







MapReduce计算模型与架构
- 计算模型
- MapReduce提供了简洁的编程接口,输入时Key/Value数据。时,输出也是Key/Value数据。应用开发者只需要根据业务逻辑实现Map和Reduce接口,即可完成大规模数据的并行处理任务。
- MapReduce计算框架会自动将中间结果中具有相同Key值得记录聚合在一起,并将数据传送给Reduce函数内定义好的处理逻辑作为其输入值。
- Reduce函数接受Map阶段传过来的某个Key值及其对应的若干Value值等中间数据,对其进行如累加、过滤、转换等操作,生成Key/Value形式的结果。
- 实例:单词统计、链接反转、网站点击量统计
- 系统架构
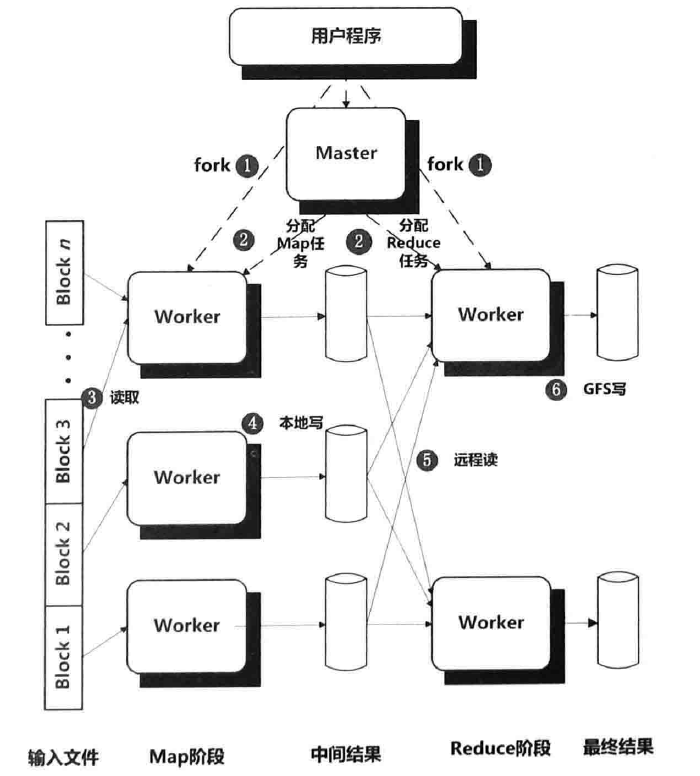
- Google的MapReduce架构
- 处理流程
- MapReduce框架将应用的输入数据分成M个数据块,典型的数据块大小为64MB,然后可以启动位于集群中不同机器上的若干程序。
- 这些程序中有一个全局唯一主控Master程序及若干工作程序Worker,Master负责分配具体的Map任务或Reduce任务并做一些全局管理功能。整个应用有M个Map任务和R个Reduce任务,M和R可以由开发者指定。Master将任务分配给目前处于空闲状态的Worker程序。
- 被分配到Map任务的Worker读取对应的数据块内容,从数据块中解析一个个key/value记录数据并将其传给用户自定义的Map函数,Map函数输出的中间结果Key/Value数据在内存中进行缓存。
- 缓存的Map函数产生的中间结果被周期性的写入本地磁盘,每个Map函数的中间结果再被写入磁盘前被分割函数(Partitioner)切割成R份,R是Reduce的个数。(这里的分割函数一般使用Key对R进行哈希取模)这样就将Map函数的中间数据分割成R份对应每个Reduce函数所需的数据分片临时文件。Map函数完成对应的数据块的处理后将R个临时文件位置通知Master,再由Master将其转交给Reduce的Worker。
- 当某个Reduce任务Worker接收到Master的通知时,其通过RPC远程调用将Map任务产生的M份属于自己的数据文件(即Map分割函数取模后与自己编号相同的那份分割数据文件)远程拉取到(pull)到本地。(从这里可以看出,只有所有Map任务都完成时Reduce任务才能启动)当所有中间数据都拉取成功,则Reduce任务根据中间数据的Key对所有记录进行排序,这样就可以将所有具有相同Key的记录聚合在一起。
注:Reduce从Map任务 获取中间数据时采用是拉取方式而不是采用由Map任务推送给Reduce任务,这样做的好处是可以支持细粒度容错。假设在计算过程中某个Reduce任务失败,那么对于Pull方式来说,只要重新运行这个Reduce任务即可,无须充不执行全部所有的Map任务。Push是接收方被动接收数据的过程,而pPull则是接收方主动接收数据的过程 - Reduce任务Worker遍历已经按照中间结果Key有序的数据,将同一个Key及其对应的多个Value传递给用户自定义的Reduce函数,Reduce函数执行业务逻辑后将结果追加到这个Reduce任务对应的结果文件的末尾。
- 当所有Map和Reduce任务都成功执行完成时,Master便唤醒用户的应用程序,此时,MapReduce调用结束,进入用户代码执行空间。
注:为了优化执行效率,MapReduce计算框架在Map阶段还可以执行可选的Combiner操作(在Map阶段执行一个操作:将中间数据中具有相同Key的Value进行合并,本地Reduce,减少中间数据率,减少网络传输,提高系统效率。) - Hadoop的MapReduce架构
- Google的MapReduce框架支持细粒度的容错机制。
Master周期性的Ping各个Worker,如果在一定时间内没有响应,则可任务其已发生故障。此时由这个Worker已经完成的和正在完成的所有Map任务重新设置为Idle状态,这些任务将由其他Worker重新执行。
- Google的MapReduce架构
- MapReduce的计算特点及不足
- 优点:
- 具有极强的扩展性,可以在数千台机器上并发执行
- 具有很好的容错性,即使集群机器发生故障,一般情况下也不会影响任务的正常执行
- 具有简单性。用户只要完成Map和Reduce函数即可完成大规模数据的并行处理。
- 缺点:
- 无高层抽象的数据操作语言
- 数据无Schema及索引
- 单节点效率低下
- 任务流描述方法单一
- MapReduce不适合对实时性要求高的应用场景,比如交互式查询或流式计算,也不适合迭代类的机器学习及数据挖掘类应用,原因如下:
- Map和Reduce任务启动时间较长。因为对于批处理系统来说,其任务启动时间相对后续执行时间来说所占比例不大,所以不是问题,但是对于时效性要求高的应用,其启动时间与任务处理相比就太高,不合理。
- 在一次应用任务执行过程中,MapReduce计算模型存在多处的磁盘读写及网络传输过程。对于迭代类机器学习应用来说,往往需要同一个MapReduce任务反复迭代进行,此时磁盘读写及网络传输开销需要反复进行多次,效率低下。
- 优点:
MapReduce计算模式
- 求和模式
- 数值求和:如计算单词词频、计算网页PV数
- 记录求和:如对链接关系反转、搜索引擎中建立倒排索引
- 过滤模式
特点:不对数据进行转换,只是从大量数据中筛选,由于此类应用不需要进行聚合操作,所以不需要Reduce阶段
- 简单过滤:根据一定条件从海量数据中筛选满足条件的记录。应用如数据清理、从大量数据中追踪感兴趣的数据、分布式Grep操作、记录随机抽样等。
- Top 10:基本思想是由局部Top 10进行Reduce得到全局Top 10。
与简单过滤的差异:简单过滤的条件判断只涉及当前记录,而top k计算模式需要在记录之间进行比较,并获得全局最大的数据子集
- 组织数据模式
- 数据分片:通过自定义Partitioner实现数据分类输出到Reduceer
- 全局排序:利用MapReduce本身自带的排序特性来实现,因为Reduce阶段框架会将中间数据按Key大小进行排序,如果是设定一个Reduceer,那么Reduce不需要做额外工作,只需要原样输出即可,但是如果设定多个Reducer,那么需要在Partitioner策略上做些处理,因为尽管每个Reduce负责的部分是有序,但是多个Reducer产生了多分部分有序的结果,并没有达到全局排序的效果。至于Partitioner策略,可以通过Partitioner在将数据发送到Reducer的时候保证不同Reducer处理一个范围区间的记录。一种Partitioner策略如下:
Partition(key){
range = (KEY_MAX - KEY_MIN) / Number_of_Reducers;
reducer_no = (key - KEY_MIN) / range;
return reducer_no;
}- join模式
- Reduce-Side Join:解决数据集合Join操作的一种比较通用的方法,很多其他类型的Join操作也可以通过Reduce-Side Join 来完成,所以其具有实现简单以及具备通用性的优点,但是缺点是因为没有根据不同Join类型的特点做出特定优化,所以计算效率较低。
- Map-Side Join
适用场景:两个需要Join的数据集合L和R,一个大一个小(假设L大R小),而且小的数据集合完全可以放入内存中,此时,只需要采用一个Map-Only MapReduce任务即可完成Join操作。Mapper的输入数据是L进行拆分后的内容,而R足够小,所以将其分发给每个Mapper并在初始化就将其加载到内存存储,一般比较搞笑的方法是将R存入内存哈希表中,以外键作为哈希表的Key,这样可以依次读入L的记录并查找哈希表来进行Join操作。
DAG计算模型
- 关于DAG是什么?在大数据领域有什么应用?
DAG是有向无环图的简称。在大数据领域,DAG计算模型往往是指将计算任务在内部分解成若干个子任务,这些子任务之间由逻辑关系或运行先后顺序等因素被构建成有向无环图。 - DAG计算系统的三层结构
- 应用表达层(最上层):通过一定手段将计算任务分解成由若干子任务形成的DAG结构,这层的核心是表达的便捷性,主要目的是方便应用开发者快速描述或者构件应用。
- 物理机集群(最下层):由大量物理机器搭建的分布式计算环境,这是计算任务最终执行的场所。
- DAG执行引擎层(中间层):主要目的是将上层以特殊方式表达的DAG计算任务通过转换和映射,将其部署到下层的物理机集群中来真正运行。这层是DAG计算系统的核心部件,计算任务的调度、底层硬件的容错、数据与管理信息的传递、整个系统的管理与正常运转都需要由这层来完成。
Dryad
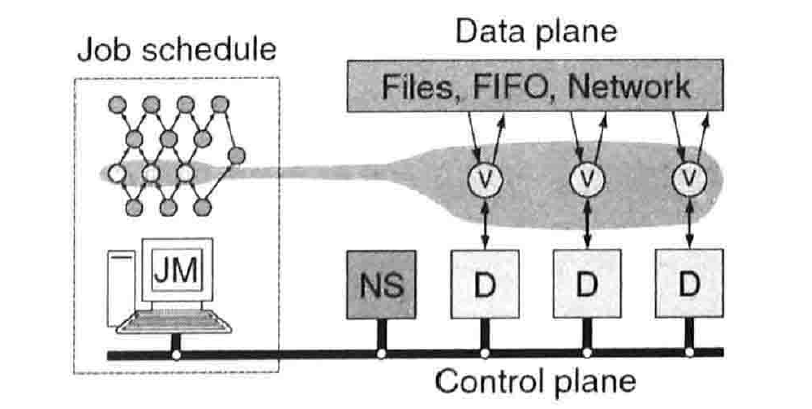
- 简介:微软的批处理DAG计算系统,主要目的是为了便于开发者便捷地进行分布式任务处理。Dryad将具体计算任务组织成有向无环图,其中图节点代表用户写的表达应用逻辑的程序,图节点之间的边代表数据流动通道。Dryad在实现时以共享内存、TCP连接以及临时文件的方式来进行数据传递,绝大多数情况下采用临时文件的方式。
- 整体架构图
- 各部件功能介绍
- JM(Job Manager,任务管理器)
负责将逻辑形式存在的DAG描述映射到物理集群机器中,起到任务调度器及全局管理者的作用。 - NS(Name Server,命名服务器)
负责维护集群当前可用的机器资源,从命名服务器还可以查到机器在物理拓扑结构中的位置,这样便于JM在任务调度时考虑到数据局部性,尽可能将计算推送到数据节点上,以此来减少网络通信开销,加快执行速度。 - Daemon守护进程
其作为Jm在计算节点上的代理,负责具体子任务的执行和监控。当DAG中某个图节点首次被分配到工作机上时,JM将二进制代码传输给Daemon进程由其负责执行,Daemon进程在执行过程中和JM通信,来汇报执行进度以及数据处理完成情况。
- JM(Job Manager,任务管理器)
- Dryad的图结构描述
两个基本操作:克隆、连接( o )、横向融合( || )
Flume Java和Tez
- Flume Java:本质上是在MapReduce基础上的DAG系统,图中每个节点可以看作是单个的MapReduce子任务,Flume Java还提供了常用的操作符来简历图之间的边,即将若干个MapReduce程序以一定语义串接起来形成DAG任务
- Tez本身是一个相对通用的DAG计算系统,最初提出是为了改善交互数据分析系统Stringer的底层执行引擎,Stinger是Hive的改进版本,最初底层的执行引擎是Hadoop的MapReduce任务形成的DAG任务图,考虑到其运行效率较低,所以提出Tez来替换底层执行引擎。Tez使用Map和Reduce任务作为DAG的图节点,图节点的有向边是数据传输通道。Tez通过消除Map阶段中间文件输出到磁盘过程以及引入Reduce-Reduce结构等改进措施提升了底层执行引擎的效率。















 805
805

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









