







Hardware Configuration Assumptions
The current implementation uses a tree reduction strategy. e.g. if there are 4 GPUs in the system, 0:1, 2:3 will exchange gradients, then 0:2 (top of the tree) will exchange gradients, 0 will calculate updated model, 0->2, and then 0->1, 2->3.
For best performance, P2P DMA access between devices is needed. Without P2P access, for example crossing PCIe root complex, data is copied through host and effective exchange bandwidth is greatly reduced.
Current implementation has a “soft” assumption that the devices being used are homogeneous. In practice, any devices of the same general class should work together, but performance and total size is limited by the smallest device being used. e.g. if you combine a TitanX and a GTX980, performance will be limited by the 980. Mixing vastly different levels of boards, e.g. Kepler and Fermi, is not supported.
“nvidia-smi topo -m” will show you the connectivity matrix. You can do P2P through PCIe bridges, but not across socket level links at this time, e.g. across CPU sockets on a multi-socket motherboard.
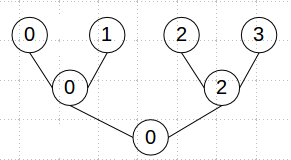
basic
P2P(P2P网络传输)一般指对等网络
网上各台计算机有相同的功能,无主从之分,一台计算机都是既可作为服务器,设定共享资源供网络中其他计算机所使用,又可以作为工作站,没有专用的服务器,也没有专用的工作站。对等网络是小型局域网常用的组网方式。
对等计算(Peer to Peer,简称p2p)可以简单的定义成通过直接交换来共享计算机资源和服务,而对等计算模型应用层形成的网络通常称为对等网络。在P2P网络环境中,成千上万台彼此连接的计算机都处于对等的地位,整个网络一般来说不依赖专用的集中服务器。网络中的每一台计算机既能充当网络服务的请求者,又对其它计算机的请求作出响应,提供资源和服务。通常这些资源和服务包括:信息的共享和交换、计算资源(如CPU的共享)、存储共享(如缓存和磁盘空间的使用)等。
DMA:
Direct Memory Access(存储器直接访问)。这是指一种高速的数据传输操作,允许在外部设备和存储器之间直接读写数据,既不通过CPU,也不需要CPU干预。整个数据传输操作在一个称为”DMA控制器”的控制下进行的。CPU除了在数据传输开始和结束时做一点处理外,在传输过程中CPU可以进行其他的工作。这样,在大部分时间里,CPU和输入输出都处于并行操作。因此,使整个计算机系统的效率大大提高
DMA的概念:DMA是在专门的硬件( DMA)控制下,实现高速外设和主存储器之间自动成批交换数据尽量减少CPU干预的输入/输出操作方式。
map-reduce(http://blog.csdn.net/opennaive/article/details/7514146)
parallel.hpp中有一个类
// Synchronous data parallelism using map-reduce between local GPUs.templateclass P2PSync : public GPUParams, public Solver::Callback, public InternalThread {
…
}
map函数:接受一个键值对(key-value pair),产生一组中间键值对。MapReduce框架会将map函数产生的中间键值对里键相同的值传递给一个reduce函数。
reduce函数:接受一个键,以及相关的一组值,将这组值进行合并产生一组规模更小的值(通常只有一个或零个值)。
how to change the old version to parallelism(作废)
A. old version: https://github.com/LisaAnne/lisa-caffe-public/tree/lstm_video_deploy
B. latest version:https://github.com/apsvvfb/caffe
C. result: https://github.com/apsvvfb/lisa-caffe-public
0.caffe.proto
使用linux下的diff命令比较旧版本和新版本的caffe.proto文件.
cd /work/na
diff lisa-caffe-public/src/caffe/proto/caffe.proto caffe/src/caffe/proto/caffe.proto -y > caffe_proto.txt(1)message BlobProto新增加了两行(blog.cpp中因此进行了改动)
repeated double double_data = 8 [packed = true];
repeated double double_diff = 9 [packed = true];1.用代码B中的caffe.cpp替换代码A中的.
2. 从复制代码B中复制A中没有的文件
复制代码B中的
solver_factory.hpp,
parallel.hpp, parallel.cpp
blocking_queue.hpp, blocking_queue.cpp
signal_handler.h
到代码A中
3. 用代码B中的common.hpp,common.cpp替换代码A中的.
区别主要是新版增加了
// Parallel training info
inline static int solver_count() { return Get().solver_count_; }
inline static void set_solver_count(int val) { Get().solver_count_ = val; }
inline static bool root_solver() { return Get().root_solver_; }
inline static void set_root_solver(bool val) { Get().root_solver_ = val; }
protected:
int solver_count_;
bool root_solver_;并修改了Get()
static shared_ptr<Caffe> singleton_;
inline static Caffe& Get() {
if (!singleton_.get()) {
singleton_.reset(new Caffe());
}
return *singleton_;
}// Make sure each thread can have different values.
static boost::thread_specific_ptr<Caffe> thread_instance_;
Caffe& Caffe::Get() {
if (!thread_instance_.get()) {
thread_instance_.reset(new Caffe());
}
return *(thread_instance_.get());
}4. solver.cpp,solver.hpp全部替换
主要定义了root_solver, class WorkerSolver,
5. net.hpp, net.cpp全部替换
6. internal_thread.hpp, internal_thread.cpp全部替换
7. blob.cpp, blob.hpp全部替换
可以使用linux下的diff命令比较旧版本和新版本的blob文件
两个版本的主要区别是
-新版本中增加了const int* gpu_shape() const;函数
-新版本中增加了shared_ptr shape_data_;成员
-旧版本的ToProto函数以及FromProto函数只考虑dataanddiff,新版本的ToProto函数以及FromProto中增加了double_data以及`double_diff
8. pythonLayer
复制sequence_input_layer.py到sequence_input_layer_2.py
(1) 在开头增加如下代码:
from threading import Lock
global trainIdx
global testIdx
trainIdx=0
testIdx=0
lock=Lock()(2) 注释掉所有的self.idx = 0 (共6处)
(3)setup(self, bottom, top)
#self.sequence_generator = sequenceGeneratorVideo(self.buffer_size, self.frames, self.num_videos, self.video_dict, self.video_order)
self.sequence_generator = sequenceGeneratorVideo(self.buffer_size, self.frames, self.num_videos, self.video_dict, self.video_order,self.train_or_test)(4)
class sequenceGeneratorVideo(object):
def __init__(self, buffer_size, clip_length, num_videos, video_dict, video_order, train_or_test):
self.buffer_size = buffer_size
self.clip_length = clip_length
self.N = self.buffer_size*self.clip_length
self.num_videos = num_videos
self.video_dict = video_dict
self.video_order = video_order
#self.idx = 0
self.train_or_test = train_or_test#新增加的
def __call__(self):
label_r = []
im_paths = []
im_crop = []
im_reshape = []
im_flip = []
#####################################
'''
if self.idx + self.buffer_size >= self.num_videos:
idx_list = range(self.idx, self.num_videos)
idx_list.extend(range(0, self.buffer_size-(self.num_videos-self.idx)))
else:
idx_list = range(self.idx, self.idx+self.buffer_size)
'''
lock.acquire()
if cmp(self.train_or_test,"train"):
idx=trainIdx
else:
idx=testIdx
if idx + self.buffer_size >= self.num_videos:
idx_list = range(idx, self.num_videos)
idx_list.extend(range(0, self.buffer_size-(self.num_videos-idx)))
else:
idx_list = range(idx, idx+self.buffer_size)
#####################################
for i in idx_list:
key = self.video_order[i]
label = self.video_dict[key]['label']
video_reshape = self.video_dict[key]['reshape']
video_crop = self.video_dict[key]['crop']
label_r.extend([label]*self.clip_length)
im_reshape.extend([(video_reshape)]*self.clip_length)
r0 = int(random.random()*(video_reshape[0] - video_crop[0]))
r1 = int(random.random()*(video_reshape[1] - video_crop[1]))
im_crop.extend([(r0, r1, r0+video_crop[0], r1+video_crop[1])]*self.clip_length)
f = random.randint(0,1)
im_flip.extend([f]*self.clip_length)
rand_frame = int(random.random()*(self.video_dict[key]['num_frames']-self.clip_length)+1+1)
frames = []
for i in range(rand_frame,rand_frame+self.clip_length):
frames.append(self.video_dict[key]['frames'] %i)
im_paths.extend(frames)
im_info = zip(im_paths,im_crop, im_reshape, im_flip)
#####################################
'''
self.idx += self.buffer_size
if self.idx >= self.num_videos:
self.idx = self.idx - self.num_videos
'''
idx += self.buffer_size
if idx >= self.num_videos:
idx = idx - self.num_videos
if cmp(self.train_or_test,"train"):
trainIdx= idx
else:
testIdx= idx
lock.release()
#####################################
return label_r, im_info9. 用代码B中的blob.cpp, blob.hpp替换代码A中的.
可以使用linux下的diff命令比较旧版本和新版本的blob文件
两个版本的主要区别是
-新版本中增加了const int* gpu_shape() const;函数
-新版本中增加了shared_ptr shape_data_;成员
-旧版本的ToProto函数以及FromProto函数只考虑dataanddiff,新版本的ToProto函数以及FromProto中增加了double_data以及`double_diff
10. 复制代码B下src/caffe/solvers文件夹到代码A下.
11. 关于代码A中的include/caffe/vision_layers.hpp
代码B(caffe新版本)中删除了这个文件,而在include/caffe/layers文件夹下定义了一堆的相关layer的hpp文件
这里暂时不动.
//TO BE CONTINUED:















 2810
2810

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









