






1)
鉴于多核处理器、GPU 以及 FPGA 和至强融核(Xeon Phi)等其他加速器的广泛应用,过去十年中并发编程的研究显著增加。为了改进并行程序的表达和执行,新的编程模型、语言和运行时系统应运而生。这些研究成果催生了许多新语言,例如 X10 [9]、Fortress [29] 和 Chapel [7],其中大多数语言构造默认支持并行(如 for 循环)。这些语言还提供了显式告知编译器某些内存区域相互独立的构造,因此对这些区域的访问可以并行执行。与这些主要面向科学计算的语言不同,Æminium 语言 [30] 专注于可靠系统编程。通过为变量标注访问权限,程序可以自动并行化,同时确保执行不会违反定义的契约。
2)
另一种编写并行程序的方法是半自动并行化。在这种方法中,程序员为现有的顺序程序添加足够的注释信息,以便编译器能够自动进行并行化处理。
代码的各个部分。Cilk [19] 和 OpenMP [11] 是这种方法最常见的两个示例,它们在 C 语言之上运行。Cilk 专注于分治递归算法,而 OpenMP 主要关注 for 循环中的对称并行性。OpenMP 3.0 通过任务 [2][3] 的概念引入了非结构化并行性。最近,OpenMP 也开始为 GPU 生成代码 [23]。
3)
第三种方法是将未经修改的顺序程序自动转换为其并行版本。像 LISP [20] 和 Haskell [25] 这样的函数式语言可以轻松实现并行化,因为其子表达式彼此不干扰。而 C 和 Java 等命令式语言使这项任务更加困难,因为代码的不同部分可能访问相同的内存位置。为了能够对代码进行并行化,必须进行一些验证。研究的主要焦点一直是 for 循环的并行化。根据循环类型的不同,可以使用不同的技术,例如 DO-ALL、DO-ACROSS 或 DO-PIPE。
- DO-ALL 并行性:循环迭代之间不存在任何干扰,每个迭代(或称为切片的一组迭代)可以并行执行,并且必须在 for 循环结束时进行同步。
- DO-ACROSS 并行性:循环中存在一部分(通常与其余部分相比最少)与其他迭代产生干扰。对于这些情况,可以进行变量私有化以按线程聚合值,然后在最后顺序执行另一个 for 循环来聚合私有变量。
- DO-PIPE 并行性:通过为 for 循环的不同部分使用不同的线程来实现并行化,其中不同线程之间的依赖关系被最小化。
为了验证循环是否可以并行化,多面体模型(Polyhedral Model)经常被使用 [6]。Cetus [12] 和 Par4All [1] 是执行这种转换的编译器,它们也可以针对 GPGPU。循环并行化已在运行时完成 [34],但没有实现任何显著的加速。
4)
自动非循环并行化的研究较少,但它仍是一种流行的并行表达方法,尤其是在分治算法中。zJava[8]通过分析局部级别的数据读写实现了这种分析。为了确保正确的并行化,zJava使用运行时区域注册表来分配线程,这使得线程可以在有同步开销的情况下访问共享数据。OoOJava[21]也通过静态分析检索带注释任务的读写信息,然后将程序编译为推测性C程序,通过运行时检查解决线程间冲突。由于这种推测机制,OoOJava不支持I/O指令。MPTomasulo[33]使用乱序指令为FPGA自动并行化代码,通过参数重命名消除写后读和读后写冲突,并分离控制流,但该方法与常规多核处理器不兼容。Jrpm[10]在运行时执行线程级推测,直接操作Java字节码而非Java代码,其加速比低于编译时策略。FJComp[28]同样基于Fork-Join框架聚焦分治算法,但编译器要求程序员手动标注任务并选择
分治算法的自动并行化。
5)
利用 Spoon 库 [26] 对 Java 抽象语法树(AST)进行操作。
JPar 编译器和 ÆminiumGPU 编译器。后两者利用 Spoon 库 [26] 对 Java 抽象语法树(AST)进行操作。
应该有工具把AST和C、Fortran语言对应起来?
7)
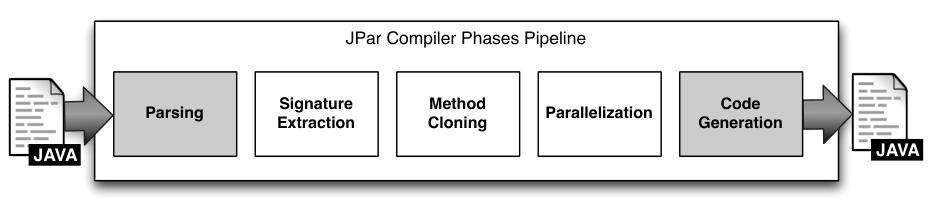
JPar 编译器是一款针对 Java 语言的源到源编译器。它将原始 Java 代码解析为抽象语法树(AST),
8)
ÆminiumGPU 编译器是一款针对 Java 语言的数据并行操作源到源编译器,可识别映射(map)和归约(reduce)等数据并行操作并将其转换为 OpenCL 代码。
9)
- 不得在所有已使用变量的声明之前声明;
- 不得在可能从该方法内部返回结果的表达式之前声明;
- 不得在可能改变该代码块内控制流(break、continue)的表达式之前声明;
- 不得在可能向 lambda 内部访问的变量写入数据的表达式之前执行;
- 不得在可能读取 lambda 内部写入的变量的表达式之前执行;
- 必须在 Future 的 get () 调用之前执行。
10)
ÆminiumGPU 编译器是一款从 Java 到 Java 的源到源编译器,其生成的最终 Java 代码包含一些额外的 OpenCL 代码。该编译器针对 Map-Reduce 风格函数内部使用的 lambda 函数进行优化。对于每个此类 lambda 函数,编译器会生成一个 OpenCL 函数。这个函数在编译阶段会作为内核进行编译,但如果与另一个函数合并,也可以在执行期间动态编译。这种将函数动态合并到单个内核的方式,旨在避免内核调度过程中的开销,以及减少 GPU 与内存之间的潜在数据传输开销。
11)
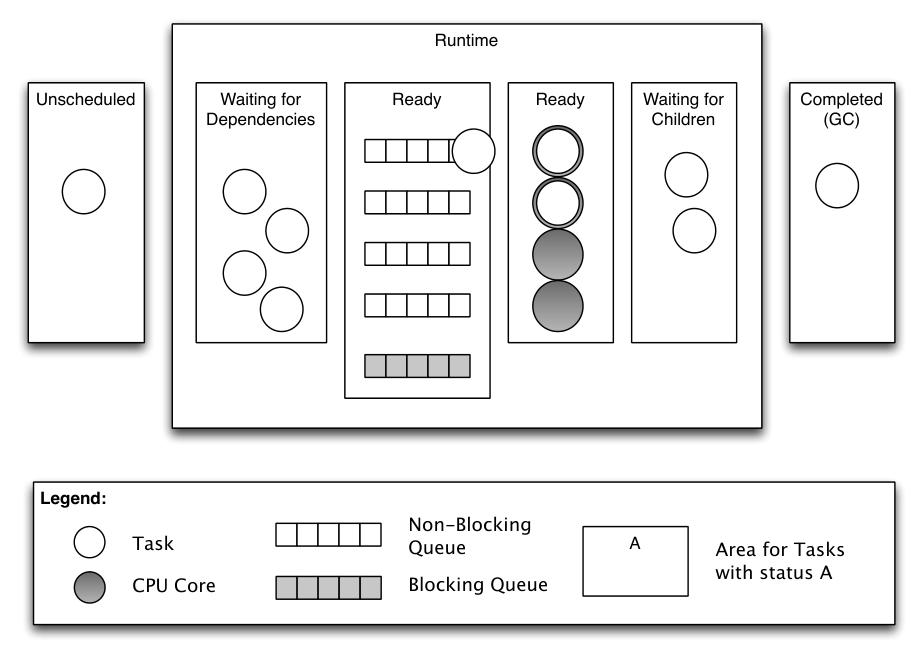
- **非阻塞任务**:指完全为计算型操作的所有任务。 - **阻塞任务**:指至少包含一个输入/输出操作的任务,例如磁盘读写、套接字通信或与操作系统的其他交互操作。 - **原子任务**:指与共享同一数据组的其他原子任务无法同时执行的任务。数据组充当锁,每个原子任务必须在执行前获取该锁,并在执行后释放。然而,具有不同数据组的两个原子任务可以并发执行。
12)



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









