







「springboot 2.x 系列」零基础快速入门
「springboot 2.x 系列」restful web 应用
「springboot 2.x 系列」properties 配置文件详解
「springboot 2.x 系列」package打包与devtools
「springboot 2.x 系列」日志log4j2会用吗?
「springboot 2.x 系列」actuator 监控/健康检查/审计/统计
「springboot 2.x 系列」深度理解定时任务schedule
「springboot 2.x 系列」多线程异步调用Async
「springboot 2.x 系列」整合mybaits数据库开发框架
「springboot 2.x 系列」exception全局异常处理
「springboot 2.x 系列」如何彻底解决跨域问题
「springboot 2.x 系列」validation数据校验详细说明
「springboot 2.x 系列」如何使用缓存缓解数据库压力
「springboot 2.x 系列」filter 过滤器如何正确使用
源码:https://github.com/langyastudio/langya-tech/tree/springboot/mybatis
| JDBC | Hibernate | JPA | MyBatis |
|---|---|---|---|
| DataSource | SessionFactory | EntityManagerFactory | SqlSessionFactory |
| Connection | Session | EntityManager | SqlSession |
Hibernate / JPA
这类 ORM 干的主要工作就是把 ResultSet 的每一行变成 Java Bean,或者把 Java Bean 自动转换到 INSERT 或 UPDATE 语句的参数中,从而实现 ORM
Spring Data JPA 是在 JPA 之上做了更高级别的抽象,使对数据库的操作更简单、更语义化
MyBatis
介于全自动 ORM 如 Hibernate 和手写全部如 JdbcTemplate 之间,还有一种半自动的 ORM,它只负责把 ResultSet 自动映射到 Java Bean,或者自动填充 Java Bean 参数,但仍需自己写出 SQL。MyBatis 就是这样一种半自动化 ORM 框架,需要手写 SQL 语句,没有自动加载一对多或多对一关系的功能。
它和 ORM 框架相比,主要有几点差别:
- 查询后需要手动提供 Mapper 实例以便把 ResultSet 的每一行变为 Java 对象
- 增删改操作所需的参数列表,需要手动传入,即把 User 实例变为 [user.id, user.name, user.email] 这样的列表,比较麻烦
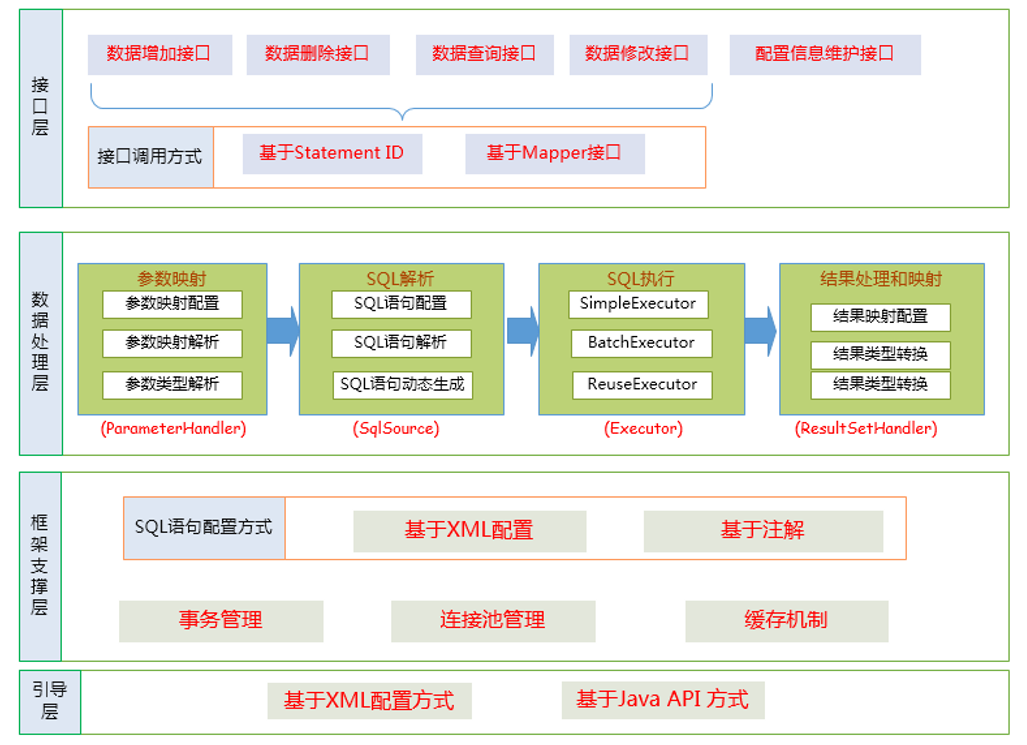
实战
基于 spring boot 2.x + mybatis(基于 xml)
maven
-
mybatis
-
mybatis plus
mybatis 扩展库,只做增强不做改变,引入它不会对现有工程产生影响
-
druid
数据库连接池
-
mysql connector
数据库的客户端驱动
<!--spring mybatis-->
<dependency>
<groupId>org.mybatis.spring.boot</groupId>
<artifactId>mybatis-spring-boot-starter</artifactId>
<version>${mybatis-starter.version}</version>
</dependency>
<!--mybatis plus-->
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>${mybatis-plus-starter.version}</version>
</dependency>
<!--druid-->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid-spring-boot-starter</artifactId>
<version>${druid-starter.version}</version>
</dependency>
<!--db driver-->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>${mysql.version}</version>
<scope>runtime</scope>
</dependency>
druid 配置
基于 application.yml 的配置文件
spring:
datasource:
url: jdbc:mysql://192.168.123.22:3306/edu_account
username: root
password: daemon
driver-class-name: org.mariadb.jdbc.Driver
druid:
initial-size: 10
max-active: 20
min-idle: 1
max-wait: 6000
#pool-prepared-statements:
#max-pool-prepared-statement-per-connection-size:
validation-query: SELECT 1
#validation-query-timeout:
test-on-borrow: false
test-on-return: false
test-while-idle: true
time-between-eviction-runs-millis: 60000
min-evictable-idle-time-millis: 600000
#max-evictable-idle-time-millis:
filters: wall
-
url
数据连接的地址,mysql位于192.168.123.22下的edu_account数据库
-
username
数据库的用户名
-
password
数据库的密码
-
druid
连接池的详细配置
连接池的配置项详细说明:
| 配置 | 缺省值 | 说明 |
|---|---|---|
| name | 配置这个属性的意义在于,如果存在多个数据源,监控的时候可以通过名字来区分开来。 如果没有配置,将会生成一个名字,格式是:“DataSource-” + System.identityHashCode(this) | |
| url | 连接数据库的url,不同数据库不一样。例如: mysql : jdbc:mysql://10.20.153.104:3306/druid2 oracle : jdbc:oracle:thin:@10.20.149.85:1521:ocnauto | |
| username | 连接数据库的用户名 | |
| password | 连接数据库的密码。如果你不希望密码直接写在配置文件中,可以使用ConfigFilter。详细看这里:https://github.com/alibaba/druid/wiki/%E4%BD%BF%E7%94%A8ConfigFilter | |
| driverClassName | 根据url自动识别 | 这一项可配可不配,如果不配置druid会根据url自动识别dbType,然后选择相应的driverClassName(建议配置下) |
| initialSize | 0 | 初始化时建立物理连接的个数。初始化发生在显示调用init方法,或者第一次getConnection时 |
| maxActive | 8 | 最大连接池数量 |
| maxIdle | 8 | 已经不再使用,配置了也没效果 |
| minIdle | 最小连接池数量 | |
| maxWait | 获取连接时最大等待时间,单位毫秒。配置了maxWait之后,缺省启用公平锁,并发效率会有所下降,如果需要可以通过配置useUnfairLock属性为true使用非公平锁。 | |
| poolPreparedStatements | false | 是否缓存preparedStatement,也就是PSCache。PSCache对支持游标的数据库性能提升巨大,比如说oracle。在mysql下建议关闭。 |
| maxOpenPreparedStatements | -1 | 要启用PSCache,必须配置大于0,当大于0时,poolPreparedStatements自动触发修改为true。在Druid中,不会存在Oracle下PSCache占用内存过多的问题,可以把这个数值配置大一些,比如说100 |
| validationQuery | 用来检测连接是否有效的sql,要求是一个查询语句。如果validationQuery为null,testOnBorrow、testOnReturn、testWhileIdle都不会其作用。 | |
| testOnBorrow | true | 申请连接时执行validationQuery检测连接是否有效,做了这个配置会降低性能。 |
| testOnReturn | false | 归还连接时执行validationQuery检测连接是否有效,做了这个配置会降低性能 |
| testWhileIdle | false | 建议配置为true,不影响性能,并且保证安全性。申请连接的时候检测,如果空闲时间大于timeBetweenEvictionRunsMillis,执行validationQuery检测连接是否有效。 |
| timeBetweenEvictionRunsMillis | 有两个含义: 1) Destroy线程会检测连接的间隔时间 2) testWhileIdle的判断依据,详细看testWhileIdle属性的说明 | |
| minEvictableIdleTimeMillis | ||
| connectionInitSqls | 物理连接初始化的时候执行的sql | |
| exceptionSorter | 根据dbType自动识别 | 当数据库抛出一些不可恢复的异常时,抛弃连接 |
| filters | 属性类型是字符串,通过别名的方式配置扩展插件,常用的插件有: 监控统计用的filter:stat日志用的filter:log4j防御sql注入的filter:wall | |
| proxyFilters | 类型是List<com.alibaba.druid.filter.Filter>,如果同时配置了filters和proxyFilters,是组合关系,并非替换关系 |
mybatis 配置
基于 application.yml 的配置文件:
mybatis:
config-location: classpath:mybatis-config.xml
mapper-locations:
classpath*:mapper/*.xml
configuration:
auto-mapping-behavior: partial
# 开启驼峰命名
map-underscore-to-camel-case: true
-
config-location
mybatis 的配置文件,位于 resource 下的 mybatis-config.xml
-
mapper-locations
mybatis SQL mapper 对应的 xml 文件
mybatis 的配置文件详细说明如下:https://mybatis.org/mybatis-3/zh/configuration.html#settings
示例
推荐辅助工具:
MybatisCodeHelperPro or Free MyBatis plugin
MyBatisXMybatisLogFormat
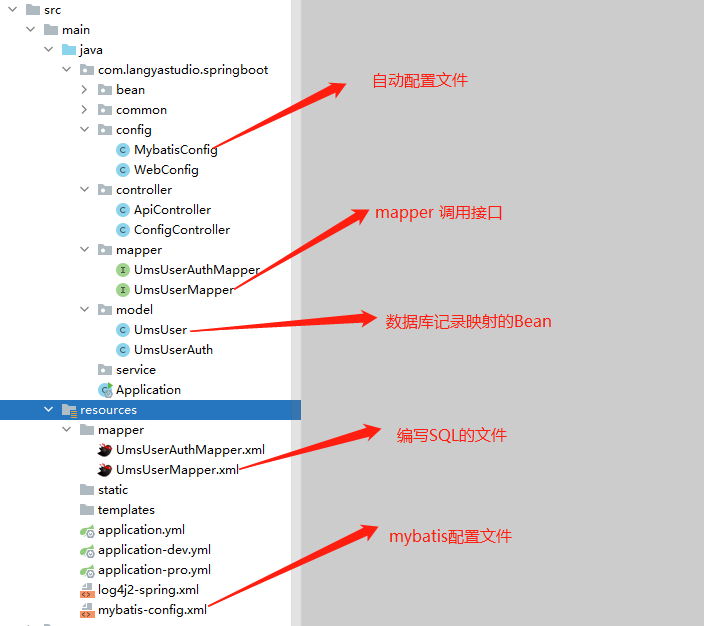
数据库
示例使用的表结构:
create database edu_account;
use edu_account;
create table ums_user
(
id int unsigned not null auto_increment,
user_name varchar(20) not null comment '用户名',
nick_name varchar(20) not null default '' comment '昵称',
full_name varchar(20) not null default '' comment '姓名',
sex tinyint not null default 0 comment '性别',
avator varchar(255) not null default '' comment '用户头像',
pcd_id int not null default 0 comment '行政区划代码',
company varchar(128) not null default '' comment '联系地址',
birthday date not null default '1970-01-01' comment '生日',
description varchar(128) not null default '' comment '描述信息',
reg_ip int unsigned not null default 0 comment '注册IP',
user_type tinyint not null default 1 comment '用户类型(1 账户、2 设备账户)',
update_time datetime not null comment '更新时间',
delete_time datetime default NULL comment '删除时间',
create_time datetime not null comment '创建时间',
primary key (id)
)
auto_increment = 1000
engine = InnoDB
default charset = utf8
collate = utf8_general_ci;
alter table ums_user comment '用户信息表';
INSERT INTO `ums_user`
VALUES ('1000',
'admin',
'超级管理员',
'超级管理员',
'3',
'',
'0',
'',
'1970-01-01',
'',
'3232267108',
'1',
NOW(),
NULL,
NOW());
编写mapper、model文件如下:
UmsUserMapper — model 层对应xml的接口
public interface UmsUserMapper
{
UmsUser selectByPrimaryKey(String userName);
}
UmsUserMapper.xml — 编写SQL的文件,如根据用户名获取用户信息
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.langyastudio.springboot.mapper.UmsUserMapper">
<resultMap id="BaseResultMap" type="com.langyastudio.springboot.model.UmsUser">
<id column="id" jdbcType="INTEGER" property="id"/>
<result column="user_name" jdbcType="VARCHAR" property="userName"/>
<result column="nick_name" jdbcType="VARCHAR" property="nickName"/>
<result column="full_name" jdbcType="VARCHAR" property="fullName"/>
<result column="sex" jdbcType="TINYINT" property="sex"/>
<result column="avator" jdbcType="VARCHAR" property="avator"/>
<result column="pcd_id" jdbcType="INTEGER" property="pcdId"/>
<result column="company" jdbcType="VARCHAR" property="company"/>
<result column="birthday" jdbcType="DATE" property="birthday"/>
<result column="description" jdbcType="VARCHAR" property="description"/>
<result column="reg_ip" jdbcType="INTEGER" property="regIp"/>
<result column="user_type" jdbcType="TINYINT" property="userType"/>
<result column="update_time" jdbcType="TIMESTAMP" property="updateTime"/>
<result column="delete_time" jdbcType="TIMESTAMP" property="deleteTime"/>
<result column="create_time" jdbcType="TIMESTAMP" property="createTime"/>
</resultMap>
<sql id="Base_Column_List">
id, user_name, nick_name, full_name, sex, avator, pcd_id, company, birthday, description,
reg_ip, user_type, update_time, delete_time, create_time
</sql>
<select id="selectByPrimaryKey" parameterType="java.lang.String" resultMap="BaseResultMap">
select
<include refid="Base_Column_List"/>
from ums_user
where user_name = #{userName,jdbcType=INTEGER}
</select>
</mapper>
UmsUser — 表记录映射的实体类
@Data
@AllArgsConstructor
@NoArgsConstructor
public class UmsUser {
private Integer id;
private String userName;
private String nickName;
private String fullName;
private Byte sex;
private String avator;
private Integer pcdId;
private String company;
private LocalDate birthday;
private String description;
private Long regIp;
private Byte userType;
private LocalDateTime updateTime;
private LocalDateTime deleteTime;
private LocalDateTime createTime;
}
mapper自动配置
用于将 com.langyastudio.springboot.mapper 下的文件自动Bean
@Configuration
@EnableTransactionManagement
@MapperScan({"com.langyastudio.springboot.mapper"})
public class MybatisConfig
{
}
调用如下
@RestController
@RequestMapping("/api")
public class ApiController
{
@Autowired
UmsUserMapper umsUserMapper;
/**
* 根据用户名获取用户信息
*/
@GetMapping("/users")
public UmsUser users(@RequestParam(value = "user_name") String userName )
{
return umsUserMapper.selectByPrimaryKey(userName);
}
}

日志
这里使用 LOG4J2日志工具,mybatis-config.xml 配置如下
<configuration>
<!--https://mybatis.org/mybatis-3/zh/configuration.html#-->
<settings>
<!-- 指定 MyBatis 增加到日志名称的前缀。-->
<setting name="logPrefix" value="batis-log-"/>
<!-- 指定 MyBatis 所用日志的具体实现,未指定时将自动查找-->
<setting name="logImpl" value="LOG4J2"/>
</settings>
</configuration>
还需要在日志配置文件log4j2-spring.xml增加 mybatis 的 mapperxml 监控,否则mybatis不生效
<!-- 将业务dao接口填写进去,并用控制台输出即可 -->
<Logger name="com.langyastudio.springboot.mapper" level="DEBUG" additivity="false">
<appender-ref ref="console"/>
</Logger>
此时在控制台可以看到SQL的执行日志:

XML 映射文件
来自:https://mybatis.org/mybatis-3/zh/sqlmap-xml.html
MyBatis 的真正强大在于它的语句映射,这是它的魔力所在。由于它的异常强大,映射器的 XML 文件就显得相对简单。如果拿它跟具有相同功能的 JDBC 代码进行对比,你会立即发现省掉了将近 95% 的代码。MyBatis 致力于减少使用成本,让用户能更专注于 SQL 代码。
SQL 映射文件只有很少的几个顶级元素(按照应被定义的顺序列出):
cache– 该命名空间的缓存配置cache-ref– 引用其它命名空间的缓存配置resultMap– 描述如何从数据库结果集中加载对象,是最复杂也是最强大的元素sql– 可被其它语句引用的可重用语句块insert– 映射插入语句update– 映射更新语句delete– 映射删除语句select– 映射查询语句
select
MyBatis 的基本原则之一是:在每个插入、更新或删除操作之间,通常会执行多个查询操作
select 元素允许你配置很多属性来配置每条语句的行为细节:
<select
id="selectPerson"
parameterType="int"
resultType="hashmap"
resultMap="personResultMap"
flushCache="false"
useCache="true"
timeout="10"
fetchSize="256"
statementType="PREPARED"
resultSetType="FORWARD_ONLY">
| 属性 | 描述 |
|---|---|
id | 在命名空间中唯一的标识符,可以被用来引用这条语句。 |
parameterType | 将会传入这条语句的参数的类全限定名或别名。这个属性是可选的,因为 MyBatis 可以通过类型处理器(TypeHandler)推断出具体传入语句的参数,默认值为未设置(unset)。 |
resultType | 期望从这条语句中返回结果的类全限定名或别名。 注意,如果返回的是集合,那应该设置为集合包含的类型,而不是集合本身的类型。 resultType 和 resultMap 之间只能同时使用一个。 |
resultMap | 对外部 resultMap 的命名引用。结果映射是 MyBatis 最强大的特性,如果你对其理解透彻,许多复杂的映射问题都能迎刃而解。 resultType 和 resultMap 之间只能同时使用一个。 |
flushCache | 将其设置为 true 后,只要语句被调用,都会导致本地缓存和二级缓存被清空,默认值:false。 |
useCache | 将其设置为 true 后,将会导致本条语句的结果被二级缓存缓存起来,默认值:对 select 元素为 true。 |
timeout | 这个设置是在抛出异常之前,驱动程序等待数据库返回请求结果的秒数。默认值为未设置(unset)(依赖数据库驱动)。 |
fetchSize | 这是一个给驱动的建议值,尝试让驱动程序每次批量返回的结果行数等于这个设置值。 默认值为未设置(unset)(依赖驱动)。 |
statementType | 可选 STATEMENT,PREPARED 或 CALLABLE。这会让 MyBatis 分别使用 Statement,PreparedStatement 或 CallableStatement,默认值:PREPARED。 |
resultSetType | FORWARD_ONLY,SCROLL_SENSITIVE, SCROLL_INSENSITIVE 或 DEFAULT(等价于 unset) 中的一个,默认值为 unset (依赖数据库驱动)。 |
databaseId | 如果配置了数据库厂商标识(databaseIdProvider),MyBatis 会加载所有不带 databaseId 或匹配当前 databaseId 的语句;如果带和不带的语句都有,则不带的会被忽略。 |
resultOrdered | 这个设置仅针对嵌套结果 select 语句:如果为 true,将会假设包含了嵌套结果集或是分组,当返回一个主结果行时,就不会产生对前面结果集的引用。 这就使得在获取嵌套结果集的时候不至于内存不够用。默认值:false。 |
resultSets | 这个设置仅适用于多结果集的情况。它将列出语句执行后返回的结果集并赋予每个结果集一个名称,多个名称之间以逗号分隔。 |
一个简单查询的 select 元素是非常简单的。比如:
<select id="selectPerson" parameterType="int" resultType="hashmap">
SELECT * FROM PERSON WHERE ID = #{id}
</select>
这个语句名为 selectPerson,接受一个 int(或 Integer)类型的参数,并返回一个 HashMap 类型的对象,其中的键是列名,值便是结果行中的对应值。
insert, update 和 delete
数据变更语句 insert,update 和 delete 的实现非常接近:
| 属性 | 描述 |
|---|---|
id | 在命名空间中唯一的标识符,可以被用来引用这条语句。 |
parameterType | 将会传入这条语句的参数的类全限定名或别名。这个属性是可选的,因为 MyBatis 可以通过类型处理器(TypeHandler)推断出具体传入语句的参数,默认值为未设置(unset)。 |
flushCache | 将其设置为 true 后,只要语句被调用,都会导致本地缓存和二级缓存被清空,默认值:(对 insert、update 和 delete 语句)true。 |
timeout | 这个设置是在抛出异常之前,驱动程序等待数据库返回请求结果的秒数。默认值为未设置(unset)(依赖数据库驱动)。 |
statementType | 可选 STATEMENT,PREPARED 或 CALLABLE。这会让 MyBatis 分别使用 Statement,PreparedStatement 或 CallableStatement,默认值:PREPARED。 |
useGeneratedKeys | (仅适用于 insert 和 update)这会令 MyBatis 使用 JDBC 的 getGeneratedKeys 方法来取出由数据库内部生成的主键(比如:像 MySQL 和 SQL Server 这样的关系型数据库管理系统的自动递增字段),默认值:false。 |
keyProperty | (仅适用于 insert 和 update)指定能够唯一识别对象的属性,MyBatis 会使用 getGeneratedKeys 的返回值或 insert 语句的 selectKey 子元素设置它的值,默认值:未设置(unset)。如果生成列不止一个,可以用逗号分隔多个属性名称。 |
keyColumn | (仅适用于 insert 和 update)设置生成键值在表中的列名,在某些数据库(像 PostgreSQL)中,当主键列不是表中的第一列的时候,是必须设置的。如果生成列不止一个,可以用逗号分隔多个属性名称。 |
databaseId | 如果配置了数据库厂商标识(databaseIdProvider),MyBatis 会加载所有不带 databaseId 或匹配当前 databaseId 的语句;如果带和不带的语句都有,则不带的会被忽略。 |
下面是 insert,update 和 delete 语句的示例:
<insert id="insertAuthor">
insert into Author (id,username,password,email,bio)
values (#{id},#{username},#{password},#{email},#{bio})
</insert>
<update id="updateAuthor">
update Author set
username = #{username},
password = #{password},
email = #{email},
bio = #{bio}
where id = #{id}
</update>
<delete id="deleteAuthor">
delete from Author where id = #{id}
</delete>
首先,如果你的数据库支持自动生成主键的字段(比如 MySQL 和 SQL Server),那么你可以设置 useGeneratedKeys=”true”,然后再把 keyProperty 设置为目标属性就 OK 了。
例如,如果上面的 Author 表已经在 id 列上使用了自动生成,那么语句可以修改为:
<insert id="insertAuthor" useGeneratedKeys="true"
keyProperty="id">
insert into Author (username,password,email,bio)
values (#{username},#{password},#{email},#{bio})
</insert>
如果你的数据库还支持多行插入, 你也可以传入一个 Author 数组或集合,并返回自动生成的主键。
<insert id="insertAuthor" useGeneratedKeys="true"
keyProperty="id">
insert into Author (username, password, email, bio) values
<foreach item="item" collection="list" separator=",">
(#{item.username}, #{item.password}, #{item.email}, #{item.bio})
</foreach>
</insert>
sql
参数可以静态地(在加载的时候)确定下来,并且可以在不同的 include 元素中定义不同的参数值。比如:
<sql id="userColumns"> ${alias}.id,${alias}.username,${alias}.password </sql>
这个 SQL 片段可以在其它语句中使用,例如:
<select id="selectUsers" resultType="map">
select
<include refid="userColumns"><property name="alias" value="t1"/></include>,
<include refid="userColumns"><property name="alias" value="t2"/></include>
from some_table t1
cross join some_table t2
</select>
参数
ORM
如果传入一个复杂的对象,行为就会有点不一样了。比如:
<insert id="insertUser" parameterType="User">
insert into users (id, username, password)
values (#{id}, #{username}, #{password})
</insert>
如果 User 类型的参数对象传递到了语句中,会查找 id、username 和 password 属性,然后将它们的值传入预处理语句的参数中。
jdbcType
JDBC 要求,如果一个列允许使用 null 值,并且会使用值为 null 的参数,就必须要指定 JDBC 类型(jdbcType)
阅读
PreparedStatement.setNull()的 JavaDoc 来获取更多信息
MyBatis 几乎总是可以根据参数对象的类型确定 javaType,除非该对象是一个 HashMap。这个时候,你需要显式指定 javaType 来确保正确的类型处理器(TypeHandler)被使用。
对于数值类型,还可以设置 numericScale 指定小数点后保留的位数:
#{height,javaType=double,jdbcType=NUMERIC,numericScale=2}
大多时候,顶多要为可能为空的列指定 jdbcType,其他的事情交给 MyBatis 自己去推断就行了:
#{firstName}
#{middleInitial,jdbcType=VARCHAR}
#{lastName}
要更进一步地自定义类型处理方式,可以指定一个特殊的类型处理器类(或别名),比如:
#{age,javaType=int,jdbcType=NUMERIC,typeHandler=MyTypeHandler}
参数的配置好像越来越繁琐了,但实际上,很少需要如此繁琐的配置
字符串替换
默认情况下,使用 #{} 参数语法时,MyBatis 会创建 PreparedStatement 参数占位符,并通过占位符安全地设置参数(就像使用 ? 一样)。 这样做更安全,更迅速,通常也是首选做法。
不过有时你就是想直接在 SQL 语句中直接插入一个不转义的字符串。 比如 ORDER BY 子句,这时候你可以:
ORDER BY ${columnName}
这样 MyBatis 就不会修改或转义该字符串了。
当 SQL 语句中的元数据(如表名或列名)是动态生成的时候,字符串替换将会非常有用。 举个例子,如果你想 select 一个表任意一列的数据时:
@Select("select * from user where ${column} = #{value}")
User findByColumn(@Param("column") String column, @Param("value") String value);
其中 ${column} 会被直接替换,而 #{value} 会使用 ? 预处理。 这样,就能完成同样的任务:
User userOfId1 = userMapper.findByColumn("id", 1L);
User userOfNameKid = userMapper.findByColumn("name", "kid");
User userOfEmail = userMapper.findByColumn("email", "noone@nowhere.com");
这种方式也同样适用于替换表名的情况。
用这种方式接受用户的输入,并用作语句参数是不安全的,会导致潜在的 SQL 注入攻击。因此,要么不允许用户输入这些字段,要么自行转义并检验这些参数。
结果映射
ResultMap 的设计思想是,对简单的语句做到零配置,对于复杂一点的语句,只需要描述语句之间的关系就行了。
resultType
如果列名和属性名不能匹配上,可以在 SELECT 语句中设置列别名(这是一个基本的 SQL 特性)来完成匹配。比如:
<select id="selectUsers" resultType="User">
select
user_id as "id",
user_name as "userName",
hashed_password as "hashedPassword"
from some_table
where id = #{id}
</select>
resultMap
解决列名不匹配的另外一种方式 — 显式使用外部的 resultMap
<resultMap id="userResultMap" type="User">
<id property="id" column="user_id" />
<result property="username" column="user_name"/>
<result property="password" column="hashed_password"/>
</resultMap>
然后在引用它的语句中设置 resultMap 属性就行了(注意我们去掉了 resultType 属性)。比如:
<select id="selectUsers" resultMap="userResultMap">
select user_id, user_name, hashed_password
from some_table
where id = #{id}
</select>
高级映射
自动映射
通常数据库列使用大写字母组成的单词命名,单词间用下划线分隔;而 Java 属性一般遵循驼峰命名法约定。为了在这两种命名方式之间启用自动映射,需要将
mapUnderscoreToCamelCase设置为 true
对于每一个结果映射,在 ResultSet 出现的列,如果没有设置手动映射,将被自动映射。在自动映射处理完毕后,再处理手动映射。 在下面的例子中,id 和 userName 列将被自动映射,hashed_password 列将根据配置进行映射。
<select id="selectUsers" resultMap="userResultMap">
select
user_id as "id",
user_name as "userName",
hashed_password
from some_table
where id = #{id}
</select>
有三种自动映射等级:
NONE- 禁用自动映射。仅对手动映射的属性进行映射。PARTIAL- 对除在内部定义了嵌套结果映射(也就是连接的属性)以外的属性进行映射FULL- 自动映射所有属性。
默认值是 PARTIAL,这是有原因的。当对连接查询的结果使用 FULL 时,连接查询会在同一行中获取多个不同实体的数据,因此可能导致非预期的映射。 下面的例子将展示这种风险:
<select id="selectBlog" resultMap="blogResult">
select
B.id,
B.title,
A.username,
from Blog B left outer join Author A on B.author_id = A.id
where B.id = #{id}
</select>
在该结果映射中,Blog 和 Author 均将被自动映射。但是注意 Author 有一个 id 属性,在 ResultSet 中也有一个名为 id 的列,所以 Author 的 id 将填入 Blog 的 id,这可不是你期望的行为。 所以,要谨慎使用 FULL。
无论设置的自动映射等级是哪种,你都可以通过在结果映射上设置 autoMapping 属性来为指定的结果映射设置启用/禁用自动映射。
<resultMap id="userResultMap" type="User" autoMapping="false">
<result property="password" column="hashed_password"/>
</resultMap>
缓存
MyBatis 内置了一个强大的事务性查询缓存机制,它可以非常方便地配置和定制。 为了使它更加强大而且易于配置,我们对 MyBatis 3 中的缓存实现进行了许多改进。
默认情况下,只启用了本地的会话缓存,它仅仅对一个会话中的数据进行缓存。 要启用全局的二级缓存,只需要在你的 SQL 映射文件中添加一行:
<cache/>
这个简单语句的效果如下:
- 映射语句文件中的所有 select 语句的结果将会被缓存。
- 映射语句文件中的所有 insert、update 和 delete 语句会刷新缓存。
- 缓存会使用最近最少使用算法(LRU, Least Recently Used)算法来清除不需要的缓存。
- 缓存不会定时进行刷新(也就是说,没有刷新间隔)。
- 缓存会保存列表或对象(无论查询方法返回哪种)的 1024 个引用。
- 缓存会被视为读/写缓存,这意味着获取到的对象并不是共享的,可以安全地被调用者修改,而不干扰其他调用者或线程所做的潜在修改。
缓存只作用于 cache 标签所在的映射文件中的语句。如果你混合使用 Java API 和 XML 映射文件,在共用接口中的语句将不会被默认缓存。你需要使用 @CacheNamespaceRef 注解指定缓存作用域
这些属性可以通过 cache 元素的属性来修改。比如:
<cache eviction="FIFO" flushInterval="60000" size="512" readOnly="true"/>
这个更高级的配置创建了一个 FIFO 缓存,每隔 60 秒刷新,最多可以存储结果对象或列表的 512 个引用,而且返回的对象被认为是只读的,因此对它们进行修改可能会在不同线程中的调用者产生冲突。
可用的清除策略有:
LRU– 最近最少使用:移除最长时间不被使用的对象。FIFO– 先进先出:按对象进入缓存的顺序来移除它们。SOFT– 软引用:基于垃圾回收器状态和软引用规则移除对象。WEAK– 弱引用:更积极地基于垃圾收集器状态和弱引用规则移除对象。
默认的清除策略是 LRU。
flushInterval(刷新间隔)属性可以被设置为任意的正整数,设置的值应该是一个以毫秒为单位的合理时间量。 默认情况是不设置,也就是没有刷新间隔,缓存仅仅会在调用语句时刷新。
size(引用数目)属性可以被设置为任意正整数,要注意欲缓存对象的大小和运行环境中可用的内存资源。默认值是 1024。
readOnly(只读)属性可以被设置为 true 或 false。只读的缓存会给所有调用者返回缓存对象的相同实例。 因此这些对象不能被修改。这就提供了可观的性能提升。而可读写的缓存会(通过序列化)返回缓存对象的拷贝。 速度上会慢一些,但是更安全,因此默认值是 false。
二级缓存是事务性的。这意味着,当 SqlSession 完成并提交时,或是完成并回滚,但没有执行 flushCache=true 的 insert/delete/update 语句时,缓存会获得更新
使用自定义缓存
除了上述自定义缓存的方式,你也可以通过实现你自己的缓存,或为其他第三方缓存方案创建适配器,来完全覆盖缓存行为。
<cache type="com.domain.something.MyCustomCache"/>
这个示例展示了如何使用一个自定义的缓存实现。type 属性指定的类必须实现 org.apache.ibatis.cache.Cache 接口,且提供一个接受 String 参数作为 id 的构造器。 这个接口是 MyBatis 框架中许多复杂的接口之一,但是行为却非常简单。
public interface Cache {
String getId();
int getSize();
void putObject(Object key, Object value);
Object getObject(Object key);
boolean hasKey(Object key);
Object removeObject(Object key);
void clear();
}
为了对你的缓存进行配置,只需要简单地在你的缓存实现中添加公有的 JavaBean 属性,然后通过 cache 元素传递属性值,例如下面的例子将在你的缓存实现上调用一个名为 setCacheFile(String file) 的方法:
<cache type="com.domain.something.MyCustomCache">
<property name="cacheFile" value="/tmp/my-custom-cache.tmp"/>
</cache>
你可以使用所有简单类型作为 JavaBean 属性的类型,MyBatis 会进行转换。 你也可以使用占位符(如 ${cache.file}),以便替换成在配置文件属性中定义的值。
从版本 3.4.2 开始,MyBatis 已经支持在所有属性设置完毕之后,调用一个初始化方法。 如果想要使用这个特性,请在你的自定义缓存类里实现 org.apache.ibatis.builder.InitializingObject 接口。
public interface InitializingObject {
void initialize() throws Exception;
}
提示 上一节中对缓存的配置(如清除策略、可读或可读写等),不能应用于自定义缓存。
请注意,缓存的配置和缓存实例会被绑定到 SQL 映射文件的命名空间中。 因此,同一命名空间中的所有语句和缓存将通过命名空间绑定在一起。 每条语句可以自定义与缓存交互的方式,或将它们完全排除于缓存之外,这可以通过在每条语句上使用两个简单属性来达成。 默认情况下,语句会这样来配置:
<select ... flushCache="false" useCache="true"/>
<insert ... flushCache="true"/>
<update ... flushCache="true"/>
<delete ... flushCache="true"/>
鉴于这是默认行为,显然你永远不应该以这样的方式显式配置一条语句。但如果你想改变默认的行为,只需要设置 flushCache 和 useCache 属性。比如某些情况下你可能希望特定 select 语句的结果排除于缓存之外,或希望一条 select 语句清空缓存。类似地你可能希望某些 update 语句执行时不要刷新缓存。
cache-ref
回想一下上一节的内容,对某一命名空间的语句,只会使用该命名空间的缓存进行缓存或刷新。 但你可能会想要在多个命名空间中共享相同的缓存配置和实例。要实现这种需求,你可以使用 cache-ref 元素来引用另一个缓存。
<cache-ref namespace="com.someone.application.data.SomeMapper"/>
动态 SQL
来自:https://mybatis.org/mybatis-3/zh/dynamic-sql.html
动态 SQL 是 MyBatis 的强大特性之一。如果你使用过 JDBC 或其它类似的框架,你应该能理解根据不同条件拼接 SQL 语句有多痛苦,例如拼接时要确保不能忘记添加必要的空格,还要注意去掉列表最后一个列名的逗号。利用动态 SQL,可以彻底摆脱这种痛苦。
借助功能强大的基于 OGNL 的表达式,MyBatis 3 替换了之前的大部分元素,大大精简了元素种类,现在要学习的元素种类比原来的一半还要少。
- if
- choose (when, otherwise)
- trim (where, set)
- foreach
if
使用动态 SQL 最常见情景是根据条件包含 where 子句的一部分。比如:
<select id="findActiveBlogLike"
resultType="Blog">
SELECT * FROM BLOG WHERE state = ‘ACTIVE’
<if test="title != null">
AND title like #{title}
</if>
<if test="author != null and author.name != null">
AND author_name like #{author.name}
</if>
</select>
choose
有时候,我们不想使用所有的条件,而只是想从多个条件中选择一个使用。针对这种情况 MyBatis 提供了 choose 元素,它有点像 Java 中的 switch 语句。
<select id="findActiveBlogLike"
resultType="Blog">
SELECT * FROM BLOG WHERE state = ‘ACTIVE’
<choose>
<when test="title != null">
AND title like #{title}
</when>
<when test="author != null and author.name != null">
AND author_name like #{author.name}
</when>
<otherwise>
AND featured = 1
</otherwise>
</choose>
</select>
trim where set
where
前面几个例子已经方便地解决了一个臭名昭著的动态 SQL 问题。现在回到之前的 “if” 示例,这次我们将 “state = ‘ACTIVE’” 设置成动态条件,看看会发生什么。
<select id="findActiveBlogLike"
resultType="Blog">
SELECT * FROM BLOG
WHERE
<if test="state != null">
state = #{state}
</if>
<if test="title != null">
AND title like #{title}
</if>
<if test="author != null and author.name != null">
AND author_name like #{author.name}
</if>
</select>
如果没有匹配的条件会怎么样?最终这条 SQL 会变成这样:
SELECT * FROM BLOG
WHERE
MyBatis 有一个简单且适合大多数场景的解决办法。而在其他场景中,可以对其进行自定义以符合需求。而这只需要一处简单的改动:
<select id="findActiveBlogLike"
resultType="Blog">
SELECT * FROM BLOG
<where>
<if test="state != null">
state = #{state}
</if>
<if test="title != null">
AND title like #{title}
</if>
<if test="author != null and author.name != null">
AND author_name like #{author.name}
</if>
</where>
</select>
where 元素只会在子元素返回任何内容的情况下才插入 “WHERE” 子句。而且,若子句的开头为 “AND” 或 “OR”,where 元素也会将它们去除。
如果 where 元素与你期望的不太一样,你也可以通过自定义 trim 元素来定制 where 元素的功能。比如,和 where 元素等价的自定义 trim 元素为:
<trim prefix="WHERE" prefixOverrides="AND |OR ">
...
</trim>
prefixOverrides 属性会忽略通过管道符分隔的文本序列(注意此例中的空格是必要的)。上述例子会移除所有 prefixOverrides 属性中指定的内容,并且插入 prefix 属性中指定的内容。
set
用于动态更新语句的类似解决方案叫做 set。set 元素可以用于动态包含需要更新的列,忽略其它不更新的列。比如:
<update id="updateAuthorIfNecessary">
update Author
<set>
<if test="username != null">username=#{username},</if>
<if test="password != null">password=#{password},</if>
<if test="email != null">email=#{email},</if>
<if test="bio != null">bio=#{bio}</if>
</set>
where id=#{id}
</update>
这个例子中,set 元素会动态地在行首插入 SET 关键字,并会删掉额外的逗号(这些逗号是在使用条件语句给列赋值时引入的)。
来看看与 set 元素等价的自定义 trim 元素吧:
<trim prefix="SET" suffixOverrides=",">
...
</trim>
注意,我们覆盖了后缀值设置,并且自定义了前缀值。
foreach
动态 SQL 的另一个常见使用场景是对集合进行遍历(尤其是在构建 IN 条件语句的时候)。比如:
<select id="selectPostIn" resultType="domain.blog.Post">
SELECT *
FROM POST P
WHERE ID in
<foreach item="item" index="index" collection="list"
open="(" separator="," close=")">
#{item}
</foreach>
</select>
foreach 元素的功能非常强大,它允许你指定一个集合,声明可以在元素体内使用的集合项(item)和索引(index)变量。它也允许你指定开头与结尾的字符串以及集合项迭代之间的分隔符。这个元素也不会错误地添加多余的分隔符,看它多智能!
你可以将任何可迭代对象(如 List、Set 等)、Map 对象或者数组对象作为集合参数传递给 foreach。当使用可迭代对象或者数组时,index 是当前迭代的序号,item 的值是本次迭代获取到的元素。当使用 Map 对象(或者 Map.Entry 对象的集合)时,index 是键,item 是值。
script
要在带注解的映射器接口类中使用动态 SQL,可以使用 script 元素。比如:
@Update({"<script>",
"update Author",
" <set>",
" <if test='username != null'>username=#{username},</if>",
" <if test='password != null'>password=#{password},</if>",
" <if test='email != null'>email=#{email},</if>",
" <if test='bio != null'>bio=#{bio}</if>",
" </set>",
"where id=#{id}",
"</script>"})
void updateAuthorValues(Author author);
bind
bind 元素允许你在 OGNL 表达式以外创建一个变量,并将其绑定到当前的上下文。比如:
<select id="selectBlogsLike" resultType="Blog">
<bind name="pattern" value="'%' + _parameter.getTitle() + '%'" />
SELECT * FROM BLOG
WHERE title LIKE #{pattern}
</select>
多数据库支持
如果配置了 databaseIdProvider,你就可以在动态代码中使用名为 “_databaseId” 的变量来为不同的数据库构建特定的语句。比如下面的例子:
<insert id="insert">
<selectKey keyProperty="id" resultType="int" order="BEFORE">
<if test="_databaseId == 'oracle'">
select seq_users.nextval from dual
</if>
<if test="_databaseId == 'db2'">
select nextval for seq_users from sysibm.sysdummy1"
</if>
</selectKey>
insert into users values (#{id}, #{name})
</insert>
API
来自:https://mybatis.org/mybatis-3/zh/java-api.html















 592
592











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











