




 本文详细介绍了如何使用Spark SQL通过Iceberg库进行数据分析,涉及CatalogManager和SparkSessionCatalog的关键类及其交互过程,特别关注了如何配置和连接非Iceberg表。
本文详细介绍了如何使用Spark SQL通过Iceberg库进行数据分析,涉及CatalogManager和SparkSessionCatalog的关键类及其交互过程,特别关注了如何配置和连接非Iceberg表。
以sql调用来分析:
[hadoop@10 ~]$ spark-sql --master local \
--conf spark.sql.extensions=org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions \
--conf spark.sql.catalog.spark_catalog=org.apache.iceberg.spark.SparkSessionCatalog \
--conf spark.sql.catalog.spark_catalog.type=hadoop \
--conf spark.sql.catalog.spark_catalog.warehouse=hdfs://ns1/user/wanghongbing/db流程如下:
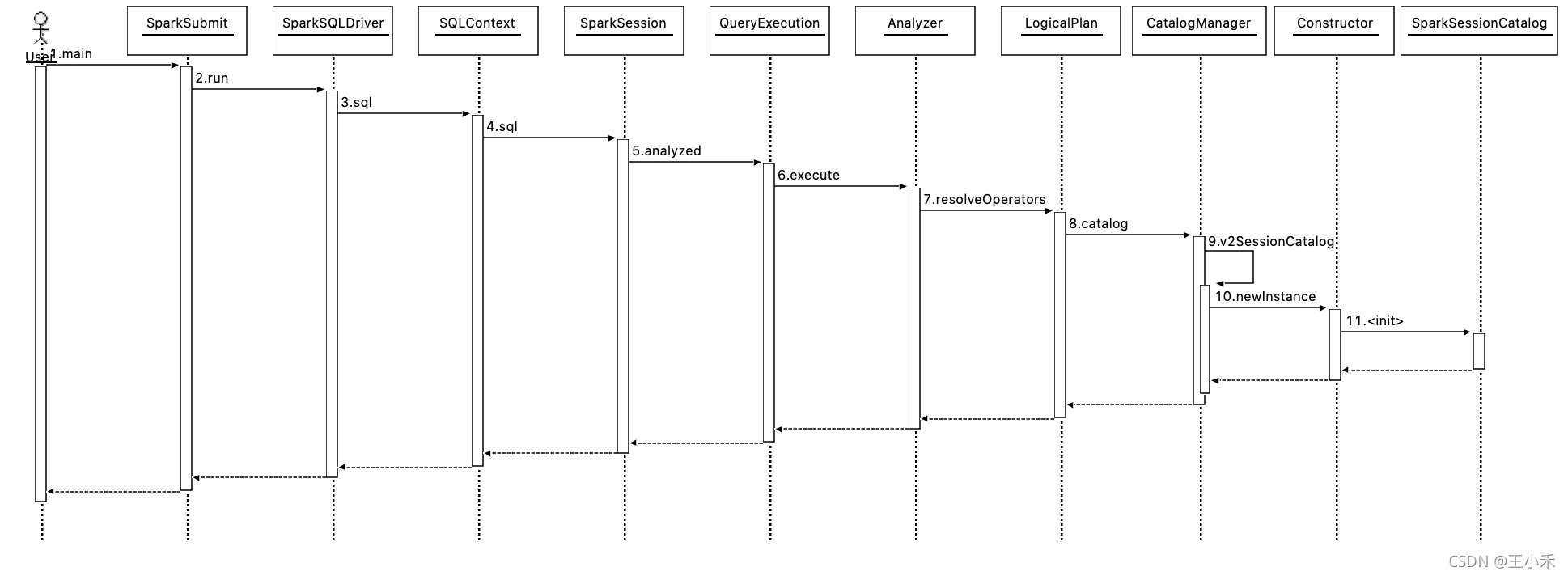
其中,spark包重要的类:
- org.apache.spark.sql.connector.catalog.CatalogManager
-
org.apache.spark.sql.connector.catalog.Catalogs
iceberg包对应的类:
- org.apache.iceberg.spark.SparkSessionCatalog
- org.apache.iceberg.spark.SparkCatalog
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1361
1361

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









