







 本文详细介绍Elasticsearch单节点及集群的安装配置过程。包括JDK环境搭建、elasticsearch安装步骤、使用Head插件进行数据浏览,以及分布式集群配置等关键环节。
本文详细介绍Elasticsearch单节点及集群的安装配置过程。包括JDK环境搭建、elasticsearch安装步骤、使用Head插件进行数据浏览,以及分布式集群配置等关键环节。
单节点的安装
1、首先安装jdk,最好是1.8及其以上的版本
2、下载elasticsearch的压缩包。
elasicsearch下载地址
将下载的压缩包进行解压缩,得到一个文件夹

进入到这个目录里面去

这里主要用到的就是 bin目录和config目录 bin目录是一些命令 config里面放了配置文件
执行命令启动elasticsearch : ./bin/elasticsearch -d (-d是让服务在后台运行)
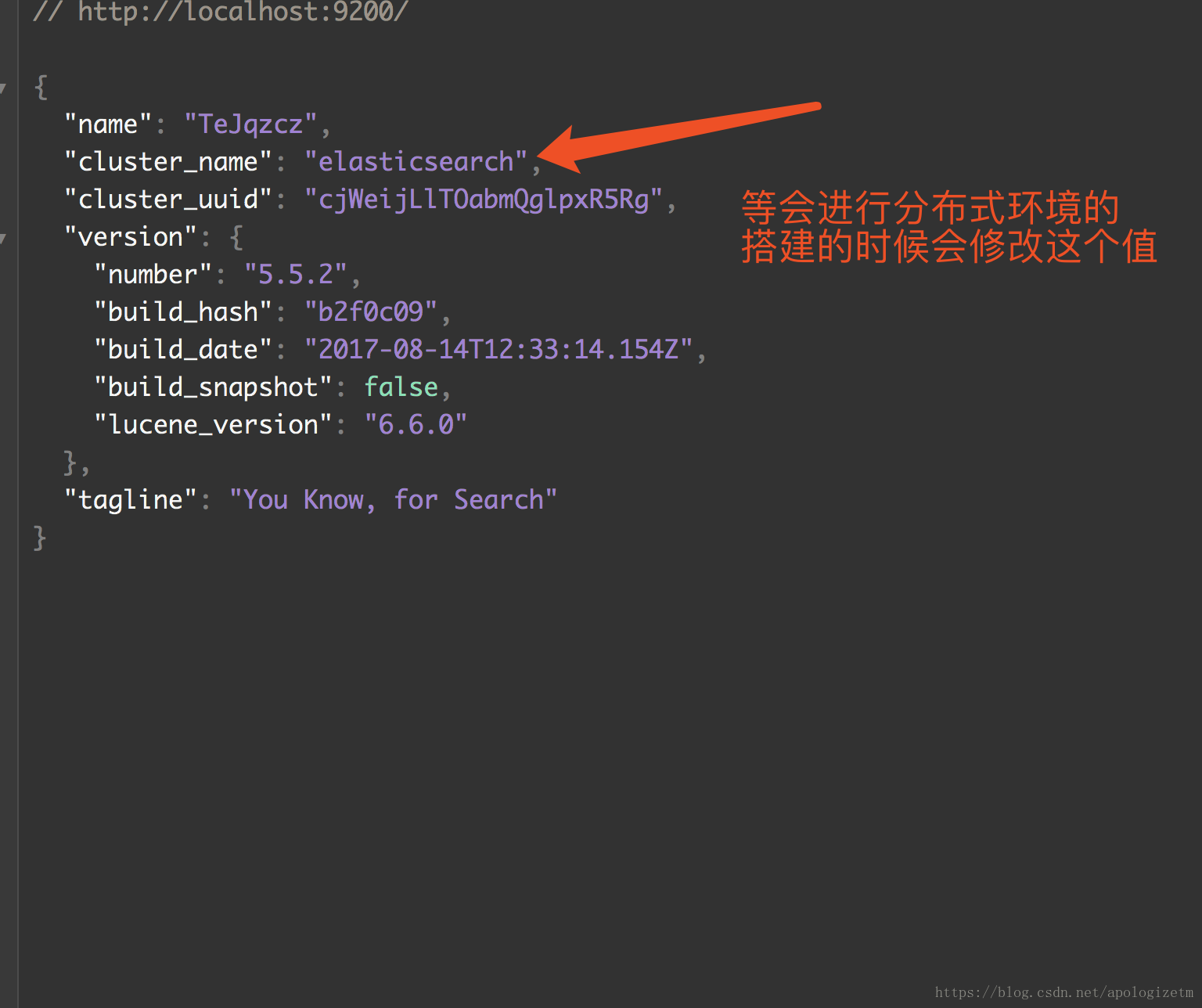
在浏览器里面输入http://localhost:9200/
出现如下页面表示安装成功
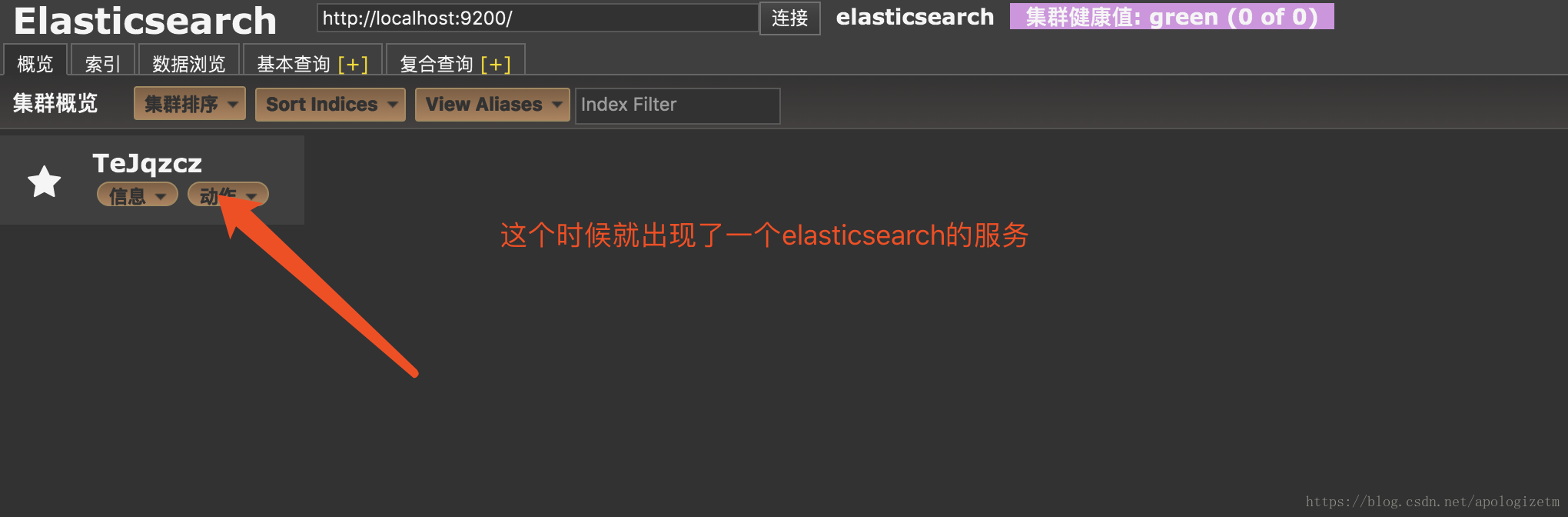
下面介绍一个插件head,它给我们提供了友好的web界面来查看elasticsearch数据
1、下载head插件
插件的下载地址
2、解压下载后的压缩包
3、这个时候需要node的环境能运行这个插件(具体node的安装 大家可以参考下其他的资料)
node安装教程
4、先使用npm install 下载一些需要的依赖 再使用npm run start来启动服务
在浏览器里面输入http://localhost:9100/ 会看到如下页面
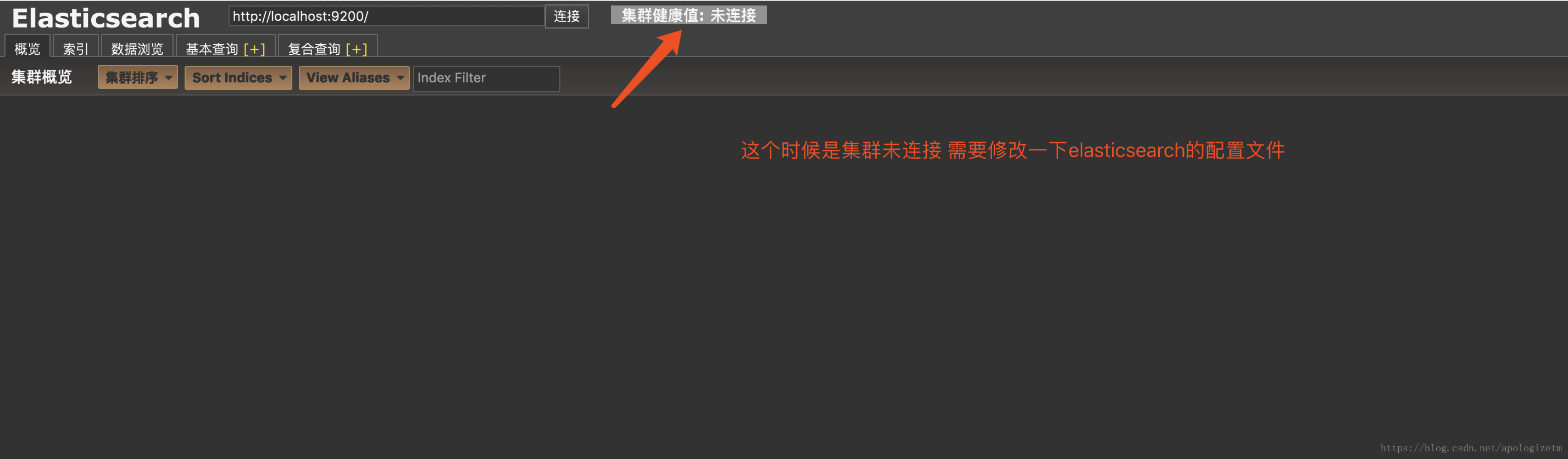
在elasticsearch的config目录的elasticsearch.yml文件的末尾加上:
http.cors.enabled: true
http.cors.allow-origin: “*”
然后停掉当前的elasticsearch服务 重新启动 停止服务的操作:ps aux | grep elasticsearch 找到服务的pid然后使用kill命令停止,再重新启动服务
分布式的安装
修改刚才的config下的elasticsearch.yml文件 在文件末尾加上下面四行
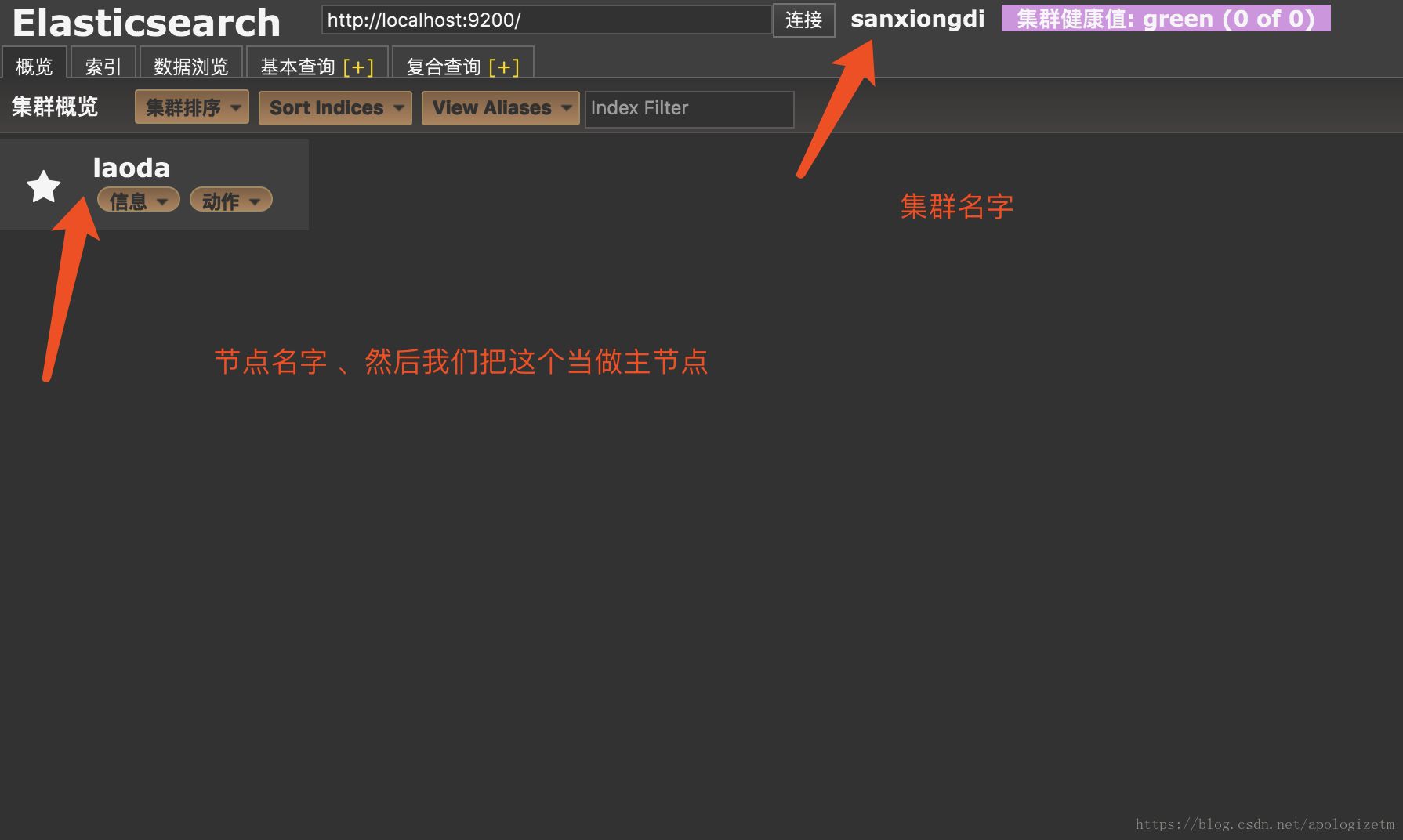
cluster.name: sanxiongdi
node.name: laoda
node.master: true
network.host: 127.0.0.1
node.name和cluster.name可以自定义
然后重启服务后去head插件的页面看下结果
下面把刚才的elasticsearch的压缩包解压两份 重命名 当做两个slave节点来使用
将两份文件当中的config目录下的elasticsearch.yml文件加上下面几段文字:
cluster.name: sanxiongdi
node.name: laosan
network.host: 127.0.0.1
http.port: 9202
discovery.zen.ping.unicast.hosts: ["127.0.0.1"]
其中cluster.name要和刚才的master节点的名字一样
node.name自己定义不要重复 当做当前节点的名字
最后一段话就是将当前节点连接到集群上面去
配置文件修改完后就直接启动服务,然后去head插件的页面(http://localhost:9100/),看到如下页面:
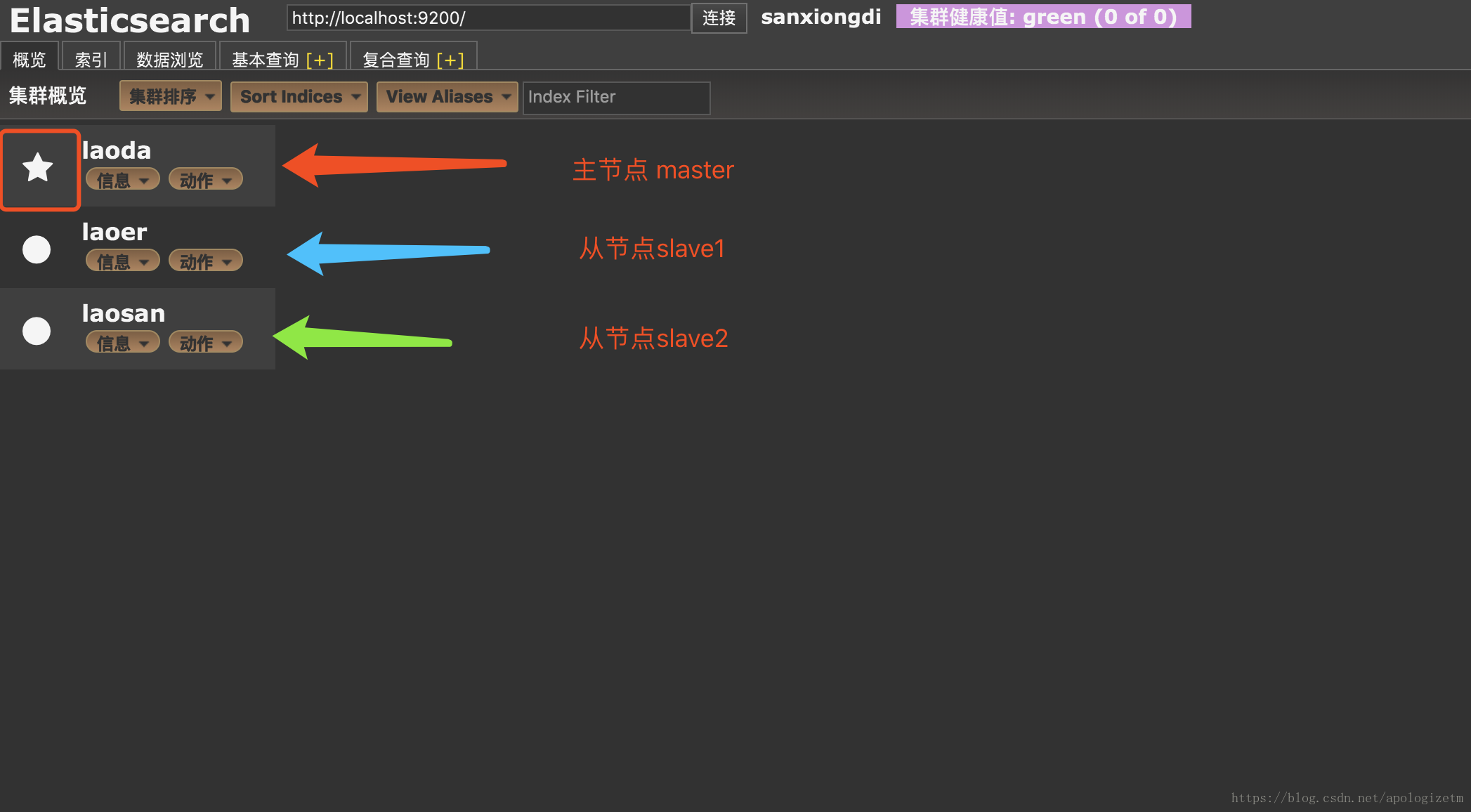
elasticsearch的单节点个集群的搭建到此结束了,使用命令和代码进行操作的介绍在下篇文章中介绍. 使用命令和代码操作

















 7353
7353

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









