






介绍ULMFiT
ULMFiT,全称为Universal Language Model Fine-tuning,是一种用于对预训练的语言模型进行特定下游任务微调的方法。由Jeremy Howard和Sebastian Ruder在2018年开发,并在他们的研究论文中提出。ULMFiT通过展示在语言任务领域迁移学习的有效性,彻底改变了自然语言处理(NLP)的领域。
Transfer Learning is the process of using knowledge from a pre-trained model on one task to improve the performance of a model on a related task. In the case of ULMFiT, the pre-trained model is a language model that has been trained on a large dataset of text, such as Wikipedia or Yelp. This language model has learned to predict the next word in a sequence of words, given the context of the previous words. By fine-tuning this pre-trained language model on a specific downstream task, such as sentiment analysis or question answering, we can leverage the knowledge that the model has already learned about language to improve its performance on the new task.
One of the key benefits of ULMFiT is that it allows us to fine-tune a language model even if we only have a small amount of labeled data for the downstream task. This is because the pre-trained language model has already learned a lot about the structure and patterns of language, which it can then use to better understand the specific task we want it to perform.
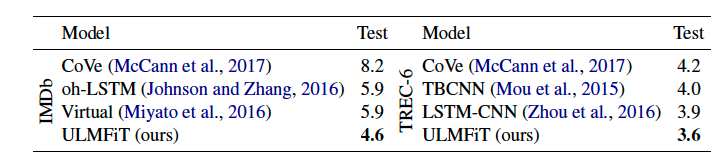
Test error rates(%) on IMDb & TREC-6 text classification datasets — Credit: Jeremy Howard and Sebastian Ruder
So, now let’s say you are a data scientist or machine learning engineer. You now want to apply ULMFiT in a practical way for your job or research and you have access to a limited amount of labeled data.
How can you practically apply ULMFiT?
I’ll break this down into four different steps:
Step 1 — Choose a pre-trained language model:
The first step is to choose a pre-trained language model that you will use as the basis for your fine-tuned model. The research paper uses the AWD-LSTM model.
The datasets used in the paper include very large text datasets such as IMDb, TREC-6, DBpedia. Yelp-bi, & AG.
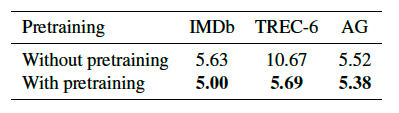
Error rates with and without pre-training — Credit: Jeremy Howard and Sebastian Ruder
Step 2 — Fine-tune the pre-trained model:
Once you have selected a pre-trained language model, you will need to fine-tune it for your downstream task. This involves adapting the model to the specific characteristics of the task, such as the type of input data and the desired output. This can be done using a process called “learning rate scheduling,” which involves gradually increasing the learning rate of the model as it adapts to the new task.
The “1cycle” Policy: The “1cycle” policy is another essential component of the ULMFiT fine-tuning process.
- 1cycle is a “rate scheduling technique that helps the model converge faster and achieve better performance.” The “1cycle” policy involves starting with a low learning rate, gradually increasing it to a maximum value, and then decreasing it back to the initial value during the training process. This approach enables the model to explore a wider range of learning rates, allowing it to escape suboptimal local minima & ultimately reach better solutions.
By incorporating discriminative fine-tuning and the “1cycle” policy into the learning rate scheduling process, ULMFiT effectively adapts the pre-trained language model to the downstream task, resulting in improved performance even with limited labeled data

Pre-training, fine-tuning, and classifier fine-tuning — Credit: Jeremy Howard and Sebastian Ruder
Step 3 — Evaluate the performance of the fine-tuned model:
After fine-tuning the pre-trained model, it’s important to evaluate its performance on the downstream task. This can be done using a variety of metrics, such as accuracy, precision, and recall.
& finally,
Step 4 — Fine-tune further and/or try different pre-trained models:
If the performance of the fine-tuned model is not satisfactory, you can try further fine-tuning the model or experimenting with different pre-trained models to see which one works best for your task.
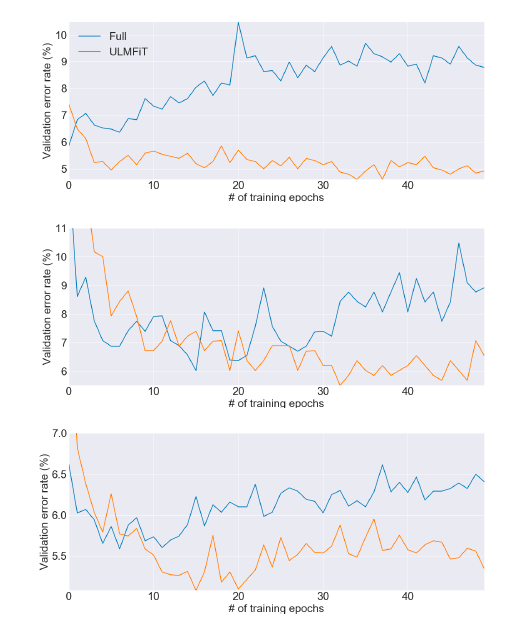
Validation error rate curves for fine-tuning the classifier with ULMFiT & ‘Full’ on IMDB, TREC-6, and AG. — Credit: Jeremy Howard and Sebastian Ruder
We can see from the figure above that ULMFiT is more stable compared to fine-tuning the full model and the performance remains similar through the various epochs.
Simple Code Example to Demonstrate ULMFiT
#Import libraries
from fastai.text import *
from fastai.callbacks import *
#Load the IMDb dataset
path = untar_data(URLs.IMDB_SAMPLE)
#Create a TextDataBunch for loading and pre-processing text data
data_lm = TextLMDataBunch.from_csv(path, 'texts.csv')
#Load a pre-trained language model
learn = language_model_learner(data_lm, AWD_LSTM, drop_mult=0.5)
#Fine-tune the lm using "1cycle" policy
learn.fit_one_cycle(1, 1e-2)
#Save fine-tuned language model
learn.save_encoder('ft_enc')
#Create a TextClasDataBunch for the downstream classification task
data_clas = TextClasDataBunch.from_csv(path, 'texts.csv', vocab=data_lm.train_ds.vocab, bs=32)
#Load fine-tuned language model for the classification task
learn = text_classifier_learner(data_clas, AWD_LSTM, drop_mult=0.5)
learn.load_encoder('ft_enc')
#Train the classifier using the "1cycle" policy
learn.fit_one_cycle(1, 1e-2)
#Save the fine-tuned classifier
learn.save('ft_clas')For a more detailed tutorial on implementing ULMFiT using fastai, you can refer to the official fastai documentation: Text classification with fastai.
Conclusion
Overall, ULMFiT is an incredible tool that harnesses the power of pre-trained language models to tackle a wide range of NLP tasks, even with limited labeled data.
So don’t be afraid to dive in yourself & explore the world of transfer learning with ULMFiT — you could even revolutionize the way you approach language problems in your work or research. Happy fine-tuning!

References: https://arxiv.org/abs/1801.06146 (Research paper by Jeremy Howard and Sebastian Ruder)
You can find my person research to code implementation of ULMFiT using a different dataset here -> https://github.com/ashley-ha/Language-Model-Classification-with-ULMFiT
As always, feedback is greatly appreciated! I am constantly working to improve my content and research and I love to collaborate. Please feel free to reach out to me at ashleyha@berkeley.edu or connect on LinkedIn https://www.linkedin.com/in/ashleyeastman/















 326
326

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









