






随着Transformer已经成为大多数深度学习模型的基座,针对Transformer模型的性能优化便屡见不鲜。
今天我们就来分享下基于GPU硬件对attention的优化技术——flashAttention。
虽然现在网上有很多关于flashAttention的解析文章,但大多是看下来都是一个调调,所以今天就用小白的视角通过通俗易懂的例子和代码来解释下flashAttention吧。
不懂transformer原理的可以参考这两篇文章:
Tim在路上:手把手教你了解Transformer —Part 1
https://zhuanlan.zhihu.com/p/643798823
Tim在路上:手把手教你了解Transformer —Part 2
https://zhuanlan.zhihu.com/p/645250967
为什么要优化Transformer?
为什么我们要对Transformer进行加速,换句话说Transformer时间复杂度如何,有什么缺点呢?
虽然目前Transformer已经成为深度学习领域最广泛的架构,但由于其固有的O(N^2) 复杂度和内存限制的键值缓存,在推理过程中表现出次优效率。
这种低效率使它们的实际部署变得复杂,特别是对于长序列来说,这就是大模型在发展的初期其输入输出往往只支持2K或4K token原因。
即使是到目前为止,GPT最长支持32K token长度,Claude最长有100K token的模型版本,然而这与现实的需求是不一致的。
如果大模型要达到人类的高度,就需要从听觉、视觉、触觉多方面获取信息,这就需要更多或者是无限的输入token。
然而现实是不尽人意的,下图是常见大模型在较长token上的指标表现情况图示:
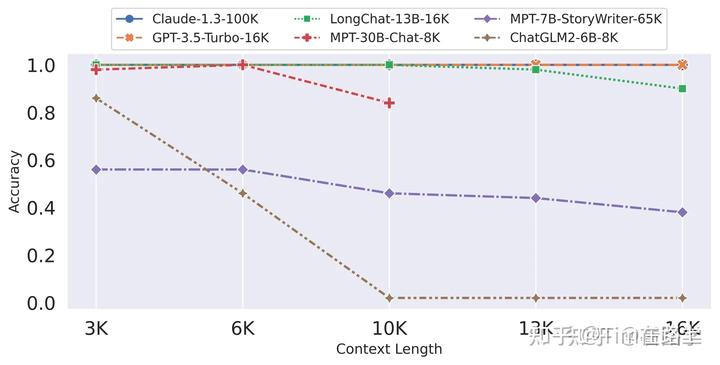
可以看出当前开源大模型在对长token的处理上基本处于躺平状态。
基于Transformer的大模型不能处理长token的本质原因是,Transformer的计算复杂度和空间复杂度随序列长度N呈二次方增长。
例如,如果要将序列长度N翻倍成为4N,我们所需的资源会变为16倍,即将序列长度扩展N倍,所需付出的计算和内存资源要扩大了约N^2倍,当然这里只是近似比喻。
下面我们分析下Attention的计算复杂度:
假设我们有一个长度为 N 的输入序列,每个位置都用一个d维向量表示。那么,查询矩阵 Q 的维度是 N×d,键矩阵 K 和值矩阵 V 的维度也是 N×d;
具体来说,Attention 的计算过程可以分为以下几个步骤:
-
线性变换:对输入序列进行线性变换,得到 Q、K、V 三个矩阵。假设每个 token 的 embedding 维度为 k,则该步骤的复杂度为 O(n * k * 3d)。
-
计算相似度得分:通过 Q、K 两个矩阵计算相似度得分,得到注意力权重矩阵。注意力权重矩阵的大小为 n * n,计算该矩阵的时间复杂度为 O(n^2 * d * h)。
-
加权求和:将注意力权重矩阵与 V 矩阵相乘并加权求和,得到最终输出。该步骤的复杂度为 O(n * d * h)。
因此,Attention 的总计算复杂度为 O(n^2 * d * h),约为O(n^2)时间复杂度。
flashAttention加速的基础
flashAtention其加速的原理是非常简单的,也是最基础和常见的系统性能优化的手段,即通过利用更高速的上层存储计算单元,减少对低速更下层存储器的访问次数,来提升模型的训练性能。
我们都了解CPU的多级分层存储架构,其实GPU的存储架构也是类似的,遵守同样的规则,即内存越快,越昂贵,容量越小。
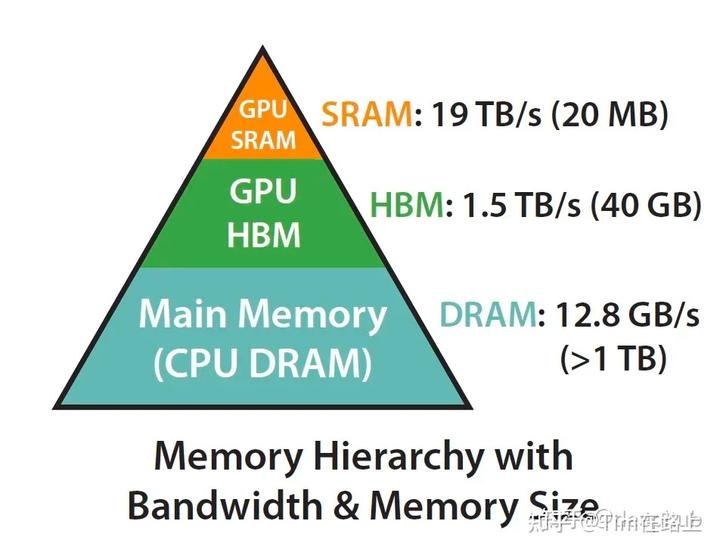
如上图所示,在A100 GPU有40-80GB的高带宽内存(HBM,它是由多个DRAM堆叠出来的),带宽为1.5-2.0 TB/s,而每108个流处理器(SM)有192KB的SRAM,带宽估计在19TB/s左右。
从上面的数字可以看出SRAM的访问速率是HBM的10倍左右,然而其能承载的数据量却远远小于HBM。
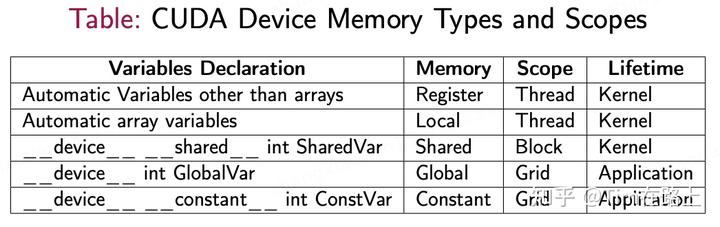
在GPU的编程架构中,最小的执行单元为warp(即为固定大小的线程束,一般为32个线程为一个warp,它们在同一个时钟周期内并行执行相同的指令),warp是SM中的调度单元,不同的warp在计算时会从SRAM中读取计算所需的数据(即共享存储寄存器)。
它对应的是编程架构中的block,一个SM可以包含多个Block,每个Block可以包含多个线程束Warp,但是Block不能跨SM。
当计算所依赖的数据量较大需要跨SM时访问时,则会从更下级的HBM存储器中拷贝数据进行计算。
它对应的是编程架构中的Grid,其能控制访问HBM显存。
可以说A100硬件的出现加速了flashAttention的实现。
虽然说flashAttention对Transformer加速的原理非常简单,然而在Transformer诞生的初期由于硬件上的一些限制,使得flashAttention并没有那么快的出现,直到A100 GPU架构的问世。
下面我们来梳理下安培架构或A100上的核心特性:
-
Ampere 架构采用了台积电 7nm 制程,其第三代 Tensor Core 增强了操作数共享并提高了效率。
-
更大更快的 L1 缓存和SRAM能够让它在每个流处理器(SM)上提供相当于 V100 1.5 倍的总容量(192 KB vs. 128 KB)。
-
A100 GPU 拥有 40 GB 的高速 HBM2 显存,与 Tesla V100 相比提升了 73%。
-
A100 GPU一种新的异步拷贝指令,可以直接从HBM拷贝到SRAM,这大大简化了数据拷贝过程,减少了延迟,并提高了整体性能。
-
A100 GPU 在SRAM中提供了硬件加速的 barrier,将 arrive 和 wait 操作分开,可将从HBM到SRAM的异步拷贝与 SM 中的计算穿插起来。
flashAttention 算法的逐行解释
我们都知道flashAttention是优化了计算过程中的访存(HBM)的过程,那么我们先来看下标准Attention的计算访存:

首先,从HBM中读取完整的Q和K矩阵(每个大小为N x d),计算点积得到相似度得分S(大小为N x N),需要进行O(Nd + N^2)次HBM访问。
其次,计算注意力权重P(大小为N x N)时,需要对S进行softmax操作,这需要进行O(N^2)次HBM访问。
最后,将注意力权重P和值向量V(每个大小为N x d)加权求和得到输出向量O(大小为N x d)时,需要进行O(Nd)次HBM访问。
因此,标准 Attention 算法的总HBM访问次数为O(Nd + N^2)。当N比较大时,总的HBM访问次数可能会比较昂贵。
从上面可以看出,标准Attention算法在GPU内存分级存储的架构下,存在以下缺陷:
-
过多对HBM的访问,如S、P需要在存入HMB后又立即被访问,HBM带宽较低,从而导致算法性能受限
-
S、P需要占用O(N^2)的存储空间,显存占用较高
基于之前的思路,我们可以有一个比较简单的实现方式:
-
之所以存在大量的访存HBM,一个原因是在Attention的计算中存在三个kernel,每个kernel的计算过程都存在从HBM读取数据,计算完成后还要写回HBM。如果我们将三个Kernel融合为一个,则就可以减少部分的访问HBM的次数。
-
在计算过程中要尽量的利用SRAM进行计算,避免访问HBM操作。
然而,我们都知道虽然SRAM的带宽较大,但其计算可存储的数据量较小。如果我们采取“分治”的策略将数据进行Tilling处理,放进SRAM中进行计算,由于SRAM较小,当sequence length较大时,sequence会被截断,从而导致标准的SoftMax无法正常工作。
那么flashAttention是如何进行实现的呢?
Flash attention基本上可以归结为两个主要点:
-
Tiling (在向前和向后传递时使用)-基本上将NxN softmax/scores矩阵分块成块。
-
Recomputation (重算,仅在向后传递中使用)
Tiling(平铺),其核心思想是将原始的注意力矩阵分解成更小的子矩阵,然后分别对这些子矩阵进行计算,只要这个子矩阵的大小可以在SRAM内存放,那么不就可以在计算过程中只访问SRAM了。
然而在Attention中softmax需要将所有的列耦合在一起计算,如何解决呢?
flashAttention提出了分块SoftMax算法,确保了整个Flash Attention的正确性,这也是整个flash attention的核心,下面我们会着重介绍。
Recomputation (重算)在深度学习优化中的老概念了,它是一种算力换内存的把戏,就是不要存储那么多梯度和每一层的正向传播的中间状态,而是在计算到反向某一层的时候再临时从头开始重算正向传播的中间状态。
下面为其主要的算法实现:

步骤一:计算分子块的大小
首先,我们需要获取GPU硬件SRAM的大小,我们假设为M。为了让Q、K、V在计算中可以存放在SRAM中,我们需要设定分块的大小尺寸。
其次,在SRAM上需要存在的数据包括,Q子块,K子块,V子块,其次还应包括计算过程中的中间输出O,O的大小应该与Q、K、V子块大小一致。
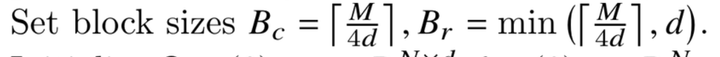
所以,在这里我们计算出子块的列大小Bc =[M/4d], d为矩阵维度。
当然,需要注意的是,上面的设置子块的大小并非唯一的,只有保证子块大小不超过SRAM的大小即可。
步骤二:初始化输出矩阵O
![]()
为SRAM上的输出O矩阵赋值为全0,它将作为一个累加器保存softmax的累积分母,l也类似。m用于记录每一行行最大分数,其初始化为-inf。
这一步属于细节问题,当然这块也是后续存在可优化的操作(见v2)。
步骤三:切分子块
按步骤一中的块大小将Q, K和V分成块。
同时将将O, l, m分割成块(与Q的块大小相同)。
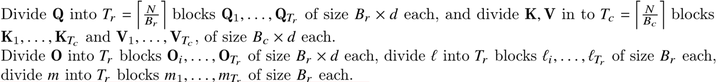
将Q划分成Tr个Bolck,K、V划分成Tc个Block,初始化 attention output O,并划分成Tr个Block。
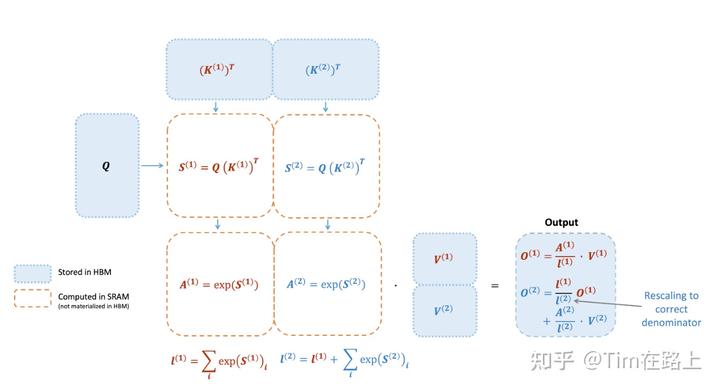
步骤四:外循环加载K、V内循环加载Q子块
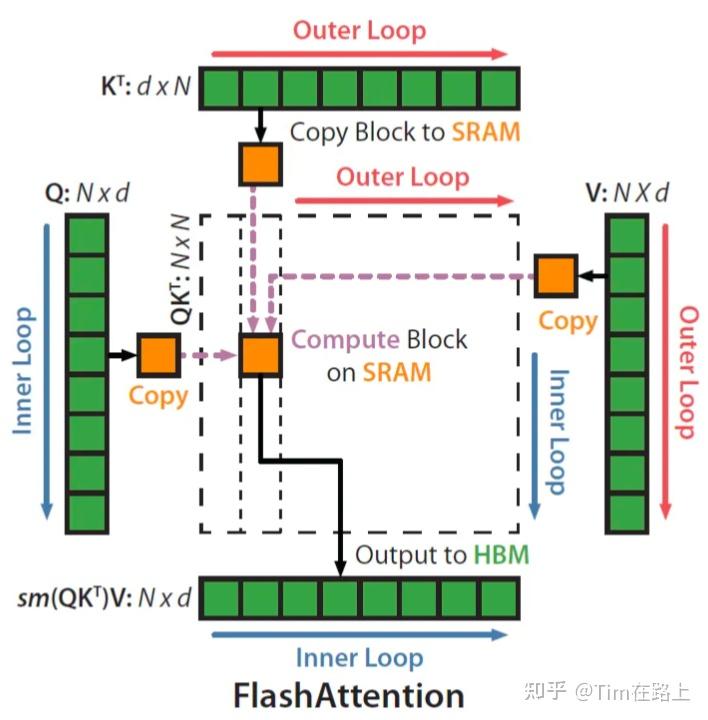
上图完美解释了这个循环过程,
-
外循环:对于每一个Block Key和Value,从HBM加载进SRAM
-
内循环:对于每个Block Query,Oi, li, mi,从HBM加载进SRAM
-
在SRAM上完成Block S的计算

这里要注意的是,Oi, li, mi其中存储的可能是上一个循环计算的中间结果。
步骤五:实现分块SoftMax算法
这里就要多扯一点了,从公式上看,这里和原来Attention SoftMax有些区别,不过本质上是一样的。
下面我们首先说明标准SoftMax是如何计算的?
对于向量[x1, x2, …, xd], 原生softmax的计算过程如下:
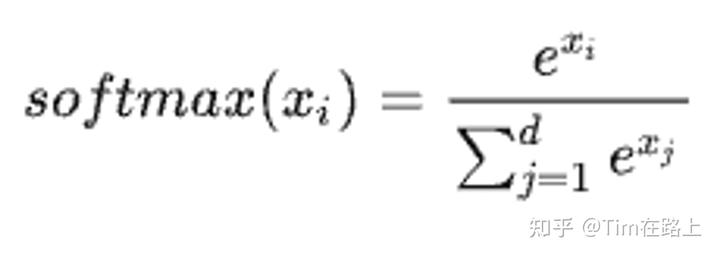
在实际硬件中,因为浮点数表示的范围是有限的,对于float32和bfloat16来说,当x≥89时,exp(x)就会变成inf,发生数据上溢的问题。
为了确保数值计算的稳定性,避免溢出问题,通常采用一种称为“safe softmax”的计算策略。在此方法中,通过减去最大值来缩放输入数据,以保证数值的相对稳定性。
所以说,现有所有的深度学习框架中都采用了“safe softmax”这种计算方式,其计算公式为如下。
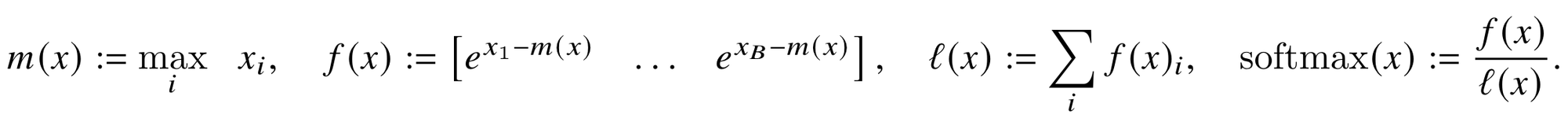
计算举例:
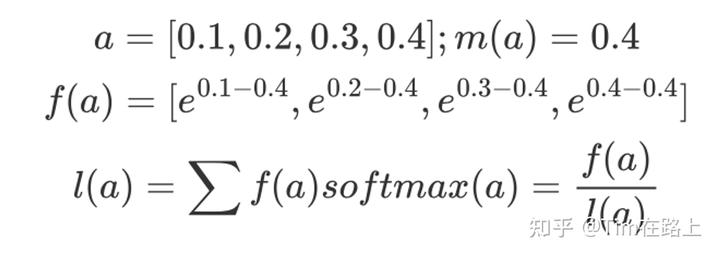
从上面可以看出,首先在分子上“safe softmax”需要获取当前区间的最大值来缩放输入数据,而在分母上需要累加所有的分子f(a)。
由于flashAttention已经采取了分块计算的策略,也就意味着在计算softmax时,并不能拿到所有数据列的最大值和全部f(a)的和。
那么flashAttention是如何实现分块softmax的呢?
虽然softmax与K的列是耦合的,但如果分开计算每个子块的softmax再将最后的结果进行收集转换是否可以等价呢?下面我们看看原版的证明公式:
-
假如有切片向量x = [x^(1), x^(2)],切片后softmax 的计算方式:

-
update m(x),根据更新后的m(x),根据上一步计算结果重新计算 f(x), l(x)。
假设存在x^(3), 那么便可以将x^(1)和x^(2)合并成一个序列,重复步骤1即可。
计算举例:

需要注意的是,可以利用GPU多线程同时并行计算多个block的softmax。
可见通过上述的转换可知,softmax与分块softmax是在数学上是等价的关系。不过由于真实计算中次数变多,精度上也可能存在一定丢失。
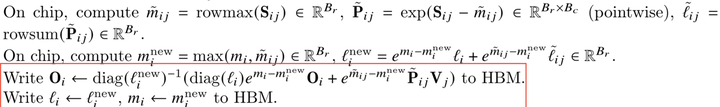
接下来,我们来看下上述代码到底做了什么?
首先,根据上一步计算的子块Sij,来计算当前块的行最大值mij,当前块Pij(即softmax的分子),lij为Pij的累积值。
其次,计算子块与子块间的最大值m^new 和多个子块的Pij的累积值l^new。
最后,根据softmax公式计算最终的softmax,经结果写到SRAM的Oi中,并写出到HBM, 同时将最后的最后的l^new赋值给li写出到HBM, m^new赋值到mi写出到HBM。
开始下一轮循环。
到此前向计算就算完成,我们可以通过下图来总结下flashAttention的前向计算过程,这里就不做过多解释了。
步骤六:反向计算
从上面的前向过程中,我们知道前向过程中只将Oi, li, mi写出到了HBM,并没有保存S和P。
那么反向的重算是如何实现的呢?
-
前向过程会保留Q,K,V,O, l, m在HBM中,dO由反向计算得倒后,按照前向相同的分块模式重新分块。
-
初始化dQ,dK,dV为全0矩阵,并按照对等Q,K,V的分割方式分割dQ,dK,dV。
-
分别从HBM中Load K V block on SRAM,再Load Q block on SRAM。根据前向过程重新计算对应block的S和P;按分块矩阵的方式分别计算对应梯度。
-
完成参数更新。
最终可以看到,在将三个kernel进行合并后,flashAttention v1实现了中间计算完全基于SRAM的目的。
当然这个过程中,仔细分析依然是存在一些可优化的点的,这也就是flashAttention v2和v3的工作了。
flashAttention性能分析
flashAttention是软硬一体优化的优秀案例,就像它严重依赖于GPU架构A100以上的硬件一样。
当然如果你的硬件和Nvidia架构类似可以通过算子重写适配到其他硬件上,但不得不说的是flashAttention算法是专为Nvidia硬件特点而设计的。
现在flashAttention很多实现利用率TensorCore和低精度进行绑定,再加上原来实现计算转换过程中的丢失,在精度上可能存在一定的损失。
那么FlashAttention到底节省了多少次访存次数呢?
我们来计算下:
首先,K,V (Nxd)的每个block都需要Load 进SRAM,因此该过程的HBM访问次数为O(Nxd)。
其次,Q也需要分block Load进SRAM,该过程一共持续外循环Tc次,因此该过程的HBM访问次数为O(TcNd)
最后,而Tc=N/(Bc)=4Nd/M(向上取整)。因此flash attention的HBM访问次数为O(N^2d^2/M)
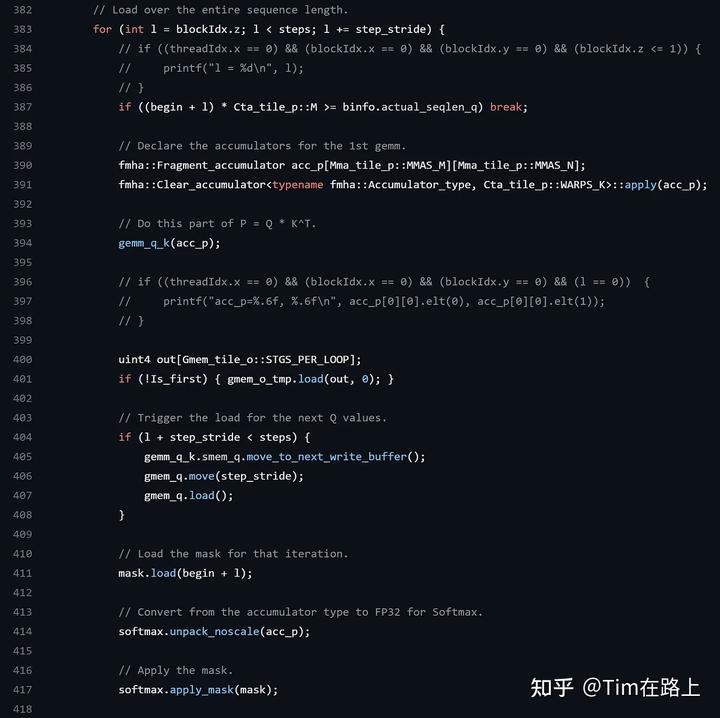
下面我们来看一段老版本的flashAttention的实现源码:
总结
针对当前普遍的以Transformer为基座的AI2.0时代,通过优化Transformer的性能就会带来一定普世的模型性能提升。
新硬件、新架构、新特性的发展,也为模型的性能优化提供了可能。例如,Nvidia H100已经抛弃了图像优化,专职提供高性能的AI训练,很多新的可定制的特性也应允而生。
高效的利用好新硬件新特性,实现软硬一体发展,也是模型性能提升的一个较好方向。
不过由于禁售的原因,未来国内这个方向可能机遇不大。
另外要说的一个点时,目前软件和硬件all in transformer的发展,其前提条件是transformer在未来5年内至少不可替代。
如果从基础模型上发生了较大的变化,那么不管是基于硬件Transformer Engine,还软件的Transformer大kernel优化,都将成为“水中捞月”。

















 4779
4779

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









