







目录
1.什么是序列化与反序列化?
1.1 序列化与反序列化的定义
在计算机网络通信中,不同机器间的通讯需要采用约定的协议,而序列化和反序列化就是属于通讯协议的一部分。通讯协议往往采用分层模型,不同模型每层的功能定义以及颗粒度不同,例如:TCP/IP协议是一个四层协议,而OSI模型却是七层协议模型。在OSI七层协议模型中展现层(Presentation Layer)的主要功能是把应用层的对象转换成一段连续的二进制串,或者反过来,把二进制串转换成应用层的对象--这两个功能就是序列化和反序列化。
序列化: 将数据结构或对象转换成二进制串的过程
反序列化:将在序列化过程中所生成的二进制串转换成数据结构或者对象的过程
1.2 序列化与反序列化的应用场景
存储:我们在运行python程序的过程中,运行时的列表、字典等数据结构往往都是随着程序的运行开始而产生,随着程序的运行结束而消失,那么如何将这些Python对象保存下来呢?这时候序列化就派上了用场。
传输:当两个进程在进行远程通信时,彼此可以发送各种类型的数据。无论是何种类型的数据,都会以二进制序列的形式在网络上传送。发送方需要把这个对象转换为字节序列,在能在网络上传输;接收方则需要把字节序列在恢复为对象。
在Python中,模块pickle实现了对一个 Python 对象结构的二进制序列化和反序列化。
2.pickle标准库介绍
pickle是python语言的一个标准模块,安装python后已包含pickle库,不需要单独再安装。通过模块的序列化操作我们能够将程序中运行的对象信息保存到文件中去,永久存储;通过模块的反序列化操作,我们能够从文件中还原保存的对象。值得注意的是,pickle模块是以二进制的形式序列化后保存到文件中(后缀.kpl),我们打开该文件看到的是一堆乱码,而python的另一个序列化标准模块JSON文件打开之后是肉眼可读的。
2.1 pickle序列化操作
pickle.dump(obj,file)
参数obj:将要序列化的python对象
参数file:将对象 obj 封存以后的对象写入已打开的file文件
下面我们通过一个实例来看看如何使用dump()函数:
import pickle
dic={
"name":"张三",
"age":12
}
#注意open函数mode选择以二进制写入文件,比如'wb+',
f = open("E:\VsCodeWorkSpace\PythonProjects\pickle_File.pkl",'wb+')
pickle.dump(dic,f)
f.close()上述代码中,我们创建了一个字典,然后打开了一个file文件对象,我们通过调用dump()函数将字典永久保存在pickle_File.pkl文件中。
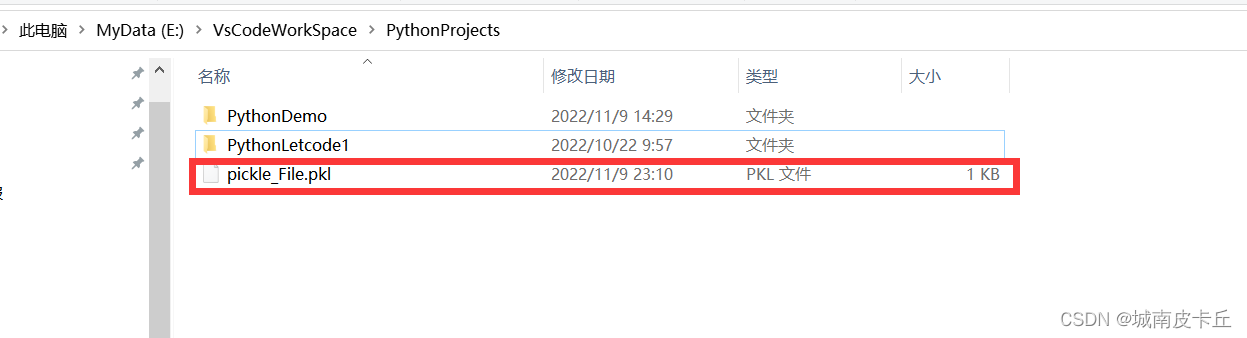
Pickler(file).dump(obj)
参数obj:将要序列化的python对象
参数file:将对象 obj 封存以后的对象写入已打开的file文件
下面我们再来通过一个实例看看如何使用这个函数
from pickle import Pickler
#注意open函数mode选择以二进制写入文件,比如'wb+'
f=open("E:\VsCodeWorkSpace\PythonProjects\Pickler_file", 'wb+')
list=["admin","123458"]
Pickler(f).dump(list);
f.close()上述代码中,我们创建了一个列表,然后打开了一个file文件对象,我们通过调用pickle模块中的Pickler类中的dump()函数将该列表永久保存在Pickler_file文件中。
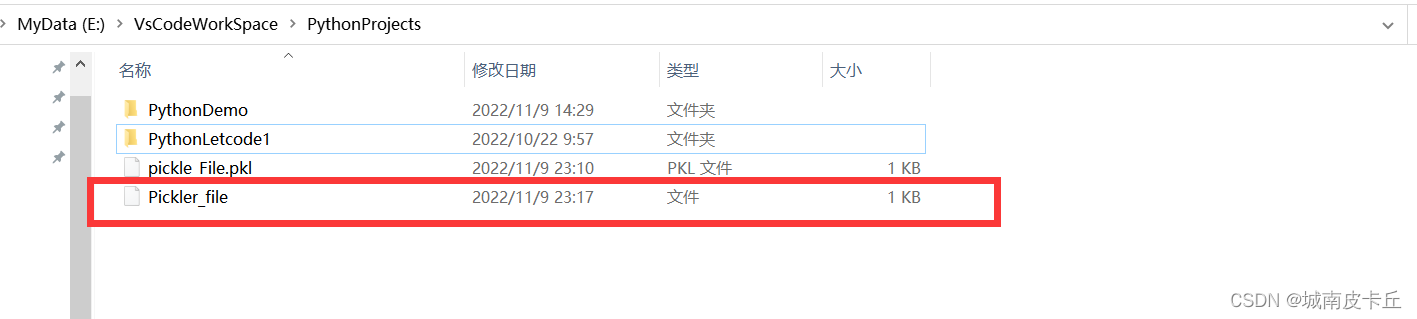
2.2 pickle反序列化操作
pickle.load(file)
#该方法实现的是将序列化的对象从文件file中读取出来
参数file:序列化的file文件
刚才我们通过调用pickle模块中的Pickler类中的dump()函数将列表
list=["admin","123458"]永久保存在Pickler_file文件中,我们现在通过调用模块中的load()方法将它还原
import pickle
#注意open函数mode选择以二进制读取文件,比如'rb'
f1 = open("E:\VsCodeWorkSpace\PythonProjects\Pickler_file", 'rb')
di=pickle.load(f1)
print(di)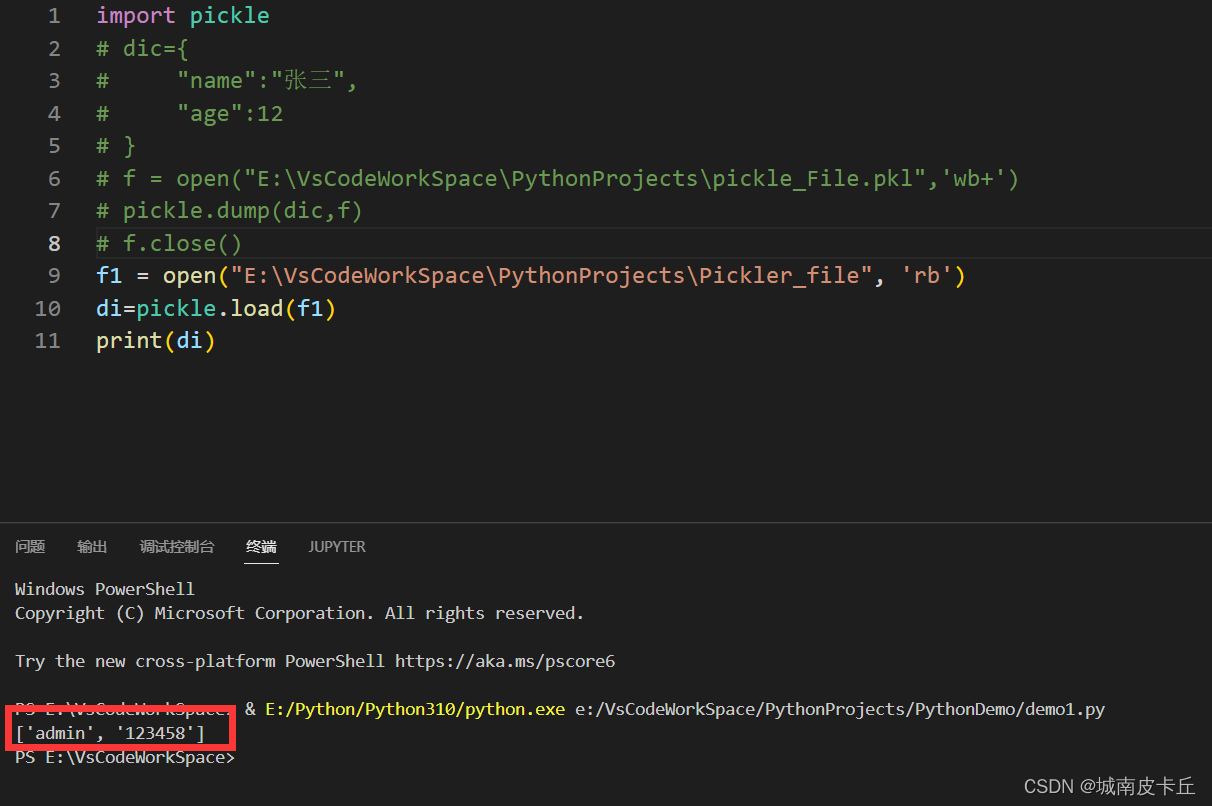
有一点需要注意,无论是序列化操作还是反序列化操作,参数file必须是以二进制的形式进行操作(读取)
Unpickler(file).load()
参数file:序列化的file文件
之前我们创建了一个字典,然后打开了一个file文件对象,我们通过调用dump()函数将字典永久保存在pickle_File.pkl文件中。现在用该反序列化方法将该对象还原。
from pickle import Unpickler
f=open("E:\VsCodeWorkSpace\PythonProjects\pickle_File.pkl",'rb')
dic=Unpickler(f).load()
print(dic)
值得注意的是pickle模块中还有一些其他的函数来帮助我们实现序列化与反序列化操作,我刚才介绍的dump()、load()函数还有其它可选参数来拓展函数的功能,这些官方文档中都做了非常详细的讲解。

更多函数用法,请参见python官方文档pickle模块
















 1347
1347

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











