







http://antkillerfarm.github.io/
高斯混合模型和EM算法(续)
E-Step中,根据贝叶斯公式可得:
将假设模型的各概率密度函数代入上式,即可计算得到 w(i)j 。
相比于K-means算法,GMM算法中的 z(i) 是个概率值,而非确定值,因此也被称为soft assignments。
K-means算法各个聚类的特征都是一样的,也就是“圆圈”的半径一致。而GMM算法的“圆圈”半径可以不同。如下面两图所示:
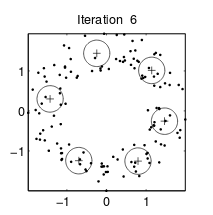 | 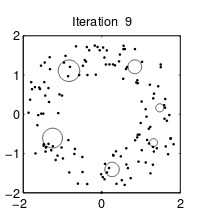 |
|---|---|
| K-means算法 | GMM算法 |
GMM算法结果也是局部最优解。对其他参数取不同的初始值进行多次计算同样适用于GMM算法。
参考:
http://cseweb.ucsd.edu/~atsmith/project1_253.pdf
EM算法
本节将进一步讨论EM算法的性质,并将之应用到使用latent random variables的一大类估计问题中。
Jensen不等式
首先我们给出凸函数的定义:
设f是定义域为实数的函数,如果对于所有的实数x, f′′(x)≥0 ,那么f是凸函数。当x是向量时,如果其Hessian矩阵H是半正定的( H≥0 ),那么f是凸函数。如果 f′′(x)>0 或 H>0 ,那么称f是严格凸函数。
Jensen不等式表述如下:
如果f是凸函数,X是随机变量,那么 E[f(X)]≥f(EX) 。
特别地,如果f是严格凸函数,那么 E[f(X)]=f(EX) ,当且仅当 p(X=EX)=1 。也就是说X是常量。
在不引起误会的情况下, E[X] 简写做 EX 。
这个不等式的含义如下图所示:
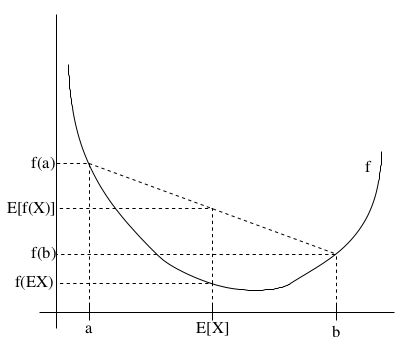
Jensen不等式应用于凹函数时,不等号方向反向,也就是 E[f(X)]≤f(EX)
注:Johan Ludwig William Valdemar Jensen,1859~1925,丹麦人。主业工程师,副业数学家。
EM算法的一般形式
EM算法一般形式的似然函数为:
根据这个公式直接求 θ 一般比较困难,但是如果确定了z之后,求解就容易了。
EM算法是一种解决存在隐含变量优化问题的有效方法。既然不能直接最大化 ℓ(θ) ,我们可以不断地建立 ℓ(θ) 的下界(E-Step),然后优化下界(M-Step)。
这里首先假设 z(i) 的分布为 Qi 。显然:
这里解释一下最后一步的不等式变换。
首先,根据数学期望的定义公式:
可知:
又因为 f(x)=logx 是凹函数,根据Jensen不等式可得:
综上,公式2给出了 ℓ(θ) 的下界。对于 Qi 的选择,有多种可能,那种更好的?
假设 θ 已经给定,那么 ℓ(θ) 的值就取决于 Qi(z(i)) 和 p(x(i),z(i)) 了。我们可以通过调整这两个概率,使下界不断上升,以逼近 ℓ(θ) 的真实值。当不等式变成等式时,下界达到最大值。
由Jensen不等式相等的条件可知, ℓ(θ) 的下界达到最大值的条件为:
其中c为常数。
这实际上表明:
其中的 ∝ 符号是两者成正比例的意思。
从中还可以推导出:
因为 ∑zQi(z(i))=1 ,所以上式可变形为:
可见,当 Qi(z(i)) 为 z(i) 的后验分布时, ℓ(θ) 的下界达到最大值。
因此,EM算法的过程为:
Repeat until convergence {
(E-step) For each i:
Qi(z(i)):=p(z(i)|x(i);θ)
(M-step) Update the parameters:
θ:=argmaxθ∑i∑zQi(z(i))logp(x(i),z(i);θ)Qi(z(i))
}
如何保证算法的收敛性呢?
如果我们用 θ(t) 和 θ(t+1) 表示EM算法第t次和第t+1次迭代后的结果,那么我们的任务就是证明 ℓ(θ(t))≤ℓ(θ(t+1)) 。
由公式1和2可得:
由之前的讨论可以看出,E-Step中的步骤是使上式的等号成立的条件,即:
因为公式3对于任意 Qi 和 θ 都成立,因此:
因为M-Step的最大化过程,可得:
综上可得: ℓ(θ(t))≤ℓ(θ(t+1))
事实上,如果我们定义:
则EM算法可以看作是J函数的坐标上升法。E-Step固定 θ ,优化Q;M-Step固定Q,优化 θ 。
重新审视混合高斯模型
下面给出混合高斯模型各参数的推导过程。
E-Step很简单:
在M-Step中,我们将各个变量和分布的概率密度函数代入,可得:
对 μl 求导,可得:
这里对最后一步的推导,做一个说明。为了便于以下的讨论,我们引入符号“tr”,该符号表示矩阵的主对角线元素之和,也被叫做矩阵的“迹”(Trace)。按照通常的写法,在不至于误会的情况下,tr后面的括号会被省略。
tr的其他性质还包括:
因为 μTlΣ−1lμl 是实数,由公式5.1可得:
由公式5.10可得:
因为 Σ−1l 是对称矩阵,因此,综上可得:
回到正题,令公式4等于0,可得:
同样的,对 ϕj 求导,可得:
因为存在 ∑kj=1ϕj=1 这样的约束,因此需要使用拉格朗日函数:
这里的 β 是拉格朗日乘子, ϕj≥0 的约束条件不用考虑,因为对 logϕj 求导已经隐含了这个条件。
因此:
令上式等于0,可得:
因为 ∑kj=1ϕj=1,∑kj=1w(i)j=1 ,所以:
因此:
因子分析
之前的讨论都是基于样本个数m远大于特征数n的,现在来看看 m≪n 的情况。
这种情况本质上意味着,样本只覆盖了很小一部分的特征空间。当我们应用高斯模型的时候,会发现协方差矩阵 Σ 根本就不存在,自然也就没法利用之前的方法了。
那么我们应该怎么办呢?
对 Σ 的限制
有两种方法可以对 Σ 进行限制。
方法一:
设定 Σ 为对角线矩阵,即所有非对角线元素都是0。其对角线元素为:
二维多元高斯分布在平面上的投影是个椭圆,中心点由 μ 决定,椭圆的形状由 Σ 决定。 Σ 如果变成对角阵,就意味着椭圆的两个轴都和坐标轴平行了。
方法二:
还可以进一步约束 Σ ,可以假设对角线上的元素都是相等的,即:
其中:















 259
259

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









