






字典dict定义是用’{}'括起来,内容是键值对,其中key是唯一的,不允许重复,存储的必须是不可变类型。
d1 = {'name':'张三',(23,4):[32]}
字典中的key就是索引
d1 = {'name':'张三',(23,4):[32]}
print(d1['name'])
输出结果:张三
例一:
d1 = {'name':'张三',(23,4):[32]}
d1['python']=100
d1['name']='李四'
print(d1)
输出结果:

由例一结果看出,当对key值进行操作的时候,对不存在的key值进行的是新建键值对的操作,对已有key值进行的是修改操作。
例2:
d1 = {'name':'张三',(23,4):[32]}
d1.update({'sex':'male'})
d1.update({'name':'kaka'})
print(d1)
输出结果:
 可以看出update()函数与例一的输出结果差不多,也是对不存在的key值进行的是新建键值对的操作,对已有key值进行的是修改操作。
可以看出update()函数与例一的输出结果差不多,也是对不存在的key值进行的是新建键值对的操作,对已有key值进行的是修改操作。
查看/增加
字典中的操作一般是:get()和setdefault()
get()例3:
d1 = {'name': 'kaka', (23, 4): [32], 'sex': 'male'}
print(d1.get('name')) #print(d1['name']的结果一致
输出结果:kaka
setdefaule()例4:
d1 = {'name': 'kaka', (23, 4): [32], 'sex': 'male'}
print(d1.setdefault('sex',100))
print(d1.setdefault('python',500))
print(d1.setdefault('java'))
print(d1)
输出结果:

以上是对setdefault()函数的运用,可以发现,当运用setdefault()函数的时候,如果是对存在的key值进行操作,就是查询的作用,即使是赋值也是无效的(给’sex’赋值为100,但结果依然是’male’);当对不存在的key值进行操作时,返回的是定义的值(‘python’不存在,所以返回定义值500);当对不存在的key值进行不赋值的操作,字典d1自动添加一对键值对,key值是’java’,value默认None。
注意:
dict1 = {'name':'张三','age':20,'gender':'男'}
dict1.update(masql=50)
print(dict1)
输出:
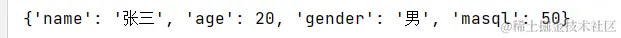
这里的update()也是新增,但是必须赋值,不然也会报错。
删除
在字典中删除的方法由pop()、popitem()、del、clear()
pop()
d1 = {'name': 'kaka', (23, 4): [32], 'sex': 'male'}
d1.pop('name')
print(d1)
输出:
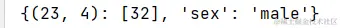
popitem()→默认删除最后一对
d1 = {'name': 'kaka', (23, 4): [32], 'sex': 'male'}
d1.popitem()
print(d1)
输出:
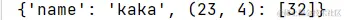
del→不指定值,默认全删
d1 = {'name': 'kaka', (23, 4): [32], 'sex': 'male'}
del d1['name']
print(d1)
clear()→清空
d1 = {'name': 'kaka', (23, 4): [32], 'sex': 'male'}
d1.clear()
print(d1)
输出:{}
修改
索引赋值:key必须是存在的
update():key必须是存在的
d2 = {'name':'王五'}
d2.update({'name':'Lucy'}) #等于d2 ['name':'Lucy']
print(d2)
输出:{‘name’: ‘Lucy’}
items()→查看所有键值对,keys()→查看所有key值,values()→查看所有values
dict1 = {'name':'张三','age':20,'gender':'男'}
print(dict1.items())
print(dict1.keys())
print(dict1.values())
输出:

以上情况多用于搭配for循环使用,例如:
dict1 = {'name':'张三','age':20,'gender':'男'}
dict1.items()
for k,v in dict1.items():
print('key:{},value:{}'.format(k,v))
输出:

序列操作:
| 运算符 | 支持的容器类型 |
|---|---|
| +(合并) | str、list、tuple |
| 运算符 | 支持的容器类型 |
|---|---|
| *(复制) | str、list、tuple |
| 运算符 | 支持的容器类型 |
|---|---|
| in(是否存在) | str、list、tuple、dict、set |
| 运算符 | 支持的容器类型 |
|---|---|
| not in(是否不存在) | str、list、tuple、dict、set |
print('123'*5)
输出:123123123123123
dict1 = {'name':'张三','age':20,'gender':'男'}
print('name' in dict1)
输出:True
序列
len():计算容器中的元素个数
del或者del():删除
max():返回容器中元素最大值
min():返回容器中元素最小值
range(start,end,step):生成从start到end的数字(不包括end),步长为step,供for循环使用
enumerate():用于将一个可遍历的数据对象(如字符串、元组或者列表)组合为一个索引序列,同时列出数据和数据下表,一般用于for循环
sum():序列求和
zip():合并序列
print(max('112df334'))
print(max([234,3,23,45,2]))
print(max(['234','3','23','45']))
输出:

字母数和数字大小的比较,是遵循ASCII码表来的,不清楚的同学,可以去百度看看ASCII码表。子母中A最小,Z最大,所有小写字母都比大写字母小。
enumerate()
for i in enumerate('helloword',10):
print(i)
输出:
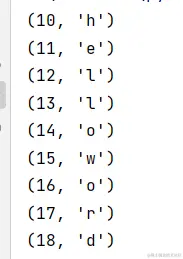
enumerate()中的第二位数字10,如果不写,默认从0开始编号。
print(sum([12,345,654,87]))
输出:1098
zip()
name = ['张三','李四','王五','赵六']
age=(45,32,29,54,62)
sex=['male','male','female','male']
result=zip(name,age,sex)
for i in result:
print(i)
输出:
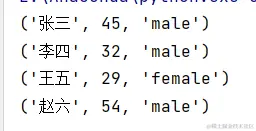
注意:由以上结果看出,zip()函数只取最少元素的数量
推导式
list1 = []
for i in range(1,11):
list1.append(i)
print(list1)
结果:
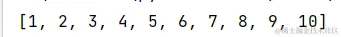
列表推导式:
list2 = [i for i in range(1,11) if i%2==0]
print(list2)
结果:

由以上列表推导式中注意:先判断for循环,在判断条件,最后再输出结果。
题外话

感兴趣的小伙伴,赠送全套Python学习资料,包含面试题、简历资料等具体看下方。
👉CSDN大礼包🎁:全网最全《Python学习资料》免费赠送🆓!(安全链接,放心点击)
一、Python所有方向的学习路线
Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照下面的知识点去找对应的学习资源,保证自己学得较为全面。


二、Python必备开发工具
工具都帮大家整理好了,安装就可直接上手!
三、最新Python学习笔记
当我学到一定基础,有自己的理解能力的时候,会去阅读一些前辈整理的书籍或者手写的笔记资料,这些笔记详细记载了他们对一些技术点的理解,这些理解是比较独到,可以学到不一样的思路。

四、Python视频合集
观看全面零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

五、实战案例
纸上得来终觉浅,要学会跟着视频一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

六、面试宝典

👉CSDN大礼包🎁:全网最全《Python学习资料》免费赠送🆓!(安全链接,放心点击)
若有侵权,请联系删除

















 1593
1593

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









