






导言
最近(其实已经火了一段时间了)大红大紫,而且生成的图像既有想象力,有的也很真实.这里我大概介绍其中涉及的技术以后后续使用.预计会写两三期.
还希望多多点赞关注 😄
AI绘画的开始与革命
当说到一件事情的开始时,我们也许会谈论到几个世纪甚至几千年前人们的一些思想.所以要确切地谈论一件事情的开始最好要限定一个范围.
AI绘画涉及到生成,谈到生成就离不开GAN了.GAN可以生成图像,其通过一个生成器和一个判断器来训练.
2018 年,第一幅由 AI 生成的肖像《Edmond de Belamy》问世,它由生成对抗网络(GAN)创建,是 Obvious Art 的 “La Famille de Belamy” 系列的一部分,最终在佳士得艺术品拍卖会上以 432500 美元成交。
2022 年,Jason Allen 的 AI 创作作品《Théâtre D’opéra Spatial》在科罗拉多州博览会的年度艺术竞赛中获得了第一名。
谈到GAN,这本身就是一个非常大的领域了,这里面有很多xxGAN同时也有很多trick.


- 整个式子由两项构成。x表示真实图片,z表示输入G网络的噪声,而G(z)表示G网络生成的图片。
- D(x)表示D网络判断真实图片是否真实的概率(因为x就是真实的,所以对于D来说,这个值越接近1越好)。而D(G(z))是D网络判断G生成的图片的是否真实的概率。
- G的目的:上面提到过,D(G(z))是D网络判断G生成的图片是否真实的概率,G应该希望自己生成的图片“越接近真实越好”。也就是说,G希望D(G(z))尽可能得大,这时V(D, G)会变小。因此我们看到式子的最前面的记号是min_G。
- D的目的:D的能力越强,D(x)应该越大,D(G(x))应该越小。这时V(D,G)会变大。因此式子对于D来说是求最大(max_D)
GAN(生成对抗网络)经过不断发展其有了不错的效果,但有些始终难以克服的问题:生成结果多样性缺乏、模式坍缩(生成器在找到最佳模式后就难以进步了)、训练难度高。这些困难导致 AI 生成艺术一直难以做出实用的产品。
重大转折是文生图即text to image,根据文字生成图像.
这个转变的代表就是DALL·E. 2021年OpenAI发布DALL·E.
DALL·E 结合了学习将图像映射到低维标记的离散变分自动编码(dVAE)和自回归建模文本和图像标记的 Transformer 模型。输入给定的文本,DALL·E 可以预测图像标记,并在推断过程中将其解码为图像。
简单来说就是dVAE+CLIP+transformer.
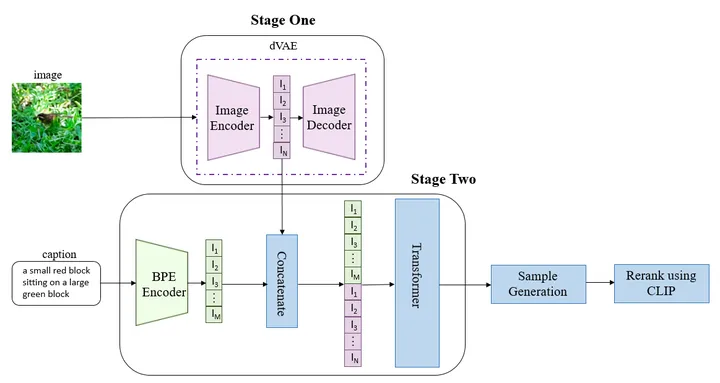
这里我就不细说这些技术了,因为我自己也不是很懂
虽然 DALL·E 可以很好地生成漫画和具有艺术风格的图像,但无法准确地生成逼真的照片。因此,OpenAI 投入了大量资源来创建改进的文生图模型——DALL·E 2
然后就是出名的Stable Diffusion了.
Diffusion Model (扩散模型) 让训练模型变得更加简单,只需大量的图片就行了,其生成图像的质量也能达到很高的水平,并且生成结果能有很大的多样性,这也是新一代 AI 能有难以让人相信的“想象力”的原因。
- 这篇 2020 年的论文 Denoising Diffusion Probabilistic Models ,首次把2015 年诞生的扩散模型用在了图像生成上
- 2021 年 1 月 openAI 公布了 Dall-E 并在 论文中宣布 Diffusion Model (扩散模型) 击败了 GAN (生成对抗网络)(Diffusion Models Beat GANs on Image Synthesis),为工程界指明了方向。
- 2021 年 10 月开源的文本生成图像工具 disco-diffusion 诞生,此后有相当多的基于此的产品出现。
- 2022 年 8 月 stability.ai 开源了 Stable Diffusion , 这是目前可用性最高的开源模型,很多商业产品都基于此如:NovelAI
Stable Diffusion 的计算效率远高于其他文生图模型,以前的文生图模型需要数百天 GPU 计算,Stable Diffusion 需要的计算量要小得多,因此资源不足的人更容易接受。它还允许用户通过图像与图像之间的转换(如将素描变成数字艺术)或绘画(在现有图像中删除或添加一些东西)来修改现有的图像。
所以截止到现在,一般说的AI绘画指的是用Diffusion技术为核心的图像生成.
实战 stable-diffusion-webui
光说不练没用.这里我会参考很多教程以及自己测试,如果在你的环境上有问题欢迎留言评论.
本文前提是您需要一定的前置知识,比如git使用,python环境等.
需要工具
- git
- python
- conda 主要解决环境隔离,不影响其他python环境
逻辑是这样的,我们本身利用公开的模型,利用调好的模型直接得到结果(当然你也可以自己训练).
而现在需要的是一个web ui也就是一个界面方便调试.
为了方便隔离不同版本Python环境我们使用conda(当然实际上使用python的virtualenv等等也是可以的)
流程
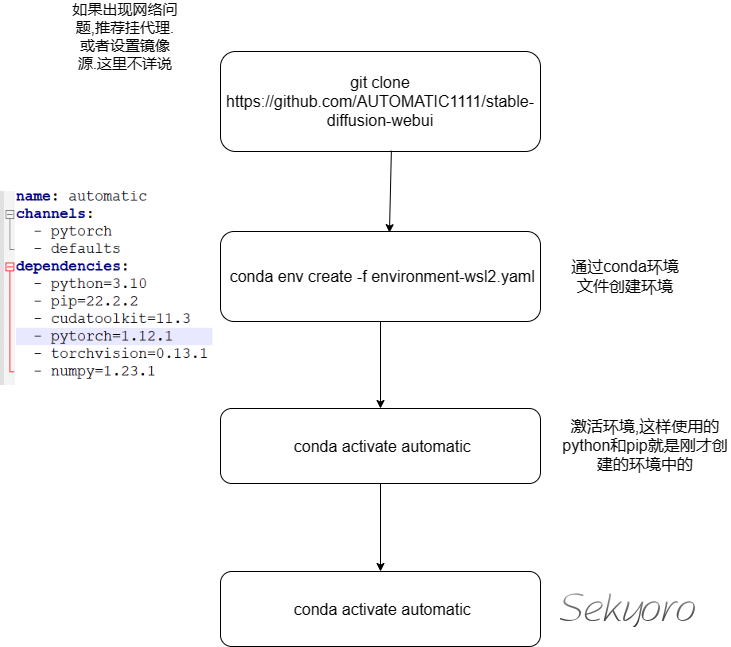
首先下载这个web ui
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui
下载好后发现里面有若干文件,注意venv目录里面有自带的python解释器,有的教程就是利用这个单独创建环境,但在这里我们利用environments-wsl2.yaml创建conda环境
conda env create -f environment-wsl2.yaml
然后激活环境
conda activate automatic
这里的automatic其实就是这个webui作者的github名字.
重点(配置一些文件)
接下来就是很多教程有差别的地方了,在实际运行项目中,我发现下载的torch实际上是cpu版本的,也许跟我镜像源设置有关.
首先看一下脚本流程
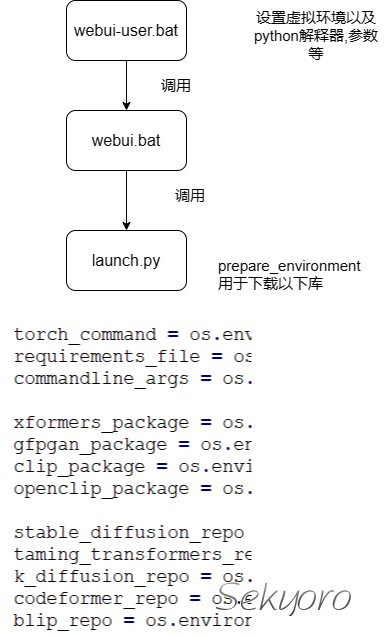
可以修改webui-user.bat中内容,设置虚拟环境中的解析器和虚拟环境文件夹,也就是包下载的文件夹.
@echo off
set PYTHON=D:\anaconda\envs\automatic\python.exe
set GIT=
set VENV_DIR=D:\anaconda\envs\automatic
set COMMANDLINE_ARGS=--medvram --autolaunch --opt-split-attention --force-enable-xformers --xformers
call webui.bat
COMMANDLINE_ARGS用于设置参数,这里启动xformers提升图像质量.
之后修改launch.py,主要修改下载的位置,从原本的github修改为ghproxy.
torch_command = os.environ.get('TORCH_COMMAND', "pip install torch==1.13.1+cu117 torchvision==0.14.1+cu117 --extra-index-url https://download.pytorch.org/whl/cu117")
requirements_file = os.environ.get('REQS_FILE', "requirements_versions.txt")
commandline_args = os.environ.get('COMMANDLINE_ARGS', "")
xformers_package = os.environ.get('XFORMERS_PACKAGE', 'xformers==0.0.16rc425')
gfpgan_package = os.environ.get('GFPGAN_PACKAGE', "git+https://ghproxy.com/https://github.com/TencentARC/GFPGAN.git@8d2447a2d918f8eba5a4a01463fd48e45126a379")
clip_package = os.environ.get('CLIP_PACKAGE', "git+https://ghproxy.com/https://github.com/openai/CLIP.git@d50d76daa670286dd6cacf3bcd80b5e4823fc8e1")
openclip_package = os.environ.get('OPENCLIP_PACKAGE', "git+https://ghproxy.com/https://github.com/mlfoundations/open_clip.git@bb6e834e9c70d9c27d0dc3ecedeebeaeb1ffad6b")
stable_diffusion_repo = os.environ.get('STABLE_DIFFUSION_REPO', "https://ghproxy.com/https://github.com/Stability-AI/stablediffusion.git")
taming_transformers_repo = os.environ.get('TAMING_TRANSFORMERS_REPO', "https://ghproxy.com/https://github.com/CompVis/taming-transformers.git")
k_diffusion_repo = os.environ.get('K_DIFFUSION_REPO', 'https://ghproxy.com/https://github.com/crowsonkb/k-diffusion.git')
codeformer_repo = os.environ.get('CODEFORMER_REPO', 'https://ghproxy.com/https://github.com/sczhou/CodeFormer.git')
blip_repo = os.environ.get('BLIP_REPO', 'https://ghproxy.com/https://github.com/salesforce/BLIP.git')
然后运行webui-user.bat脚本,这里可能涉及网络问题
./webui-user.bat

下载完毕
模型与扩展
主要网站是Hugging Face – The AI community building the future.和Civitai | Stable Diffusion models, embeddings, hypernetworks and more
一般使用的就是stable diffusion v2.1的模型.动漫风的有anything和Momok
由于一些模型这里不太好放出,可以到我的网站或点击查看原文看详情
下载的模型放入一般都放入stable-diffusion-webui\models\
大模型
大模型特指标准的latent-diffusion模型。拥有完整的TextEncoder、U-Net、VAE。
由于想要训练一个大模型非常困难,需要极高的显卡算力,所以更多的人选择去训练小型模型。
CKPT
CKPT格式的全称为CheckPoint(检查点),完整模型的常见格式,模型体积较大,一般单个模型的大小在7GB左右。
小模型
小模型一般都是截取大模型的某一特定部分,虽然不如大模型能力那样完整,但是小而精,因为训练的方向各为明确,所以在生成特定内容的情况下,效果更佳。
VAE
全称:VAE全称Variational autoencoder。变分自编码器,负责将潜空间的数据转换为正常图像。
后缀格式:后缀一般为.pt格式。
功能描述:类似于滤镜一样的东西,他会影响出图的画面的色彩和某些极其微小的细节。大模型本身里面自带 VAE ,但是并不是所有大模型都适合使用VAE,VAE最好搭配指定的模型,避免出现反效果,降低生成质量。
使用方法:设置 -> Stable-Diffusion -> 模型的 VAE (SD VAE),在该选项框内选择VAE模型。
文件位置:该模型一般放置在*\stable-diffusion-webui\models\VAE目录内。
Embedding
常见格式为pt、png、webp格式,文件体积一般只有几KB。
风格模型,即只针对一个风格或一个主题,并将其作为一个模块在生成画作时使用对应TAG在Prompt进行调用。
使用方法:例如本站用数百张海绵宝宝训练了一个Embedding模型,然后将该模型命名为HMBaby,在使用AI绘图时加载名称为HMBaby的Embedding模型,在使用Promat时加入HMBaby的Tag关键字,SD将会自动调用该模型参与AI创作。
文件位置:该模型一般放置在*\stable-diffusion-webui\embeddings目录内。
Hypernetwork
一般为.pt后缀格式,大小一般在几十兆左右。这种模型的可自定义的参数非常之多。
使用方法:使用方法:在SD的文生图或图生图界面内的生成按钮下,可以看到一个红色的图标,该图标名为Show extra networks(显示额外网络),点击该红色图标将会在本页弹出一个面板,在该面板中可以看到Hypernetwork选项卡。
文件位置:该模型一般放置在*\stable-diffusion-webui\models\hypernetworks目录内。
LoRA
LoRA的模型分两种,一种是基础模型,一种是变体。
目前最新版本的Stable-diffusion-WebUI原生支持Lora模型库,非常方便使用。
使用方法:在SD的文生图或图生图界面内的生成按钮下,可以看到一个红色的图标,该图标名为Show extra networks(显示额外网络),点击该红色图标将会在本页弹出一个面板,在该面板中可以看到Lora选项卡,在该选项卡中可以自由选择Lora模型,点击想要使用的模型将会自动在Prompt文本框中插入该Lora模型的Tag名称。
基础模型
名称一般为chilloutmix*,后缀可能为safetensors或CKPT。
基础模型存放位置:*\stable-diffusion-webui\models\Stable-diffusion目录内。
变体模型
变体模型存放位置:*\stable-diffusion-webui\models\Lora目录内。
文件位置:该模型一般放置在*\stable-diffusion-webui\models\Stable-diffusion目录内。
插件
在Extensons中点击Available,然后点击load from.去掉localization即可搜索到语言支持.

- 首先下载中文支持,下载后在设置中搜索localization

选择zh-Hans然后再Apply settings,reload UI即可.

- 后面可以下载ControlNet等等,这里就不用示范了
遇到的问题
由于我一开始参照了很多教程,碰了一些壁.导致配置环境时出现很多问题.这里写一下遇到的问题.
- 如果遇到是N卡而且能使用CUDA但却提示不可用,可能是下载到了cpu版本的torch
所以这里推荐先下载对应的的torch以及torchvision. 比如这里我下载1.13版本支持gpu的torch.
(这里下载这个版本是因为为了和后面xformer库匹配) cuda版本11.7
pip install torch==1.13.1+cu117 torchvision==0.14.1+cu117 torchaudio==0.13.1 --extra-index-url https://download.pytorch.org/whl/cu117
如果你要下载其他版本可以在pytorch官网上查看Previous PyTorch Versions | PyTorch
-
我下载时如果遇到卡住情况会尝试使用代理.有时可以开启TUN模式更好下载.
-
再次测试时发现我下载的torch竟然是1.12版本的,这跟
launch.py中不太一致,怀疑是后面被覆盖下载了.所以再运行一次pip install torch==1.13.1+cu117 torchvision==0.14.1+cu117 --extra-index-url https://download.pytorch.org/whl/cu117 -

pip直接没了,怀疑是覆盖安装时出现了问题.
执行命令
python -m ensurepip --upgrade
- 下载插件时,有时也会出现连不上下载不了的情况.应该是连接github的问题
大致总结
- 一个是网络问题,建议使用代理
- 我推荐一定要在
launch.py中修改下载地址,也就是修改github - 后续会更新一些扩展使用以及lora,contrtolnet模型使用,欢迎关注
欢迎在个人网站:www.proanimer.com查看原文
个人博客:www.sekyoro.top
参考资料
- 从画笔到像素:一文读懂AI绘画的前世与今生
- DALL·E—从文本到图像,超现实主义的图像生成器
- hua1995116/awesome-ai-painting: AI绘画资料合集(包含国内外可使用平台、使用教程、参数教程、部署教程、业界新闻等等) stable diffusion tutorial、disco diffusion tutorial、 AI Platform (github.com)
- DALL·E (openai.com)
- Image Generation - NovelAI Documentation
- AI繪圖:Windows安裝Stable Diffusion WebUI教學 | Ivon的部落格 (ivonblog.com)
- 使用Anaconda对Stable-Diffusion进行环境隔离本地化部署 - 哔哩哔哩 (bilibili.com)
- AI绘画 xformers安装疑问解答 - 哔哩哔哩 (bilibili.com)
- Stable Diffusion 模型格式及其相关知识全面指南 - openAI
- 最细Stable Diffusion2.1+WebUI的安装部署教程(非大佬整合包,Revirsion) - 哔哩哔哩 (bilibili.com)
- 本地化部署Stable Diffusion WebUI - openAI
















 3109
3109

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











