







运算放大器的串联:如何同时实现高精度和高输出功率
复合放大器
复合放大器由两个单独放大器组合而成,分别具有不同的特性。 图1所示就是这种结构。放大器1为低噪声精密放大器ADA4091-2。 在本例中,放大器2为AD8397,具有高输出功率,可用于驱动其他模块。
实现方法如下
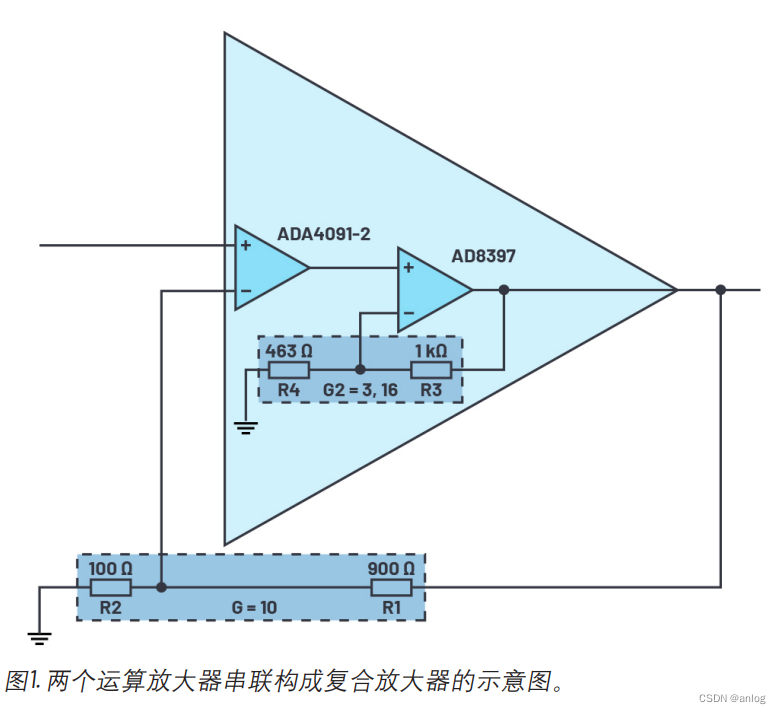
注意其中的第二级运放 AD8397 是一种 高输出电流放大器 这样就可以输出高电流。
图1所示的复合放大器的配置与同相放大器的配置类似,后者具有两个外部操作电阻R1和R2。将两个串联在一起的运算放大器看作一个放大器。总增益(G)通过电阻比设置,G = 1 + R1/R2。如果R3与R4电阻比发生变化,会影响放大器2 (G2)的增益,也会影响放大器1 (G1)的增益或输出电平。但是,R3和R4不会改变有效总增益。如果G2降低,G1将增加。
带宽扩展
复合放大器的另一个特性是具备更高带宽。相比单个放大器,复合放大器的带宽更高。所以,如果使用两个完全相同的放大器,其增益带宽积(GBWP)为100 MHz,增益G = 1,那么–3 dB带宽可以提高约27%。增益越高,效果越明显,但最高只能达到特定限值。一旦超过限值,可能会不稳定。两个增益分布不均时,也会出现这种不稳定的情况。一般来说,在两个放大器的增益均等分布的情况下,可获得最大带宽。采用上述值(GBWP = 100 MHz、G2 = 3.16、G = 10),在总增益为10时,两个放大器组合的–3 dB带宽可以达到单个放大器的3倍。
结论
通过将两个放大器串联在一起,可以将两者的出色特性相结合,从而获得使用单个运算放大器无法实现的结果。例如,可以实现具有高输出功率和高带宽的高精度放大器。图1所示的示例电路使用了轨到轨放大器AD8397(–3 dB带宽 = 69 MHz)和精密放大器ADA4091-2(–3 dB带宽 = 1.2 MHz),将两者组合得到的带宽比单个放大器(放大器1)的带宽要高2倍以上(G = 10)。此外,将AD8397和各种精密放大器组合,还可以降低噪声,并改善THD特性。但是,在设计中,还必须通过修正放大器配置来确保系统的稳定性。如果考虑所有标准,复合放大器也可能适用于各种要求严苛的广泛应用。
参考链接
实际使用历城仿真电路
下面是一个将2v电压转换为电流的实际应用电路仿真
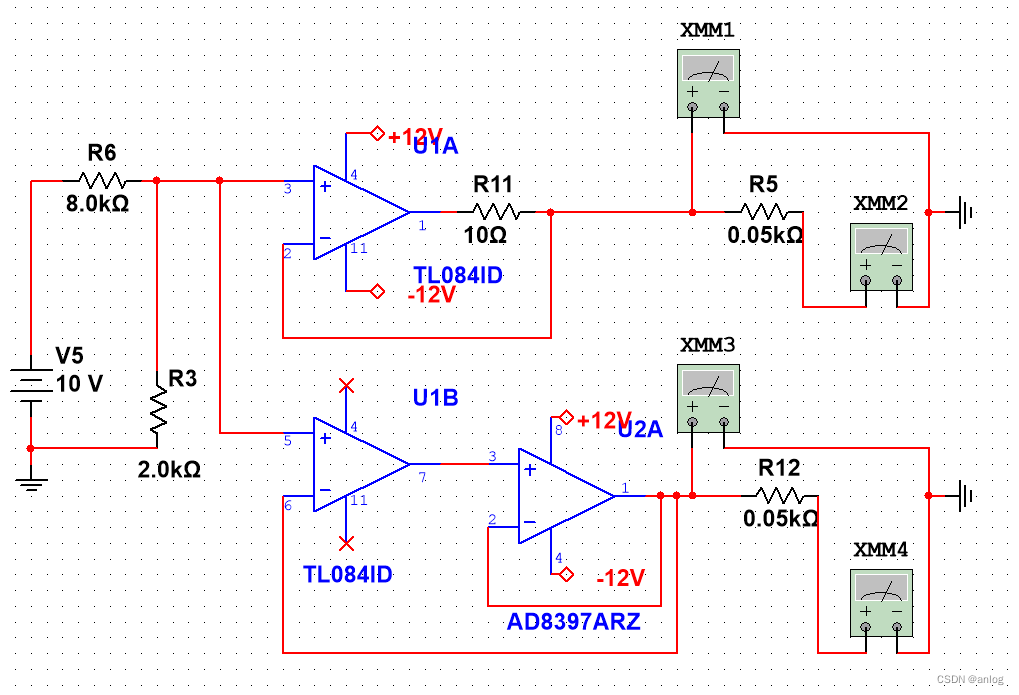
运行结果在负载电阻继续减小的情况下万用表XMM2的电流已经不正常了。
而万用表XMM4的电流依旧正常。如下图
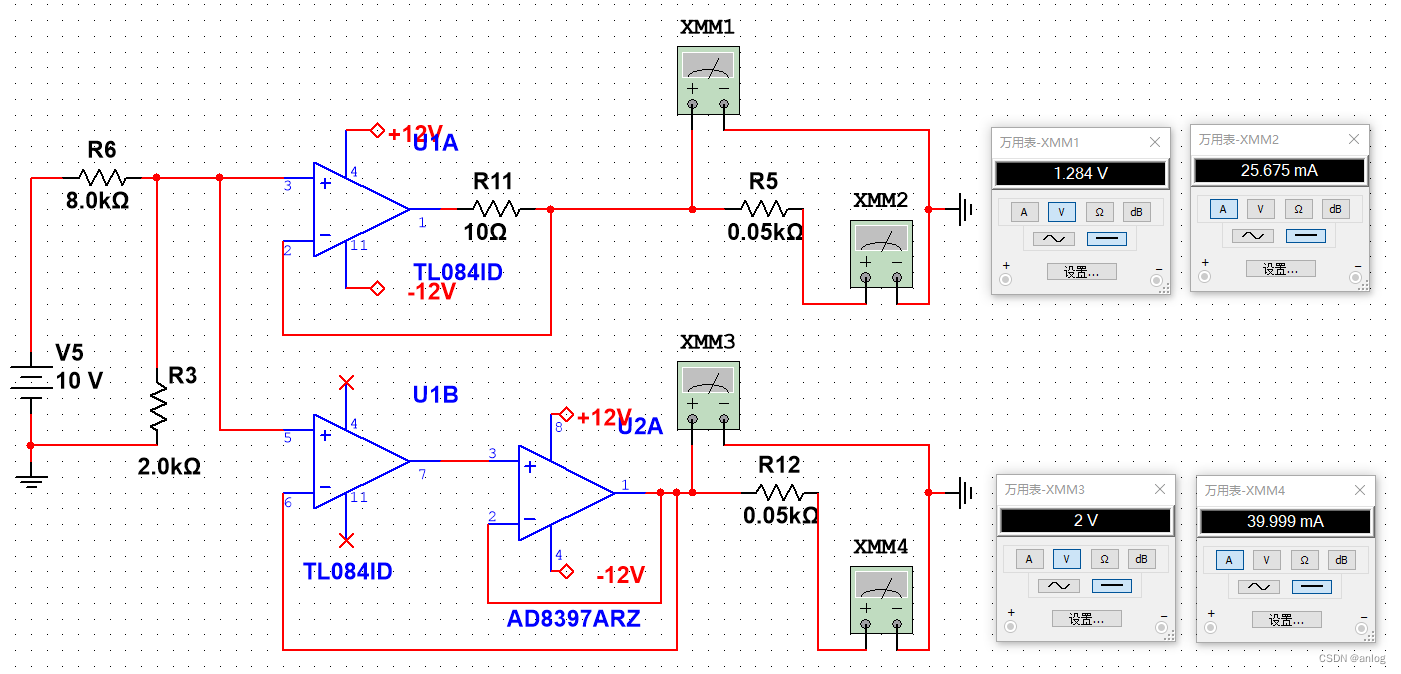
可以确定,使用AD8897 对运放的输出功率进行了扩展。当然此处没有使用放大反馈功能。仅仅是使用了跟随功能。但也很好的满足了电压转电流的目的。
特别题注 AD8397的特点

高输出电流特性可以上到310mA的输出电流。
其他一些不相关的信息
HIFIDIY论坛-运放并联输出 - Powered by Discuz! http://bbs.hifidiy.net/thread-1478108-1-1.html
http://bbs.hifidiy.net/thread-1478108-1-1.html
运放并联能实现双倍电流输出吗?
运放并联能实现双倍电流输出吗? - 模拟技术 - 电子发烧友网 (elecfans.com)https://www.elecfans.com/analog/20170408504804.html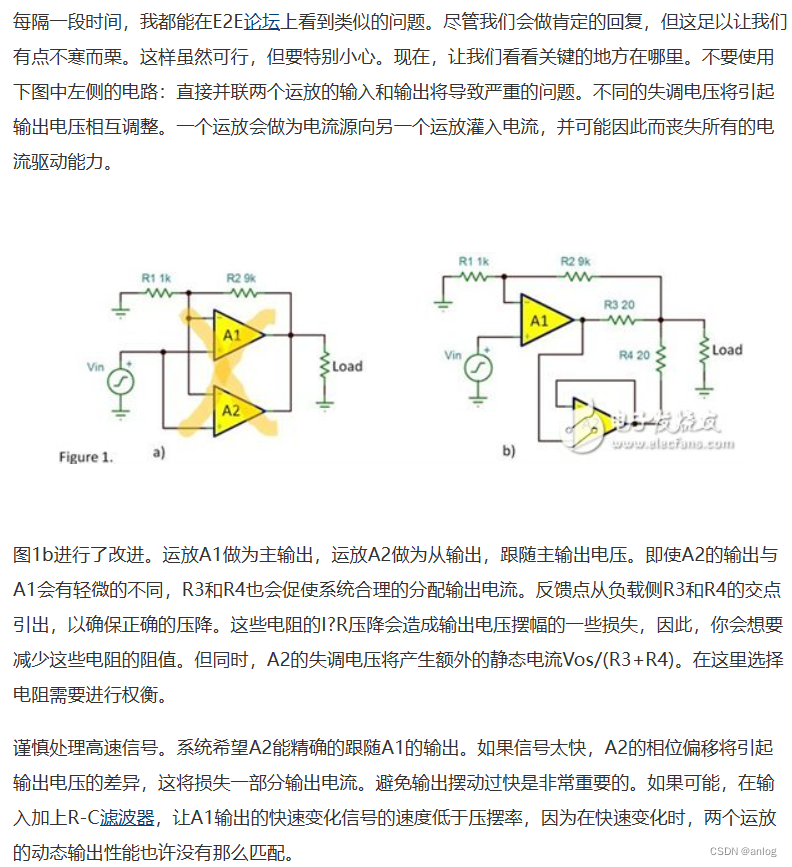

使用普通运放浏览扩展。也是可以使用的(放大较小是)
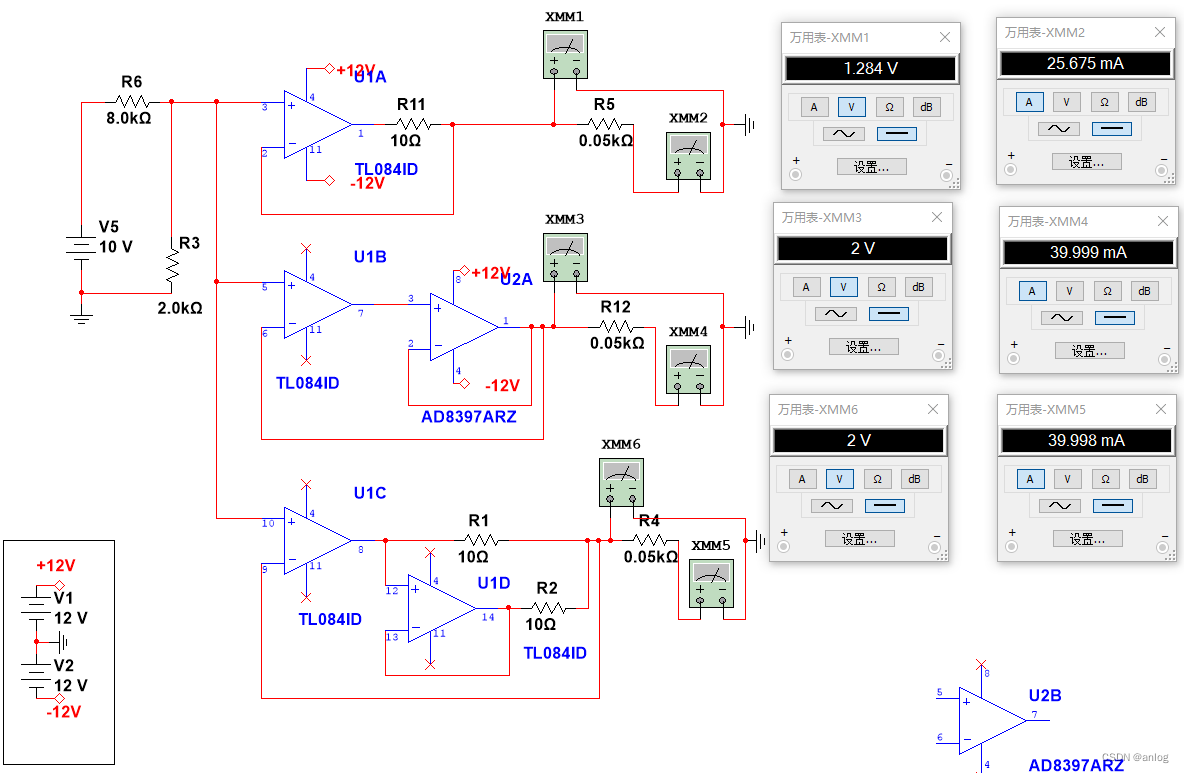
当然使用AD8379也可以双运放并联使用。
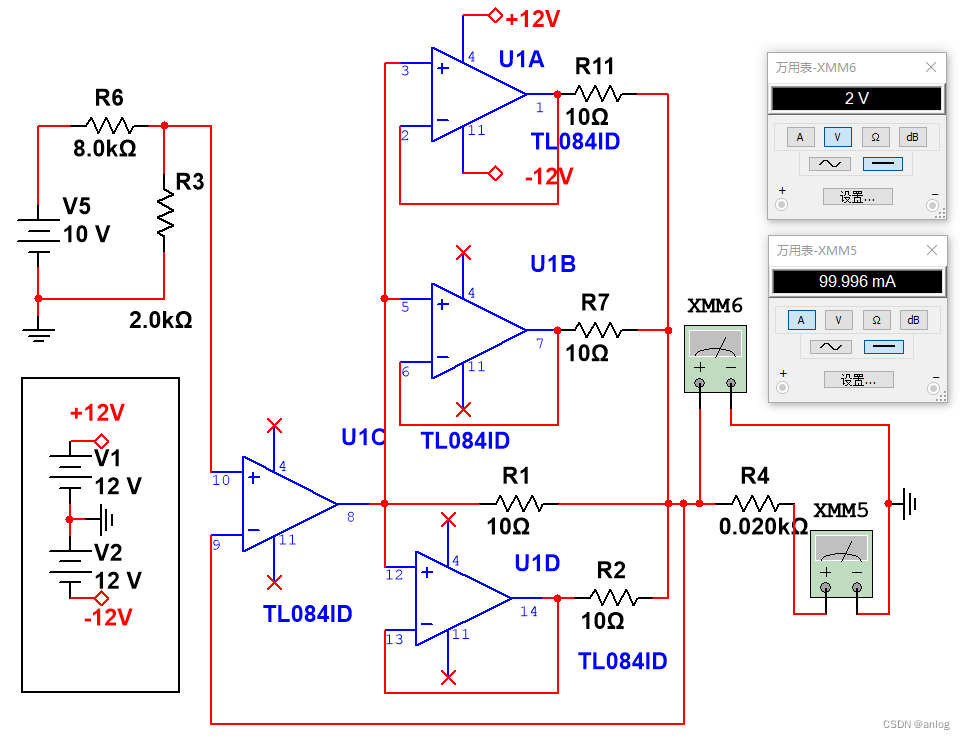
多个普通运放并联驱动。实际应用中还是需要注意运放种类,例如上图就不适合换成TL064
题注:图中的8K电阻是为了测试简单方便计算所使用的电阻。实际使用中当然不是直接使用8k电阻了。
特此记录
anlog
2023年5月18日

















 2595
2595

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









