






机器学习是一个比较广阔的知识领域,涉及到很多数学统计和计算机的相关知识。 要想深入了解,需要系统学习和大量的时间。 但是如果我们很清楚地知道机器学习如果用一句话来概括就是:通过大量的训练,使得机器把输入的数据整理出有用的知识输出,这种输出或者是分类或者是回归。分类问题是要预测类别,回归问题是要预测值。
如下图,训练数据集输入给训练模型,模型达到一定的准确率后,可以进行测试,把测试数据输入给模型,得到预期要得到的结果。

所以,如果我们要了解机器学习,主要就是要了解中间的训练环节,也就是机器学习的训练模型。这部分才是机器学习的核心。如果我们对训练模型有一定地了解了。我们可以从我们要处理的实际问题出发,采用相依的训练模型,来做机器学习的应用,得到我们想要的结果。我们就能回答机器到底能学习什么和如何学习的问题。
下面我们将详细讲述如下机器学习训练模型,也叫做训练方法: 二元分类,多元分类,打分,排名,概率预测,树模型,规则模型,线性模型,基于距离的模型,概率模型,梯度下降,多项式回归,正则化线性回归,逻辑回归,支持向量机,决策树,集成学习,随即森林,深度神经网络,卷积神经网络,递归神经网路,强化学习,偏好学习,多任务学习,在线学习。这些模型有的只用于分类,有的只用于回归,也有的既能用于分类还能用于回归。
二元分类(binary classification),是机器学习里比较早就应用的学习模型,比较著名的应用就是垃圾邮件分类识别。 二元分类一般分为正例(positive)和反例(negative)。其他还有医疗诊断和信用卡欺诈识别。分出垃圾邮件和特殊疾病的类都是正例类别(positive class)。一个简单的分类方法就是训练集上,做出一个特征树,把每个特征树的叶子上各个类别的数量标出来,选择大多数的类别,作为这个叶子的类别。这样特征树就变成了决策树。
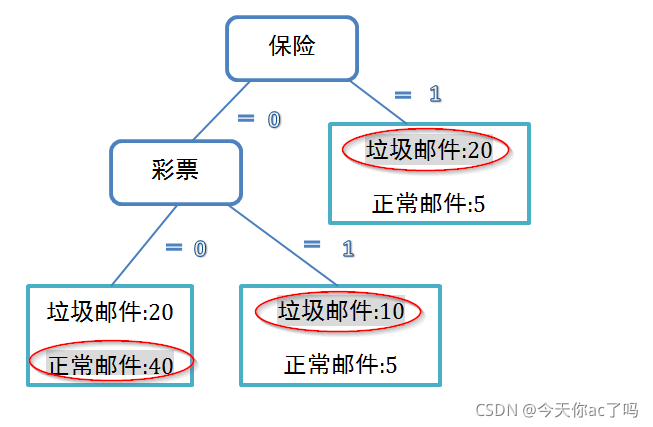
如上图一所示,找出一批邮件,作为训练集,垃圾邮件有20封 出现保险字样,正常邮件有5封出现保险字样,在没有保险字样的邮件里,出现彩票字样的垃圾邮件有10封,正常邮件有5封。没有出现保险和彩票字样的邮件,垃圾邮件有20封,正常邮件有40封。所以每个叶子节点,取大多数类别的值 画圈所示,就得到了一棵决策树。也可以用其他方法得到各种情况的概率大小,取概率的的类别作为最后的类别。这样,我们就可以用这个决策树去判断测试集,得到测试集的数据分类。比如我们拿一些未知的邮件,这些邮件就是测试集,去按照这个决策树的条件去判断每一封测试集的邮件,最后得出每个邮件是不是垃圾邮件。
二元分类模型不止是决策树,还有线性模型等等,都可以把现有数据分成两类。
了解了二元分类的过程,我们可以扩展到多元分类(multi-class classification),顾名思义就是分类不止是两类,而是多类。如果你有一个二元分类模型,比如线性模型,有很多方法可以把他们变成K 类分类器。一对多模式(one-versus-rest) ,训练K 个二元分类器,第一份分类器,把类一 C1 从其他类里分出来,第二个分类器把类二 C2 从其他类里分出来,如此继续。当我们训练第i 类时,我们把第i类 Ci的所有实例,当作正例,其他类都是反例。比方说,分第一类时,只把第一类作为正例,其他作为反例,找到第一类。还有一对一模式(one-versus-one), 在这种模式下,训练k(k-1)/2个二元分类器,每对不同的类只训练一次。
当实现一个神经网络的时候,我们需要知道一些非常重要的技术和技巧。例如有一个包含个样本的训练集,你很可能习惯于用一个for循环来遍历训练集中的每个样本,但是当实现一个神经网络的时候,我们通常不直接使用for循环来遍历整个训练集,所以在这周的课程中你将学会如何处理训练集。
另外在神经网络的计算中,通常先有一个叫做前向暂停(forward pause)或叫做前向传播(foward propagation)的步骤,接着有一个叫做反向暂停(backward pause) 或叫做反向传播(backward propagation)的步骤。所以这周我也会向你介绍为什么神经网络的训练过程可以分为前向传播和反向传播两个独立的部分。
在课程中我将使用逻辑回归(logistic regression)来传达这些想法,以使大家能够更加容易地理解这些概念。即使你之前了解过逻辑回归,我认为这里还是有些新的、有趣的东西等着你去发现和了解,所以现在开始进入正题。
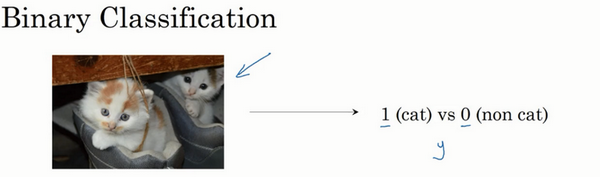
逻辑回归是一个用于二分类(binary classification)的算法。首先我们从一个问题开始说起,这里有一个二分类问题的例子,假如你有一张图片作为输入,比如这只猫,如果识别这张图片为猫,则输出标签1作为结果;如果识别出不是猫,那么输出标签0作为结果。现在我们可以用字母 y来 表示输出的结果标签,如下图所示:

















 4318
4318

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









