







模式识别课程实验
在鸢尾花数据集上实现感知器算法和支持向量机算法。
鸢尾花数据集iris包含3类鸢尾花,分别为山鸢尾(Iris-setosa)、杂色鸢尾(Iris-versicolor)和维吉尼亚鸢尾(Iris-virginica),每类各 50 条记录,共 150 条记录,每条记录都包含 4 项特征:花萼长度(sepal length)、花萼宽度(sepal width)、花瓣长度(petal length)、花瓣宽度(petal width)。如下图:
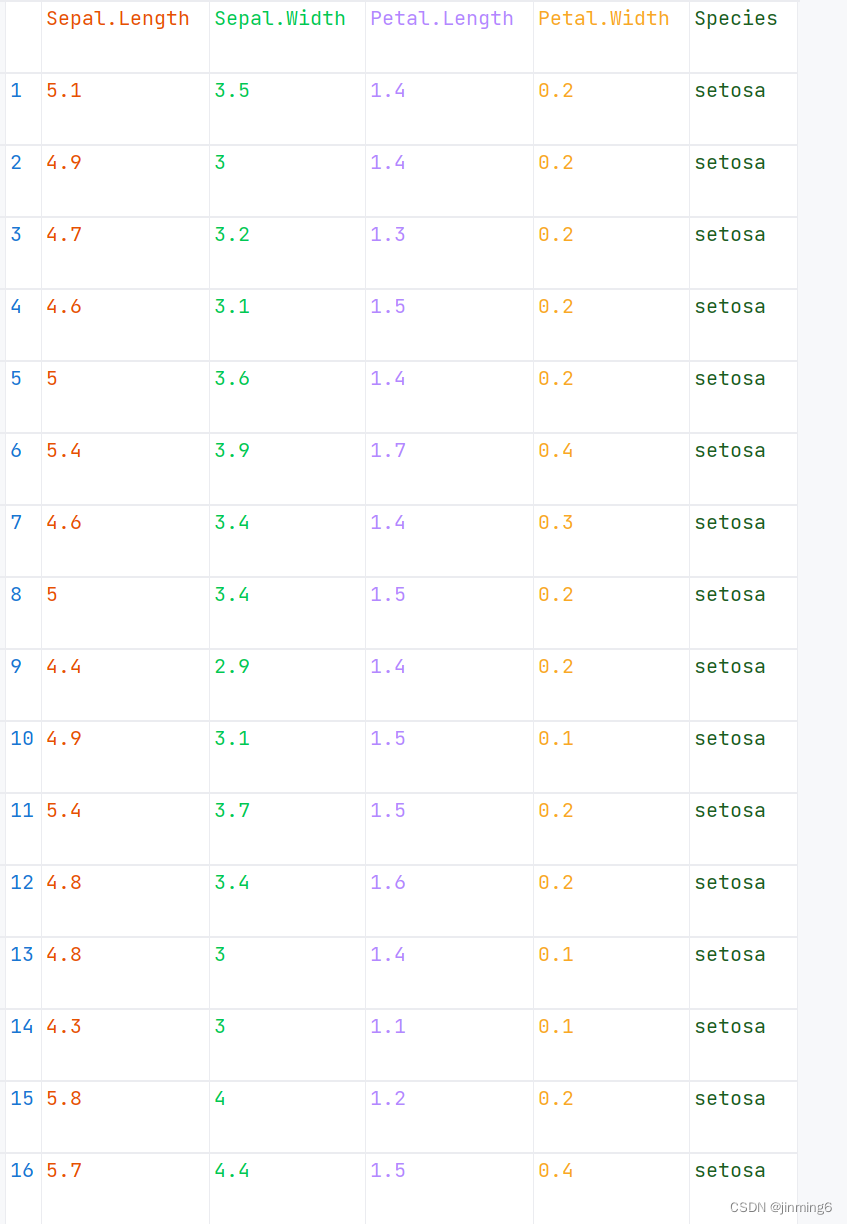
sklearn中datasets中的鸢尾花数据与上图有不同。
读取iris鸢尾花数据集,绘制散点图展示3类鸢尾花。
def show():
print('')
iris = datasets.load_iris()
X = iris.data
y = iris.target #分类标签
tab=["Sepal.Length 萼片长度","Sepal.Width 萼片宽度","Petal.Length 花瓣长度","Petal.Width 花瓣宽度"]
for i in range(4):
for j in range(i+1,4):#两个循环实现在4个维度上选择2个来绘图
print('绘制', tab[i], '与', tab[j], '数据的图像')
x0 = X[y == 0, i:i + 1]
x1 = X[y == 1, i:i + 1]
x2 = X[y == 2, i:i + 1]
y0 = X[y == 0, j:j + 1]
y1 = X[y == 1, j:j + 1]
y2 = X[y == 2, j:j + 1]
# 表示绘制图形的画板尺寸为8*5
plt.figure(figsize=(8, 5))
# 散点图的x坐标、y坐标、标签
plt.scatter(x0, y0, label='Iris-setosa 山鸢尾')
plt.scatter(x1, y1, label='Iris-versicolor 杂色鸢尾')
plt.scatter(x2, y2, label='Iris-virginica 维吉尼亚鸢尾')
plt.xlabel(str(tab[i]) + '/cm')
plt.ylabel(str(tab[j]) + '/cm')
# 添加标题 '鸢尾花萼片的长度与宽度的散点分布'
title = '鸢尾花数据的散点分布'
plt.title(str(title))
# 显示标签
plt.legend()
plt.show()
print('**图片绘制结束**')结果展示:
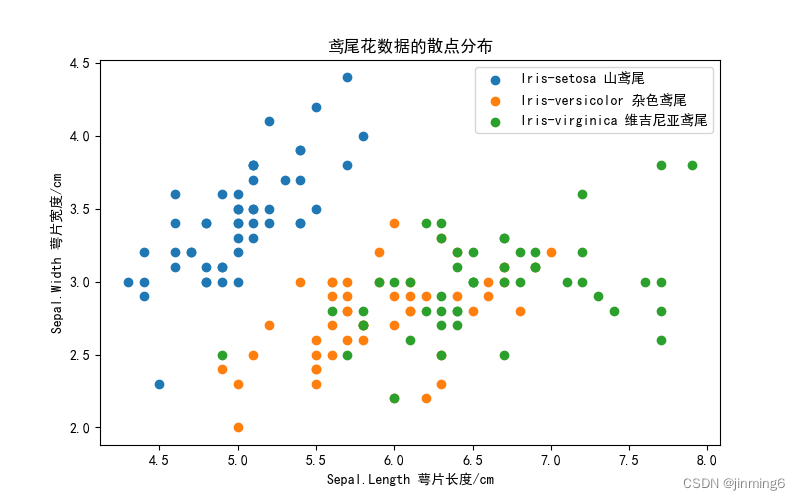
像是这样的图片,有6张。
使用感知器算法区分山鸢尾和维吉尼亚鸢尾
def PLA(max_iter=2000,step=0.1,w=[1,-1],w_0=5,print_data=1):#迭代次数,步长,初始权重,初始偏置,显示模式
#max_iter 最多迭代max_iter次
#step 步长
w=np.mat(w) #初始权重
w_0=np.mat(w_0) #偏置
#print_data控制输出 0-不输出 1-少输出 2-多输出
if print_data==0:#p1 p2 控制显示的等级
p1=p2=False
elif print_data==1:
p1=True
p2=False
elif print_data==2:
p1=p2=True
a=np.bmat('w_0 w')
#input data
iris = datasets.load_iris()
X = iris.data
y = iris.target # 目标
# 舍弃y==1的部分(不要第二个分类)
XX = X[y != 1,:]
# 舍弃y==1的部分
y = y[y != 1]
tab = y
for i in [0,2]:
if i==0:
xlabel = '花萼长度'
ylabel = '花萼宽度'
if i==2:
xlabel = '花瓣长度'
ylabel = '花瓣宽度'
#花萼长度和花萼宽度
#只要前两项数据(萼片数据)
X = XX[:, i:i+2]
#转换
x = np.mat(X)
#初始化
r1=np.mat('1')
y_n=[]
for ii in range(len(tab)):
r2 = x[ii]
y_i=np.bmat('r1 r2')
if tab[ii]==2:
y_i=y_i*-1
#print('y',ii,'=',y_i)#完成计算
y_n.append(y_i)#存储
#更改格式为matrix
y=np.bmat(y_n[0])
for ii in range(1,len(y_n)):
r2=y_n[ii]
y=np.bmat('y;r2')
#迭代
tiaos=0
for iter_num in range(max_iter):
if p1:print('第',iter_num+1,'轮:')
true_num = 1 #统计是否全部分类成功
for ii in range(len(tab)):
yy=np.dot(a,y[ii].T)
if p2:print('y',ii+1,'=',yy)
if yy>0:
if p2:print('分类正确')
true_num=true_num*1
elif yy==0:
if p2:print('=0!')
true_num=true_num*1
else:
if p2:print('分类错误,更新参数')
a=a+step*y[ii]
if p2:print('a=',a)
true_num=true_num*0
if true_num==1: #全部分类成功
if p1:print('全部分类成功')
break
if p1:print('如果没有显示‘全部分类成功’则迭代超过上限')
#绘图
x=np.array(x)
x0=[]
y0=[]
x1=[]
y1=[]
for ii in range(len(tab)):
if tab[ii]==0:
x0.append(x[ii][0])
y0.append(x[ii][1])
elif tab[ii]==2:
x1.append(x[ii][0])
y1.append(x[ii][1])
# 表示绘制图形的画板尺寸为8*5
plt.figure(figsize=(8, 5))
# 散点图的x坐标、y坐标、标签
plt.scatter(x0, y0, label='山鸢尾')
plt.scatter(x1, y1, label='维吉尼亚鸢尾')
#分类线
a = np.array(a)
a=a[0]
if a[1]!=0 and a[2]!=0:
max_plot=max(max(x0),max(x1))
min_plot=min(min(x0),min(x1))
plot_x1=min_plot
plot_x2=max_plot
plot_y1=(-a[0]-a[1]*plot_x1)/a[2]
#print(plot_y1)
plot_y2=(-a[0]-a[1]*plot_x2)/a[2]
#print(plot_y2)
plt.plot([plot_x1, plot_x2], [plot_y1, plot_y2], color='r')
plt.xlabel(xlabel)
plt.ylabel(ylabel)
# 添加标题
title = '感知器算法区分山鸢尾和维吉尼亚鸢尾'
plt.title(str(title))
# 显示标签
plt.legend()
plt.show()结果展示:

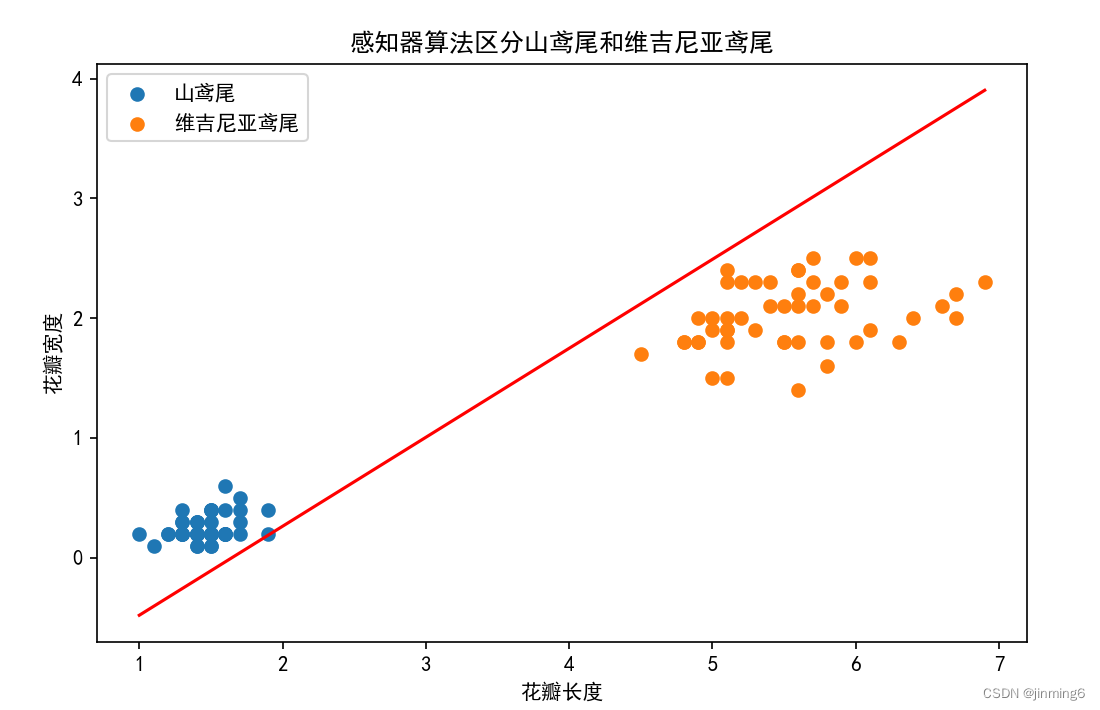
注:分类平面受到参数影响,可能与示例图片不同。
基于花萼长度和花萼宽度两个特征用线性SVM算法区分山鸢尾和维吉尼亚鸢尾
def SVM1():
print('基于花萼长度和花萼宽度两个特征用线性SVM算法区分山鸢尾和维吉尼亚鸢尾。')
iris = datasets.load_iris()
X = iris.data
y = iris.target#目标
#舍弃y==0的部分(不要第2个分类),并且只要前两项数据(萼片数据)
X = X[y != 1, :2]
#舍弃y==0的部分(不要第2个分类)
y = y[y != 1]
n_sample = len(X)
#print('样本数量:',n_sample)
#这里先绘制图像
plt.figure(figsize=(8, 5))
x0 = X[y == 0, 0]
y0 = X[y == 0, 1]
plt.scatter(x0, y0,s=10, label='Iris-setosa 山鸢尾')
x2 = X[y == 2, 0]
y2 = X[y == 2, 1]
plt.scatter(x2, y2,s=10, label='Iris-virginica 维吉尼亚鸢尾')
#随机数种子
np.random.seed(0)
#print(np.random.rand(5))
#产生一个随机序列(不重复,不遗漏0-【n-1】),由于固定了随机数种子,order每次运行都是一样的
order = np.random.permutation(n_sample)
#print(order)
#按照随机序列进行随机排序
X = X[order]
#按照一样的随机序列进行随机排序
y = y[order].astype(float)
#0.9的训练(90)
X_train = X[: int(0.9 * n_sample)]
y_train = y[: int(0.9 * n_sample)]
#测试
X_test = X[int(0.9 * n_sample) :]
#y_test = y[int(0.9 * n_sample) :]
clf = svm.SVC(C = 50,kernel="linear", gamma=20)#错误术语的惩罚参数C , kernel核函数类型 , gamma核函数系数
clf.fit(X_train, y_train)
# Circle out the test data 圈出测试数据none
plt.scatter(
X_test[:, 0], X_test[:, 1], s=30, facecolors="none", zorder=100, edgecolor="k"
)
#绘制超平面
#计算分类面方程,计算划线点
#wx+b=0 , w=[ , ]
b=clf.intercept_
w=clf.coef_
x_max = X[:, 0].max()
x_min = X[:, 0].min()
max_y=(-b-w[0][0]*x_max)/w[0][1]
min_y=(-b-w[0][0]*x_min)/w[0][1]
x=[x_min,x_max]
y=[min_y,max_y]
plt.plot(x,y,'-r')
plt.title('线性SVM算法区分山鸢尾和维吉尼亚鸢尾')
plt.xlabel('花萼长度(sepal length)')
plt.ylabel('花萼宽度(sepal width)')
plt.legend()
plt.show()结果展示:
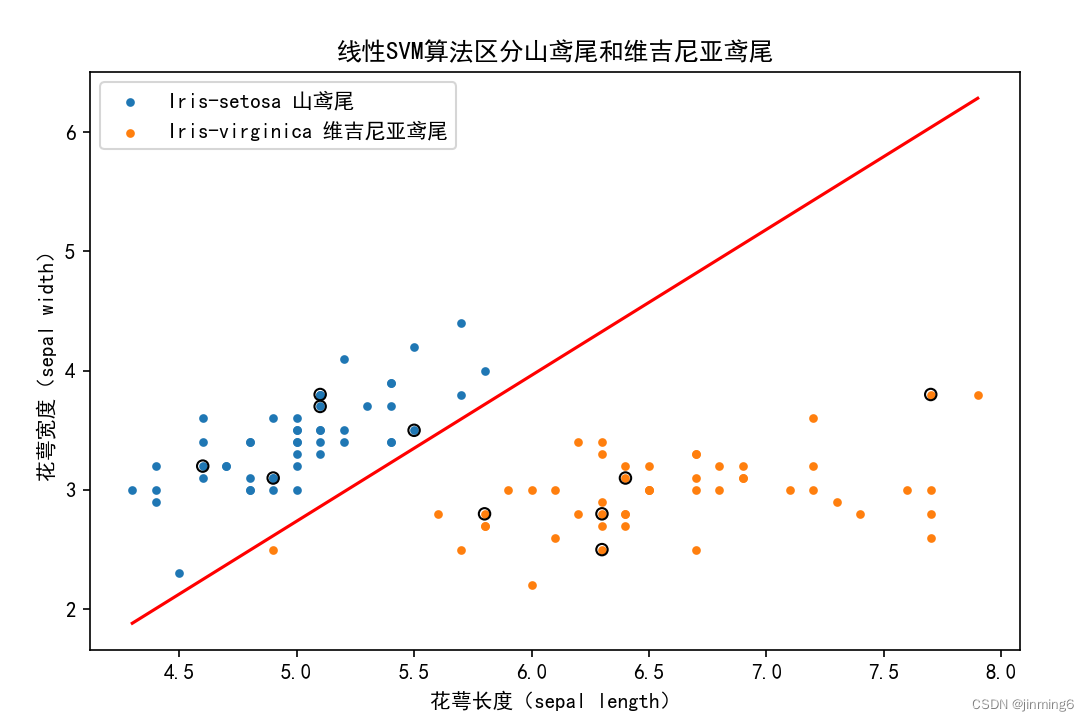
注:超平面受到参数影响,可能与示例图片不同。
基于所有特征用SVM算法区分三类鸢尾花,分别使用线性核、RBF核和Sigmoid核进行分类。
def SVM():
print('基于所有特征用SVM算法区分三类鸢尾花,分别使用线性核、RBF核和Sigmoid核进行分类。')
#导入数据
from sklearn.datasets import load_iris
iris = load_iris()
X = iris.data
#print(X.shape, X)
y = iris.target
#print(y.shape, y)
for kernel in ['linear','rbf','sigmoid']:
#svm
C = 10
gamma = 100
Svm=svm.SVC(kernel=kernel,C=C,gamma=gamma)
#使用全部特征对鸢尾花进行分类
Svm.fit(X[:,:4],y)
#训练得分:
print('\nkernel=',kernel,' C=',C,' gamma=',gamma,':')
print("training score:", Svm.score(X[:, :4], y))
#print("predict: ", Svm.predict([[7, 5, 2, 0.5], [7.5, 4, 7, 2]]))结果展示:

使用到的库:
import numpy as np
import matplotlib.pyplot as plt
...
plt.rcParams["font.sans-serif"] = ["SimHei"]
plt.rcParams['axes.unicode_minus'] = False
#中文支持
...
from sklearn import datasets
from sklearn import svm














 1341
1341











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









