






1.前言
这几种方法呢都是在求最优解中常常出现的方法,主要是应用迭代的思想来逼近。在梯度下降算法中。都是环绕下面这个式子展开:
当中在上面的式子中hθ(x)代表。输入为x的时候的其当时θ參数下的输出值,与y相减则是一个相对误差。之后再平方乘以1/2,而且当中
注意到x能够一维变量。也能够是多维变量,实际上最经常使用的还是多维变量。
我们知道曲面上方向导数的最大值的方向就代表了梯度的方向,因此我们在做梯度下降的时候。应该是沿着梯度的反方向进行权重的更新。能够有效的找到全局的最优解。
这个θ的更新过程能够描写叙述为:
就是依据每个x的分量以及当时的偏差值进行θ的更新,当中α为步长,一開始没搞清楚步长和学习速率的关系。这里提一下事实上这两个是一个概念,叫法不一样,最优化问题中叫步长。但一般在神经网络中也叫学习速率,比較好理解。
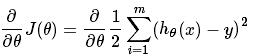
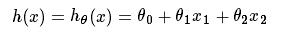
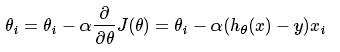
2.梯度下降、随机梯度下降、批量(小批量)梯度下降算法对照
以下是楼燚航的理解,个人感觉还是很透彻的:
- 梯度下降:梯度下降就是上面的推导。要留意,在梯度下降中。对于θ的更新,全部的样本都有贡献,也就是參与调整θ.其计算得到的是一个标准梯度。因而理论上来说一次更新的幅度是比較大的。假设样本不多的情况下,当然是这样收敛的速度会更快啦~
- 随机梯度下降:能够看到多了随机两个字,随机也就是说用样本中的一个样例来近似全部的样本,来调整θ。因而随机梯度下降是会带来一定的问题。由于计算得到的并非准确的一个梯度。easy陷入到局部最优解中
- 批量梯度下降:事实上批量的梯度下降就是一种折中的方法。他用了一些小样本来近似所有的,其本质就是随机指定一个样例替代样本不太准,那我用个30个50个样本那比随机的要准不少了吧。并且批量的话还是很能够反映样本的一个分布情况的。
2.1 梯度下降算法
这里相同引入楼燚航给的一个样例:输出结果为:#-*- coding: utf-8 -*- import random #This is a sample to simulate a function y = theta1*x1 + theta2*x2 input_x = [[1,4], [2,5], [5,1], [4,2]] y = [19,26,19,20] theta = [1,1] loss = 10 step_size = 0.001 eps =0.0001 max_iters = 10000 error =0 iter_count = 0 while( loss > eps and iter_count < max_iters): loss = 0 #这里更新权重的时候全部的样本点都用上了 for i in range (3): pred_y = theta[0]*input_x[i][0]+theta[1]*input_x[i][1] theta[0] = theta[0] - step_size * (pred_y - y[i]) * input_x[i][0] theta[1] = theta[1] - step_size * (pred_y - y[i]) * input_x[i][1] for i in range (3): pred_y = theta[0]*input_x[i][0]+theta[1]*input_x[i][1] error = 0.5*(pred_y - y[i])**2 loss = loss + error iter_count += 1 print 'iters_count', iter_count print 'theta: ',theta print 'final loss: ', loss print 'iters: ', iter_count这个不用细说,主要是全局数据都被应用到了,在小样本计算和优化中是可取的,可是对于大样本,这样的方法非常少用。theta: [3.0023172534735867, 3.9975404266238805] final loss: 9.92948359178e-05 iters: 10772.2 随机梯度下降算法
随机梯度下降算法每次从训练集中随机选择一个样本来进行学习,即: θ=θ−η⋅∇θJ(θ;xi;yi)
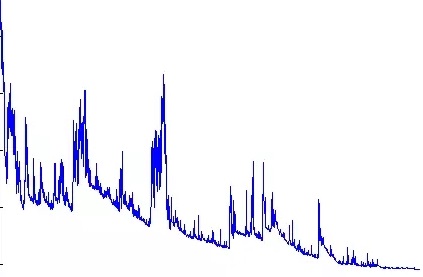
随机梯度下降算法每次仅仅随机选择一个样本来更新模型參数,因此每次的学习是很高速的,而且能够进行在线更新。 随机梯度下降最大的缺点在于每次更新可能并不会依照正确的方向进行,因此能够带来优化波动(扰动)。例如以下图:
只是从还有一个方面来看,随机梯度下降所带来的波动有个优点就是,对于类似盆地区域(即非常多局部极小值点)那么这个波动的特点可能会使得优化的方向从当前的局部极小值点跳到还有一个更好的局部极小值点,这样便可能对于非凸函数,终于收敛于一个较好的局部极值点。甚至全局极值点。
因为波动,因此会使得迭代次数(学习次数)增多。即收敛速度变慢。只是终于其会和全量梯度下降算法一样,具有同样的收敛性,即凸函数收敛于全局极值点,非凸损失函数收敛于局部极值点。採用上面的样例进行測试:输出结果:#-*- coding: utf-8 -*- import random #This is a sample to simulate a function y = theta1*x1 + theta2*x2 input_x = [[1,4], [2,5], [5,1], [4,2]] y = [19,26,19,20] theta = [1,1] loss = 10 step_size = 0.001 eps =0.0001 max_iters = 10000 error =0 iter_count = 0 while( loss > eps and iter_count < max_iters): loss = 0 #每一次选取随机的一个点进行权重的更新 i = random.randint(0,3) pred_y = theta[0]*input_x[i][0]+theta[1]*input_x[i][1] theta[0] = theta[0] - step_size * (pred_y - y[i]) * input_x[i][0] theta[1] = theta[1] - step_size * (pred_y - y[i]) * input_x[i][1] for i in range (3): pred_y = theta[0]*input_x[i][0]+theta[1]*input_x[i][1] error = 0.5*(pred_y - y[i])**2 loss = loss + error iter_count += 1 print 'iters_count', iter_count print 'theta: ',theta print 'final loss: ', loss print 'iters: ', iter_count通过和梯度下降算法相比較。能够发现迭代次数确实有变多。可是结果是一致的。当然实际上。对于非凸大样本问题迭代次数可能会很多其它。theta: [3.0026881883781535, 3.9977486449798345] final loss: 9.9846677704e-05 iters: 10942.3 批量梯度下降算法
每次使用所有训练集样本计算损失函数loss_function 的梯度 params_grad。然后使用学习速率 lr朝着梯度相反方向去更新模型的每一个參数params。一般各现有的一些机器学习库都提供了梯度计算api。假设想自己亲手写代码计算。那么须要在程序调试过程中验证梯度计算是否正确。
批量梯度下降每次学习都使用整个训练集。因此其长处在于每次更新都会朝着正确的方向进行,最后可以保证收敛于极值点(凸函数收敛于全局极值点。非凸函数可能会收敛于局部极值点)。可是其缺点在于每次学习时间过长,而且假设训练集非常大以至于须要消耗大量的内存,而且全量梯度下降不能进行在线模型參数更新。
2.4 小批量梯度下降算法
Mini-batch梯度下降综合了 batch 梯度下降与 stochastic 梯度下降,在每次更新速度与更新次数中间取得一个平衡,其每次更新从训练集中随机选择 m,m<n 个样本进行学习。即:
θ=θ−η⋅∇θJ(θ;xi:i+m;yi:i+m)相对于随机梯度下降,Mini-batch梯度下降减少了收敛波动性,即减少了參数更新的方差。使得更新更加稳定。相对于全量梯度下降,其提高了每次学习的速度。而且其不用操心内存瓶颈从而能够利用矩阵运算进行高效计算。
一般而言每次更新随机选择[50,256]个样本进行学习,可是也要依据详细问题而选择,实践中能够进行多次试验。选择一个更新速度与更次次数都较适合的样本数。
mini-batch梯度下降能够保证收敛性,这种方法在神经网络训练中是很经常使用的。
3.梯度下降算法中存在的问题
尽管梯度下降算法效果非常好,而且广泛使用。但同一时候其也存在一些挑战与问题须要解决:
- 选择一个合理的学习速率非常难。假设学习速率过小。则会导致收敛速度非常慢。假设学习速率过大,那么其会阻碍收敛,即在极值点附近会振荡。学习速率调整(又称学习速率调度,Learning rate schedules)试图在每次更新过程中。改变学习速率。如退火。一般使用某种事先设定的策略或者在每次迭代中衰减一个较小的阈值。不管哪种调整方法。都须要事先进行固定设置,这边便无法自适应每次学习的数据集特点。
- 模型全部的參数每次更新都是使用同样的学习速率。假设数据特征是稀疏的或者每一个特征有着不同的取值统计特征与空间,那么便不能在每次更新中每一个參数使用同样的学习速率,那些非常少出现的特征应该使用一个相对较大的学习速率。
- 对于非凸目标函数,easy陷入那些次优的局部极值点中。如在神经网路中。那么怎样避免呢?更严重的问题不是局部极值点,而是鞍点。
4.深度学习中,梯度下降优化算法
5.參看资料以下将讨论一些在深度学习社区中常常使用用来解决上诉问题的一些梯度优化方法,只是并不包含在高维数据中不可行的算法,如牛顿法。
4.1 Momentum动量
假设在峡谷地区(某些方向较还有一些方向上陡峭得多。常见于局部极值点),SGD会在这些地方附近振荡,从而导致收敛速度慢。这样的情况下,动量(Momentum)便能够解决。
动量在參数更新项中加上一次更新量(即动量项),即: νt=γνt−1+η ∇θJ(θ),θ=θ−νt
当中动量项超參数γ<1通常是小于等于0.9。下图展示了没有动量和加入动量前后,搜索路径的差异:
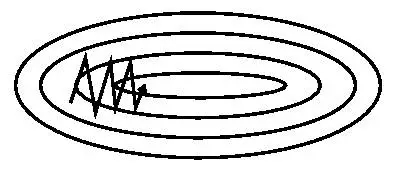
加上动量项就像从山顶滚下一个球。求往下滚的时候累积了前面的动量(动量不断添加),因此速度变得越来越快,直到到达终点。
同理。在更新模型參数时,对于那些当前的梯度方向与上一次梯度方向同样的參数,那么进行加强,即这些方向上更快了;对于那些当前的梯度方向与上一次梯度方向不同的參数,那么进行削减。即这些方向上减慢了。因此能够获得更快的收敛速度与降低振荡。
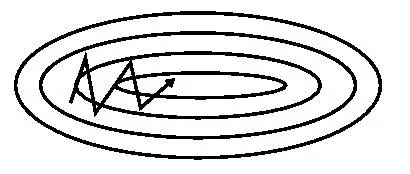
4.2 Nesterov accelerated gradient(NAG)
从山顶往下滚的球会盲目地选择斜坡。更好的方式应该是在遇到倾斜向上之前应该减慢速度。
Nesterov accelerated gradient(NAG。涅斯捷罗夫梯度加速)不仅添加了动量项,而且在计算參数的梯度时。在损失函数中减去了动量项。即计算∇θJ(θ−γνt−1),这样的方式预估了下一次參数所在的位置。即: νt=γνt−1+η⋅∇θJ(θ−γνt−1)。θ=θ−νt
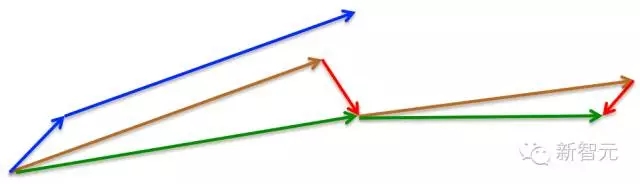
如果动量因子參数γ=0.9。首先计算当前梯度项。如上图小蓝色向量,然后加上动量项,这样便得到了大的跳跃。如上图大蓝色的向量。这便是仅仅包括动量项的更新。
而NAG首先来一个大的跳跃(动量项),然后加上一个小的使用了动量计算的当前梯度(上图红色向量)进行修正得到上图绿色的向量。这样能够阻止过快更新来提高响应性。如在RNNs中。
通过上面的两种方法。可以做到每次学习过程中可以依据损失函数的斜率做到自适应更新来加速SGD的收敛。下一步便须要对每一个參数依据參数的重要性进行各自自适应更新。
4.3 Adagrad
Adagrad也是一种基于梯度的优化算法,它可以对每一个參数自适应不同的学习速率。对稀疏特征,得到大的学习更新,对非稀疏特征,得到较小的学习更新,因此该优化算法适合处理稀疏特征数据。Dean等发现Adagrad可以非常好的提高SGD的鲁棒性,google便用起来训练大规模神经网络(看片识猫:recognize cats in Youtube videos)。Pennington等在GloVe中便使用Adagrad来训练得到词向量(Word Embeddings), 频繁出现的单词赋予较小的更新,不常常出现的单词则赋予较大的更新。
Adagrad主要优势在于它可以为每一个參数自适应不同的学习速率,而一般的人工都是设定为0.01。同一时候其缺点在于须要计算參数梯度序列平方和。而且学习速率趋势是不断衰减终于达到一个很小的值。下文中的Adadelta便是用来解决该问题的。
4.4 Adam
Adaptive Moment Estimation (Adam) 也是一种不同參数自适应不同学习速率方法,与Adadelta与RMSprop差别在于,它计算历史梯度衰减方式不同。不使用历史平方衰减。其衰减方式类似动量,例如以下:
mt=β1mt−1+(1−β1)gt
vt=β2vt−1+(1−beta2)g2t
mt与vt各自是梯度的带权平均和带权有偏方差,初始为0向量,Adam的作者发现他们倾向于0向量(接近于0向量),特别是在衰减因子(衰减率)β1,β2接近于1时。为了改进这个问题,
对mt与vt进行偏差修正(bias-corrected):
mt^=mt1−betat1
vt^=vt1−betat2
终于,Adam的更新方程为:
θt+1=θt−ηvt^−−√+ϵmt^
论文中建议默认值:β1=0.9,β2=0.999。ϵ=10−8。论文中将Adam与其他的几个自适应学习速率进行了比較。效果均要好。4.5 总结与对照
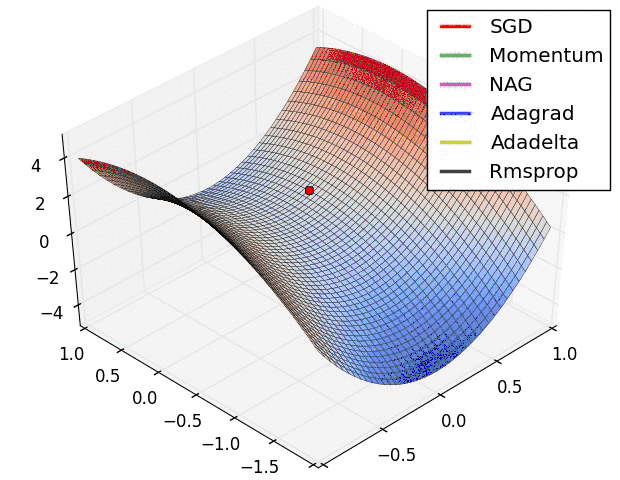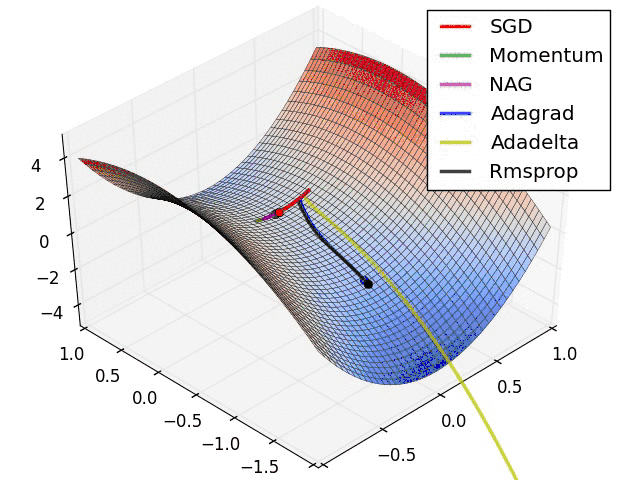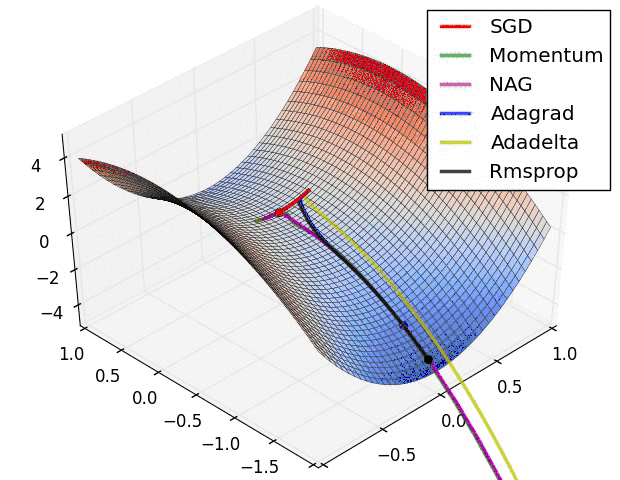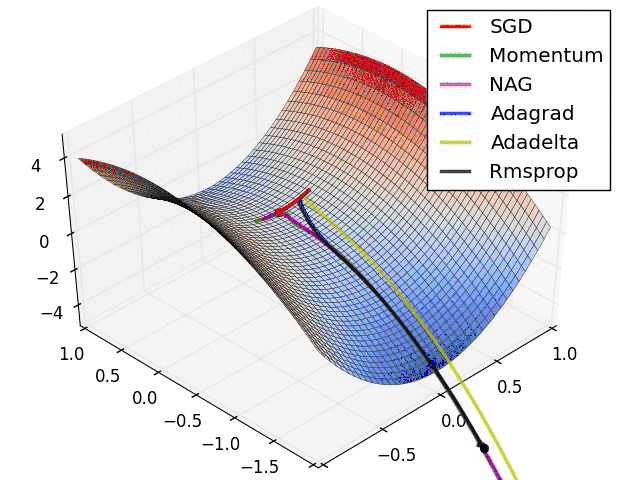
从上图可以看出。Adagrad、Adadelta与RMSprop在损失曲面上可以马上转移到正确的移动方向上达到高速的收敛。而Momentum 与NAG会导致偏离(off-track)。同一时候NAG可以在偏离之后高速修正其路线,由于其依据梯度修正来提高响应性。
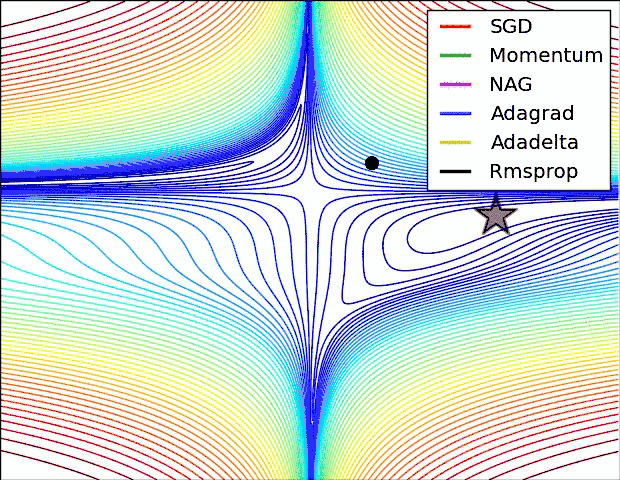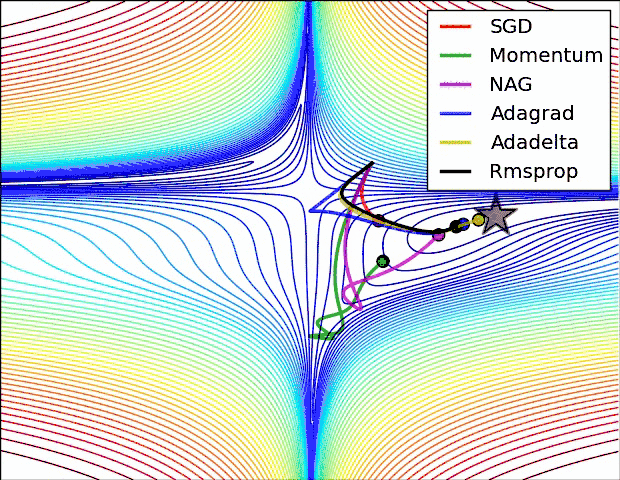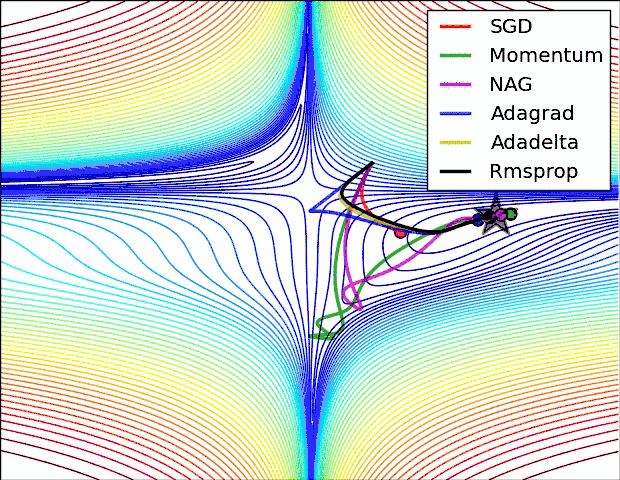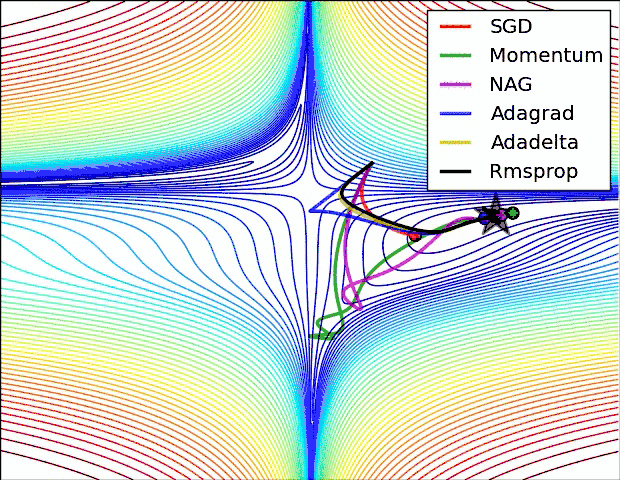
最后考察,各种方法在鞍点问题上的处理效果:
从上图可以看出,在鞍点(saddle points)处(即某些维度上梯度为零,某些维度上梯度不为零)。SGD、Momentum与NAG一直在鞍点梯度为零的方向上振荡,非常难打破鞍点位置的对称性。Adagrad、RMSprop与Adadelta可以非常快地向梯度不为零的方向上转移。
从上面两幅图能够看出,自适应学习速率方法(Adagrad、Adadelta、RMSprop与Adam)在这些场景下具有更好的收敛速度与收敛性。
1.感谢楼燚(yì)航
2.感谢Sebastian Ruder















 274
274

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









