







本篇,我将分为两个章节来讲一下,什么是Python 的序列化,以及Python的序列化在不同语言之间的应用(第二篇将会讲到),当然,有正就有负,有左就要有右,有上就要有下,等等,事物的存在都是有两面性的,因此,讲Python的序列化的时候,就不得不讲到反序列化,如果将这两个概念比喻成行为的话,那么就相当于一个在包装,一个在分解。
序列化
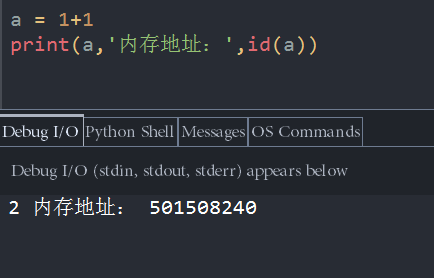
我们举个简单的例子,就拿1+1来说吧,看下如下代码
#!/usr/bin/env Python3
# -*- coding:utf-8 -*-
a = 1+1
print(a)a的结果显然等于2,且这个结果属于运行时才计算出来的,存放在了a对应的内存地址中。
我们一旦程序结束,就访问不到这个a变量了(假设,我们希望a的值是永驻内存的,因此我们试图直接从内存中调出a变量的值)
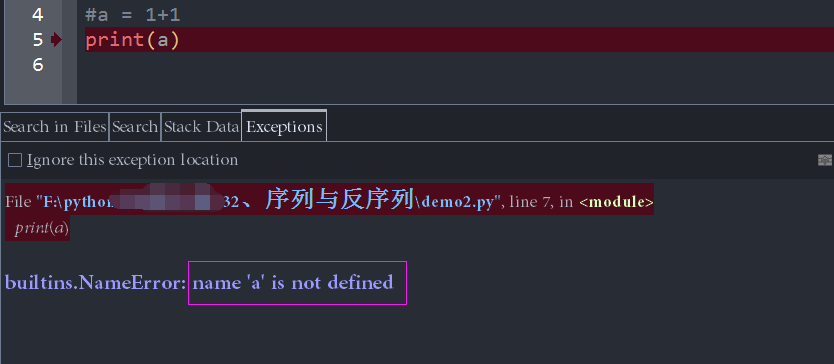
其实我们就是想再看一下1+1的结果,可是,内存中好像并没有这个结果,我们以为a还在内存中,但是,内存毕竟有限,不可能你不用的时候,还给你留一块house,专门供a这个变量长住,如果这样的话,内存会被耗死。因此,我们的程序一旦结束,内存就会把a这个变量有关的一切,全部清掉(记忆抹除),如果,我们想要再次看到1+1的结果,就得在内存中重新分配a的地址,重新计算,重新赋值。有没有其他的办法,可以让1+1的结果,一次运行,处处调用,且不再考虑内存地址的重新分配呢?
这个时候,我们就需要借助序列化这个概念,将变量或对象通过序列化,转化成字节流(bytes)存储到文件中(磁盘)或者通过网络传输到需要的机器上。
因此,我们把变量或对象从内存中变成可存储或传输的过程称之为序列化
在Python中,有两种提供序列化的模块,一个是pickle,一个是json,前者,序列化变量或对象成字节流,但却是Python独有的模块,序列化后的字节流,无法和其他语言进行交互(第二篇的时候,会和Java做个交互,验证一下,而且这也是其他编程语言特有的序列化问题,而且,如果Python版本不一致,也有可能出现序列化和反序列化互不兼容的情况发生),后者,可将对象序列化成网络中标准的数据传输格式---->json串,这是一个轻量级的数据交互格式,相对于XML来说,简洁且高效。
序列化之 ---- pickle模块
序列化
dumps : 直接将变量或对象序列化成bytes,可以用print打印内容
下面,我们就来实际操作一下,实现变量或对象的序列化和反序列化,两种模式+两种方式:
A、文件模式 dump 和 load 的组合
序列化对象的内容,并写入文件
pickling.py
#!/usr/bin/env Python3
# -*- coding:utf-8 -*-
import pickle
d = {'name':'appleyk','sex':'男','age':26}
with open('info.txt','wb') as f:
pickle.dump(d,f)

一堆乱码,完全看不懂!反序列化文件info.txt里面的bytes为dict对象,并打印集合内容,还原真相
unpickling.py
#!/usr/bin/env Python3
# -*- coding:utf-8 -*-
import pickle
#d = {'name':'appleyk','sex':'男','age':26}
#with open('info.txt','wb') as f:
#pickle.dump(d,f)
with open('info.txt','rb') as f:
d = pickle.load(f)
print(d)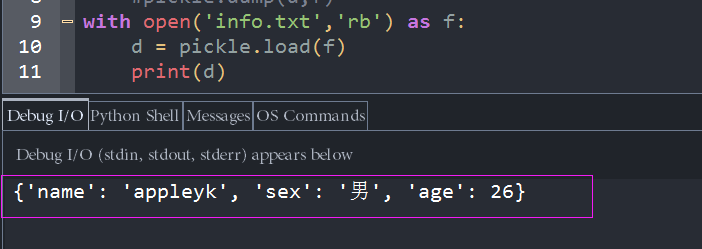
B、传输模式 dumps 和 loads 的组合
(1)本地反序列化
#!/usr/bin/env Python3
# -*- coding:utf-8 -*-
import pickle
a = 1+1
byte = pickle.dumps(a) #序列化a的结果 --->字节流
print(byte)
result = pickle.loads(byte) #反序列化字节流 --->a的结果
print(result)
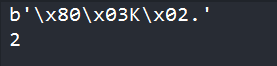
注意,变量result和之前的变量a是两个毫不相干的对象,但是,他们的内容都是一样的,结果都是2
(2)网络传输反序列化(仅限Python语言,关于和Java语言的交互,放在下一篇说明)
服务端server.py
#!/usr/bin/env Python3
# -*- coding:utf-8 -*-
import socket ,pickle
serSock = socket.socket(socket.AF_INET,socket.SOCK_STREAM)
serSock.bind(('192.168.1.54',9999))
serSock.listen(5)
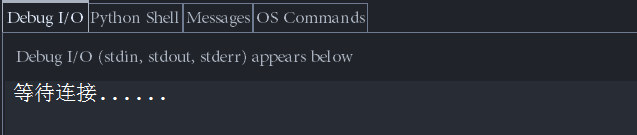
print('等待连接......')
s,addr = serSock.accept()
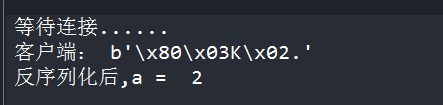
result = s.recv(1024) #来至于客户端的 消息
print('客户端:',result)
a = pickle.loads(result) #反序列化
print('反序列化后,a = ',a)
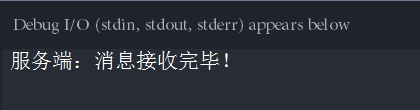
s.send(bytes('服务端:消息接收完毕!',encoding='utf-8'))
serSock.close; #最后别忘关了套接字对象,关闭资源
启动服务端
#!/usr/bin/env Python3
# -*- coding:utf-8 -*-
import pickle,socket
a = 1+1
byte = pickle.dumps(a) #序列化a的结果 --->字节流
s = socket.socket(socket.AF_INET,socket.SOCK_STREAM)
s.connect(('192.168.1.54 ',9999))
s.send(byte)
print(s.recv(1024).decode('utf-8'))
s.close()
服务端:
客户端:
关于套接字,我们依然在本篇中略过,因为,网络socket通信,涉及多线程,因此,我们统一放在后续的连载博文中再讲!
当然,这个是针对变量序列化的,我们也可以针对对象,进行序列化和反序列化,我们快速看下demo和效果演示
服务端 server.py
#!/usr/bin/env Python3
# -*- coding:utf-8 -*-
import socket ,pickle
class Student(object): #一定要声明下这个Student类,否则反序列化出对象的时候,找不到类标志
pass
serSock = socket.socket(socket.AF_INET,socket.SOCK_STREAM)
serSock.bind(('192.168.1.54',9999))
serSock.listen(5)
print('等待连接......')
s,addr = serSock.accept()
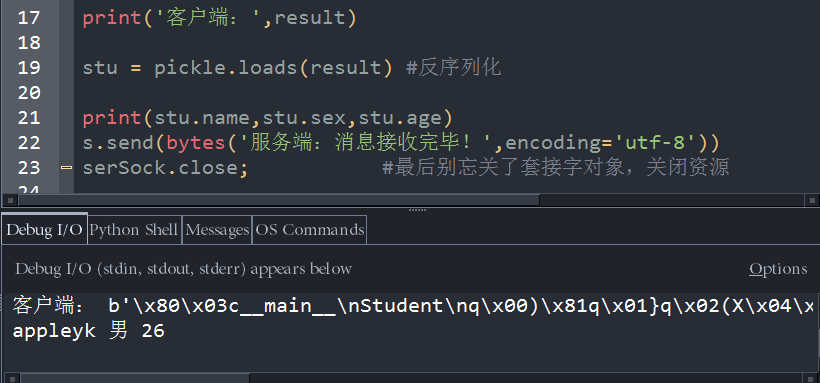
result = s.recv(1024) #来至于客户端的 消息
print('客户端:',result)
stu = pickle.loads(result) #反序列化
print(stu.name,stu.sex,stu.age)
s.send(bytes('服务端:消息接收完毕!',encoding='utf-8'))
serSock.close; #最后别忘关了套接字对象,关闭资源
客户端 client.py
#!/usr/bin/env Python3
# -*- coding:utf-8 -*-
import pickle,socket
class Student(object):
def __init__(self,name,sex,age):
self.name = name
self.age = age
self.sex = sex
def show(self):
print(self.name,self.sex,self.age)
s = Student('appleyk','男',26)
byte = pickle.dumps(s) #序列化实例s --->字节流
stu = pickle.loads(byte)
stu.show() #注意,方法是无法通过传输,进行反序列化的,感兴趣的可以自己验证下
s = socket.socket(socket.AF_INET,socket.SOCK_STREAM)
s.connect(('192.168.1.54 ',9999))
s.send(byte)
print(s.recv(1024).decode('utf-8'))
s.close()
演示效果
服务端
客户端
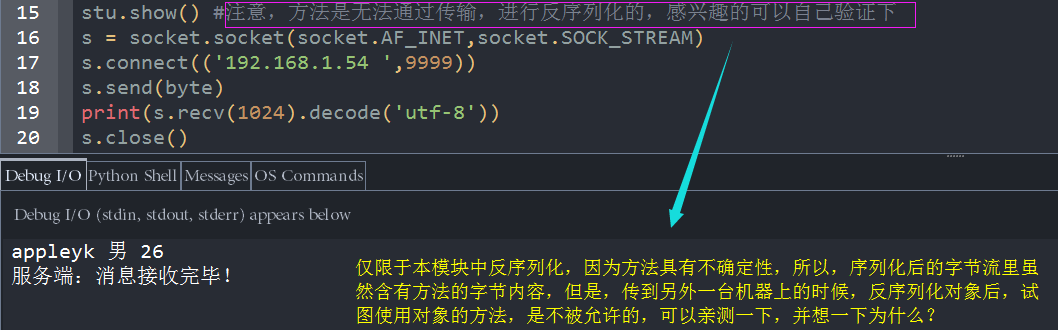
因此,我们在将序列化应用到网络传输的时候,pickle只能保存一些基本数据类型(这就够用了,毕竟我们主要是传数据的,不是传递行为的),因此,如果一些对象中的成员,传输后,无法被成功的反序列化,请不要大惊小怪,毕竟,对象的行为操作,是有域的,如果离开了自身所处的环境,其他地方是无法正常运转的,就好比,淡水中的鱼,我们可以拿来享用,但是,如果,我们把它放在咸水中饲养一段时间后再享用,肯定是不行的!它会挂掉的。
序列化之 ---- json模块
讲之前,我们先来看一下,json数据类型和python数据类型之间的对照关系
JSON 类型 Python 类型
{} dict
[] list
"string" str
1234.56 int 或 float
true/false True/False
null None
#!/usr/bin/env Python3
# -*- coding:utf-8 -*-
import json
d = {'name':'appleyk','sex':'男','age':26}
with open('json.txt','w') as f:
json.dump(d,f)
#!/usr/bin/env Python3
# -*- coding:utf-8 -*-
import json
#d = {'name':'appleyk','sex':'男','age':26}
#with open('json.txt','w') as f:
#json.dump(d,f)
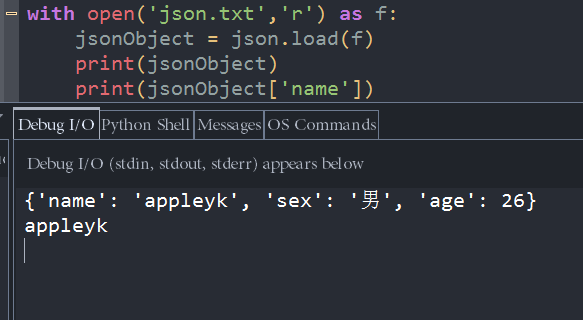
with open('json.txt','r') as f:
jsonObject = json.load(f)
print(jsonObject)
print(jsonObject['name'])
(2)dumps和loads组合
demo.py
#!/usr/bin/env Python3
# -*- coding:utf-8 -*-
import json
d = {'name':'appleyk','sex':'男','age':26}
jstr = json.dumps(d)
print(jstr)
print('-----上面为json的序列化,下面为json的反序列化-----')
jsonObject = json.loads(jstr)
print(jsonObject)

B、序列化int类型(基本数据类型的演示,到此为止,其余类型,都是一个模子里刻出来的)
import json
#d = {'name':'appleyk','sex':'男','age':26}
num = 100
jstr = json.dumps(num)
print(jstr)
print('-----上面为json的序列化,下面为json的反序列化-----')
jsonObject = json.loads(jstr)
print(jsonObject)int还是int,序列化之前和反序列化之后,没什么变化

C、序列化类对象
哎哟,上面我们说过了,json和python的数据类型对照表中,没有涉及到Python类的对象是怎么序列化成json类型的对象的,那么我们用序列化基本数据类型的方法来序列化一个类对象,可行吗?我们看一下
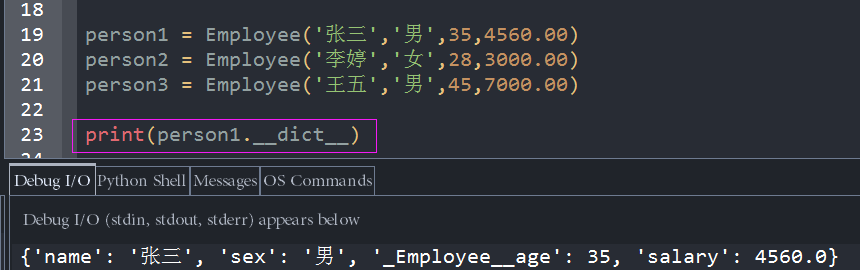
我们先来定义一个类,Employee,员工类,注意,类中有一个成员变量age,它是一个私有private类型,因此,我们需要给私有age变量提供公有属性getter和setter,我们利用之前学过的内置装饰器@property,来完成这一壮举,为什么要定义一个私有的age,目的就是为了区分和对比public和private的成员变量,在默认序列化成json对象的时候的细微不同之处。
Employee类定义如下
#!/usr/bin/env Python3
# -*- coding:utf-8 -*-
import json
class Employee:
def __init__(self,name,sex,age,salary):
self.name = name #姓名
self.sex = sex #性别
self.__age = age #年龄 私有变量
self.salary= salary #薪资 按月算
@property
def age(self): #age的getter属性,还记得装饰器@property的用法吗?
return self.__age
@age.setter
def age(self,value): #age的setter属性
self.__age = value
实例化一个对象person
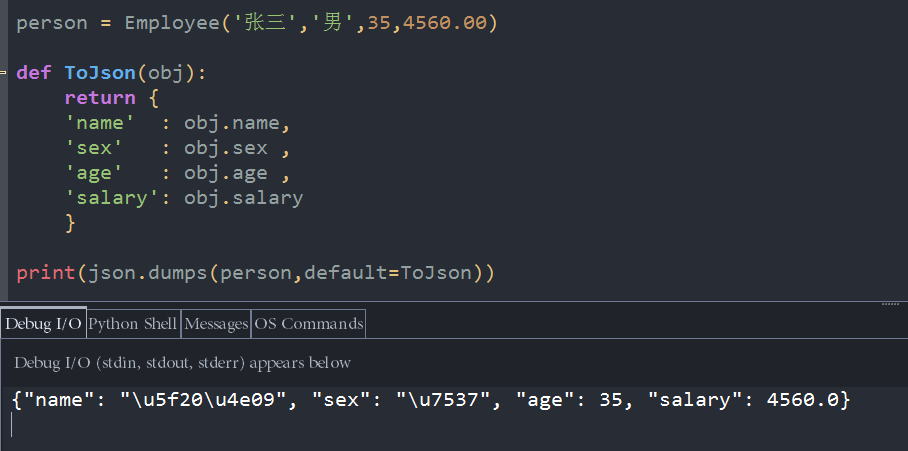
person = Employee('张三','男',35,4560.00)我们利用序列化基本数据类型的方法dumps,来试图,序列化这个person对象,操作如下
print(json.dumps(person))
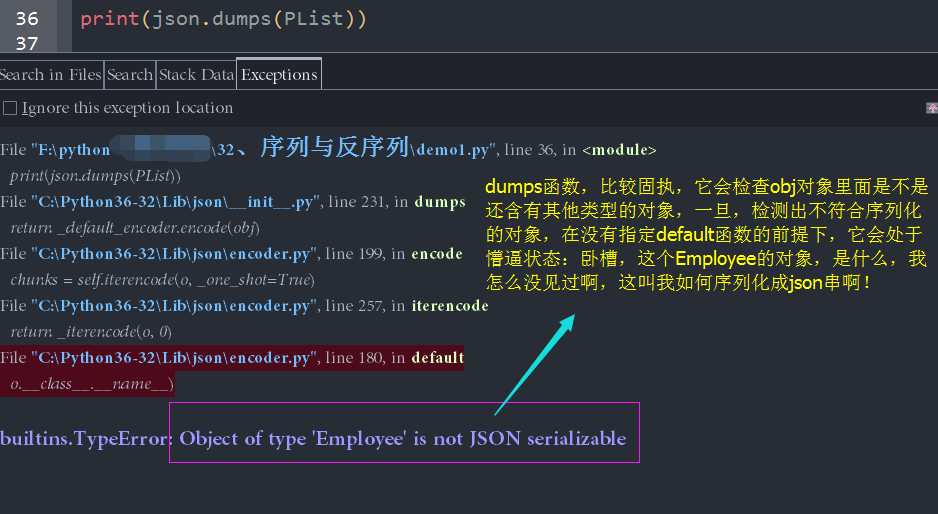
打印结果的时候,IDE抛出了异常,异常信息如下

意思就是,这个类型为Employee的对象,不支持JSON序列化,换句话说,你这个person对象,究竟让我json给你怎么个序列化法呢?你是不是需要指定一种格式(这种格式区分于基本数据类型),告诉json的dumps方法,嘿,伙计,我给你一个person对象,这是参考格式,照着这个给我序列化一下。
这个格式是什么呢?那我们就得借助help函数,来看一下,json.dumps()的信息了
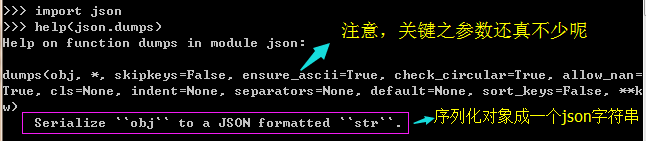
我们发现,虽然dumps函数的参数很多,但是必须的只有一个,那就是第一个参数obj,也就是要序列化的对象,一定要有,其余的参数都可以使用默认值,但是
我们接着往下看(Enter键往下翻),直奔主题
``default(obj)`` is a function that should return a serializable version
of obj or raise TypeError. The default simply raises TypeError.

意思就是,关键字参数default使用默认值(None)的时候,是针对当前对象obj(第一个参数)的,如果当前对象,可以被(支持)序列化,那就返回对象的可序列化版本(比如int就是int,{}就是dict,true就是True),另一种就是,不支持的时候,就会抛出TypeError的异常,所以,我们看到的builtins.TypeError: Object of type 'Employee' is not JSON serializable这句异常信息,实际上就是这个default引起的,我们既然没有类的对象对应的json序列化版本,那我们就去创造一个,它不是说了嘛,a function that that should return a serializable version of obj,那我们就为default指定一个函数:
function of ToJson
def ToJson(obj):
return {
'name' : obj.name,
'sex' : obj.sex ,
'age' : obj.age ,
'salary': obj.salary
}
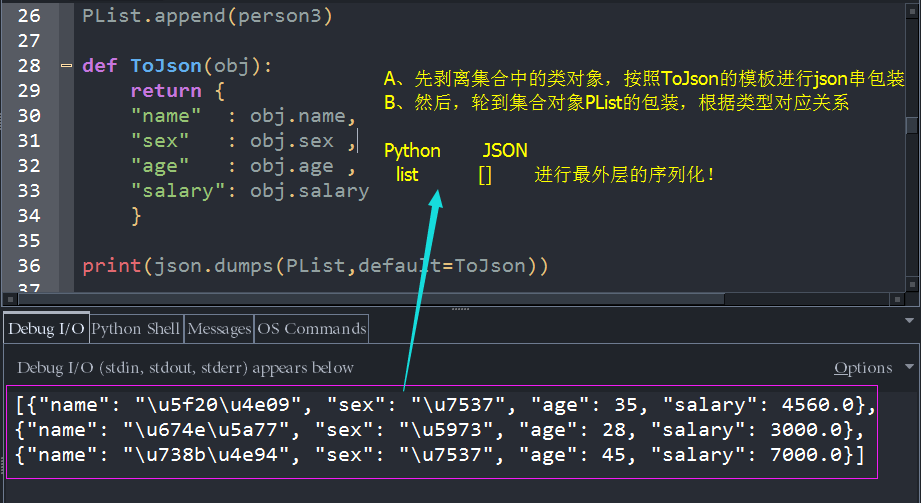
print(json.dumps(person,default=ToJson)) 这样一来,函数dumps在序列化对象person的时候,就会按照ToJson函数的模板去构造属于person对象的json串,不相信吗,我们看一下执行结果好吧:
如果我们构造了三个Employee的实例怎么办,别慌,我们最开始不是说了json和python的基本数据类型对应关系吗,Pyhton的list集合对应json的[](数组),那我们就用Python的list来存放这三个实例,然后,将list作为要序列化的obj
person1 = Employee('张三','男',35,4560.00)
person2 = Employee('李婷','女',28,3000.00)
person3 = Employee('王五','男',45,7000.00)
PList = []
PList.append(person1)
PList.append(person2)
PList.append(person3)
def ToJson(obj):
return {
"name" : obj.name,
"sex" : obj.sex ,
"age" : obj.age ,
"salary": obj.salary
}
print(json.dumps(PList))
注意,因为PList中的元素是类类型的对象,因此,参数default如果不指定序列化转换规则的话,仍然会让dumps函数一脸懵逼,上面的demo在运行时抛出异常:
ok,我们也不为难dumps函数了,正常点好了
拿到这个JSON串后,你就可以对数据进行解析了,排版后的格式如下

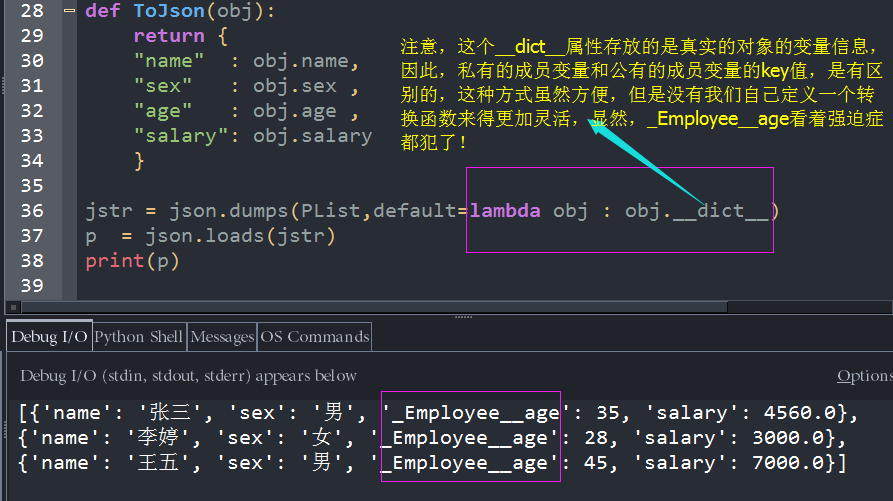
序列化类对象成json串,还有一种通用的方式,就是使用lambda表达式,来指定default的值,因为类的对象有一个属性__dict__,该属性以dict键值对的形式存储过了对象的变量名和其对应的值,如下
我们,看一下,利用通用的方式怎么来写
说了半天json串的序列化,还没有讲如何将json串反序列化成对象,不能讲太细了,关于loads函数信息,借助help函数自行查看,既然,我们dumps函数指定了序列化的转换函数,那么,我们的loads函数也要指定一下反序列化的转换函数,注意,前者是将对象按照指定的函数转化成json串,后者则是这项工作的逆向操作
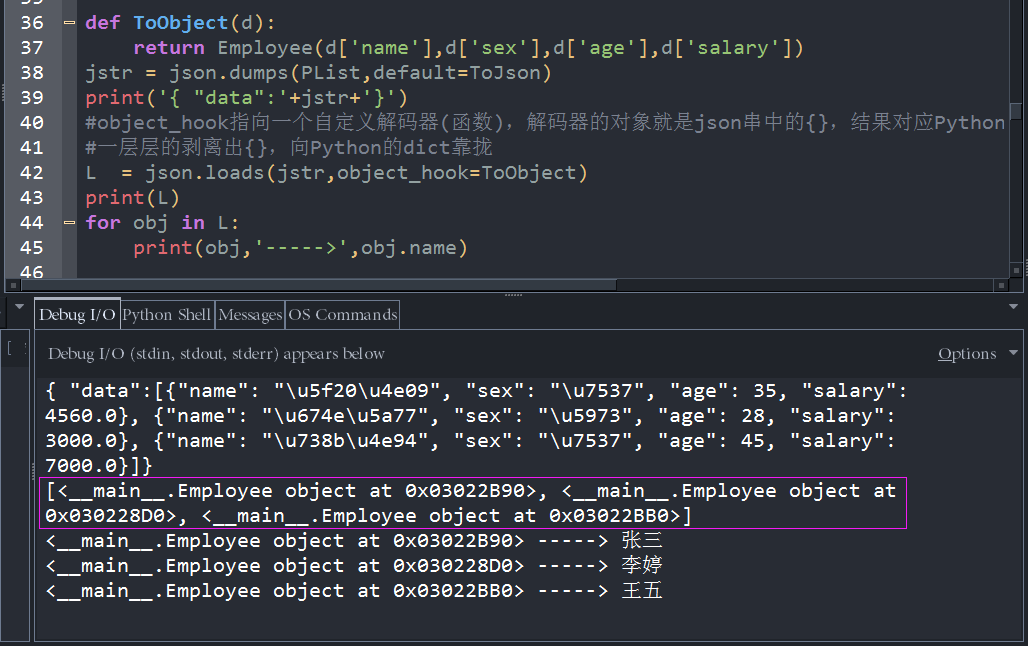
直接上完整demo
#!/usr/bin/env Python3
# -*- coding:utf-8 -*-
import json
class Employee:
def __init__(self,name,sex,age,salary):
self.name = name ; #姓名
self.sex = sex ; #性别
self.__age = age ; #年龄 私有变量
self.salary= salary; #薪资 按月算
@property
def age(self): #age的getter属性,还记得装饰器@property的用法吗?
return self.__age
@age.setter
def age(self,value): #age的setter属性
self.__age = value
person1 = Employee('张三','男',35,4560.00)
person2 = Employee('李婷','女',28,3000.00)
person3 = Employee('王五','男',45,7000.00)
PList = []
PList.append(person1)
PList.append(person2)
PList.append(person3)
def ToJson(obj):
return {
"name" : obj.name,
"sex" : obj.sex ,
"age" : obj.age ,
"salary": obj.salary
}
def ToObject(d):
return Employee(d['name'],d['sex'],d['age'],d['salary'])
jstr = json.dumps(PList,default=ToJson) #高阶函数
print('{ "data":'+jstr+'}')
#object_hook指向一个自定义解码器(函数),解码器的对象就是json串中的{},结果对应Python的dict
#一层层的剥离出{},向Python的dict靠拢
L = json.loads(jstr,object_hook=ToObject)
print(L)
for obj in L:
print(obj,'----->',obj.name)我们看下最终效果
你肯定会有这样一个疑问,如果单单是传送基本数据的话,那我直接写一个函数,将对方要的数据封装成str不就行了嘛,干嘛还要用json模块序列化功能呢,我去,如果你要这样想,我拿你没办法,Python给你提供的有现成的模块你不用,你非要自己去写,好吧,那你就一个数据一个数据的拼接去吧。
下一篇,我们转向实际应用开发,讲解一下,如何利用Python现成的json模块提供的序列化json串的功能,来实现,和Java的网络数据通信!















 1444
1444

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









