






好的数据结构。对于检索数据,插入数据的效率就会非常高。
常见的数据结构
B+树
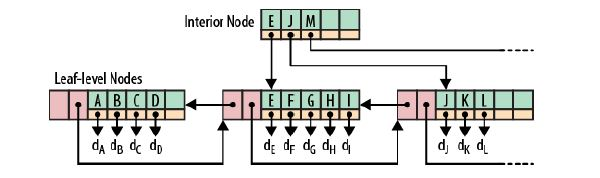
根节点和枝节点非常easy,分别记录每一个叶子节点的最小值,并用一个指针指向叶子节点。
叶子节点里每一个键值都指向真正的数据块,每一个叶子节点都有前指针和后指针。这是为了做范围查询时,叶子节点间能够直接跳转,从而避免再去回溯至枝和根节点。
特点:
1、有n棵子树的结点中含有n个keyword。每一个keyword不保存数据,仅仅用来索引,全部数据都保存在叶子节点。
2、全部的叶子结点中包括了全部keyword的信息,及指向含这些keyword记录的指针,且叶子结点本身依keyword的大小自小而大顺序链接。
3、全部的非终端结点能够看成是索引部分。结点中仅含其子树(根结点)中的最大(或最小)keyword。
缺点:
通常数据量会非常大,磁盘中的数据採用这样的分页形式的话,就会比較多。非常有可能存储的数据在两个页表其中不连续,相隔非常远,这样的顺序查询的方式就会比較慢。
B+树最大的性能问题是会产生大量的随机IO。随着新数据的插入,叶子节点会慢慢分裂,逻辑上连续的叶子节点在物理上往往不连续,甚至分离的非常远,但做范围查询时。会产生大量读随机IO。
对于大量的随机写也一样,举一个插入key跨度非常大的样例。如7->1000->3->2000 … 新插入的数据存储在磁盘上相隔非常远,会产生大量的随机写IO。从上面能够看出,低下的磁盘寻道速度严重影响性能。
LSM树
为了更好的说明LSM树的原理。以下举个比較极端的样例:
如今如果有1000个节点的随机key。对于磁盘来说,肯定是把这1000个节点顺序写入磁盘最快。可是这样一来,读就悲剧了,由于key在磁盘中全然无序。每次读取都要全扫描。
那么。为了让读性能尽量高,数据在磁盘中必须得有序。这就是B+树的原理,可是写就悲剧了,由于会产生大量的随机IO,磁盘寻道速度跟不上。
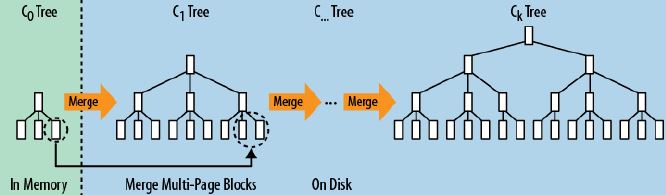
LSM树本质上就是在读写之间取得平衡,和B+树相比,它牺牲了部分读性能。用来大幅提高写性能。
它的原理是把一颗大树拆分成N棵小树, 它首先写入到内存中(内存没有寻道速度的问题,随机写的性能得到大幅提升),在内存中构建一颗有序小树,随着小树越来越大,内存的小树会flush到磁盘上。当读时,由于不知道数据在哪棵小树上。因此必须遍历全部的小树,但在每颗小树内部数据是有序的。
HBase数据存储格式
HBase引入了LSM树的概念,即Log-Structured Merge-Trees。
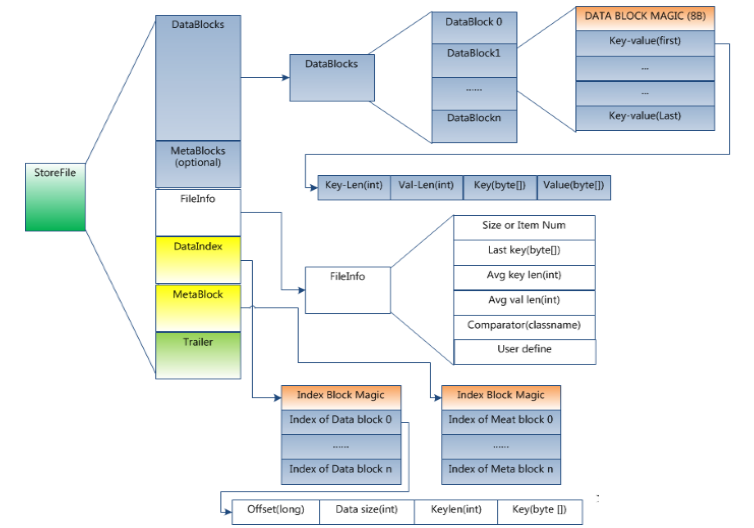
HFile格式
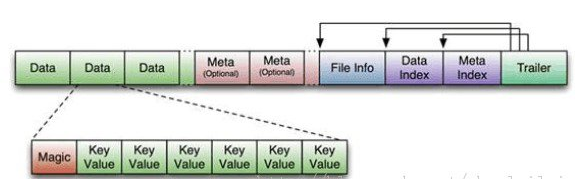
HFile分为六个部分:
Data Block 段
—–保存表中的数据,这部分能够被压缩。每一个数据块由块头和一些KeyValue组成。key的值是严格依照顺序存储的。块大小默觉得64K(由建表时创建cf时指定或者HColumnDescriptor.setBlockSize(size)) 。这一部分能够压缩存储。
在查询数据时。是以数据块为单位从硬盘load到内存。查找数据时,是顺序的遍历该块中的keyValue对。
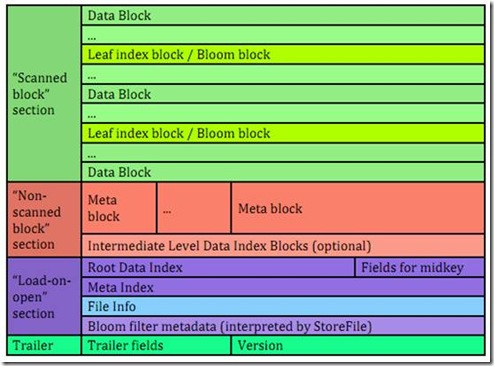
Meta Block 段 (可选的)
–—保存用户自己定义的key-value对。能够被压缩。
比方booleam filter就是存在元数据块中的,该块仅仅保留value值。key值保存在元数据索引块中。每一个元数据块由块头和value值组成。
能够高速推断key是否都在这个HFile中。
File Info 段
–—-HFile的元信息。不被压缩。用户也能够在这一部分加入自己的元信息。
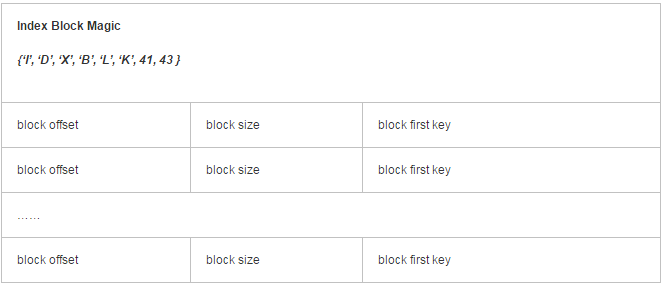
Data Block Index 段
—-–Data Block的索引,每条索引的key是被索引的block的第一条记录的key(格式为:头信息,(数据块在文件里的偏移 + 数据块长 + 数据块的第一个key),(数据块在文件里的偏移 + 数据块长 + 数据块的第一个key)。……..)。
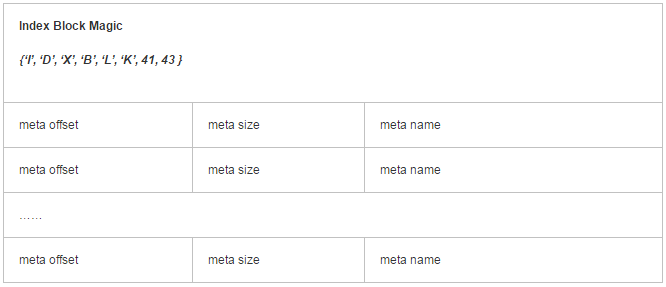
Meta Block Index段 (可选的)
–Meta Block的索引。 该块组成格式同数据块索引,仅仅是某部分的意义不一样。
Trailer
–—这一段是定长的。保存了每一段的偏移量。读取一个HFile时,会首先读取Trailer,Trailer**保存了每一个段的起始位置**(段的Magic Number用来做安全check)。然后,DataBlock Index会被读取到内存中,这样,当检索某个key时,不须要扫描整个HFile,而仅仅需从内存中找到key所在的block。通过一次磁盘io将整个 block读取到内存中,再找到须要的key。
DataBlock Index採用LRU机制淘汰。

说明例如以下:
1、 FileInfo Offset – FileInfo信息在HFile中的偏移。long(8字节)。
2、 DataIndex Offset – 数据块索引在HFile中的偏移。long(8字节)。
3、 DataIndex Count – 数据块索引的个数。int(4字节)。
4、 MetaIndex Offset – 元数据索引块在HFile中的偏移。long(8字节)。
5、 MetaIndex Count – 元数据索引块的个数。int(4字节)。
6、 TotalUncompressedBytes – 未压缩的数据块部分的总大小。long(8字节)。
7、 Entry Count – 数据块中全部cell(key-value)的个数。int(4字节)
8、 Compression Codec – 压缩算法为enum类型,该值表示压缩算法代码。(LZO-0,GZ-1,NONE-2),int(4字节)
9、 Version – 版本号信息。当前该版本号值为1. int(4字节)。
HFile的Data Block,Meta Block通常採用压缩方式存储。压缩之后能够大大降低网络IO和磁盘IO,随之而来的开销当然是须要花费cpu进行压缩和解压缩。
目标Hfile的压缩支持两种方式:Gzip,Lzo。
StoreFile格式
每一个Strore又由一个memStore和0至多个StoreFile组成。
StoreFile以HFile格式保存在HDFS上。
KeyValue对象格式
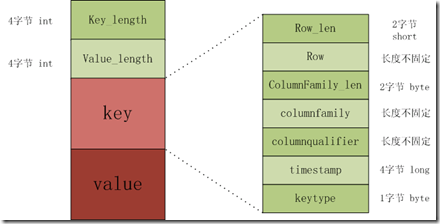
The KeyValue格式:
Keylength
valuelength
key
value其中keylength和valuelength都是整型,表示长度。
而key和value都是byte数据,key是有固定的数据,而value是raw data。Key的格式例如以下。
The Key format:
rowlength
row (i.e., the rowkey)
columnfamilylength
columnfamily
columnqualifier
timestamp
keytypekeytype有四种类型,各自是Put、Delete、 DeleteColumn和DeleteFamily。















 672
672

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









