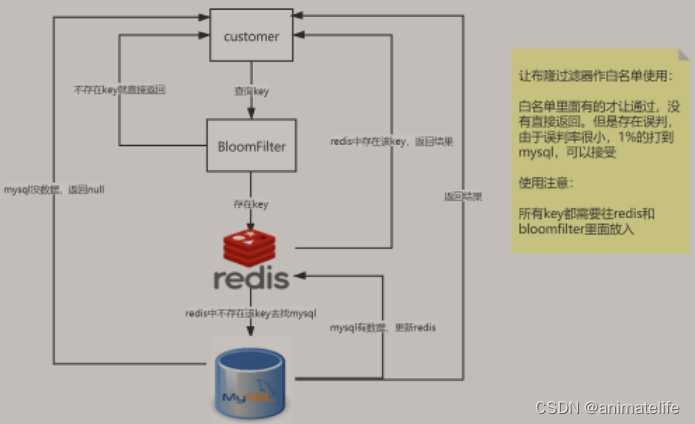
- 缓存穿透:查询的数据在 redis、MySQL中都没有,导致每次请求都打在 MySQL上
- 解决办法:
- 设置空对象缓存,将查不到的 key 存一份空对象 或 其它商量好的数据,当服务器返回这个值就意味着,这是个没有任何业务意义的返回
- 设置 布隆过滤器(可以使用 Guava 的布隆过滤器),上面的方法只能解决正常情况下,发生不太频繁的缓存击穿,但是当面对恶意攻击、并发很大的情况下,空对象缓存 就十分浪费内存
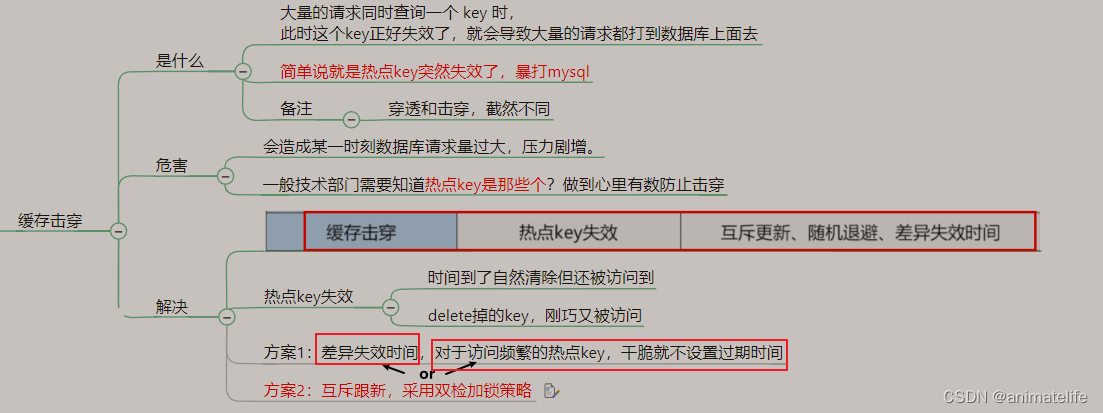
缓存击穿

redis 分布式锁
- 分布式锁,用于解决多个微服务共同操作一个数据时产生的数据可用性问题

- 每一个锁都应该遵循 JUC 下的 java.util.concurrent.locks.Lock 接口规范
使用 SETNX 实现分布式锁
- 有以下几个注意点:
- 要设置锁过期时间,且必须和创建锁时原子操作
- 取不到锁,可以通过自旋的方式(while)多次尝试获取锁,但是要注意自旋要有间隔
- 在 finall 中删除锁的时候,需要判断是否为本线程持有的锁
- 缺点:
- 不能做到可重入
- 看可以自动续期
- 删除锁的时候,就算判断了锁的归属,依然会有误删其它微服务的锁的可能性
- 判断锁的归属 和 删除锁 对 redis 而言是两次请求,分开的两条指令,意味着 锁过期的情况下,就会删除别的微服务设置的锁
- 不能高可用,存储作为分布式锁的 key 的 redis 一般是单独出来的,不与存储业务数据的 redis 混合
- 当只有一台 redis 时,会出现单点问题
- 集群 或 哨兵 + 主从,会出现一锁多建多用

Hash + Lua 实现分布式锁
Lua

- 可以在 Redis 中通过指令
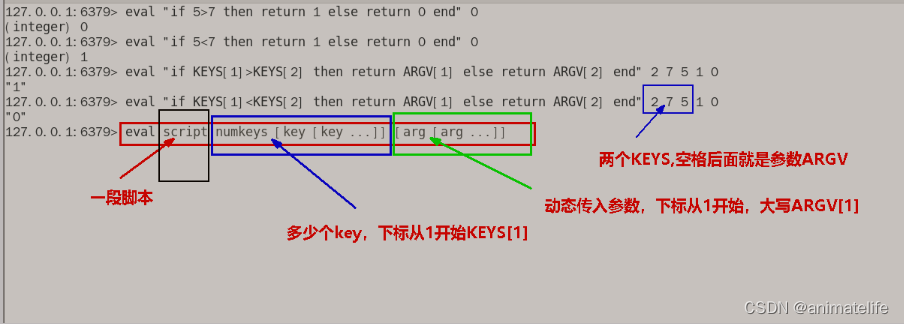
eval luascript numkeys [key[key...]] [arg[arg...]]使用 Lua 脚本实现多条指令的原子性- numkeys 必须指定,它是指脚本中用到的 key 的个数,也是后面 [key[key…]] 的 key 的个数
- 必须要用 return 返回脚本执行的结果值(0-false、1-true)
- 双引号 里面的 参数用单引号


redis.call('具体的 redis 指令',’KEYS[n]‘,ARGV[n])返回具体的 redis 指令执行的返回值,KEYS[n]、ARGV[n]写法是固定的,只是数量是根据 redis 指令的不同,而不同- Lua 中的条件判断


可重入+独占+防死锁
- 可重入锁,通过 synchronized 的实现原理,可以知道可重入的关键在于,识别锁的持有者、获取锁的次数、释放锁的次数

- 为了实现可重入锁,所以必须使用 Hash 的数据结构
hset keyName keyHolder times
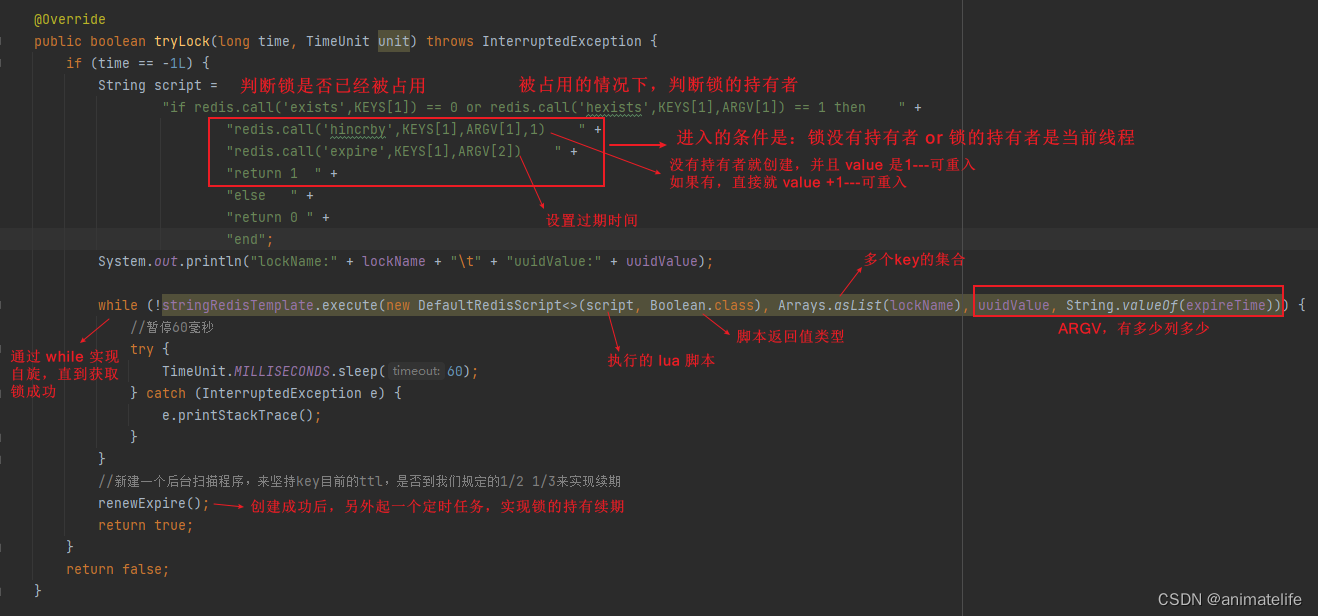
锁续期
释放锁(不乱抢)

Redisson(为了解决高可用)
- 上面两种方式都不能实现高可用,Redisson 是 java 语言使用 redis 分布式锁的 客户端,可以通过 jar 包的方式引入,它实现了高可用
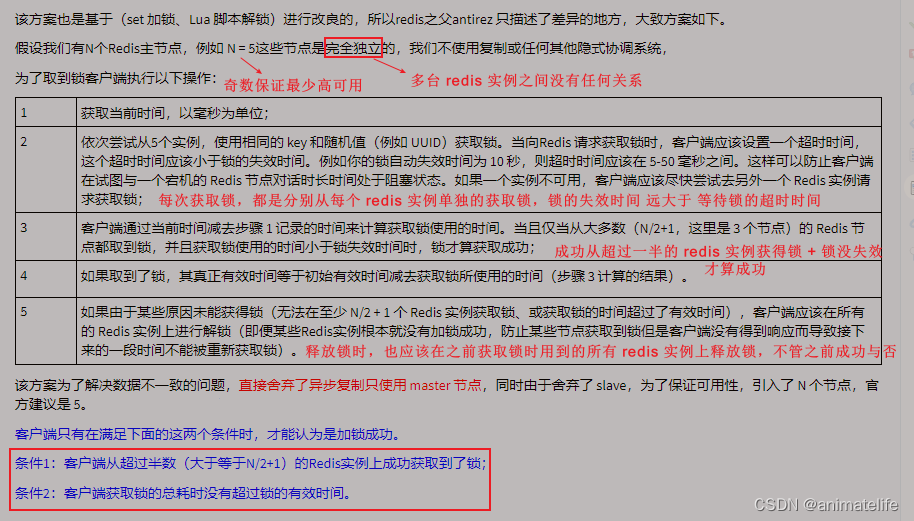
RedLock 红锁算法
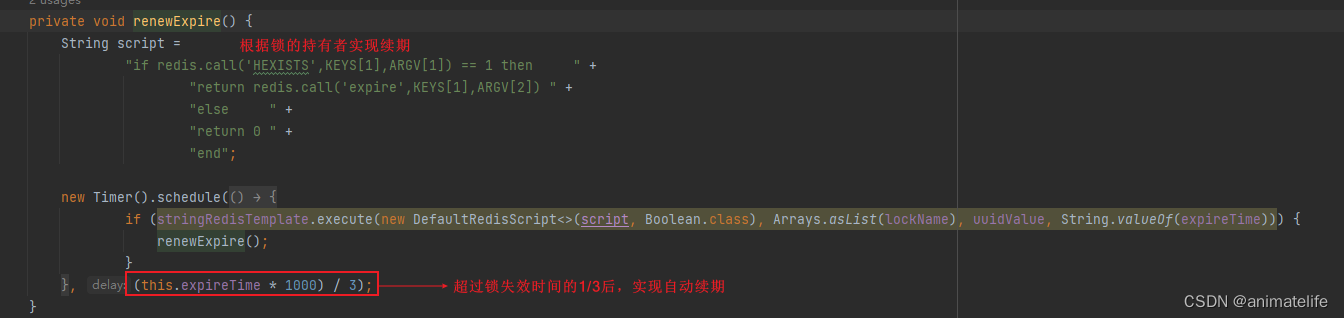
看门狗 实现续期
- 额外起一个线程,定期检查线程是否还持有锁,如果有则延长过期时间。Redisson 里面就实现了这个方案,使用“看门狗”定期检查(每1/3的锁时间检查1次),如果线程还持有锁,则刷新过期时间
- 没有指定失效时间的锁,其失效时间是 30s

- 看门狗就是一个不断启动定时任务,执行续期 Lua 脚本的后台线程
redis 内存
查看内存
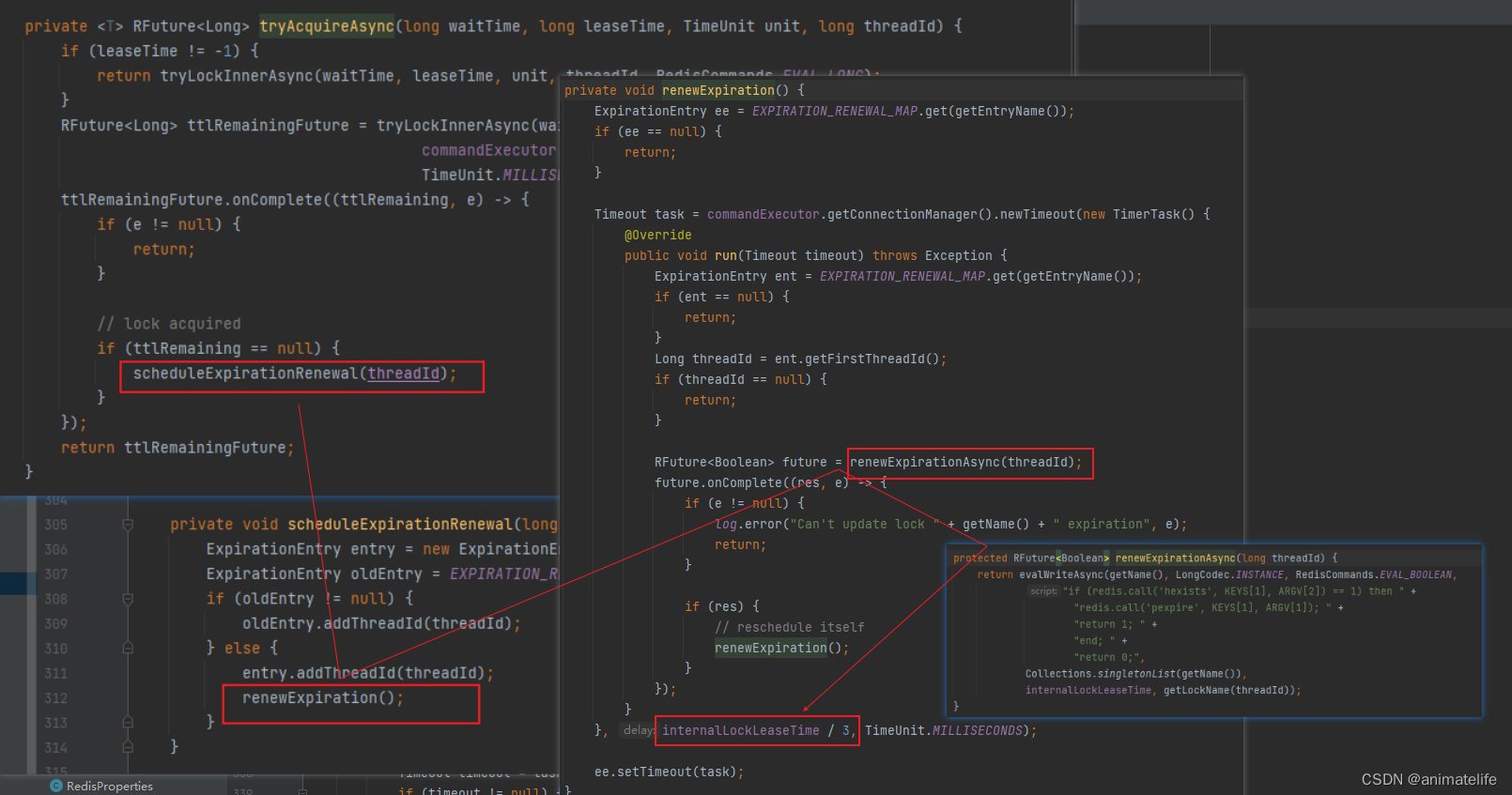
- 查看 redis 最大占用内存,通过 redis 的配置文件 reids.conf

- 通过命令查看
config get maxmemory
#查看内存使用情况
info memory
内存使用与管理
- 在没有指定 redis 最大使用内存时,maxmemory 的值为0

- 不限制 redis 使用的内存,有可能导致 服务器内存资源被沾满,导致服务器不可用
- 生产环境一般设置为当前 redis 所在服务器的最大内存的 3/4
- 对于过期 key 的删除
设置内存
- 修改配置文件 redis.conf

- 通过指令修改,这种方式重启后无效

内存溢出
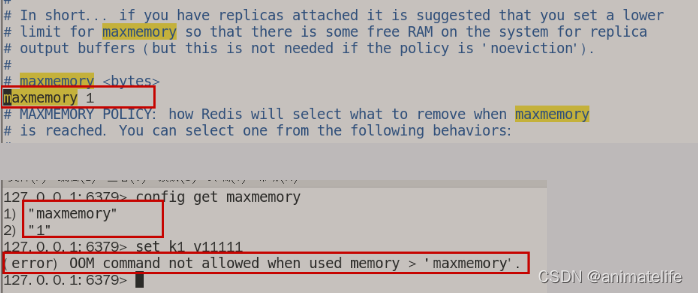
- 通过设置 redis 的最大内存为 1 B的情况,可以知道 redis 内存用满后的情况,用满后继续添加 数据到 redis 会报错 OOM
内存淘汰策略
- 知道了 redis 内存用满后会出现 OOM ,所以需要对 redis 的内存进行清理
- redis 本身提供了 8 种内存淘汰策略,通过 redis.conf 可以查看和修改内存淘汰策略,默认的内存淘汰策略是
noeviction
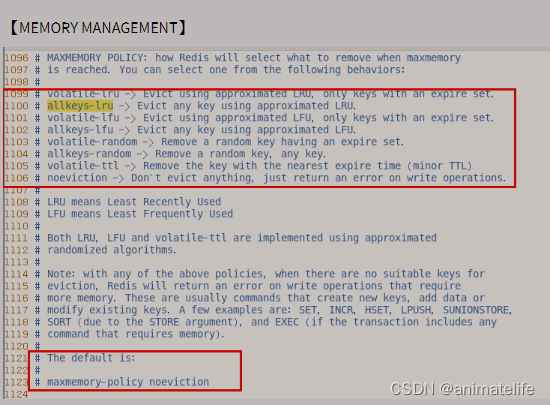

- 总结上面所有的可能
- 2种维度:所有 key & 快过期的 key
- 4个方面:lru、lfu、random、ttl
- 一般使用 第二种,两种修改方式
- 直接修改配置文件 redis.conf 如上上图所示的
maxmemory-policy allkeys-lru - 通过指令修改
config set maxmemory-policy allkeys-lru
- 直接修改配置文件 redis.conf 如上上图所示的
过期 key 的删除
- 以下内容更多详情参考文章
被动删除
- 开启惰性淘汰,修改配置文件 redis.conf ,
lazyfree-lazy-eviction=yes- 惰性/随性淘汰:过期的 key 不会马上删除,而是下次访问到时,直接返回客户端不存在,然后再删除对应 key
- 这种淘汰方式对 CPU 是友好的,删除操作只有在不得不的情况下才会进行,不会对其他的 expire key 上浪费无谓的CPU时间
- 对内存不友好,一个 key 已经过期,但是在它被操作之前不会被删除,仍然占据内存空间
- 如果有大量的过期 key 存在,但是又很少被访问到,那会造成大量的内存空间浪费
- 触发内存淘汰策略,当 redis 使用的内存超过 配置文件中 maxmemory 的值就会触发 redis 执行淘汰策略
- 淘汰策略并不是针对redis的所有key,而是以配置文件中的 maxmemory-samples 个 key 作为样本池进行抽样清理

- 这个参数的作用是:redis 不会准确的将整个数据库中最久未被使用的 key 删除,而是每次从数据库中随机取5个键并删除这5个键里最久未被使用的键
- 这个值如果设置为10,就近乎是将整个数据库中最久未被使用的 key 删除
- 这个清理过程是阻塞的,直到清理出足够的内存空间
- 如果在达到 maxmemory 并且调用方还在不断写入的情况下,可能会反复触发内存淘汰策略,导致请求会有一定的延迟
- 淘汰策略并不是针对redis的所有key,而是以配置文件中的 maxmemory-samples 个 key 作为样本池进行抽样清理
主动删除
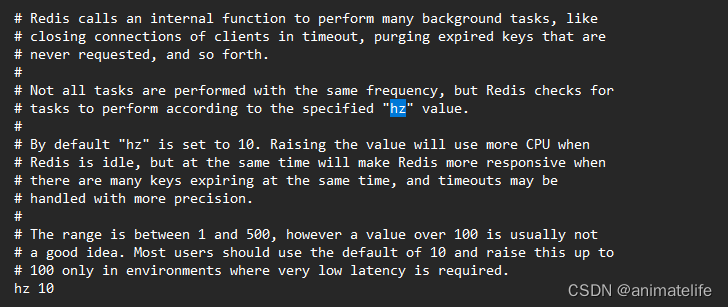
- 主动删除,即为定时删除,如上图所示的配置表示的是,每秒执行多少次内存清理
- 具体的执行过程,如下图所示,这个循环的过程有时长限定,超过时长就会终止本次清理

- hz 的值 和 上述清理内存的循环过程的最大时长成反比
- 结束一次 redis 主动清理的条件
- 降低到 25%
- 超出限定时长(hz 为 10 时,默认为250 ms)
内存使用总结
- 避免存储 BigKey
- 尽量不要触发 淘汰策略(结合业务调整 hz、maxmemory 的值)
- 内存压力不大时,可以开启惰性删除(redis 的作用不仅仅时内存,看具体的用途,大部分可能会占用大量CPU)














 2131
2131











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









