







文章目录
案例介绍 #
首先,此次案例是以油气开发为背景,选取加粗样式其中重要的两个参数含油饱和度和孔隙度分别作为此次案例的自变量和因变量进行试验。按照正常的案例分析步骤进行操作,此次为了凸显程序效果会加上许多绘图效果。
数据预处理 #
导入Python库与所需数据集:
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
import seaborn as sns
data = pd.read_excel(r"xxx\xx\x.xlsx")
查看数据集:
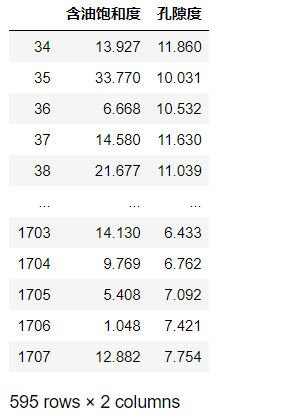
data

提取目标数据并删除空值行:
targetCol = data.loc[:, ['含油饱和度','孔隙度']];#提取目标的列
dealTargetCol = targetCol.dropna(axis=0, how='any')#删除空值行
查看目标数据:
dealTargetCol
函数拟合仿真 #
查看目标数据集的分布状态:
#解决中文乱码
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus']=False
#查看目标数据的分布情况
plt.figure(figsize=(12,4))
plt.subplot(121)
sns.distplot(dealTargetCol['含油饱和度'])
plt.subplot(122)
sns.distplot(dealTargetCol['孔隙度'])
plt.show()
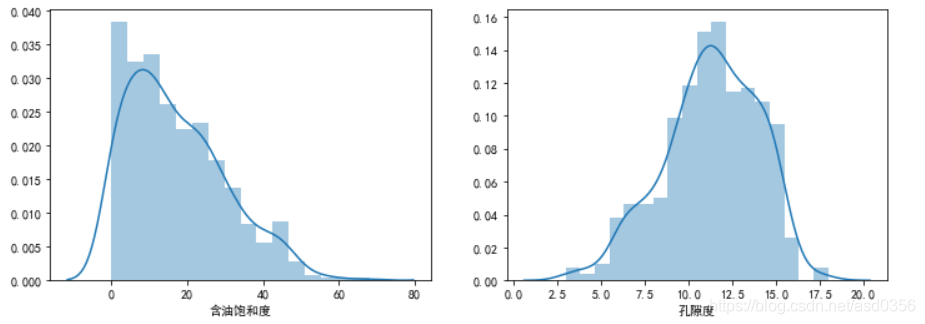
有图可见,孔隙度数据呈近似正态分布而含油饱和度数据有轻微的偏态分布,此处对于含油饱和度数据应该再给与一定的数值处理使其分布较为平衡一些,此处为了简便我就没处理。
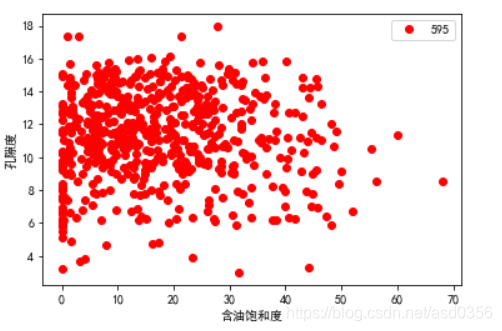
绘制目标数据之间的散点图:
plt.plot(dealTargetCol['含油饱和度'],dealTargetCol['孔隙度'],'ro',label=len(dealTargetCol['含油饱和度']))
plt.xlabel('含油饱和度')
plt.ylabel('孔隙度')
plt.legend()
plt.show()
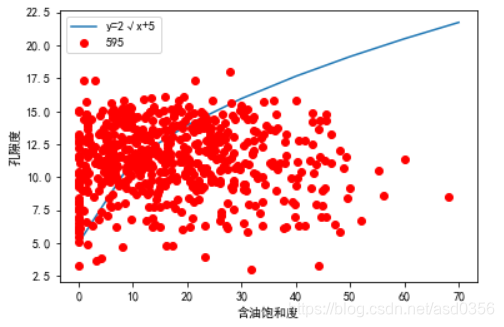
进行函数拟合:
SVR建模 #
划分数据集:
#划分数据集X和Y
X=dealTargetCol.iloc[:,:-1]
Y=dealTargetCol.iloc[:,-1]
分割测试集与训练集:
from sklearn.model_selection import train_test_split
#分割数据集的函数,test_siz用于决定训练集与测试集的分割比例,random_state表示按指定的数值来获取指定的随机分配
Xtrain, Xtest, Ytrain, Ytest = train_test_split(X,Y,test_size=0.2,random_state=42)
#恢复分割后的索引
for i in [Xtrain, Xtest, Ytrain, Ytest]:
i.index = range(i.shape[0])
定义绘制建模曲线函数:
#绘制建模曲线
def svr_results(y_test, X_test, fitted_svr_model):
print("C: {}".format(fitted_svr_model.C))
print("gamma: {}".format(fitted_svr_model.gamma))
print("Epsilon: {}".format(fitted_svr_model.epsilon))
perc_within_eps = 100*np.sum(y_test - fitted_svr_model.predict(X_test) < eps) / len(y_test)
print("Percentage within Epsilon = {:,.2f}%".format(perc_within_eps))
plt.figure(figsize=(10,7))
plt.scatter(x=dealTargetCol['含油饱和度'], y=dealTargetCol['孔隙度'],label="非支持向量")
plt.plot(Xtrain.take(fitted_svr_model.support_,axis = 0),Ytrain.take(fitted_svr_model.support_,axis = 0),'ro',label="支持向量")
plt.plot(X_test, fitted_svr_model.predict(X_test), color='red',label="预测函数")
plt.plot(X_test, fitted_svr_model.predict(X_test)+eps, color='black',label="预测边界函数")
plt.plot(X_test, fitted_svr_model.predict(X_test)-eps, color='black')
plt.xlabel('含油饱和度')
plt.ylabel('孔隙度')
plt.title('SVR Prediction')
plt.legend()
plt.show()
SVR建模:
from sklearn.svm import SVR
kernels = ['linear','poly','rbf','sigmoid']
eps = 3
for kernel in kernels:
svr = SVR(kernel=kernel,epsilon=eps, C=1.0,gamma=0.1).fit(Xtrain,Ytrain)
Ypredict = svr.predict(Xtest)
print("kernel: {}".format(kernel))
svr_results(Ytest, Xtest, svr)
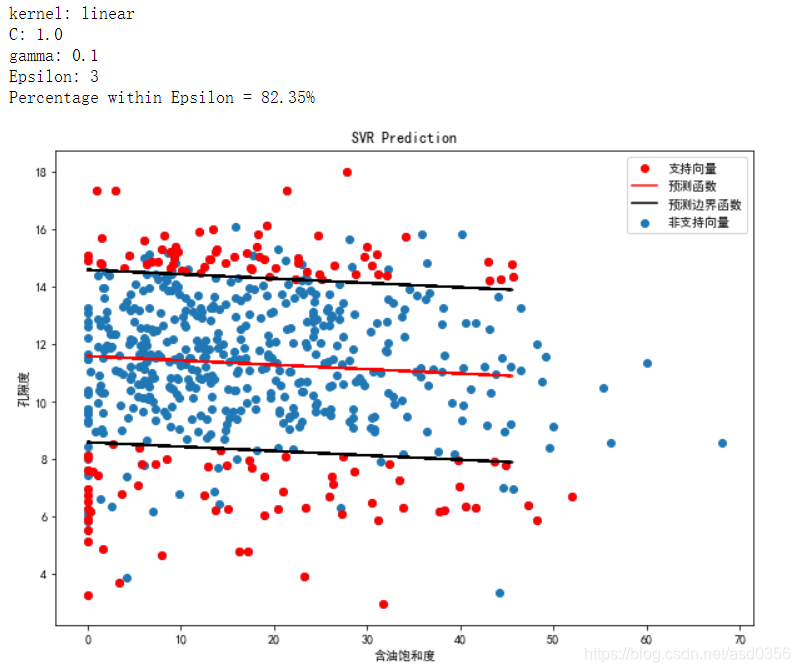
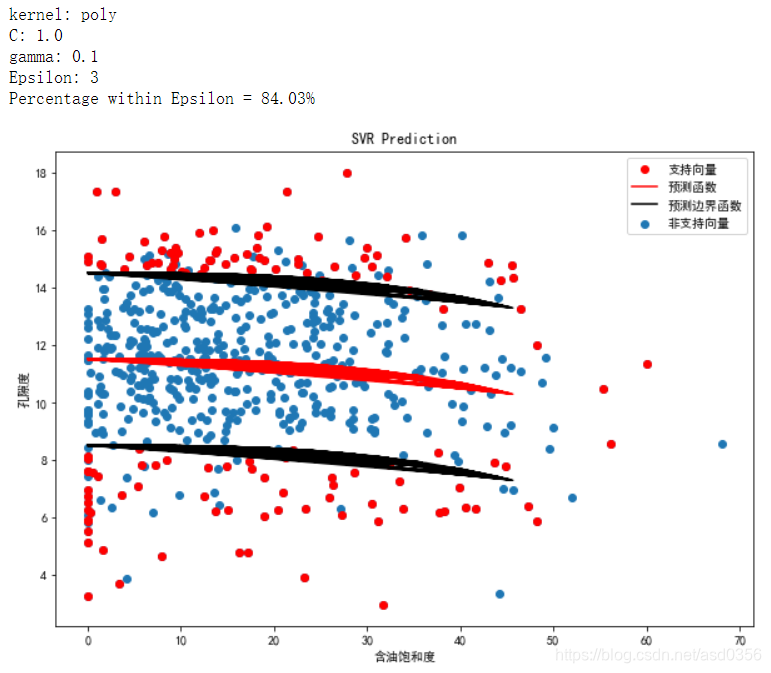
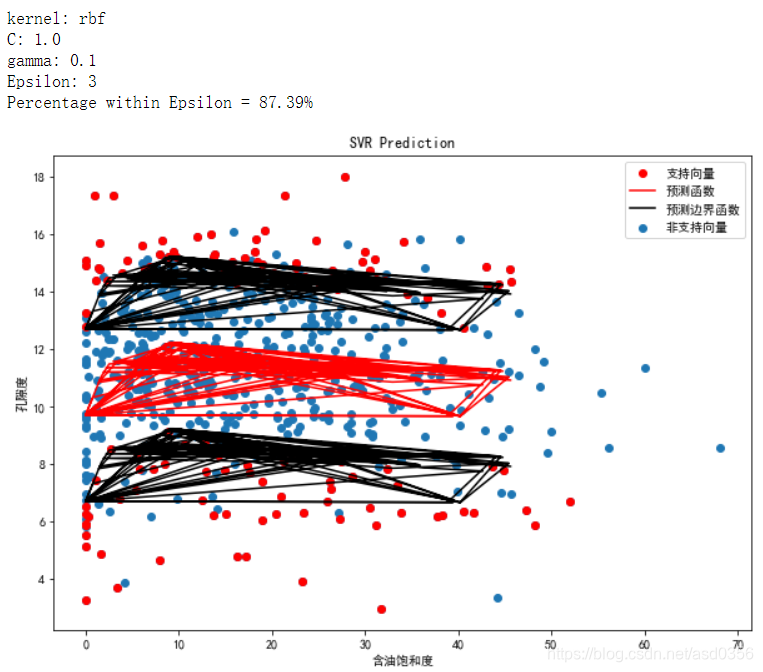
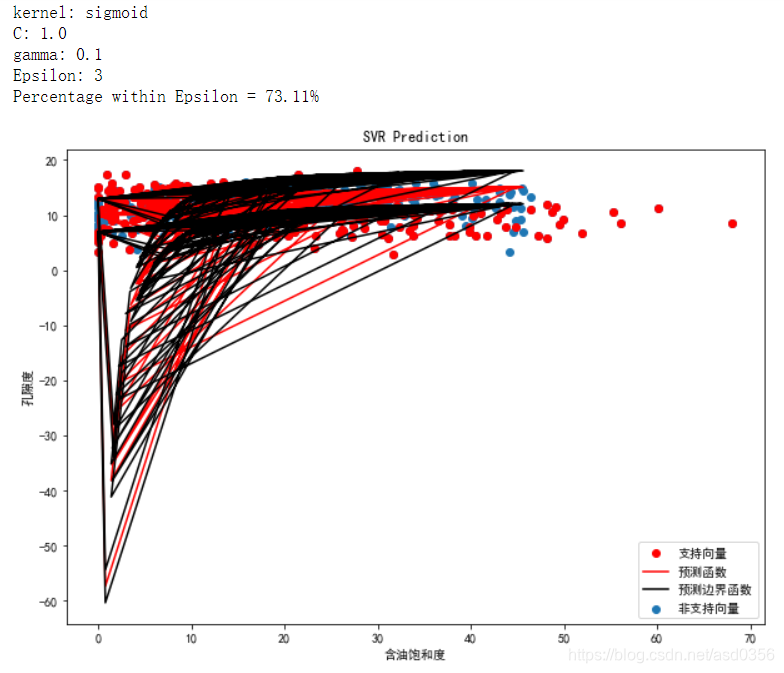
其实这里的有些绘制图形应该用三维图形来展示视觉效果应该会更好,这里我也略过,有兴趣的伙伴可以自己尝试着玩玩。
模型调参 #
由上图不难看出在同等参数的情况下,核函数rbf的表现最为优异,所以我们将以rbf为核函数内核进行进一步模型调参来寻找最优的参数C和参数gamma。
注:我的上述理论没有严格的正确性,所以为了确保数据的绝对可靠性,可以再把另外三个核函数的最优参数的情况也一律寻找出来。
寻找最优参数C:
import math
# C_range = np.logspace(-1,0,100)
C_range = np.linspace(0.01,100,1000)
max_perc = 0.8
predicts = []
for c in C_range:
svr = SVR(kernel='rbf',epsilon=3,gamma=0.1,C=c).fit(Xtrain,Ytrain)#gramma无影响
perc_within_eps = 100*np.sum(Ytest - svr.predict(Xtest) < 3) / len(Ytest)
max_perc = max(max_perc,perc_within_eps)
predicts.append(perc_within_eps)
print("Max percentage within Epsilon = {:,.2f}%".format(max_perc))
plt.figure()
plt.plot(C_range,predicts,c="blue")
plt.xlabel('c')
plt.ylabel('predict')
plt.show()
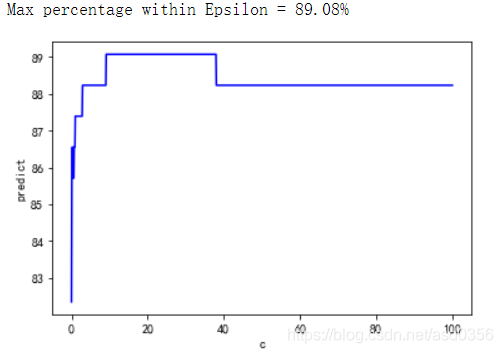
由上图不难看出20就是其中的一个最优参数C值。
寻找最优参数gamma:
# gamma_range = np.logspace(-2,0,1000)
gamma_range = np.linspace(0.01,10,1000)
max_perc = 0.8
predicts = []
for gamma in gamma_range:
svr = SVR(kernel='rbf',epsilon=3,gamma=gamma,C=20).fit(Xtrain,Ytrain)
perc_within_eps = 100*np.sum(Ytest - svr.predict(Xtest) < 3) / len(Ytest)
max_perc = max(max_perc,perc_within_eps)
predicts.append(perc_within_eps)
print("Max percentage within Epsilon = {:,.2f}%".format(max_perc))
plt.figure()
plt.plot(gamma_range,predicts,c="red")
plt.xlabel('gamma')
plt.ylabel('predict')
plt.show()
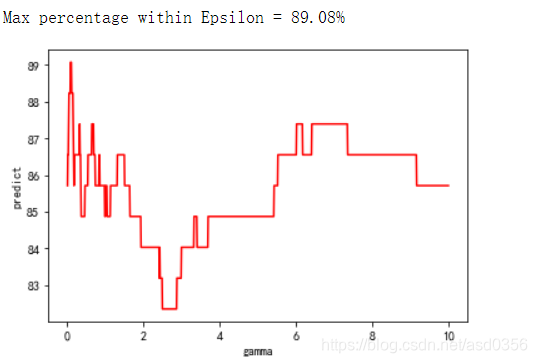
由图可见,最优的gamma值就是最初的默认gamma值–0.1。
到此,此次SVR案例就完整结束,此实验的操作还是很粗糙有很多细节可以优化,希望我所列出的部分能对大家会有所帮助吧。

















 5366
5366

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









