







1、Apache HBase
1.1、HBase逻辑结构

1.2、HBase物理存储结构

1)Name Space:命名空间,类似于关系型数据库的database概念,每个命名空间下有多个表。HBase有两个自带的命名空间,分别是hbase和default,hbase中存放的是HBase内置的表,default表是用户默认使用的命名空间;
2)Table:类似于关系型数据库的表概念。不同的是,HBase定义表时只需要声明列族即可,不需要声明具体的列。这意味着,往HBase写入数据时,字段可以动态、按需指定。因此,和关系型数据库相比,HBase能够轻松应对字段变更的场景;
3)Row:HBase表中的每行数据都由一个RowKey和多个Column(列)组成,数据是按照RowKey的字典顺序存储的,并且查询数据时只能根据RowKey进行检索,所以RowKey的设计十分重要;
4)Column:HBase中的每个列都由Column Family(列族)和Column Qualifier(列限定符)进行限定,例如info:name,info:age。建表时,只需指明列族,而列限定符无需预先定义;
5)Time Stamp:用于标识数据的不同版本(version),每条数据写入时,系统会自动为其加上该字段,其值为写入HBase的时间;
6)Cell:由{rowkey, column Family, column Qualifier, time Stamp} 唯一确定的单元。cell中的数据全部是字节码形式存贮;
1.3、HBase基本架构

1)Region Server:Region Server为 Region的管理者,其实现类为HRegionServe;
2)Master:Master是所有Region Server的管理者,其实现类为HMaster,分配regions到每个RegionServer,监控每个RegionServer的状态,负载均衡和故障转移;
3)Zookeeper:HBase通过Zookeeper来做master的高可用、RegionServer的监控、元数据的入口以及集群配置的维护等工作;
4)HDFS:HDFS为Hbase提供最终的底层数据存储服务,同时为HBase提供高可用的支持;
2、HBase安装和使用
hadoop-3.1.3.tar.gz
apache-zookeeper-3.5.7-bin.tar.gz
hbase-2.0.5-bin.tar.gz
apache-phoenix-5.0.0-HBase-2.0-bin.tar.gz
2022-02-03 17:21:01,104 ERROR [Thread-15] master.HMaster: Failed to become active master
java.net.ConnectException: Call From hadoop102/192.168.2.34 to hadoop102:8020 failed on connection exception: java.net.ConnectException: 拒绝连接; For more details see: http://wiki.apache.org/hadoop/ConnectionRefused
The fs.defaultFS makes HDFS a file abstraction over a cluster, so that its root is not the same as the local system’s. You need to change the value in order to create the distributed file system.
注意:hadoop 3.X的HDFS文件系统访问端口号为9820,而不是8020
<configuration>
<property>
<name>hbase.rootdir</name>
<value>hdfs://hadoop102:9820/hbase</value>
</property>
</configuration>
2.1、HBase的启动与停止
# 单点启动
[atguigu@hadoop102 hbase-2.0.5]$ bin/hbase-daemon.sh start master
[atguigu@hadoop102 hbase-2.0.5]$ bin/hbase-daemon.sh start regionserver
# 群起
[atguigu@hadoop102 hbase-2.0.5]$ bin/start-hbase.sh
[atguigu@hadoop102 hbase-2.0.5]$ bin/stop-hbase.sh
2.2、namespace的操作
# 进入HBase的shell
[atguigu@hadoop102 ~]$ hbase shell
HBase Shell
Use "help" to get list of supported commands.
Use "exit" to quit this interactive shell.
For Reference, please visit: http://hbase.apache.org/2.0/book.html#shell
Version 2.0.5, rUnknown, Thu Jun 18 15:10:52 CST 2020
Took 0.0024 seconds
# 查看命名空间
hbase(main):025:0> list_namespace
NAMESPACE
default
hbase
2 row(s)
Took 0.0272 seconds
# 创建明明空间
hbase(main):031:0> create_namespace 'test'
Took 0.3161 seconds
# 查看命名空间
hbase(main):032:0> describe_namespace 'test'
DESCRIPTION
{NAME => 'test'}
Took 0.0077 seconds
=> 1
# 修改命名空间属性
hbase(main):033:0> alter_namespace 'test',{METHOD => 'set','author' => 'jieky'}
Took 0.2959 seconds
hbase(main):034:0> describe_namespace 'test'
DESCRIPTION
{NAME => 'test', author => 'jieky'}
Took 0.0097 seconds
=> 1
hbase(main):035:0> alter_namespace 'test',{METHOD => 'set','like' => 'study'}
Took 0.2554 seconds
# 清楚命名空间属性
hbase(main):039:0> alter_namespace 'test',{METHOD => 'unset',NAME => 'like'}
Took 0.2505 seconds
# 删除命名空间
hbase(main):041:0> drop_namespace 'test'
Took 0.3004 seconds
2.3、HBase Shell表操作
3、HBase进阶
3.1、RegionServer 架构

3.2、Hbase的读写流程
3.3、HBase的Java API操作
4、HBase优化
5、Apache Phoenix
Apache Phoenix enables OLTP and operational analytics in Hadoop for low latency applications by combining the best of both worlds:
1)the power of standard SQL and JDBC APIs with full ACID transaction capabilities and
2)the flexibility of late-bound, schema-on-read capabilities from the NoSQL world by leveraging HBase as its backing store
Apache Phoenix is fully integrated with other Hadoop products such as Spark, Hive, Pig, Flume, and Map Reduce.
- phoenix开启schema对应hbase中的namespace
- Hbase2.0.5-整合Phoenix实际操作
- Phoenix 的 “thick Client” 和 “thin Client”
- phoenix构建二级索引
- 详细介绍HBase 与 Hive 集成使用
5.1、Hive、Hbase、Phoenix字段类型
Hive所有字段类型汇总
HBase 支持的数据类型
phoenix_字段类型
HBase 通过 Put 操作和 Result 操作支持 “byte-in / bytes-out” 接口,所以任何可以转换为字节数组的内容都可以作为一个值存储。输入可以是字符串、数字、复杂对象、甚至可以是图像,只要它们可以呈现为字节。值的大小有实际的限制(例如,在 HBase 中存储 10-50MB 的对象可能太多了)。
计算机存储的是补码,HBase值经过二进制编码Bytes.toBytes(),数值以补码的形式存储在计算机中,Phoenix在读取HBase编码的数据时把第一位取反,其他位不变。因此使用HBase写入的int值,Phoenix读出不正确,反之也不正确。
PS:所有的值建议显示调用Bytes.toBytes()
put 'list','1001','info:age',10
-- 此时10,默认是字符串类型,调用Bytes.toBytes('10'),底层存储的是字节数组
put 'list','1001','info:age',Bytes.toBytes(10)
-- 此时10,默认是Long类型,底层存储的是原数据的二进制补码
5.2、Phoenix Shell操作

Thin Client
[atguigu@hadoop102 ~]$ queryserver.py start
[atguigu@hadoop102 ~]$ sqlline-thin.py http://hadoop102:8765
Thick Client
默认情况下,在Phoenix 中不能直接创建schema,需要将如下的参数添加到Hbase中conf目录下的hbase-site.xml 和Phoenix中bin目录下的 hbase-site.xml中
<property>
<name>phoenix.schema.isNamespaceMappingEnabled</name>
<value>true</value>
</property>
[atguigu@hadoop102 ~]$ sqlline.py hadoop102,hadoop103,hadoop104:2181
Setting property: [incremental, false]
Setting property: [isolation, TRANSACTION_READ_COMMITTED]
issuing: !connect jdbc:phoenix:hadoop102,hadoop103,hadoop104:2181 none none org.apache.phoenix.jdbc.PhoenixDriver
Connecting to jdbc:phoenix:hadoop102,hadoop103,hadoop104:2181
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/opt/module/apache-phoenix-5.0.0-HBase-2.0-bin/phoenix-5.0.0-HBase-2.0-client.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/module/hadoop-3.1.3/share/hadoop/common/lib/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
22/02/05 13:30:12 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Connected to: Phoenix (version 5.0)
Driver: PhoenixEmbeddedDriver (version 5.0)
Autocommit status: true
Transaction isolation: TRANSACTION_READ_COMMITTED
Building list of tables and columns for tab-completion (set fastconnect to true to skip)...
133/133 (100%) Done
Done
sqlline version 1.2.0
# 注意:在phoenix中,schema名,表名,字段名等会自动转换为大写,若要小写,使用双引号。
0: jdbc:phoenix:hadoop102,hadoop103,hadoop104> create schema bigdata;
No rows affected (0.259 seconds)
# 必须指定主键,主键是HBase表中的rowkey
0: jdbc:phoenix:hadoop102,hadoop103,hadoop104> CREATE TABLE STUDENT(id integer PRIMARY KEY,name VARCHAR);
No rows affected (3.249 seconds)
# 如果表名是小写,那么必须用双引号。
0: jdbc:phoenix:hadoop102,hadoop103,hadoop104> CREATE TABLE "grade"(id integer PRIMARY KEY,class VARCHAR);
No rows affected (1.325 seconds)
0: jdbc:phoenix:hadoop102,hadoop103,hadoop104> UPSERT INTO STUDENT VALUES(1001,'Tom');
1 row affected (0.145 seconds)
0: jdbc:phoenix:hadoop102,hadoop103,hadoop104> UPSERT INTO "grade" VALUES(1,'grade1');
1 row affected (0.016 seconds)
0: jdbc:phoenix:hadoop102,hadoop103,hadoop104> select * from STUDENT;
+-------+-------+
| ID | NAME |
+-------+-------+
| 1001 | Tom |
+-------+-------+
1 row selected (0.054 seconds)
0: jdbc:phoenix:hadoop102,hadoop103,hadoop104> select * from "grade";
+-----+---------+
| ID | CLASS |
+-----+---------+
| 1 | grade1 |
+-----+---------+
1 row selected (0.025 seconds)
# 要修改的rowkey要存在,否则就是插入数据
0: jdbc:phoenix:hadoop102,hadoop103,hadoop104> UPSERT INTO STUDENT VALUES(1001,'JoJo');
0: jdbc:phoenix:hadoop102,hadoop103,hadoop104> DELETE FROM STUDENT WHERE name='Tom';
1 row affected (0.016 seconds)
# SCHEMA 中还存在表时,是删除不了的
0: jdbc:phoenix:hadoop102,hadoop103,hadoop104> DROP SCHEMA BIGDATA;
Error: ERROR 723 (43M06): Cannot mutate schema as schema has existing tables schemaName=BIGDATA (state=43M06,code=723)
java.sql.SQLException: ERROR 723 (43M06): Cannot mutate schema as schema has existing tables schemaName=BIGDATA
0: jdbc:phoenix:hadoop102,hadoop103,hadoop104> DROP TABLE STUDENT;
No rows affected (1.28 seconds)
0: jdbc:phoenix:hadoop102,hadoop103,hadoop104> DROP TABLE "grade";
No rows affected (1.257 seconds)
0: jdbc:phoenix:hadoop102,hadoop103,hadoop104> DROP SCHEMA BIGDATA;
No rows affected (0.261 seconds)
Phoenix与HBase的视图映射、表映射
# 在DEFAULT命名空间创建的表
hbase(main):061:0> create 'TEST','info'
Created table TEST
Took 1.2759 seconds
=> Hbase::Table - TEST
hbase(main):062:0> put 'TEST','1001','info:name','zhangsan'
Took 0.0556 seconds
hbase(main):063:0> put 'TEST','1001','info:age','21
0: jdbc:phoenix:hadoop102,hadoop103,hadoop104> use default;
No rows affected (0 seconds)
0: jdbc:phoenix:hadoop102,hadoop103,hadoop104> CREATE VIEW TEST(
. . . . . . . . . . . . . . . . . . . . . . .> id VARCHAR PRIMARY KEY,
. . . . . . . . . . . . . . . . . . . . . . .> "info"."name" VARCHAR,
. . . . . . . . . . . . . . . . . . . . . . .> "info"."age" VARCHAR);
No rows affected (6.479 seconds)
0: jdbc:phoenix:hadoop102,hadoop103,hadoop104> SELECT * FROM TEST;
+-------+-----------+------+
| ID | name | age |
+-------+-----------+------+
| 1001 | zhangsan | 21 |
+-------+-----------+------+
1 row selected (0.074 seconds)
0: jdbc:phoenix:hadoop102,hadoop103,hadoop104> !tables
+------------+--------------+----------------+---------------+----------+------------+----------------------------+----+
| TABLE_CAT | TABLE_SCHEM | TABLE_NAME | TABLE_TYPE | REMARKS | TYPE_NAME | SELF_REFERENCING_COL_NAME | RE |
+------------+--------------+----------------+---------------+----------+------------+----------------------------+----+
| | SYSTEM | CATALOG | SYSTEM TABLE | | | | |
| | SYSTEM | FUNCTION | SYSTEM TABLE | | | | |
| | SYSTEM | LOG | SYSTEM TABLE | | | | |
| | SYSTEM | SEQUENCE | SYSTEM TABLE | | | | |
| | SYSTEM | STATS | SYSTEM TABLE | | | | |
| | | TEST | VIEW | | | |
| | | US_POPULATION | TABLE | | | | |
+------------+--------------+----------------+---------------+----------+------------+----------------------------+----+
0: jdbc:phoenix:hadoop102,hadoop103,hadoop104> drop view Test;
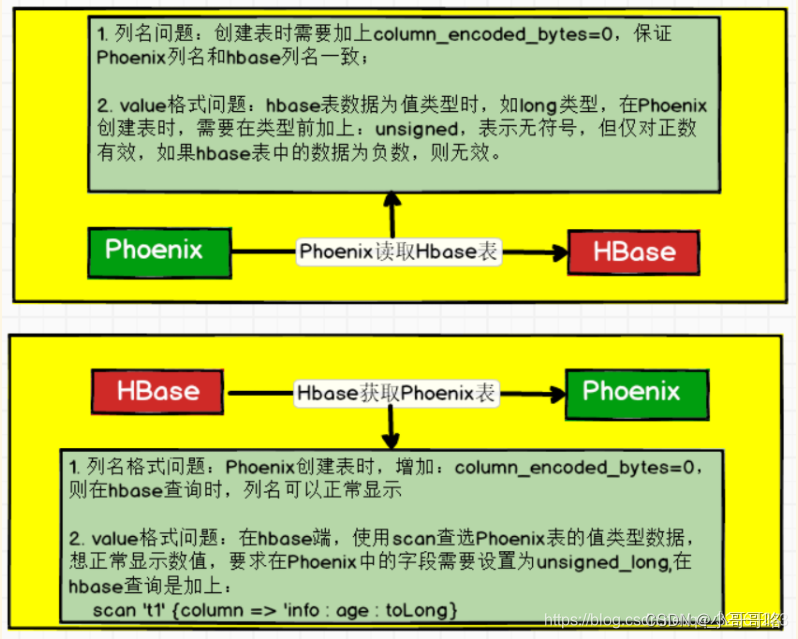
# 注意: 表映射一定要加上column_encoded_bytes=0。
0: jdbc:phoenix:hadoop102,hadoop103,hadoop104> CREATE TABLE TEST(
. . . . . . . . . . . . . . . . . . . . . . .> id VARCHAR PRIMARY KEY,
. . . . . . . . . . . . . . . . . . . . . . .> "info"."name" VARCHAR,
. . . . . . . . . . . . . . . . . . . . . . .> "info"."age" VARCHAR) column_encoded_bytes=0;
1 row affected (0.035 seconds)
0: jdbc:phoenix:hadoop102,hadoop103,hadoop104> !tables
+------------+--------------+----------------+---------------+----------+------------+----------------------------+----+
| TABLE_CAT | TABLE_SCHEM | TABLE_NAME | TABLE_TYPE | REMARKS | TYPE_NAME | SELF_REFERENCING_COL_NAME | RE |
+------------+--------------+----------------+---------------+----------+------------+----------------------------+----+
| | SYSTEM | CATALOG | SYSTEM TABLE | | | | |
| | SYSTEM | FUNCTION | SYSTEM TABLE | | | | |
| | SYSTEM | LOG | SYSTEM TABLE | | | | |
| | SYSTEM | SEQUENCE | SYSTEM TABLE | | | | |
| | SYSTEM | STATS | SYSTEM TABLE | | | | |
| | | TEST | TABLE | | | | |
| | | US_POPULATION | TABLE | | | | |
+------------+--------------+----------------+---------------+----------+------------+----------------------------+----+
全局二级索引:默认的索引格式,全局索引会在HBase创建新的索引表,索引表和数据表是分开存储的。适用于读多写少的场景。
-- 创建单个字段的全局索引
CREATE INDEX stu_name_index ON STUDENT(name);
-- 创建携带其他字段的全局索引
CREATE INDEX stu_name_index ON STUDENT(name) INCLUDE(address);
本地二级索引:本地索引索引和数据是在同一张表中存储。相对于全局索引来说,查询更慢,但是插入数据更快。
-- 创建本地索引
CREATE LOCAL INDEX stu_name_index ON STUDENT(name);
5.3、Phoenix API操作
Thin Client(pom.xml)
- 报错java.lang.ClassNotFoundException:org.apache.http.config.Lookup解决方式
- NoClassDefFoundError: com/google/protobuf/GeneratedMessageV3
<dependency>
<groupId>org.apache.phoenix</groupId>
<artifactId>phoenix-queryserver-client</artifactId>
<version>5.0.0-HBase-2.0</version>
</dependency>
<dependency>
<groupId>org.apache.httpcomponents</groupId>
<artifactId>httpclient</artifactId>
<version>4.5</version>
</dependency>
<dependency>
<groupId>org.apache.httpcomponents</groupId>
<artifactId>httpcore</artifactId>
<version>4.4.1</version>
</dependency>
<dependency>
<groupId>com.google.protobuf</groupId>
<artifactId>protobuf-java</artifactId>
<version>3.5.1</version>
</dependency>
Thick Client(pom.xml)
<dependency>
<groupId>org.apache.phoenix</groupId>
<artifactId>phoenix-core</artifactId>
<version>5.0.0-HBase-2.0</version>
<exclusions>
<exclusion>
<groupId>org.glassfish</groupId>
<artifactId>javax.el</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.glassfish</groupId>
<artifactId>javax.el</artifactId>
<version>3.0.0</version>
</dependency>
5.4、Phoenix与Hbase编码问题
- phoenix_编码问题
- 关于Phoenix映射Hbase数据字段类型Demo
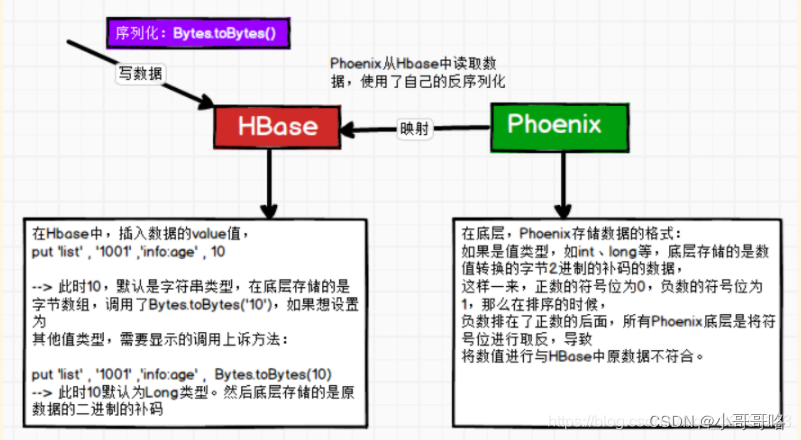
如果hbase表中的数据是由phoenix写入,不会出现问题,因为对数字的编解码都是phoenix来负责;如果hbase表中的数据不是由phoenix写入的,数字的编码由hbase负责,而phoenix读数据时要对数字进行解码, 因为Phoenix与Hbase编解码方式不一致(将hbase存储在数值补码符号位取反),导致数字出错。
解决方案一:
# 1)在hbase中创建表,并插入数值类型的数据
hbase(main):001:0> create 'person','info'
# 注意: 如果要插入数字类型,需要通过Bytes.toBytes(123456)来实现。
hbase(main):001:0> put 'person','1001', 'info:salary',Bytes.toBytes(123456)
# 2)在phoenix中创建映射表并查询数据
0: jdbc:phoenix:hadoop102,hadoop103,hadoop104> create table "person"(id varchar primary key,"info"."salary" integer ) column_encoded_bytes=0;
# 会发现数字显示有问题
0: jdbc:phoenix:hadoop102,hadoop103,hadoop104> select * from "person"
# 3)解决办法: 在phoenix中创建表时使用无符号的数值类型unsigned_long(hbase负数phoenix解析会报错)
0: jdbc:phoenix:hadoop102,hadoop103,hadoop104> create table "person"(id varchar primary key,"info"."salary" unsigned_long ) column_encoded_bytes=0;
解决方案二:
要想hbase写入的int值在phoenix能正常读取,对值进行\x80\x00\x00\x00异或运算,其他值类似。
public static int bytesToInt_phoenix(byte[] bytes) {
int n = 0;
for(int i = 0; i < 4; i++) {
n <<= 8;
n ^= bytes[i] & 0xFF;
}
n = n ^ 0x80000000;
return n;
}
public static byte[] intToBytes_phoenix(int val) {
val = val ^ 0x80000000;
byte [] b = new byte[4];
for(int i = 3; i > 0; i--) {
b[i] = (byte) val;
val >>= 8;
}
b[0] = (byte) val;
return b;
}
使用这一套编码转换规则,hbase自己读写时都处理了,因此能自己读写,同时编码是按phoenix来的,因此phoeinix也正常了。
5.5、整合Hive与Hbase
Hive表与Hbase表,同建同删。(两边都插入的数据互相可见)
create table hive_customer22(
name string, --对应hbase的rowkey
order_numb string, --对应hbase的列簇名order 和列名numb 用_表示:
order_date string, --对应hbase的列簇名order 和列名date 用_表示:
addr_city string, --对应hbase的列簇名addr 和列名city 用_表示:
addr_state string --对应hbase的列簇名addr 和列名state 用_表示:
)
stored by 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
with serdeproperties
("hbase.columns.mapping"=":key,order:numb,order:date,addr:city,addr:state")
tblproperties("hbase.table.name" = "hbase_customer22");
先建Hbase表后建Hive表,删除Hive表后Hbase表存在,删除Hbase表后Hive表报错。(两边都插入的数据互相可见)
create external table hive_customer(
name string, --对应hbase的rowkey
order_numb string, --对应hbase的列簇名order 和列名numb 用_表示:
order_date string, --对应hbase的列簇名order 和列名date 用_表示:
addr_city string, --对应hbase的列簇名addr 和列名city 用_表示:
addr_state string --对应hbase的列簇名addr 和列名state 用_表示:
)
stored by 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
with serdeproperties
("hbase.columns.mapping"=":key,order:numb,order:date,addr:city,addr:state")
tblproperties("hbase.table.name" = "hbase_customer");
create 'hbase_customer','order','addr'
举例:
# HIVE操作
hive (default)> CREATE TABLE hive_hbase_emp_table(
> empno int,
> ename string,
> job string,
> mgr int,
> hiredate string,
> sal double,
> comm double,
> deptno int)
> STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
> WITH SERDEPROPERTIES ("hbase.columns.mapping" = ":key,info:ename,info:job,info:mgr,info:hiredate,info:sal,info:comm,info:deptno")
> TBLPROPERTIES ("hbase.table.name" = "hbase_emp_table");
hive (default)> insert into table hive_hbase_emp_table select * from emp;
# hbase操作
hbase(main):011:0> scan 'hbase_emp_table'
ROW COLUMN+CELL
7369 column=info:deptno, timestamp=1658810250382, value=20
7369 column=info:ename, timestamp=1658810250382, value=SMITH
7369 column=info:hiredate, timestamp=1658810250382, value=1980-12-17
7369 column=info:job, timestamp=1658810250382, value=CLERK
7369 column=info:mgr, timestamp=1658810250382, value=7902
7369 column=info:sal, timestamp=1658810250382, value=800.0
7499 column=info:comm, timestamp=1658810250382, value=300.0
7499 column=info:deptno, timestamp=1658810250382, value=30
7499 column=info:ename, timestamp=1658810250382, value=ALLEN
7499 column=info:hiredate, timestamp=1658810250382, value=1981-2-20















 1395
1395











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









