







排序包括内部排序和外部排序。内部排序包括 插入排序,选择排序,交换排序,归并排序,基数排序。插入排序包括直接插入排序和希尔排序,选择排序包括简单选择排序和堆排序,交换排序包括冒泡排序和快速排序。
Straight Insertion sort 直接插入排序
将一个记录插入到已排好的有序表中,从而得到一个新的记录数增1的有序表。即,先将序列的第一个记录看成是一个有序的子序列,然后从第2个记录逐个进行插入,直至整个序列有序为止。
Key: 设立哨兵,作为临时存储和判断数组边界之用。
Example:

当碰到一个和插入元素相等的,插入元素把想插入的元素放在相等元素的后面。插入排序是稳定的。
C++算法实现:
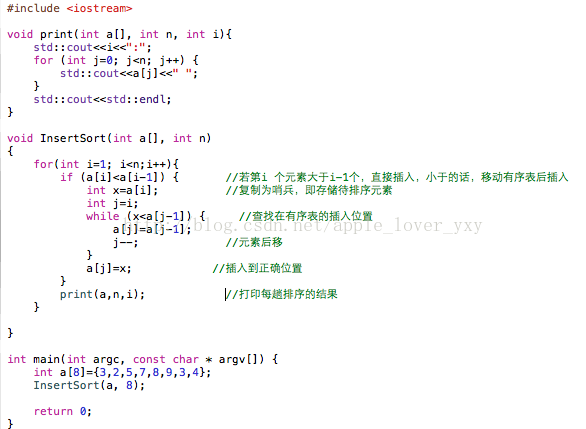
时间复杂度 O(n^2) .
Python 算法实现:
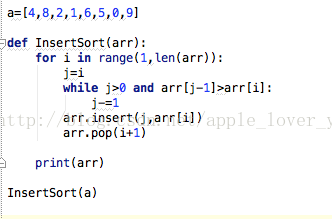
Binary Insertion sort 二分插入排序
先跟序列最中间的那个元素比较,如果比最中间的这个元素小,则插入位置在它的左边,否则在它的右边。
以当前最中间位置为分割点,如果在左边,则当前最中间位置是待搜索子序列的终点,如果在右边,右边邻接的元素将是待搜索子序列的起点。按照这种原则继续寻找下一个中间位置,并继续这种过程,直到找到合适的插入位置为止。
最坏的情况下二分插入排序的时间复杂度依然是 O(n^2)。如果待排序的序列已经有序,排序时间复杂度为O(nlogn)。
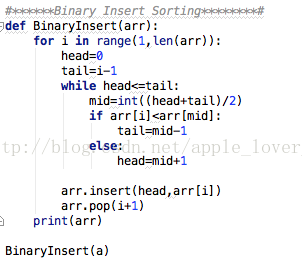
C++算法实现:

Python 算法实现:
Shell sort 希尔排序
相对直接排序有较大改进。希尔排序又叫缩小增量排序。
先将整个待排序的记录分割成为若干子序列分别进行直接插入排序,待整个序列中的记录“基本有序”时,再对全体记录进行依次直接插入排序。
操作方法:
1. 选择一个增量序列 t1, t2, .., tk, 其中 ti>tj, tk=1;
2. 按增量序列个数k, 对序列进行k趟排序;
3. 每趟排序,根据对应的增量ti,将待排序列分割成若干长度为m 的子序列,分别对各子表进行直接插入排序。仅增量因子为1时,整个序列作为一个表来处理,表长度即为整个序列的长度。
C++算法实现:

Python 算法实现:

希尔排序时效分析较难,比较次数与记录移动次数依赖于增量因子序列 gap 的选取,特定情况下可以准确估算出关键码的比较次数和记录的移动次数。是一个不稳定的排序方法。
Selection sort 选择排序
在要排序的一组数中,选出最小(或者最大)的一个数与第1个位置的数交换;然后在剩下的数当中再找最小 (或者最大) 的与第2个位置的数交换,依次类推,直到第n-1个元素(倒数第二个数) 和第n个元素(最后一个数)比较为止。
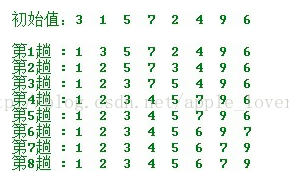
操作方法:
第一轮,从n个记录中找出关键码最小的记录与第一个记录交换;
第二轮,从第二个记录开始的n-1个记录中再选出关键码最小的记录与第二个记录交换;
第i 轮,从第i 个记录开始的 n-i+1个记录中选出关键码最小的记录与第i 个记录交换;
直到整个序列按关键码有序。
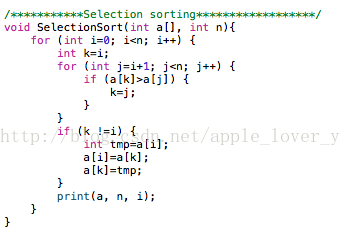
C++算法实现:
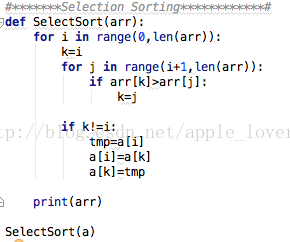
Python算法实现:
Heap sort 堆排序
堆排序是一种树形选择排序,是对直接选择排序的有效改进。
堆的定义:具有n个元素的序列(k1,k2,...,kn),当且仅当满足

时称之为堆。
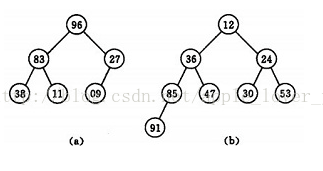
若以一维数组存储一个堆,则堆对应一棵完全二叉树,且所有非叶结点的值均不大于(或不小于)其子女的值,根结点(堆顶元素)的值是最小(或最大)的。如:
(a) 大顶堆序列:(96,83,27,38,11,09)
(b) 小顶堆序列:(12,36,24,85,47,30,53,91)
初始时把要排序的n个数的序列看作是一棵顺序存储的二叉树(一维数组存储二叉树),调整它们的存储序,使之成为一个堆,将堆顶元素输出,得到n个元素中最小(或最大)的元素,这时堆的根节点的数最小(或者最大)。然后对前面(n-1)个元素重新调整使之成为堆,输出堆顶元素,得到n个元素中次小(或此大)的元素。依次类推,直到只有两个节点的堆,并对它们作交换,最后得到有n个节点的有序序列。这个过程为堆排序。
因此,实现堆排序需要解决两个问题:
1. 如何将n个待排序的数建成堆;
2. 输出堆顶元素后,怎样调整剩余n-1个元素,使其成为一个新堆。
输出堆顶元素后,对剩余n-1个元素重新建成堆的调整过程。
调整小顶堆的方法:
1)设有m个元素的堆,输出堆顶元素后,剩下m-1个元素。将堆底元素送入堆顶(最后一个元素与堆顶进行交换),堆被破坏,其原因仅是根结点不满足堆的性质。
2)将根结点与左,右子树中较小元素的进行交换。
3)若与左子树交换:如果左子树堆被破坏,即左子树的根结点不满足堆的性质,则重复方法(2)。
4)若与右子树交换,如果右子树堆被破坏,即右子树的根结点不满足堆的性质,则重复方法(2)。
5)继续对不满足堆性质的子树进行上述交换操作,直到叶子结点,堆被建成。
称这个自根结点到叶子结点的调整过程为筛选。
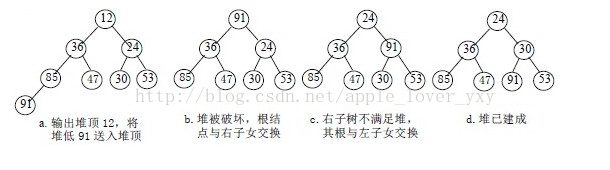
对n个元素初始建堆的过程。
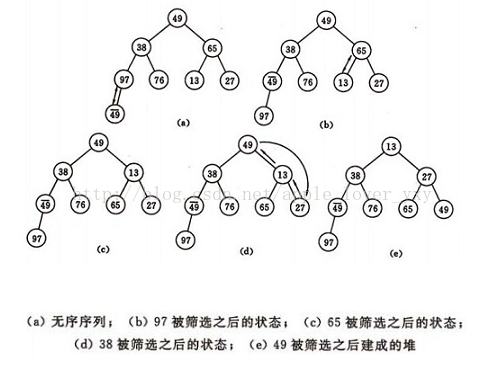
建堆方法:对初始序列建堆的过程,就是一个反复进行筛选的过程。
1)n个结点的完全二叉树,则最后一个结点是第[n/2] 个结点的子树。
2)筛选从第[n/2]个结点为根的子树开始,该子树成为堆。
3) 之后向前依次对各结点为根的子树进行筛选,使之成为堆,直到根结点。
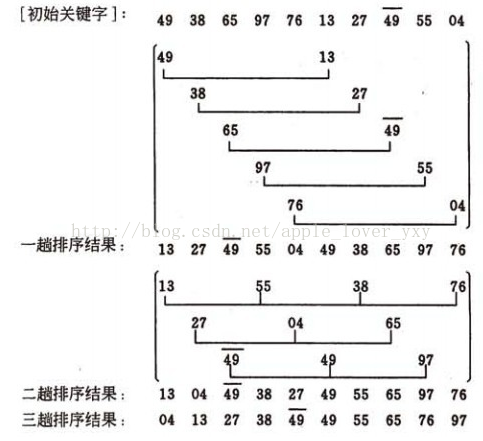
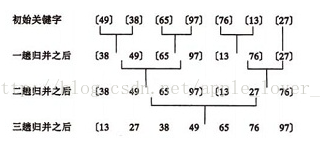
如图建堆初始过程:无序序列:(49, 38, 65, 97,76, 13, 27, 49)
算法实现:从算法描述来看,堆排序需要两个过程,一是建立堆,二是堆顶与堆的最后一个元素交换位置。所以堆排序有两个函数组成。一是建堆的渗透函数,二是反复调用渗透函数实现排序的函数。
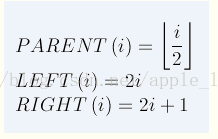
C++算法实现:
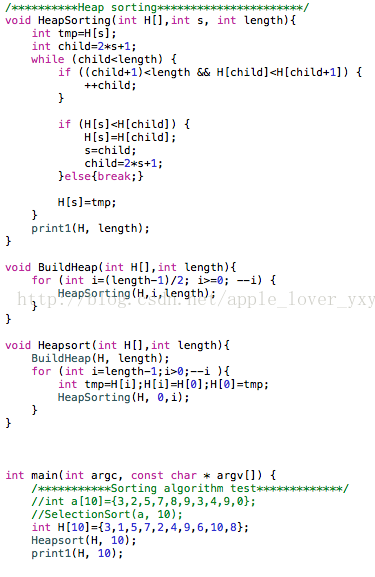
Python 算法实现:

设树的深度为k,k=[log2n]+1,从根到叶的筛选,元素比较次数至多2(k-1)次,交换记录至多k次。所以,在建好堆后,排序过程中的筛选次数不超过下式:
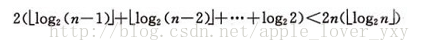
而建堆时的比较次数不超过4n次,因此堆排序最坏情况下,时间复杂度也为:O(nlogn)。
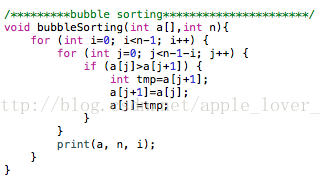
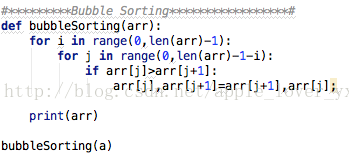
Bubble sort 冒泡排序
在要排序的一组数中,对当前还未排好序的范围内的全部数,自上而下对相邻的两个数依次进行比较和调整,让较大的数往下沉,较小的往上冒。即:每当两相邻的数比较后发现它们的排序与排序要求相反时,就将它们互换。
C++算法实现:
Python算法实现:
Quick sort 快速排序
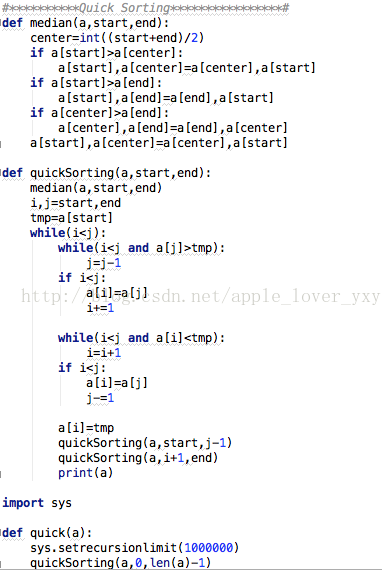
基本思想:
1)选择一个基准元素,通常选择第一个元素或者最后一个元素
2)通过一趟排序讲待排序的记录分割成独立的两部分,其中一部分记录的元素值均比基准元素值小。另一部分记录的元素值比基准值大。
3)此时基准元素在其排好序后的正确位置
4)然后分别对这两部分记录用同样的方法继续进行排序,直到整个序列有序。
排序过程:

C++算法实现:

Python算法实现:
快速排序通常被认为在同数量级 (O(nlog2n))的排序方法中平均性能最好。快速排序是一个不稳定的排序方法。
Merge sort 归并排序
归并排序法是将两个(或两个以上) 有序表合并成一个新的有序表,即把待排序序列分为若干个子序列,每个子序列是有序的。然后再把有序子序列合并为整体有序序列。
合并方法:
设r[i...n]由两个有序子表r[i,...m]和r[m+1...n]组成,两个子表长度分别为m-i+1和n-m。
1. j=m+1; k=i; i=i; //置两个子表的起始下标及辅助数组的起始下标
2. 若i>m 或 j>n,转(4) //其中一个子表已合并完,比较选取结束
3. //选取r[i]和r[j] 较小的存入辅助数组rf
如果r[i]<r[j],rf[k]=r[i]; i++; k++; 转(2)
否则,rf[k]=r[j];j++; k++;转(2)
4,//将尚未处理完的子表中元素存入rf
如果i<=m,将r[i...m]存入rf[k...n] //前一子表非空
如果j<=n,将r[j...n]存入rf[k...n] //后一子表非空
5. 合并结束
1个元素的表总是有序的。所以对n个元素的待排序列,每个元素可以看成1个有序子表。对子表两两合并生成n/2个子表,所得子表除最后一个子表长度可能为1外,其余子表长度均为2。再进行两两合并,直到生成n个元素按关键码有序的表。
C++ 算法实现:
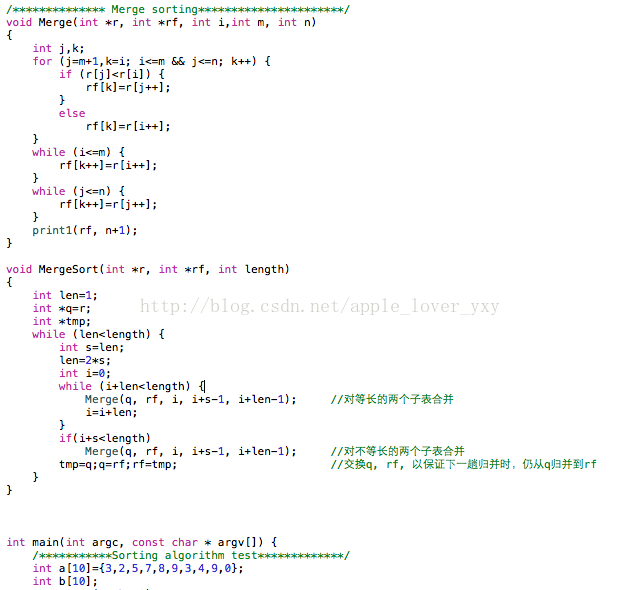
Python 算法实现:
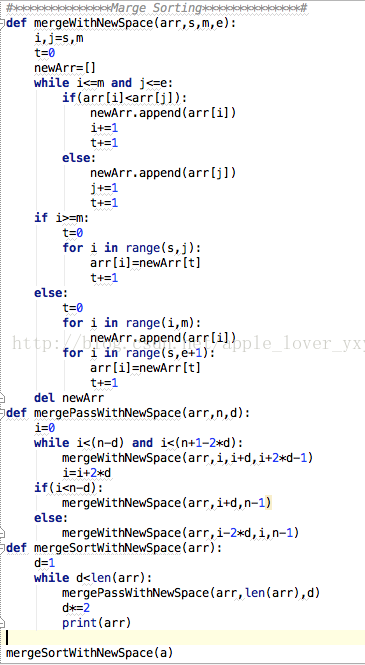
归并排序算法中,在合并两个已排序的表时,通常的做法时新建一个大小等于它们之和的新表,用于存储这两个表合并的结果,然后把合并后的表在拷贝回这两个连续的表中。另外一个做法,也可以不分配新的空间存储结果,而是使用插入排序的思想进行合并。
使用分配空间合并的方式,时间复杂度为O(nlogn),使用插入合并方式,时间复杂度为 O(n^2)。
Radix sort 基数排序
是按照低位先排序,然后收集;再按照高位排序,然后再收集;依次类推,直到最高位。有时候有些属性是有优先级顺序的,先按低优先级排序,再按高优先级排序。最后的次序就是高优先级高的在前,高优先级相同的低优先级高的在前。基数排序基于分别排序,分别收集,所以是稳定的。

C++算法实现:

算法时间复杂度计算:
1. 计算出基本操作的执行次数 T(n)
基本操作即算法中的每条语句(以;为分割),语句的执行次数也叫做语句的频度。在做算法分析时,一般默认为考虑最坏的情况。
2. 计算出T(n) 的数量级
求T(n) 的数量级,只要将T(n) 进行如下操作:
忽略常量,低次幂和最高次幂的系数,令 f(n)=T(n)的数量级。
3. 用大O来表示时间复杂度
当n趋近无穷大时,如果lim(T(n)/f(n))的值为不等于0的常数,则称f(n)是T(n)的同数量级函数。记作 T(n)=O(f(n))。

简化步骤:
1. 找到执行次数最多的语句
2. 计算语句执行次数的数量级
3. 用大O来表示结果

复杂度为 c, log2n, n, n*log2n, 这个算法时间效率比较高,如果是 2n, 3n, n! 会很差。














 8万+
8万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









