






Relu激活函数导致 [ 神经元死亡 ] 的原因
神经网络接受异于常值范围的输入时,在反向传播过程中会产生大的梯度。这种大的梯度,会因梯度消失而永久关闭诸如 ReLU 的激活函数。
relu函数和sigmoid函数相比,虽然能够避免反向传播过程中的梯度消失、屏蔽负值、防止梯度饱和;
但是relu也有自身的缺陷,当学习率过大时会出现某些神经元永久死亡的现象,导致网络后期无法正常更新
原因分析:
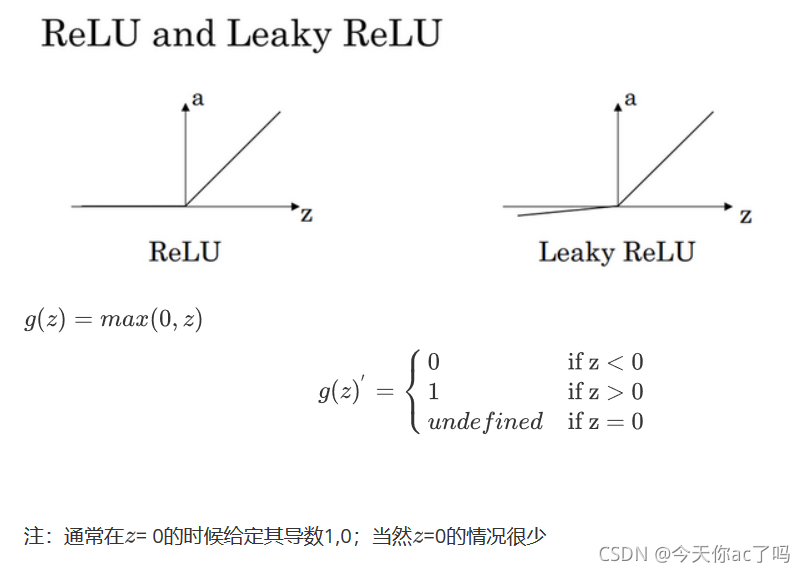
ReLU 的全称是 Rectified Linear Unit,其函数图像如下图所示
异常输入杀死神经元

上图是一个典型的神经元。
由于 ReLU 在 x>0x>0 时,导数恒为 1。因此在反向传播的过程中,不会因为导数连乘,而使得梯度特别小,以至于参数无法更新。在这个意义上,ReLU 确实避免了梯度消失问题。
下式是神经网络权重更新的公式,迭代就是不断重复做如图的公式:
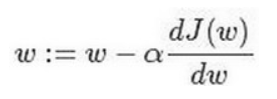
其中,
:= 表示更新参数,J(ω)为代价函数(成本函数);
α表示学习率(learning rate),用来控制步长(step),即向下走一步的长度![]() 就是函数J(ω)对 求导(derivative),在代码中我们会使用dw表示这个结果。
就是函数J(ω)对 求导(derivative),在代码中我们会使用dw表示这个结果。
当学习率过大时,会导致α*![]() 这一项很大,当 它大于ω时,更新后的ω’就会变为负值;
这一项很大,当 它大于ω时,更新后的ω’就会变为负值;
当权重参数变为负值时,输入网络的正值会和权重相乘后也会变为负值,负值通过ReLu后就会输出0;如果在后期有机会被更新为正值也不会出现大问题,但是当relu函数输出值为0时,relu的导数也为0,因此会导致后边Δω一直为0,进而导致ω一直不会被更新,因此会导致这个神经元永久性死亡(一直输出0)
如此看来,尽管 ReLU 解决了因激活函数导数的绝对值小于 1,在反向传播连乘的过程中迅速变小消失至 0 的问题,但由于它在输入为负的区段导数恒为零,而使得它对异常值特别敏感。这种异常值可能会使 ReLU 永久关闭,而杀死神经元。

















 2668
2668

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









