






数据结构:树
一、树
1、树的定义
由n个结点构成的集合,n=0称为空树,n=1的树只有一个结点,对于n>1的树T有:
- 最顶端的结点称为根节点,根结点无前驱结点
- 除根结点,其余结点被分为m个不相交的集合,每个集合又是结构与树类似的子树
常用术语:
- 结点的度:结点所拥有的子树(或者孩子结点)的个数
- 叶结点:度为0(无子树)
- 树的度:所有结点的度的最大值
- 分支结点:度不为0的结点称为分支结点
- 孩子结点:树中一个结点的子树的根结点
- 双亲结点:孩子结点的前驱结点
- 兄弟结点:具有相同双亲结点的结点
- 结点的层次:根结点的层次规定为0,则其它结点的层次是其双亲结点层次+1
- 树的深度:结点层次的最大值,层次为0的树只有一个根节点
- 树的高度:树的深度+1
- 有序树:从左到右的兄弟结点存在次序不能互换
- 森林:树的集合
2、树的常见性质
① 结点数=结点总度数+1
结点的度代表该结点有几个孩子,根节点没有算入,所以+1
② 度为m的数:代表其中一个结点的度最大值是m
m叉树:代表结点的度最大为m
③ 度为m的树第i层至多有mi个结点(根节点为第0层)
④ 高度为h的m叉树至多有[mh-1]/[m-1]个结点
- 深度为k的m叉树至多有[mk+1-1]/[m-1]个结点
⑤ 具有m个结点的m叉树的最小高度为[logm(n(m-1)+1)]
3、树的抽象数据类型
① 数据集合
树的结点集合,每个结点由数据元素和构造数据元素之间关系的指针组成
② 操作集合
Initiate(T);//初始化
Parent(T,curr);//返回双亲结点或NULL
LeftChild(T,curr);//返回左兄弟结点
RightChild(T,curr);//返回右兄弟结点
Traverse(T,Visit());//前中后序遍历
DestroyTree(T);//撤销树
4、树的存储结构
① 双亲表示法
- 顺序存储
- 一个结点存储两个内容,data和parent
② 双亲孩子表示法
- 顺序+链式
- 顺序存放结点即data,链式存放第一个孩子firstChild

③ 孩子兄弟表示法
- 链式
- 类似链式存储二叉树
- 每个结点的后继结点,一个是第一个孩子,一个是兄弟结点

5、树、森林和二叉树转换
① 森林👉二叉树
将根结点用右指针连接,若有树X,Y,Z(表示结点树)转换为二叉树,则以X的根结点作为根结点,用右指针连接Y,然后用Y的右指针连接Z,则右子树总数为Y+Z,左子树总数为X-1。
② 二叉树👉森林
反之,将右子树从最底层分离,一直到根节点
③ 树👉二叉树
将结点的孩子放在左子树,将结点的兄弟放在右子树。

二、二叉树
1、二叉树的定义
二叉树不是树的特例,树和二叉树是同属于树结构的两种不同类型
- n=0:空二叉树
- n=1:只有一个根结点
- n>1:由一个根节点和至多两个互不相交的,分别称为左子树和右子树的子二叉树构成
满二叉树:所有分支结点都存在左子树和右子树,所有叶子结点都在同一层,深度为k,则有2k+1-1个结点的二叉树
- 只有最后一层有叶子结点
- 不存在度为1的结点
- 按层序从1开始编号,结点i的左孩子为2i,右孩子为2i+1,结点i的父节点为[i/2]
完全二叉树:当且仅当每个结点都与高度为h的满二叉树中编号为1~n的结点一一对应时,称为完全二叉树
- 只有最后两层可能有叶子结点
- 对任一结点,其左分支下的子孙最大层次不小于其右分支下的子孙的最大层次
- 最多只有一个度为1的结点
- i≤[n/2]为分支结点,反之为叶子结点
二叉排序树:左子树的根结点均小于右子树根结点的关键字
平衡二叉树:树上任一结点的左子树和右子树的深度之差不超过1
2、二叉树的性质
二叉树
① 设非空二叉树中度为0,1,2的结点个数分别为x,y,z,则x=z+1
- 叶子结点比二分支结点(同时有左孩子和右孩子)多一个
② 二叉树第i层至多有2i个结点
-
m叉树第i层至多有mi个结点
③ 高度为h的二叉树至多有2h-1个结点 -
[mh+1-1]/[m-1]
-
深度为k的二叉树至多有2k+1-1个结点
完全二叉树
④ 具有n个结点的完全二叉树的高度h为[log2(n+1)]或[log2n]+1
- 第i个结点所在层次为[log2(n+1)]或[log2n]+1
⑤ 具有n个结点的完全二叉树的深度为log2(n+1)-1
⑥ 对于完全二叉树,可以由的结点数n推出度为0、1和2的结点个数为x、y、z
- 完全二叉树最多只有一个度为1的结点
- y为0或1
- x=z+1一定是奇数
- 若完全二叉树有2k个结点,则必有x=1,y=k,z=k-1
⑦
- i的左孩子2i,右孩子2i+1
- i的父结点i/2
- i所在的层次log2(n+1)或log2n+1
- 判断i是否有左孩子:2i≤n
- 判断i是否有右孩子:2i+1≤n
- 判断i是否有叶子/分支结点:i>[n/2]
3、二叉树的存储结构
① 顺序存储
二叉树的大小和形状不发生剧烈动态变化时
② 链式存储
n个结点的二叉链表共有n+1个空链域
typedef struct BiTNode
{ DataType data;
struct BiTNode *leftChild;
struct BiTNode *rightChild;
} BiTreeNode;
void Initiate(BiTreeNode **root)/*初始化*/
{ *root = (BiTreeNode *)malloc(sizeof(BiTreeNode));/ /头结点
(*root)->leftChild = NULL;
(*root)->rightChild = NULL;
}
BiTreeNode *InsertLeftNode(BiTreeNode *curr, DataType x)
/*在curr结点的左子树插入结点x*/
{ BiTreeNode *s, *t; //s:新生成结点指针
if (curr == NULL) return NULL; //插入失败
t = curr->leftChild; //原左子树
s = (BiTreeNode *)malloc(sizeof(BiTreeNode));
s->data = x;
s->leftChild = t;
s->rightChild = NULL;
curr->leftChild = s; //新左子树
return curr->leftChild; //插入成功
}
BiTreeNode *DeleteLeftTree(BiTreeNode *curr)
/*删除curr结点的左子树*/
{ if(curr == NULL || curr->leftChild == NULL)
return NULL; //删除失败
Destroy(&curr->leftChild); //待述
curr->leftChild = NULL;
return curr; //删除成功
}
void main(void)
{ BiTreeNode *root, *p;
Initiate(&root);
p = InsertLeftNode(root, 'A');
p = InsertLeftNode(p, 'B');
p = InsertLeftNode(p, 'D');
p = InsertRightNode(p, 'G');
p = InsertRightNode(root->leftChild, 'C');
InsertLeftNode(p, 'E');
InsertRightNode(p, 'F');
}
4、二叉树的先中后序遍历
先左后右,根跟名走
① 先序遍历(NLR)
对每棵子树
先根结点,再左结点,再右结点
② 中序遍历(LNR)
对每棵子树
先左子树,再根节点,再右结点
③ 后序遍历
对每棵子树
先左子树,再右子树,再根结点
5、二叉树的层序遍历
一层一层的从左到右遍历(可用队列辅助)
6、由遍历序列构造二叉树
只给出一种遍历顺序,不能得出一个确定的二叉树,确定一棵二叉树至少要确定:
-
前+中
-
后+中
-
层+中
找对应的组合,从上至下拆分
- 确认根节点,左右子树包含的结点
- 循环上一步
三、二叉排序/查找/搜索(BST)树
1、定义
左子树结点值<根结点值<右子树结点值
使用中序遍历可获得一个递增的有序序列
- 或者是一颗空二叉树;
- 或者是具有下列性质的二叉树:对于根结点,设其值为K,
- 则该结点的左子树(若不空)的任意一个结点的值都小于K;
- 该结点的右子树(若不空)的任意一个结点的值都大于K;而
- 且它的左右子树也分别为二叉搜索树。
2、二叉搜索树的查找算法
① 思想
- 从根结点开始,在二叉搜索树中查找k。
- 如果根结点的值等于k,则查找成功,查找结束;
- 如果k小于根结点的值,则只需查找根的左子树;
- 如果k大于根结点的值,就只查找根的右子树。
这个过程一直持续到k被找到(查找成功)或者遇上了一个叶结点仍然没找到k(查找失败)。 - 查找成功返回所查结点的地址,查找失败返回NULL。
- 二叉搜索树查找效率高的原因在于只需查找二个子树之一。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-DMB88v2d-1625191541574)(C:\Users\官二的磊子\Desktop\未来村村长\图片\image-20210701201849707.png)]](https://img-blog.csdnimg.cn/20210702100633256.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L2FwcGxlXzUxOTc2MzA3,size_16,color_FFFFFF,t_70)
② 实现(后者为递归)
BiTreeNode * SearchI(BiTreeNode * root, DataType item)
/*在root结点为根的二叉搜索树中迭代形式查找item数据元素*/
{ BiTreeNode *current;
if (root!=NULL)
{ current=root;
while(current!=NULL)
{ if(item.key==current->data.key)
return current; /*查找成功*/
else if(item.key<current->data.key)
current=current->leftChild;
else current=current->rightChild;
}
}
return NULL; /*查找失败*/
}
BiTreeNode * Search(BiTreeNode * p, DataType item)
/*在p结点为根的二叉搜索树中递归形式查找item数据元素*/
{ if (p==NULL)
return NULL; //base case 1:查找失败,不递推,返回1.?
if( item.key==p->data.key)
return p; //base case 2:查找成功,不递推,返回2.?
else if( item.key<p->data.key)
return Search(p->leftChild, item); //递推,返回3.?
else return Search(p->rightChild, item);} //递推,返回4.?
③ 性能分析
二叉搜索树最大比较次数取决于树的高度O(h)
- 有序插入时形成一棵单支树,此时是最坏情况,对树的搜索、插入和删除操作所需要的时间均为O(n)。
- u 在随机情况下,搜索、插入和删除操作的平均时间是O(logn)。
3、二叉搜索树的插入
插入是这样进行的:
- 首先在二叉搜索树中查找item结点。
- 若查找失败,则得到插入位置parent。
生成一新结点,新结点的数据域置为item。 - 若二叉搜索树为空,则新结点为二叉搜索树的根结点。
- 若二叉搜索树非空,则将新结点的值和parent的关键字值比较:
- 若小于parent结点的值,则插入作为parent的左孩子
- 若大于parent结点的值,则插入作为parent的右孩子
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Cbj9GCNI-1625191541577)(C:\Users\官二的磊子\Desktop\未来村村长\图片\image-20210701201909845.png)]](https://img-blog.csdnimg.cn/20210702100643107.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L2FwcGxlXzUxOTc2MzA3,size_16,color_FFFFFF,t_70)
BiTreeNode * InsertI(BiTreeNode **root, DataType item)
/*在以root为根指针的二叉搜索树中迭代形式插入新的item结点*/
{ BiTreeNode *current,*parent=NULL,*p;
current =*root;
while(current!=NULL)
{ if(item.key== current->data.key) return NULL; /*查找成功不插入*/
parent= current;
if(item.key>current ->data.key)
current = current ->rightChild;
else current = current ->leftChild;
}
p=(BiTreeNode *)malloc(sizeof(BiTreeNode));
p->data=item; p->leftChild=p->rightChild=NULL;
if (parent==NULL) *root=p; /*二叉搜索树为空,p作为根结点*/
else if(item.key<parent->data.key) parent->leftChild=p;
else parent->rightChild=p; /*插入p结点*/
return p; /*成功插入*/
}
BiTreeNode * Insert(BiTreeNode * p, DataType item)
{ if (p==NULL) /*base case 1: 查找失败插入,不递推,返回1. ?*/
{ q=(BiTreeNode *)malloc(sizeof(BiTreeNode));
q->data = item; q->leftChild = q->rightChild = NULL;
return q; } /*何时建立连接?*/
if ( item.key < p->data.key)
p->leftChild=Insert(p->leftChild,item); //递推,返回后建立连接
else
if ( item.key > p->data.key)
p->rightChild=Insert(p->rightChild,item);//递推,返回后建立连接
return p; }/*base case 2: 查找成功不插入,不递推,返回2. ?*/
3、二叉搜索树的删除
被删结点具有以下三种情况:
- 1)被删结点是 叶结点(左、右子树都空 )
- 2)被删结点 只有1个孩子结点 (左子树空或
右子树空) - 3)被删结点 有2个孩子结点(左、右子树都
不空)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-xmzkmfur-1625191541579)(C:\Users\官二的磊子\Desktop\未来村村长\图片\image-20210701202057942.png)]](https://img-blog.csdnimg.cn/20210702100654717.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L2FwcGxlXzUxOTc2MzA3,size_16,color_FFFFFF,t_70)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ZngLG0xI-1625191541581)(C:\Users\官二的磊子\Desktop\未来村村长\图片\image-20210701202113749.png)]](https://img-blog.csdnimg.cn/20210702100659266.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L2FwcGxlXzUxOTc2MzA3,size_16,color_FFFFFF,t_70)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-MAvTtW51-1625191541583)(C:\Users\官二的磊子\Desktop\未来村村长\图片\image-20210701202226676.png)]](https://img-blog.csdnimg.cn/20210702100706814.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L2FwcGxlXzUxOTc2MzA3,size_16,color_FFFFFF,t_70)
BiTreeNode* Remove ( BiTreeNode* p, DataType item)
{ //递归函数:在以ptr为根的二叉搜索树中删除含x的结点,
//若删除成功,则新根通过ptr返回。
BiTreeNode *replace,*temp;
if ( p == NULL ) //base case 1: 探到NULL,删除失败,不递推,返回1: ?
return NULL;
if ( item.key < p->data.key )
p->leftChild=Remove(p->leftChild, item); //递推-在左子树中删除,返回后建立链接
else if ( item.key > p->data.key )
p->rightChild=Remove(p->rightChild, item); //递推-在右子树中删除,返回后建立链接
else if ( p->leftChild && p->rightChild )
//找到要删除的关键码为x的结点,并且该结点有两个子女
{ replace= p->leftChild; /*在p左子树找替身结点*/
while( replace->rightChild!=NULL ) replace=replace->rightChild ;
p->data = replace->data; //用该结点数据域覆盖ptr的数据域
p->leftChild=Remove ( p->leftChild, p->data); /*递推-在p右
子树中删除与p键值相同的结点,返回后建立链接*/
}
else { /* p->data.key==item.key并且p指向的将要被删除的替身结点
只有一个或零个子女*/
temp = p; //temp指向替身节点(即被删结点)
if ( p->leftChild == NULL ) / /p下降一层
p = p->rightChild; //只有右子女或零个子女
else
p = p->leftChild; //只有左子女
delete temp; //删除替身结点
}
return p; //base case 2:删除成功,不递推,返回2: ?
}
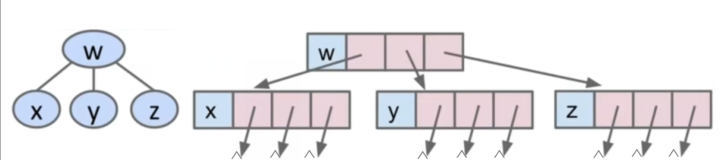
四、B-树
1、定义
设置关键字限制为M,则每个分支结点最多有M-1个关键字
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-oCnjKFCc-1625191541583)(C:\Users\官二的磊子\Desktop\未来村村长\图片\image-20210701204007062.png)]](https://img-blog.csdnimg.cn/20210702100719906.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L2FwcGxlXzUxOTc2MzA3,size_16,color_FFFFFF,t_70)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-nHLzynjz-1625191541584)(C:\Users\官二的磊子\Desktop\未来村村长\图片\image-20210701204020375.png)]](https://img-blog.csdnimg.cn/20210702100724392.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L2FwcGxlXzUxOTc2MzA3,size_16,color_FFFFFF,t_70)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-myh0DAec-1625191541585)(C:\Users\官二的磊子\Desktop\未来村村长\图片\image-20210701204035918.png)]](https://img-blog.csdnimg.cn/20210702100730200.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L2FwcGxlXzUxOTc2MzA3,size_16,color_FFFFFF,t_70)
-
插入时,不延展,先找到合适的位置合并
-
超出限制上提中间位(或者中间靠前一位)
-
然后分裂,按照上提分为不同区间,每个区间形成一个子树
-
如果根结点满,继续上提,形成新的根结点
通过在中间分裂结点,我们可以保持完美的平衡!这些树被称为B树(M>2)或2-3-4/2-3树。
2、不变式
- 所有的叶子必须与根保持相同的距离。
- 具有k项的非叶结点必须正好有k+1个子结点。
3、性能分析
B树中搜索的最坏运行时间情况是,如果每个结点中的元素数最大,我们必须一直遍历到底部。使用M来表示每个结点中子树的数量,L=M-1表示每个结点中元素的数量。这意味着将需要探索logn结点。并且在每个结点上,将需要探索L个元素。总之,我们需要运行Llogn操作。但是,M、L是一个常量,所以我们的总运行时间是O(logn)。
BST具有最佳高度O(logn)和最坏情况下的高度O(n)
B树是BST的一种改进,它避免了O(n) 最坏的情况
B树有完美的平衡。操作的运行时间是O(logn)。
4、b树的性质
b树的查找类似于二叉排序树,只不过分区更多,但是小左大右依然实用。
规定:
- m叉查找树中,除了根节点以外,任何结点至少有m/2个分叉,即至少有m/2-1个关键字
- 对于任何一个结点,其所有子树的高度都要相同
- 若根结点不是终端节点,则其至少有两棵子树,根结点关键字个数大于1而小于m-1
- 所有叶子结点都出现在同一层次,并且不带信息
- 每个中断结点中的关键字有序递增,其k1,k2区间的子树必大于k1而小于k2
- 最小高度(让结点尽可能的满),n≤(m-1)(1+m+m2+…+mh-1),h≥logm(n+1)
- 最大高度:h≤log(m-2)[n+1]/2+1
5、b树的插入
当关键字超出m-1时,进行分裂,取m/2(向上取整)处关键字上提,分割区间。
新元素插入,一定是到达底层的终端结点,通过分裂上提确定位置,上提如果超出双亲结点的m-1范围,双亲继续上提分裂
核心:
- 保证每个结点的关键字个数[m/2]-1≤n≤m-1
- 子树0<关键字1<子树1<关键字2<子树2<…
- 新元素一定是插入在底层的终端结点
- 对于任何一个结点,所有子树的高度都要相同
6、b树的删除
- 若被删除结点为终端结点,直接删除,注意关键字个数不能低于下限[m/2]-1。
- 删除为非终端结点,则用直接前驱或者直接后继取替代被删除的关键字(左子树的最右下或右子树的最左下),然后删除所替代的直接前驱结点或直接后继结点,这样就转换为删除终端节点。
- 若删除后,关键字的下限低于[m/2]-1:
- 右兄弟多:向右兄弟借,首先把父亲拉下来,然后把兄弟提上去。即将父结点中的最左关键字下移,然后提上右兄弟节点中最左关键字,这是为了符合分割区间的性质。
- 左兄弟多:向左兄弟借,即将父结点中的最左关键字下移,然后提上左兄弟中最右关键字。
- 左右兄弟都不够,则选择合体,拉父结点最左关键字下马,和右(左)兄弟合体,若导致父结点不满住特性,继续合体。
五、红黑树
1、BST树的旋转
BST的旋转操作的定义是:
- 左旋转rotateLeft(G):设x是G的右孩子,使G成为x的新左孩子。
- 右旋转rotateRight(G):设x是G的左孩子,使G成为x的新右孩子。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-KP5GRG6c-1625191541586)(C:\Users\官二的磊子\Desktop\未来村村长\图片\image-20210701205223567.png)]](https://img-blog.csdnimg.cn/20210702100741424.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L2FwcGxlXzUxOTc2MzA3,size_16,color_FFFFFF,t_70)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-TZyDga3x-1625191541586)(C:\Users\官二的磊子\Desktop\未来村村长\图片\image-20210701205233729.png)]](https://img-blog.csdnimg.cn/20210702100746176.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L2FwcGxlXzUxOTc2MzA3,size_16,color_FFFFFF,t_70)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Iapmk6PK-1625191541587)(C:\Users\官二的磊子\Desktop\未来村村长\图片\image-20210701205308581.png)]](https://img-blog.csdnimg.cn/20210702100750654.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L2FwcGxlXzUxOTc2MzA3,size_16,color_FFFFFF,t_70)
// 使右倾链接向左倾斜
Node* rotateLeft(Node* h) {
// 假设h != NULL && isRed(h->leftChild);
Node *x = h->rightChild;
h->rightChild = x->leftChild;
x->leftChild = h;
return x;
}//O(1)
//使左倾链接向右倾斜
Node* rotateRight(Node* h) {
// 假设h != NULL && isRed(h->rightChild);
Node *x = h->leftChild;
h->leftChild = x->rightChild;
x->rightChild = h;
return x;
}//O(1)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-4PIIgiCU-1625191541588)(C:\Users\官二的磊子\Desktop\未来村村长\图片\image-20210701205702885.png)]](https://img-blog.csdnimg.cn/2021070210075673.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L2FwcGxlXzUxOTc2MzA3,size_16,color_FFFFFF,t_70)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-kelm1NXA-1625191541589)(C:\Users\官二的磊子\Desktop\未来村村长\图片\image-20210701205839056.png)]](https://img-blog.csdnimg.cn/20210702100806454.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L2FwcGxlXzUxOTc2MzA3,size_16,color_FFFFFF,t_70)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-REYQOPtw-1625191541590)(C:\Users\官二的磊子\Desktop\未来村村长\图片\image-20210701205804522.png)]](https://img-blog.csdnimg.cn/20210702100811619.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L2FwcGxlXzUxOTc2MzA3,size_16,color_FFFFFF,t_70)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-aS6PWWFD-1625191541591)(C:\Users\官二的磊子\Desktop\未来村村长\图片\image-20210701205820560.png)]](https://img-blog.csdnimg.cn/20210702100818190.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L2FwcGxlXzUxOTc2MzA3,size_16,color_FFFFFF,t_70)
2、红黑树定义
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-c6WMAWeU-1625191541592)(C:\Users\官二的磊子\Desktop\未来村村长\图片\image-20210701205940708.png)]](https://img-blog.csdnimg.cn/20210702100824690.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L2FwcGxlXzUxOTc2MzA3,size_16,color_FFFFFF,t_70)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-sy9RIErE-1625191541592)(C:\Users\官二的磊子\Desktop\未来村村长\图片\image-20210701210007244.png)]](https://img-blog.csdnimg.cn/20210702100828168.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L2FwcGxlXzUxOTc2MzA3,size_16,color_FFFFFF,t_70)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-XeezqCHL-1625191541593)(C:\Users\官二的磊子\Desktop\未来村村长\图片\image-20210701210015555.png)]](https://img-blog.csdnimg.cn/20210702100832476.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L2FwcGxlXzUxOTc2MzA3,size_16,color_FFFFFF,t_70)
我们选择使左元素成为右元素的子元素,这会导致树向左倾斜。我们通过使链接变红来显示它是一个粘合链接,正常链接为黑色。因此,我们称这些结构为左倾红黑树(Left-Leaning Red Black Binary Search Tree,LLRB,我们将在本门课程中使用左倾的树)。
LLRB是正常的BST
- 在LLRB和等价的2-3树之间存在1-1对应关系
- 红色只是一个便利的虚构,红色链接没有什么特别的作用
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-NkkfPCpA-1625191541594)(C:\Users\官二的磊子\Desktop\未来村村长\图片\image-20210702085457953.png)]](https://img-blog.csdnimg.cn/20210702100841619.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L2FwcGxlXzUxOTc2MzA3,size_16,color_FFFFFF,t_70)
3、LLRB树的性质
- 1-1对应一棵2-3树。LLRB与2-3树有1-1对应关系。每棵2-3树都有一棵独特的LLRB对应。
- 没有结点有2个红色链接(有2个红色链接的结点相似于有4个分支的结点,但是2-3树不允许)。
- 没有红色的右链接。
- (黑平衡)从根到叶子的每条路径都有相同数量的黑色链接(因为2-3树根到每个叶的链接数量相同),因此LLRB平衡。
- 高度不超过对应2-3树高度的2倍。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-j5oT4PKX-1625191541594)(C:\Users\官二的磊子\Desktop\未来村村长\图片\image-20210701211944467.png)]](https://img-blog.csdnimg.cn/20210702160112444.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L2FwcGxlXzUxOTc2MzA3,size_16,color_FFFFFF,t_70)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-6S2DBG9H-1625191541595)(C:\Users\官二的磊子\Desktop\未来村村长\图片\image-20210701212045024.png)]](https://img-blog.csdnimg.cn/20210702100854740.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L2FwcGxlXzUxOTc2MzA3,size_16,color_FFFFFF,t_70)
4、分裂临时的4分支结点
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-OS7KgeMM-1625191541596)(C:\Users\官二的磊子\Desktop\未来村村长\图片\image-20210702090137419.png)]](https://img-blog.csdnimg.cn/20210702100903974.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L2FwcGxlXzUxOTc2MzA3,size_16,color_FFFFFF,t_70)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-vGaVvBVB-1625191541597)(C:\Users\官二的磊子\Desktop\未来村村长\图片\image-20210702090212311.png)]](https://img-blog.csdnimg.cn/20210702100910427.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L2FwcGxlXzUxOTc2MzA3,size_16,color_FFFFFF,t_70)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-L6S2F5fu-1625191541597)(C:\Users\官二的磊子\Desktop\未来村村长\图片\image-20210702090323318.png)]](https://img-blog.csdnimg.cn/20210702100917559.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L2FwcGxlXzUxOTc2MzA3,size_16,color_FFFFFF,t_70)
插入时:使用红色链接
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-xRGj3OZG-1625191541598)(C:\Users\官二的磊子\Desktop\未来村村长\图片\image-20210702091246717.png)]](https://img-blog.csdnimg.cn/20210702100923756.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L2FwcGxlXzUxOTc2MzA3,size_16,color_FFFFFF,t_70)
- 如果有一个右倾的3分支结点,我们违反了”左倾”规定!
- 向左旋转要修复的相应结点
- 如果有两个连续的左链接,我们有个不正确的4节点违规!
- 向右旋转要修复的相应结点
- 如果任何结点有两个红色链接,我们违反了”没有4分支结
点”规定!
- 对结点进行颜色翻转以模拟分裂结点操作
5、级联平衡
插入Z使我们有一个4分支结点
颜色翻转产生一棵无效的树。为什么?下一步怎么做?
我们有一个右倾的3分支结点(B-S结点)我们可以使用:rotateLeft(B)来修复
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ajJjVx6t-1625191541599)(C:\Users\官二的磊子\Desktop\未来村村长\图片\image-20210702091839085.png)]](https://img-blog.csdnimg.cn/20210702100929854.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L2FwcGxlXzUxOTc2MzA3,size_16,color_FFFFFF,t_70)
6、LLRB树运行时间
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-aaqX5wOF-1625191541599)(C:\Users\官二的磊子\Desktop\未来村村长\图片\image-20210702091925194.png)]](https://img-blog.csdnimg.cn/20210702100935630.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L2FwcGxlXzUxOTc2MzA3,size_16,color_FFFFFF,t_70)
Node put(Node *h, Key k, DataType d) {
if (h == null) { h=(Node *)malloc(sizeof(Node));h->data=d;h-
>key=k;h->color=RED); }
int cmp = compareTo(k, h->key);
if (cmp < 0) { h->leftChild = put(h->leftChild, k, d); }
else if (cmp > 0) { h->rightChild = put(h->rightChild, k, d); }
else { h->data = d; }
//三行代码
if (isRed(h->rightChild)&&!isRed(h->leftChild)){h=rotateLeft(h);}
if (isRed(h->leftChild)&&isRed(h->leftChild
->leftChild)){h=rotateRight(h); }
if (isRed(h->leftChild)&&isRed(h->rightChild)){ flipColors(h); }
return h; }
LLRB树容易实现,但是删除很难
六、树的遍历
1、深度优先遍历
① 前序遍历
- 访问根结点;
- 前序遍历左子树;
- 前序遍历右子树。
void Print(DataType item)
//根据应用需要编写相应的访问函数
{ cout<< item; }
void PreOrder(BiTreeNode *t, void (*Visit)(DataType item))
/*前序遍历二叉树t。为了通用性,把访问操作设计成二叉树遍历函数的一
个函数虚参 (*Visit)( ) */
{ if (t ! =NULL) {
Visit(t->data); //访问
PreOrder(t->leftChild, Visit);
PreOrder(t->rightChild, Visit); }
}
//时间复杂度O(n)
② 中序遍历
与前文二叉树的遍历类似
③ 后序遍历
与前文二叉树的遍历类似
2、广度优先遍历
层次遍历(亦称广度优先遍历)
从根结点开始,按从上到下、从左到右的次序进
行遍历。
由于先被访问的结点其下一层结点将先被访问,
因此使用一个队列存放还没有处理子树的根结点地址
(1) 初始化队列
(2) 将根结点指针入队列
(3) 当队列不空时,循环
- 出队列
- 访问原队头元素;
- 将原队头元素的左孩子指针入队列;
- 将原队头元素的右孩子指针入队列;
















 376
376











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











