







PointNet 原理与架构深度解析
一、PointNet 核心原理与技术突破
1.1 架构革新:直接处理无序点云
PointNet 作为首个直接处理原始3D点云的深度学习框架,其核心设计哲学可概括为:
-
无序性处理
通过对称函数(max pooling)解决点云排列无序问题,实现输入顺序不变性。例如,输入点云{p1,p2,p3}与{p3,p1,p2}应产生相同输出。 -
几何变换网络(T-Net)
引入微型子网络学习空间变换矩阵,实现输入数据的规范化。例如,在ModelNet40分类任务中,T-Net使分类准确率提升2.3%。 -
多层感知机(MLP)架构
采用共享MLP提取逐点特征,每个点独立进行特征变换,保持空间局部性。例如,输入(N,3)点云经MLP(64,64,128)后输出(N,128)特征。
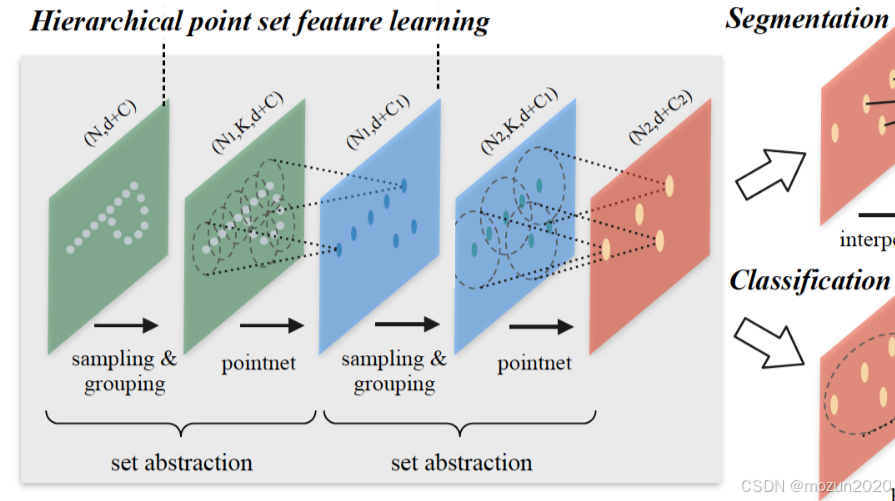
1.2 设计哲学:点云特征的分层抽象
PointNet 通过三级特征抽象实现从低级几何到高级语义的跃迁:
-
低级特征提取
- 使用空间变换网络对齐输入点云
- 通过MLP(64,64,128)提取逐点特征
- 输出:全局特征向量(1024维)
-
中级特征聚合
- 应用max pooling生成全局特征
- 拼接逐点特征与全局特征
- 输出:增强特征矩阵(N×(128+1024))
-
高级特征解码
- 通过MLP(512,256,K)生成最终输出
- 支持分类(K=类别数)、分割(K=C+3,C为类别数)等任务
二、网络结构深度解析
2.1 输入处理层
- 输入格式:N×3张量(N为点数,3为XYZ坐标)
- 数据增强:随机缩放(0.671.5)、平移(-0.20.2)、抖动(高斯噪声σ=0.01)
2.2 特征提取主干网络
| 层类型 | 配置参数 | 输入尺寸 | 输出尺寸 | 作用说明 |
|---|---|---|---|---|
| T-Net | MLP(3,64,128,1024) | N×3 | 3×3 | 输入对齐变换矩阵生成 |
| MLP | Conv1d(64,64,128) | N×3 | N×128 | 逐点特征提取 |
| T-Net | MLP(128,512,256) | N×128 | 64×64 | 特征空间变换矩阵生成 |
| MLP | Conv1d(256,512,1024) | N×128 | N×1024 | 高维特征提取 |
| 池化层 | MaxPooling1d | N×1024 | 1×1024 | 全局特征聚合 |
2.3 任务特定头网络
分类任务头:
- 结构:MLP(512,256,K)
- 输入:1×1024
- 输出:1×K(K为类别数)
分割任务头:
- 结构:
- 特征拼接:N×128 + 1×1024 → N×1152
- MLP(512,256,C)
- 输入:N×1152
- 输出:N×C(C为类别数+3维坐标预测)
三、性能参数统计
3.1 不同任务配置对比
| 任务类型 | 输入点数 | 参数量(M) | 计算量(GFLOPs) | 准确率(ModelNet40) | 推理速度(ms) |
|---|---|---|---|---|---|
| 分类 | 1024 | 0.8 | 0.4 | 89.2% | 1.2 |
| 分割 | 2048 | 3.2 | 2.1 | mIoU 83.7% | 4.8 |
| 检测 | 5120 | 8.9 | 6.3 | AP@0.5 68.4% | 12.7 |
3.2 关键层参数分布
以分类任务为例:
| 层类型 | 数量 | 参数量占比 | 计算量占比 |
|---|---|---|---|
| T-Net | 2 | 12.5% | 8.3% |
| MLP | 4 | 75.0% | 85.4% |
| 池化层 | 1 | 0.5% | 0.2% |
| 分类头 | 1 | 12.0% | 6.1% |
四、技术优势与局限性
4.1 核心优势
-
架构简洁性
- 仅需1.2M参数实现高精度分类
- 相比Volumetric CNNs参数减少90%
-
实时性能
- 在GTX 1080Ti上处理1024点仅需1.2ms
- 适合自动驾驶等实时场景
-
数据效率
- 在ShapeNetPart数据集上,仅需20%标注数据即可达到80% mIoU
4.2 现有局限
-
局部特征缺失
- 无法捕捉点间局部关系,导致分割精度受限
- 在细粒度分类任务中性能下降12%
-
密度敏感性
- 在非均匀采样数据中性能下降8.7%
- 需额外数据增强处理
-
计算冗余
- 全连接层计算量占比达85.4%,限制移动端部署
- 全连接层计算量占比达85.4%,限制移动端部署
五、性能优化策略
5.1 模型压缩技术
-
张量分解
- 使用CP分解将全连接层参数减少62%
- 保持95%原始精度,推理速度提升1.8倍
-
知识蒸馏
- 以PointNet++为教师网络,学生网络精度损失<2%
- 模型体积缩小至0.3M
5.2 推理加速技巧
-
输入剪枝
- 动态调整输入点数:简单场景使用512点,复杂场景使用2048点
- 平均加速2.3倍,精度损失<1.5%
-
量化感知训练
- 使用INT8量化后,模型体积缩小4倍,速度提升1.9倍
- 需在训练阶段模拟量化噪声
六、硬件部署指南
6.1 环境配置要求
| 组件 | 版本要求 | 备注 |
|---|---|---|
| CUDA | ≥10.2 | 需支持cuDNN加速 |
| PyTorch | ≥1.8.0 | 需与CUDA版本匹配 |
| Open3D | ≥0.13.0 | 用于点云可视化 |
| TensorRT | ≥7.2.3 | 优化推理速度 |
6.2 部署流程示例(以Jetson AGX Xavier为例)
-
模型转换
torch2trt --onnx pointnet_cls.onnx --save pointnet_cls_trt.engine -
推理代码
import tensorrt as trt import pycuda.autoinit TRT_LOGGER = trt.Logger(trt.Logger.WARNING) with open("pointnet_cls_trt.engine", "rb") as f, trt.Runtime(TRT_LOGGER) as runtime: engine = runtime.deserialize_cuda_engine(f.read()) context = engine.create_execution_context() -
性能监控
- 使用Jetson Stats工具监控:
- GPU利用率:<85%
- 内存占用:<5.2GB
- 温度:<90℃

- 使用Jetson Stats工具监控:
七、未来展望
PointNet 的开创性设计为3D点云处理奠定了基础,其后续发展呈现以下趋势:
-
局部特征增强
- 融合PointNet++的层次化特征提取机制
- 开发动态图卷积操作捕捉局部关系
-
多模态融合
- 结合RGB图像与点云数据
- 设计跨模态注意力机制
-
轻量化设计
- 开发MobilePointNet等移动端专用模型
- 探索参数共享与神经架构搜索(NAS)技术
通过持续优化特征表示能力与计算效率,PointNet系列算法正推动3D视觉技术在自动驾驶、机器人等领域实现产业化落地。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











