






eval()与train()(结合源码理解)
结论
先上结论:eval和training实际上就是需要判断BN层(dorpout类似)中全局统计特征moving_mean和moving_variance是否需要迭代更新
1.eval()与train()的实质


从源码上不难看出,eval()和trian()实际上就是遍历了所有子模块,然后把其中的training属性给设置为Ture和False。
2.结合BN层理解
那么这个training属性有什么用呢,我们直接定位BN层的源代码,参考理解

抛开中间的部分,就看绿色的部分可以发现module中的training到了这里,通过training给bn_training进行了赋值。看到这会很自然产生两个问题,这个training怎么来的,这个bn_training又是什么捏。
training从何而来
我们看看上面图片中,这个定义的类叫_BatchNorm,它继承自_NormBase而这个_NormBase又继承自module,如下图所示:

所以module的training属性也就自然而然继承了过来,接下来看看bn_training又有什么用。
在先前起到的_NormBase类的forward中的return结果中,我们找到了bn_training的用处,如下图所示:
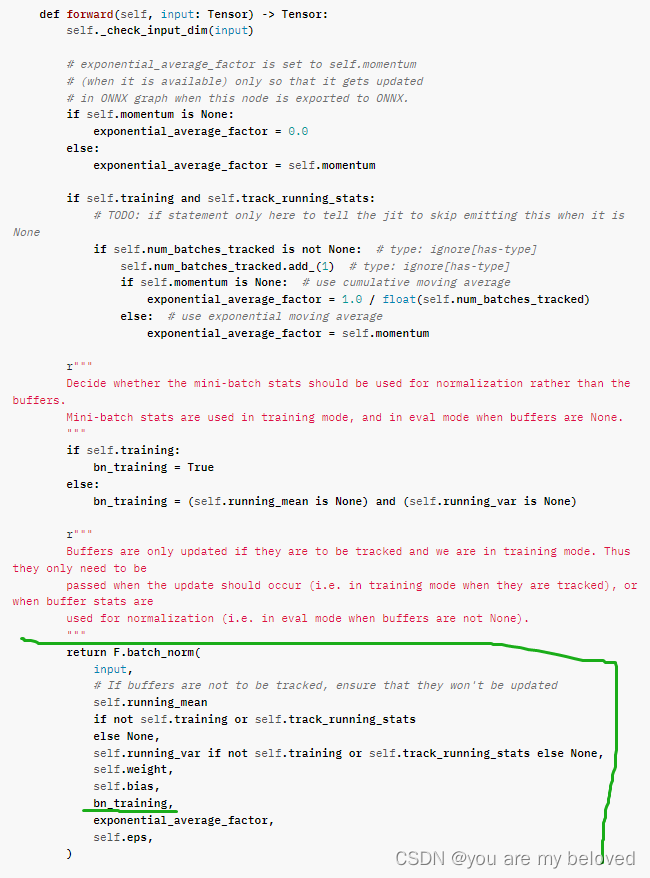
这个参数有什么用呢,自然就要追溯一下F.batch_norm方法是如何使用的
参考飞桨的开发文档如下:

通过BN层的原理我们可以知道,要对每个Batch进行标准化需要的是两部分,一部分是全局统计特征(moving_mean和moving_variance),一部分是局部也就是minibatch的统计特征,μβ 和 σ2β。
前一部分通过对每个batch的数据特征计算迭代得到(类似参数的更新,但不完全是,后面会提到),后一部分对当前batch计算即可得到。
所以综上可以得到,eval和training实际上就是需要判断这个全局统计特征moving_mean和moving_variance是否需要迭代更新,这不也就对应了train和validation的两个阶段吗:)。
另外提到的BN层的迭代类似参数但不是的原因是:moving_mean和moving_variance不是模型的参数,而是作为一个buffer保存在模型中,所以其更新与参数的更新(loss反传)不一样,与require_grad要区别开哦。(这里后续会继续开一篇文章讲解buffer、parameter、module的相关)
以上就是eval()和train()的理解,感兴趣的小伙伴可以点点关注蹲蹲后续的一些分享,同时欢迎各位大佬评论区留言指正!:)
参考资料:
[1].飞桨参考文档https://www.paddlepaddle.org.cn/documentation/docs/zh/api/paddle/nn/BatchNorm1D_cn.html#cn-api-nn-batchnorm1d
[2].pytorch官网
https://pytorch.org/














 5276
5276











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









