






ColBERT使用了"延迟交互"来计算query与doc的相似度。具体来说,就是对query与doc分别编码之后,使用简单且有效的模块来评估相似度。
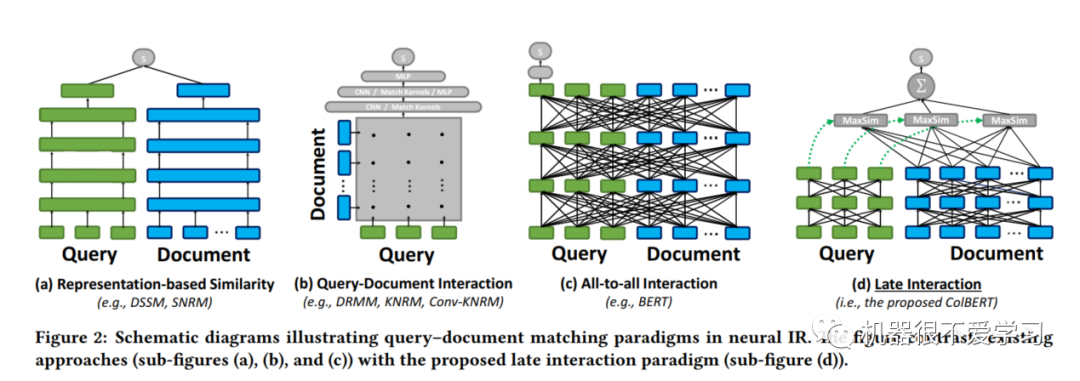
图2,为四种query-doc相似度计算的范式,依次说明下:
-
Representation-based Similarity:分别将query-doc使用编码器进行编码,得到两者表示向量之后,使用相似度计算函数,例如余弦距离,来算出query-doc相似分数。典型代表:DSSM、SRNM。
-
Query-Document Interaction:很明显上述模式的缺点是没有充分利用query与doc之间的交互(分别将query与doc独立编码)。因此便有了基于交互式的匹配模式,该模式使用CNN/MLP等对q与d的词、短语粒度的关系进行建模。比较简单的方式是为q与d生成一个交互矩阵,用来刻画q与d中词、短语的相似度。典型代表:DRMM、KNRM Conv-KNRM。
-
All-to-all Interaction:第三种模式是一种更为强大的交互,同时对q与d的token交互进行建模。典型代表:BERT。
-
Late Interaction:即本文使用的"延迟交互"模式,从图中可以明显看到,其实本质也是双塔结构,分别编码q与d,然后将编码之后的q、d向量表示,使用一些计算函数(例如MaxSim)分别再进行计算q与d之间的相互作用,刻画"粗粒度的token相似性"。
第四种模式,既可以用到PLM等强大的表示能力,又能降低编码doc的成本,工业应用时,使用向量检索工具,能够直接返回与query相关的top-k个doc结果,这也是很多公司在用的方法。
Architecture (模型结构)

如上图所示,ColBERT主要有三个模块:
-
query编码器:使用BERT完成query编码
-
doc编码器:使用BERT完成doc编码
-
延迟交互模块:使用余弦相似度计算每个q编码后的向量与d编码向量表示,最终进行相加
Query & Document Encoders
q与d共享一个BERT进行编码。
-
Query Encoder. 此处几个细节,好多强行翻译文章没有讲清楚。。。
-
作者在[CLS]之后拼接了[Q]再拼接query,[Q]来说明之后的句子为query。
-
另一个细节是,在padding时候,使用的是BERT词表中的[MASK],作者将其记为(query augmentation)query扩展,该部分可学习。
-
对于BERT输出的每个token表示,将其输入一个没有激活函数的线性层,将原始维度映射到m,m<<BERT embedding hidden size
-
最终使用L2 norm进行归一化,这样可以使得计算余弦距离时,将值域限制到[-1,1]
-
-
Document Encoder.
-
作者在[CLS]之后拼接了[D]再拼接doc,[D]来说明之后的句子为doc。
-
doc在padding时没有使用[MASK]进行拼接。
-
作者任务标点对于相似度计算意义不大,因此获取doc表示embdding时,过滤掉了标点embedding
-
最终表示如下:#代表[MASK]

3.3 Late Interaction
其实"延迟交互"还是比较简单的,利用余弦或者L2距离来进行计算q、d两个向量的相似度,取max再求和。
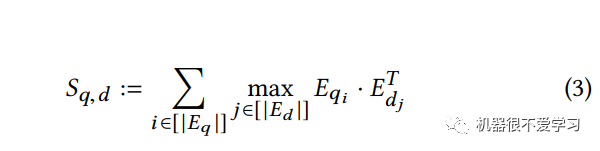
















 2143
2143

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









