









因为大型公司都有使用spark/hadoop的官方配置,不太需要个人工程师关心,
这个博客用来给予自己搭建或者小公司使用集群时使用
先复习下yarn-site.xml中几个参数的含义[3]:
| 配置文件 | 配置设置 | 默认值 | 计算值 |
|---|---|---|---|
| yarn-site.xml | yarn.nodemanager.resource.memory-mb | 8192 MB | = containers * RAM-per-container |
| yarn-site.xml | yarn.scheduler.minimum-allocation-mb | 1024MB | = RAM-per-container |
| yarn-site.xml | yarn.scheduler.maximum-allocation-mb | 8192 MB | = containers * RAM-per-container |
表格来自[1],增加一列用来记录约束关系(表中加粗的行都是在启动spark-shell或者spark-submit是需要注意的约束关系,约束关系必须全部满足,否则启动后必定报错,甚至连启动都会启动不了)
| 参数名 | 参数说明 | 默认取值[15] | 与配置文件yarn-site.xml中的参数约束关系(含依据 Reference) |
| --master | master 的地址,提交任务到哪里执行,例如 spark://host:port, yarn, local | spark://master:6066 | 无 |
| --deploy-mode | 在本地 (client) 启动 driver 或在 cluster 上启动,默认是 client | client | 无 |
| --class | 应用程序的主类,仅针对 java 或 scala 应用 | 无 | 无 |
| --name | 应用程序的名称 | 无 | 无 |
| --jars | 用逗号分隔的本地 jar 包,设置后,这些 jar 将包含在 driver 和 executor 的 classpath 下 | CLASSPATH | 无 |
| --packages | 包含在driver 和executor 的 classpath 中的 jar 的 maven 坐标 | 无 | 无 |
| --exclude-packages | 为了避免冲突 而指定不包含的 package | 无 | 无 |
| --repositories | 远程 repository | 无 | 无 |
| --conf PROP=VALUE | 指定 spark 配置属性的值, 例如 -conf spark.executor.extraJavaOptions="-XX:MaxPermSize=256m" | 无 | 无 |
| --properties-file | 加载的配置文件,默认为 conf/spark-defaults.conf | 无 | 无 |
| --driver-memory | Driver内存 spark-defaults.conf中是: spark.driver.memory | 1G | 无 |
| --driver-java-options | 传给 driver 的额外的 Java 选项 | 无 | 无 |
| --driver-library-path | 传给 driver 的额外的库路径 | 无 | 无 |
| --driver-class-path | 传给 driver 的额外的类路径 | 无 | 无 |
| --driver-cores | Driver 的核数,默认是1。在 yarn 或者 standalone 下使用
spark-defaults.conf中的变量是 spark.driver.cores | 1 | 无 |
| --executor-memory | 每个 executor 的内存,默认是1G spark-defaults.conf中的变量是 spark.executor.memory | 1G | executor-memory ≤ yarn.scheduler.minimum-allocation-mb≤yarn.scheduler.maximum-allocation-mb(一个container的最大值)≤yarn.nodemanager.resource.memory-mb[5] ------------------------------------------------------------------ executor-memory*num_executors<yarn.nodemanager.resource.memory-mb*node总数量
|
| --total-executor-cores | 所有 executor 总共的核数。仅仅在 mesos 或者 standalone 下使用(根据[4],这个参数是集群中所有被用作executor的core的数量)
spark-defaults.conf中的变量是 spark.executor.cores | 1 in YARN mode, all the available cores on the worker in standalone and Mesos coarse-grained modes. | num-executors * executor-cores<总cpu核数[6] |
| --num-executors | 启动的 executor 数量(cluster中总数量[11])。默认为2。在 yarn 下使用 | 2 | num-executors * executor-cores<总cpu核数[6] |
| --executor-cores | 每个 executor 的核数。在yarn或者standalone下使用
spark-defaults.conf中的变量是 spark.executor.cores | 1 | 命令行executor-cores<配置文件yarn.scheduler.maximum-allocation-vcores[2] |
如果懒得关心表格中的一些约束关系,可以直接参考[7]
yarn.nodemanager.resource.memory-mb那这个我的精确理解是:
针对yarn提交到目标集群的application,整个集群中,每个nodemanager可分配的内存上限
这里的内存上限指的是系统占用、同事占用后剩下的单机内存的上限
如何为每台机子分配cores呢?
根据[8]中的一个例子:
spark-submit \
--num-executors 10 \
--master spark://master:7077 --driver-memory 4G --executor-memory 2G \
--deploy-mode client \
--executor-cores 2 \
--total-executor-cores 8 \
/opt/app/Application.jar HelloWorld假设有4台机子,node1剩余8个core,其他三台剩余3个core
- 此时会遍历每个Worker,第一轮遍历后,每个Worker否符合启动一个executor(根据命令中的executor-cores,每个executor占用两个cpu core),这是已经分配了8个core,每台Worker都运行了一个executor(即占用两个cpu core)。
- 然后继续遍历可用资源,进行下一轮分配,只有node1可以符合启动executor,于是最后两个core分配到node1上。最后达到了标准的
--total-executor-cores 8。
另外[5]还提到了pyspark对资源的分配原理
网上常说的yarn队列指的就是scheduler
[6]num-executors乘以executor-memory,就代表了你的Spark作业申请到的总内存量(也就是所有Executor进程的内存总和),这个量是不能超过队列的最大内存量的。
[9]讲解了yarn.scheduler.maximum-allocation-mb和yarn.nodemanager.resource.memory-mb的区别
这个链接中的意思是:
yarn.scheduler.maximum-allocation-mb:分配给container的资源上限
yarn.nodemanager.resource.memory-mb:多个container的总资源上限
[10]提到了关于两种不同模式的消耗资源的更为准确的计算方式
- yarn-client 模式的资源计算
节点 资源类型 资源量(结果使用上面的例子计算得到) master core 1 mem driver-memroy = 4G worker core num-executors * executor-cores = 4 mem num-executors * executor-memory = 4G - 作业主程序(Driver 程序)会在 master 节点上执行。按照作业配置将分配 4G(由 —driver-memroy 指定)的内存给它(当然实际上可能没有用到)。
- 会在 worker 节点上起 2 个(由 —num-executors 指定)executor,每一个 executor 最大能分配 2G(由 —executor-memory 指定)的内存,并最大支持 2 个(由--executor-cores 指定)task 的并发执行。
- yarn-cluster 模式的资源计算
节点 资源类型 资源量(结果使用上面的例子计算得到) master - 一个很小的 client 程序,负责同步 job 信息,占用很小。 worker core num-executors * executor-cores+spark.driver.cores = 5 mem num-executors * executor-memory + driver-memroy = 8g
[12]任务的并行度由分区数(Partitions)决定,一个Stage有多少分区,就会有多少Task。每个Task默认占用一个Core,一个Executor上的所有core共享Executor上的内存,一次并行运行的Task数等于num_executor*executor_cores,如果分区数超过该值,则需要运行多个轮次,一般来说建议运行3~5轮较为合适,否则考虑增加num_executor或executor_cores。
下面是spark应用时序图
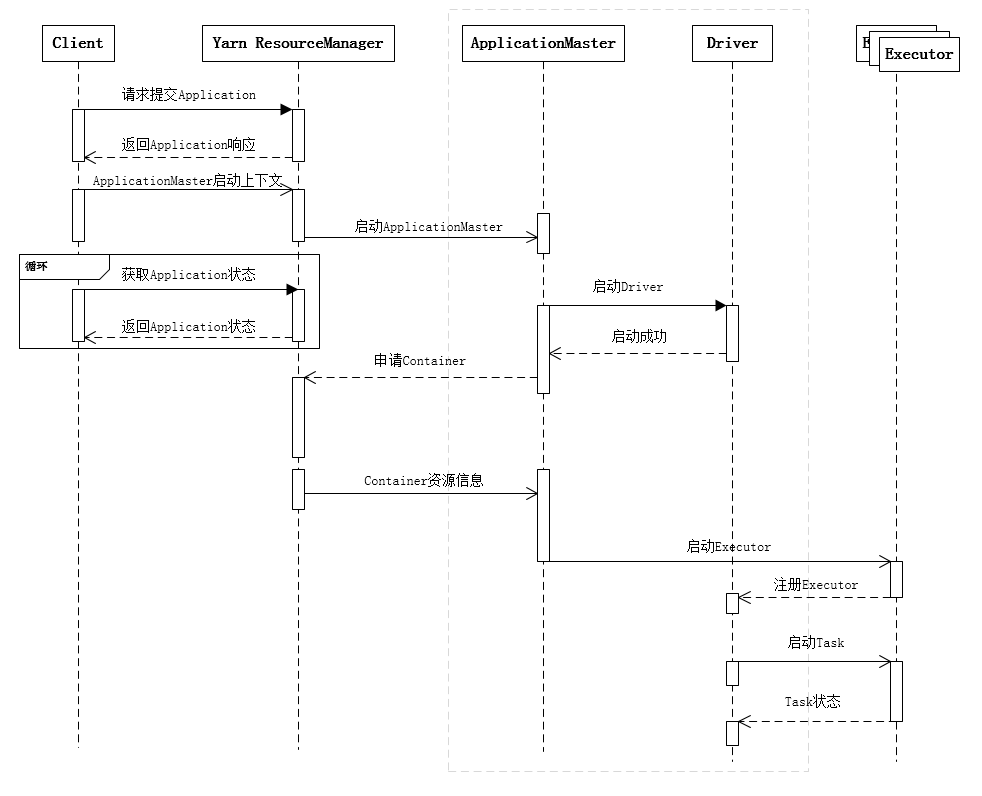
yarn-client模式[13](这张图可能不够准确,因为slaves文件中中如果写入master,那么master中也可以存在 executor)
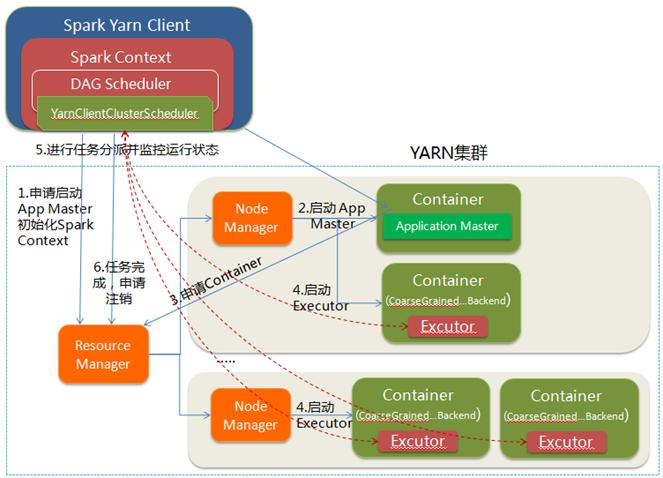
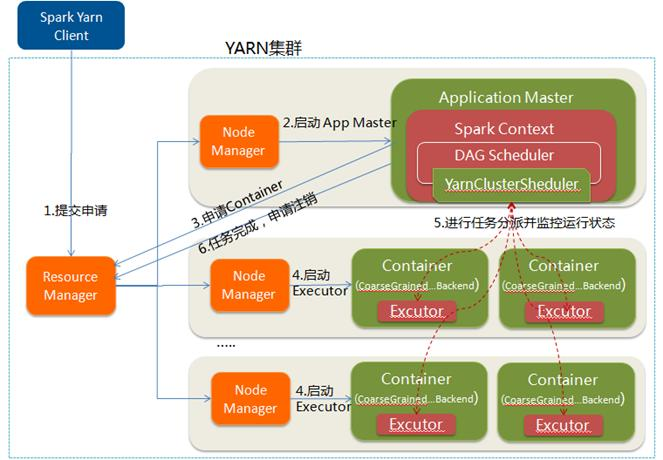
yarn-cluster模式[13]
#--------------------------------------------关于scheduler队列-------------------------------------------------------------------
这个东西和django+celery的邮件系统案例了类似,都是多开一个进程,然后主题把任务甩锅给队列。
#-----------------------------------------如何运用这些约束关系呢?(举例)------------------------------------------------------------------------------
①yarn.scheduler.maximum-allocation-mb(一个container的最大值)≤yarn.nodemanager.resource.memory-mb
当这个关系被违反的时候,会发生现象[16]
②executor-cores<yarn.scheduler.maximum-allocation-vcores
当这个关系被违反的时候,会发生报错[17]
Reference:
[2]Yarn application has already ended! It might have been killed or unable to launch application master
[4]Spark遇到的问题
[6]spark 指定相关的参数配置 num-executor executor-memory executor-cores
[8]Spark遇到的问题
[9]Difference between `yarn.scheduler.maximum-allocation-mb` and `yarn.nodemanager.resource.memory-mb`?
[11]Distribution of Executors, Cores and Memory for a Spark Application running in Yarn
[13]spark集群的任务提交执行流程
[14]How to deal with executor memory and driver memory in Spark?
[16]Spark集群启动正常,但是提交任务后只有一个节点(slave/worker)参与集群计算
[17]Yarn application has already ended! It might have been killed or unable to launch application master


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









