







文章目录
- 1、MySQL常用的存储引擎有什么?它们有什么区别?
- 2、说一下数据库的三大范式
- 3、MySQL的数据类型有哪些 ?
- 4、SQL语句主要分为哪几类?
- 5、SQL约束有哪些?
- 6、什么是子查询?
- 7、了解MySQL的几种连接查询吗?
- 8、mysql中in和exists的区别?
- 9、varchar和char的区别?
- 10、MySQL中int(10)和char(10)和varchar(10)的区别?
- 11、drop、delete和truncate的区别?
- 12、UNION和UNION ALL的区别?
- 13、什么是临时表,什么时候会使用到临时表,什么时候删除临时表?
- 14、大表数据查询如何进行优化?
- 15、为什么要设置主键?
- 16、了解慢查询日志吗?统计过慢查询吗?对慢查询如何优化?
- 17、主键一般用自增ID还是UUID?
- 18、字段为什么要设置成NOT NULL?
- 19、MySQL的binlog有有几种录入格式?分别有什么区别?
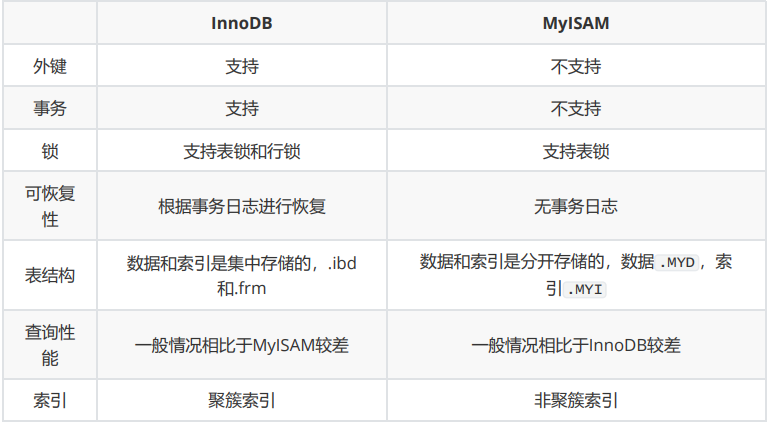
1、MySQL常用的存储引擎有什么?它们有什么区别?
答:MySQL常用的存储引擎有InnoDB和MyISAM:
InnoDB
- InnoDB是MySQL的默认存储引擎,支持事务、行锁和外键等操作。
MyISAM
- MyISAM是MySQL5.1版本前的默认存储引擎,MyISAM的并发性比较差,不支持事务和外键等操作,默认的锁的粒度为表级锁。
对比如下:
2、说一下数据库的三大范式
答:
- 第一范式:确保每列保持原子性,数据表中的所有字段值都是不可分解的原子值。
- 第二范式:确保表中的每列都和主键相关。
- 第三范式:确保每列都和主键列直接相关而不是间接相关。
3、MySQL的数据类型有哪些 ?
答:
整数
TINYINT:占用8位存储空间;SMALLINT:占用16位存储空间;MEDIUMINT:占用24位存储空间;INT:占用32位存储空间;BIGINT:占用64位存储空间;
值得注意的是,INT(10)中的10只是表示显示字符的个数,并无实际意义。一般和
UNSIGNED ZEROFILL配合使用才有实际意义,例如,数据类型INT(3),属性为UNSIGNED ZEROFILL,如果插入的数据为3的话,实际存储的数据为003。
浮点数
FLOAT、DOUBLE及DECIMAL为浮点数类型;- DECIMAL是利用字符串进行处理的,能存储精确的小数;
- 相比于FLOAT和DOUBLE,DECIMAL的效率更低些;
- FLOAT、DOUBLE及DECIMAL都可以指定列宽;
例如
FLOAT(5,2)表示一共5位,两位存储小数部分,三位存储整数部分。
字符串
- 字符串常用的主要有
CHAR和VARCHAR; - VARCHAR主要用于存储可变长字符串,相比于定长的CHAR更节省空间;
- CHAR是定长的,根据定义的字符串长度分配空间。
应用场景:
- 对于经常变更的数据使用CHAR更好,
CHAR不容易产生碎片。- 对于非常短的列也是使用CHAR更好些,
CHAR相比于VARCHAR在效率上更高些。- 一般避免使用TEXT/BLOB等类型,因为查询时会使用临时表,造成严重的性能开销。
日期
- 比较常用的有
year、time、date、datetime、timestamp等 - datetime保存从1000年到9999年的时间,精度到秒,使用八字节的存储空间,与时区无关;
- timestamp和UNIX的时间戳相同,保存从1970年1月1日午夜到2038年的时间,精度到秒,使用四个字节的存储空间,并且与时区相关。
应用场景:尽量使用
timestamp,相比于datetime它有着更高的空间效率。
4、SQL语句主要分为哪几类?
答:
- 数据据定义语言DDL(Data Definition Language):主要有
CREATE,DROP,ALTER等对逻辑结构有操作的,包括表结构、视图和索引; - 数据库查询语言DQL(Data Query Language):主要以
SELECT为主; - 数据操纵语言DML(Data Manipulation Language):主要包括
INSERT,UPDATE,DELETE; - 数据控制功能DCL(Data Control Language):主要是权限控制操作,包括
GRANT,REVOKE,COMMIT,ROLLBACK等。
5、SQL约束有哪些?
答:有主键约束、外键约束、唯一约束、默认约束和Check约束,主要区别如下:
主键约束
- 主键为在表中存在一列或者多列的组合,能唯一标识表中的每一行。
- 一个表只有一个主键,并且主键约束的列不能为空。
外键约束
- 外键约束是指用于在两个表之间建立关系,需要指定引用主表的哪一列。
- 只有主表的主键可以被从表用作外键,被约束的从表的列可以不是主键。
- 所以创建外键约束需要先定义主表的主键,然后定义从表的外键。
唯一约束
- 确保表中的一列数据没有相同的值,一个表可以定义多个唯一约束。
默认约束
- 在插入新数据时,如果该行没有指定数据,系统将默认值赋给该行。
- 如果没有设置没默认值,则为NULL。
Check约束
- Check会通过逻辑表达式来判断数据的有效性,用来限制输入一列或者多列的值的范围。
- 在列更新数据时,输入的内容必须满足Check约束的条件。
6、什么是子查询?
答:子查询就是把一个查询的结果在另一个查询中使用。
子查询可以分为以下几类:
- 标量子查询:指子查询返回的是一个值;
- 列子查询:指子查询的结果是n行一列;
- 行子查询:指子查询返回的结果一行n列;
- 表子查询:指子查询是n行n列的一个数据表;
7、了解MySQL的几种连接查询吗?
答:MySQl的连接查询主要可以分为外连接,内连接,交叉连接,区别如下:
外连接
- 外连接主要分为左外连接(
LEFT JOIN)、右外连接(RIGHT JOIN)、全外连接。- 左外连接:返回包括左表中的所有记录和右表中连接字段相等的记录,右表中不符合条件的数据为null。
- 右外连接:返回包括右表中的所有记录和左表中连接字段相等的记录,左表中不符合条件的数据为null。
- 全外连接:返回左右表中所有的记录和左右表中连接字段相等的记录。
MySQL中不支持全外连接。
内连接
- 内连接也称为等同连接,返回的结果集是两个表中所有相匹配的数据,而舍弃不匹配的数据。
交叉连接
- 使用笛卡尔积的一种连接。
8、mysql中in和exists的区别?
答:in和exists一般用于子查询。
- 使用
exists时会先进行外表查询,将查询到的每行数据带入到内表查询中看是否满足条件; - 使用
in一般会先进行内表查询获取结果集,然后对外表查询匹配结果集,返回数据。 in在内表查询或者外表查询过程中都会用到索引。exists仅在内表查询时会用到索引。- 一般来说,当子查询的结果集比较大,外表较小使用
exist效率更高; - 当子查询寻得结果集较小,外表较大时,使用
in效率更高。 - 对于
not in和not exists,not exists效率比not in的效率高,与子查询的结果集无关,因为not in对于内外表都进行了全表扫描,没有使用到索引。not exists的子查询中可以用到表上的索引。
9、varchar和char的区别?
答:
-
varchar表示变长,char表示长度固定。
- 当所插入的字符超过他们的长度时:
- 在严格模式下,会拒绝插入并提示错误信息。
- 在一般模式下,会截取后插入。
- 当所插入的字符小于他们的长度时:
- 如
char(5),无论插入的字符长度是多少,长度都是5,插入字符长度小于5,则用空格补充。 - 对于
varchar(5),如果插入的字符长度小于5,则存储的字符长度就是插入字符的长度,不会填充。
- 如
- 当所插入的字符超过他们的长度时:
-
存储容量不同:
- 对于
char来说,最多能存放的字符个数为255。 - 对于
varchar来说,最多能存放的字符个数是65532。
- 对于
-
存储速度不同:
char长度固定,存储速度会比varchar快一些,但在空间上会占用额外的空间,属于一种空间换时间的策略。varchar长度不固定,而varchar空间利用率会高些,但存储速度慢,属于一种时间换空间的策略。
10、MySQL中int(10)和char(10)和varchar(10)的区别?
答:int(10)中的10表示的是显示数据的长度,而char(10)和varchar(10)表示的是存储数据的大小。
11、drop、delete和truncate的区别?
答:区别如下:
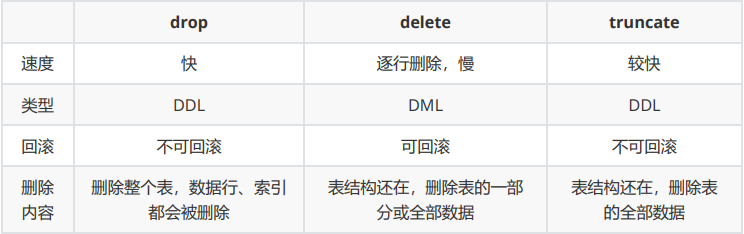
一般来讲:
- 删除整个表,使用drop;
- 删除表的部分数据使用delete;
- 保留表结构删除表的全部数据使用truncate;
12、UNION和UNION ALL的区别?
答:union和union all的作用都是将两个结果集合并到一起。
union会对结果去重并排序;union all直接直接返回合并后的结果,不去重也不进行排序;union all的性能比union性能好;
13、什么是临时表,什么时候会使用到临时表,什么时候删除临时表?
答:MySQL在执行SQL语句的时候会临时创建一些存储中间结果集的表,这种表被称为临时表,临时表只对当前连接可见,在连接关闭后,临时表会被删除并释放空间。
临时表主要分为内存临时表和磁盘临时表两种:
- 内存临时表使用的是MEMORY存储引擎;
- 磁盘临时表使用的是MyISAM存储引擎;
一般在以下几种情况中会使用到临时表:
FROM中的子查询DISTINCT查询并加上ORDER BYORDER BY和GROUP BY的子句不一样时会产生临时表UNION查询会产生临时表
14、大表数据查询如何进行优化?
答:
- 索引优化
- SQL语句优化
- 水平拆分
- 垂直拆分
- 建立中间表
- 使用缓存技术
- 固定长度的表访问起来更快
- 越小的列访问越快
15、为什么要设置主键?
答:主键是唯一区分表中每一行的唯一标识,如果没有主键,更新或者删除表中特定的行会很困难,因为不能唯一准确地标识某一行。
16、了解慢查询日志吗?统计过慢查询吗?对慢查询如何优化?
答:慢查询日志一般用于记录执行时间超过某个临界值的SQL语句的日志。
相关参数
slow_query_log:是否开启慢查询日志,1表示开启,0表示关闭。slow_query_log_file:MySQL数据库慢查询日志存储路径。long_query_time:慢查询阈值,当SQL语句查询时间大于阈值,会被记录在日志上。log_queries_not_using_indexes:未使用索引的查询会被记录到慢查询日志中。log_output:日志存储方式。“FILE”表示将日志存入文件。“TABLE”表示将日志存入数据库。
如何对慢查询进行优化?
- 分析语句的执行计划,查看SQL语句的索引是否命中。
- 优化数据库的结构,将字段很多的表分解成多个表,或者考虑建立中间表。
- 优化LIMIT分页。
17、主键一般用自增ID还是UUID?
答:我们先来看一下自增ID与UUID的区别:
自增ID:在设计表时将id字段的值设置为自增的形式。
使用自增ID的好处
- 字段长度较uuid会小很多。
- 数据库自动编号,按顺序存放,利于检索。
- 无需担心主键重复问题。
使用自增ID的缺点
- 因为是自增,在某些业务场景下,容易被其他人查到业务量。
- 发生数据迁移时,或者表合并时会非常麻烦。
- 在高并发的场景下,竞争自增锁会降低数据库的吞吐能力。
UUID:通用唯一标识码,UUID是基于当前时间、计数器和硬件标识等数据计算生成的。
使用UUID的优点
- 唯一标识,不会考虑重复问题,在数据拆分、合并时也能达到全局的唯一性。
- 可以在应用层生成,提高数据库的吞吐能力。
- 无需担心业务量泄露的问题。
使用UUID的缺点
- 因为UUID是随机生成的,所以会发生随机IO,影响插入速度,并且会造成硬盘的使用率较低。
- UUID占用空间较大,建立的索引越多,造成的影响越大。
- UUID之间比较大小较自增ID慢不少,影响查询速度。
最后说下结论:
- 一般情况MySQL推荐使用自增ID。因为在MySQL的InnoDB存储引擎中,主键索引是一种聚簇索引,主键索引的B+树的叶子节点按照顺序存储了主键值及数据,如果主键索引是自增ID,只需要按顺序往后排列即可,如果是UUID,ID是随机生成的,在数据插入时会造成大量的数据移动,产生大量的内存碎片,造成插入性能的下降。
18、字段为什么要设置成NOT NULL?
答:首先说一点,NULL和空值是不一样的,空值是不占用空间的,而NULL是占用空间的,所以字段设为NOT NULL后仍然可以插入空值。
字段设置成NOT NULL主要有以下几点原因:
- NULL值会影响一些函数的统计,如
COUNT,遇到NULL值,这条记录不会统计在内。 - B树不存储NULL,所以索引用不到NULL,会造成第一点中说的统计不到的问题。
NOT IN子查询在有NULL值的情况下返回的结果都是空值。- MySQL在进行比较的时候,NULL会参与字段的比较,因为NULL是一种比较特殊的数据类型,数据
库在处理时需要进行特殊处理,增加了数据库处理记录的复杂性。
19、MySQL的binlog有有几种录入格式?分别有什么区别?
有三种格式,statement,row和mixed:
statement级别下,每一条会修改数据的sql都会记录在binlog中。- 不需要记录每一行的变化,减少了binlog日志量,节约了IO,提高性能。
- 由于sql的执行是有上下文的,因此在保存的时候需要保存相关的信息。
- 还有一些使用了函数之类的语句无法被记录复制。
row级别下,不记录sql语句上下文相关信息,仅保存哪条记录被修改。- 记录单元为每一行的改动,基本是可以全部记下来但是由于很多操作会导致大量行的改动(比如altertable)。
- 因此这种模式的文件保存的信息太多,日志量太大。
mixed级别,一种折中的方案,普通操作使用statement记录,当无法使用statement的时候使用row。
此外,新版的MySQL中对row级别也做了一些优化,当表结构发生变化的时候,会记录语句而不是逐行记录。
















 10万+
10万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











