







本文章是针对论文《2017-CVPR-DenseNet-Densely-Connected Convolutional Networks》中实验的复现,使用了几乎相同的超参数
目录
一、论文中的实验
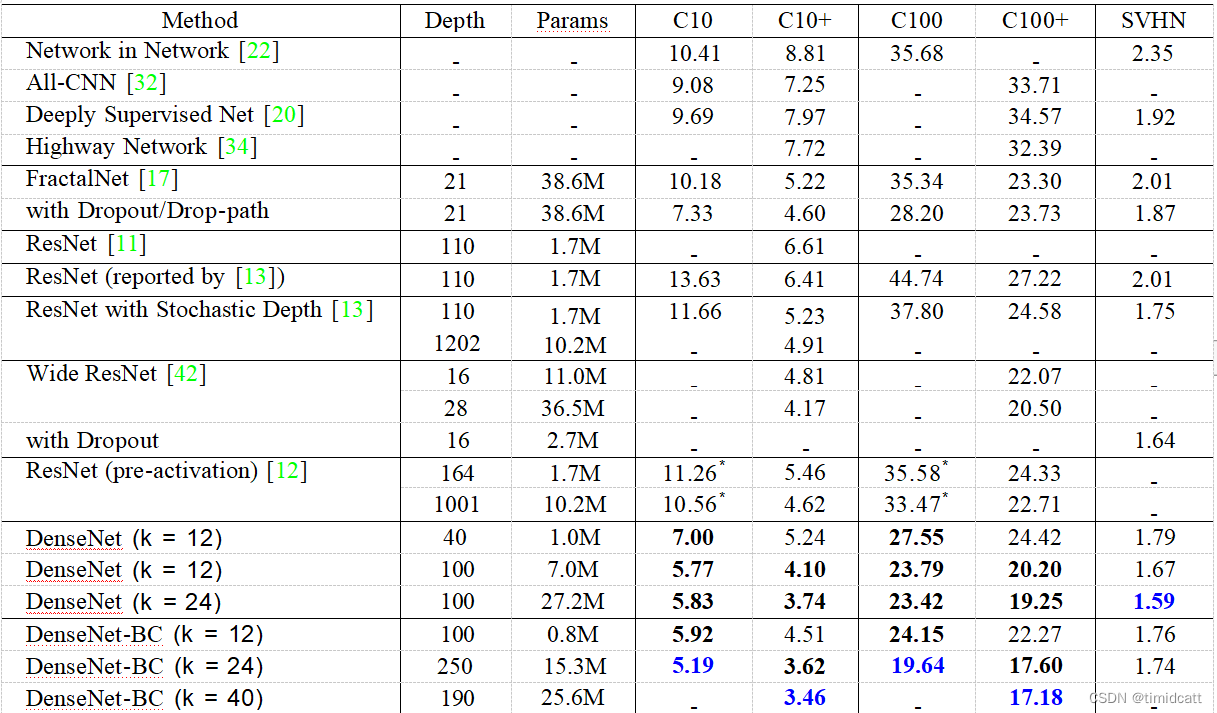
在源论文中,作者使用CIFAR10,CIFAR100和SVHN三个数据集上使用了一些包括DenseNet-BC(以下统称DenseNet)和ReNet的网络进行测试,最终的错误率如下:
1.增长率
增长率k指每个复合函数H()函数(即DenseNet的核心创新点)向总体状态输出的特征图的数量,总体状态在网络中的任何地方都可以访问到,所以增长率越高,总体状态越复杂,运算量越高,参数效率越低,越容易过拟合,一般选择较低的增长率就可以获得理想的结果,pytorch中成熟的DenseNet模型采用的k=12
2.准确率
在没有数据增强的情况下(此时额外加入dropout层),DenseNet的准确率显著超过了其他网络,可能来源于对过拟合的优化,在有数据增强的情况下,也有微弱优势
密集卷积网络精度提高的一个可能的解释是,通过更短的连接,每一层都可以根据损失函数的反馈调整其参数,从而使整个网络更加准确地捕捉数据中的特征
3.参数效率
Dense Block是直接concat来自不同层的特征图,这可以实现特征重用,同时DenseNet层非常窄(例如k=12时,相当于每一层有12个过滤器),只向网络的“集体知识”添加一小部分特征图,并保持其余的特征图不变
例如,上图中的250层模型只有15.3M参数,但它始终优于具有超过30M参数的FractalNet和宽残差网络等其他模型。所以在参数数量相等的情况下,DenseNet有更低的错误率,在达到相同错误率时,DenseNet只用了1/3的参数

4.计算效率

因为参数效率更高,所以要达到同样的错误率,DenseNet进行的浮点运算次数更少
5.过拟合
正如上文提到,在没有数据增强时的准确率要更高,体现了防止过拟合的能力。
对于没有瓶颈层的普通DenseNet,将k=12增加到k=24导致的参数数量为原来的4倍,同时错误率从5.77%小幅上升到5.83%。而DenseNet-BC避免了这种趋势,所以瓶颈层可能能够防止过拟合。(但是作者在提出这个观点时是不是没注意k=12的DenseNet-BC是250层的)

二、超参数:
#使用镜像加裁剪的数据增强,以及使用通道均值和标准差对数据进行归一化
transform_train = transforms.Compose([
transforms.RandomHorizontalFlip(),
transforms.RandomCrop(32, padding=4),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)),
])
#使用通道均值和标准差对数据进行归一化
transform_test = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)),
])#载入训练集50000张图片,batchsize=64
trainset = tv.datasets.CIFAR10(root='./data', train=True,
download=True, transform=transform_train)
trainloader = t.utils.data.DataLoader(trainset, batch_size=64,
shuffle=True, num_workers=0)
#载入测试集10000张图片
testset = tv.datasets.CIFAR10(root='./data', train=False, download=True, transform=transform_test)
testloader = t.utils.data.DataLoader(testset, batch_size=64,shuffle=False, num_workers=0)
#使用GPU训练
MyDevice = t.device("cuda:0" if t.cuda.is_available() else "cpu")# 权重初始化(本论文中直接引用的另一篇论文的权重初始化,这里也是直接拿过来用)
def weights_init(m):
classname = m.__class__.__name__
if classname.find('Conv') != -1:
nn.init.kaiming_normal_(m.weight)
elif classname.find('BatchNorm') != -1:
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
net.apply(weights_init)
net=net.to(MyDevice)#交叉熵损失函数
criterion = nn.CrossEntropyLoss()
#使用SGD优化,初始学习率为0.1,使用权重衰减为0.0001和0.9的Nesterov动量
optimizer = optim.SGD(net.parameters(), lr=0.1, momentum=0.9, weight_decay=1e-4)
#在训练周期为总周期的50%和75%时,学习率降低10倍
scheduler = MultiStepLR(optimizer, milestones=[20,30], gamma=0.1)三、网络结构
1.输入层
(conv0): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)
(norm0): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu0): ReLU(inplace=True)
(pool0): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
2.密集层
其中前三层为瓶颈层:
虽然每一层只产生k个输出特征图,但它通常有更多的输入。在每个3×3卷积之前引入一个1×1卷积可以作为瓶颈层,以减少输入的特征图数量,从而提高计算效率
(norm1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(64, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
后三层为复合函数H()
(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
3.过渡层
当特征图的大小发生变化时,复合函数H()中使用的拼接操作是不可行的,为了方便实现下采样,我们将网络分成多个密集连接的密集块。我们称块之间的层为过渡层,它们执行卷积和池化
(norm): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(pool): AvgPool2d(kernel_size=2, stride=2, padding=0)
4.输出层
(norm5):BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(classifier): Linear(in_features=1024, out_features=10, bias=True)
5.总结构
如下图,论文中给出了DenseNet的四中结构,
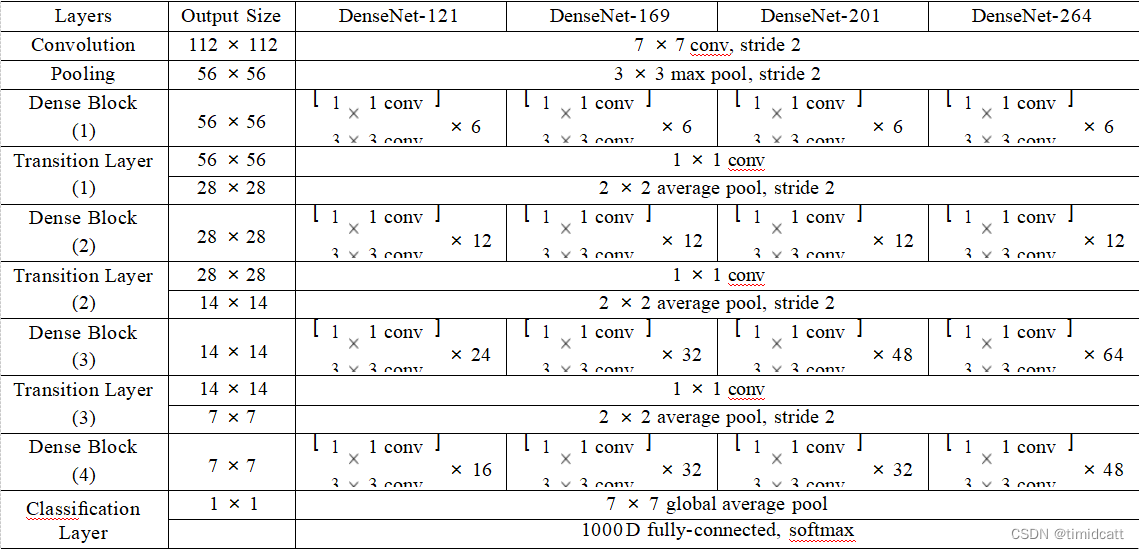
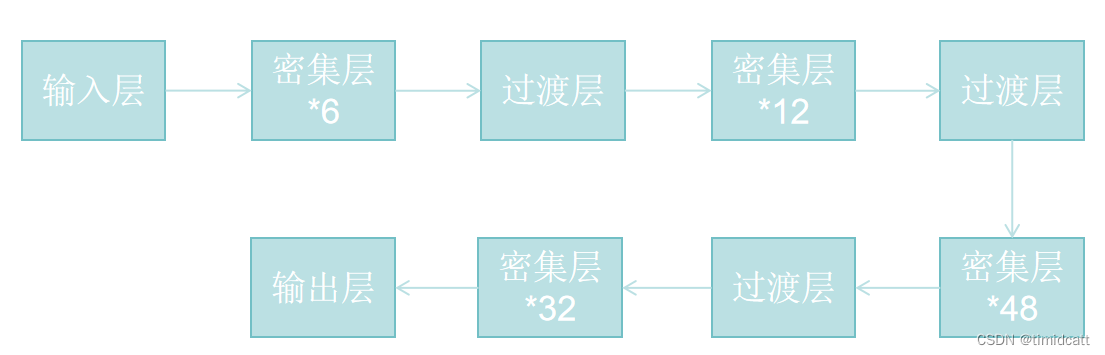
以DenseNet201为例,其具体结构为:
四、复现的实验结果:
我们首先分别使用121和201使用同样的超参数进行了测试:
1.DenseNet201 epoch=40:
#直接使用pytorch提供的网络
net = models.densenet121(pretrained=False,num_classes=10).to(MyDevice)
![]()

2.DenseNet121 epoch=40:
#直接使用pytorch提供的网络
net = models.densenet121(pretrained=False,num_classes=10).to(MyDevice)
![]()

可以很明显的看出201相比121的优势很明显
对于ResNet,我们同样使用了最简单ResNet18和较复杂的ResNet101:
3.ResNet18 epoch=40:
net = models.resnet18(pretrained=False,num_classes=10).to(MyDevice)![]()
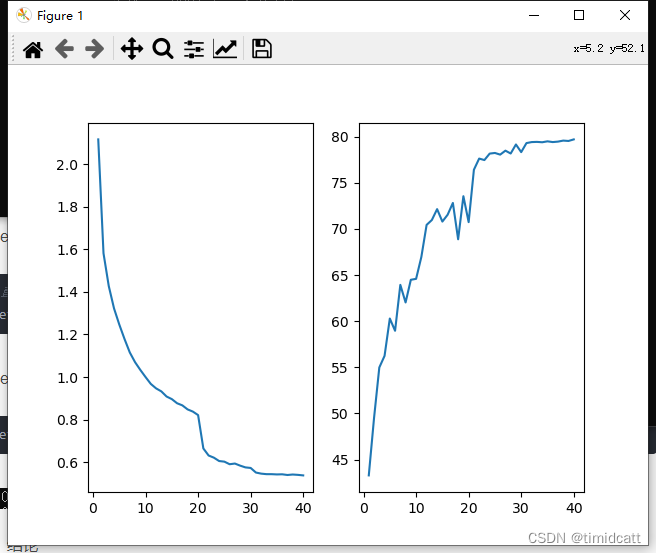
4.ResNet101 epoch=40:
net = models.resnet101(pretrained=False,num_classes=10).to(MyDevice)![]()

准确率极低,可能是过拟合或退化问题导致的
5.DenseNet201 epoch=300:
![]()
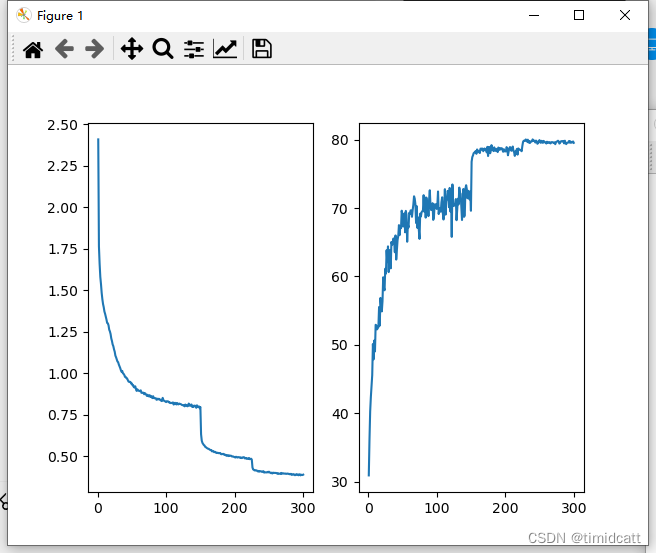
6.ResNet101 epoch=300:
![]()
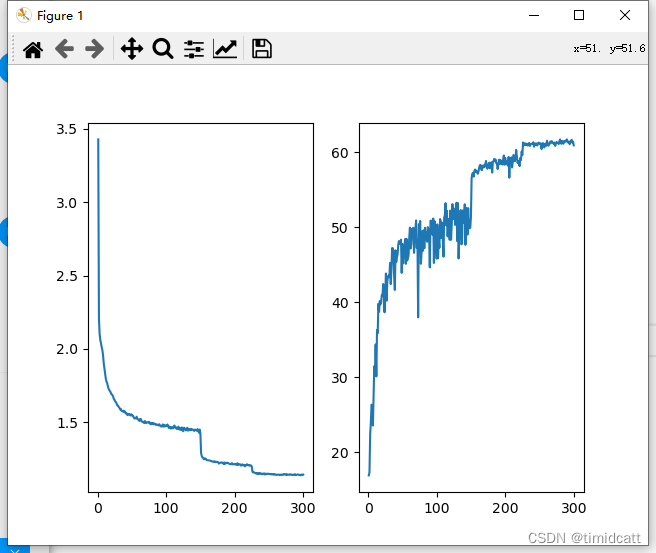
可以发现epoch=40和epoch=300的结果几乎相同,可能因为CIFAR10数据集比较小,容易过拟合,而相对来说,DenseNet确实更能防止过拟合
五、结果
1.准确率
复现的实验准确率与论文中的实验准确率存在差距,原因可能是仍有部分超参数不同,论文中有一些超参数时直接引用的其他论文,没有给出具体参数,比如“We adopt a standard data aug-mentation scheme (mirroring/shifting) that is widely used for these two datasets[11, 13, 17, 22, 28, 20, 32, 34]”,我们没有时间和能力去读额外的论文,所以采用了便于实现的镜像+裁剪来进行数据增强。在权重初始化和定义优化函数时也遇到了类似的问题,所以实验并不是100%复现
在复现的实现中,ResNet18和DenseNet201的准确率几乎一样,与论文中使用数据增强时的结果类似
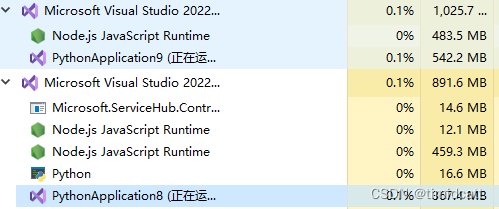
2.参数效率
DenseNet的参数效率确实比DenseNet,可以从运行时的程序内存占用大概看出来(PythonApplication9在运行ResNet18,PythonApplication8在运行DenseNet201)
3.过拟合
从上面ResNet101的结果可以看出,在使用相同超参数的情况下,ResNet很早就出现了损失下降二准确率没有提高的过拟合迹象,尤其在epoch=40时,即使学习率改变也没有改善,而DenseNet没有出现这种情况
4.计算效率
在进行epoch=300的复现实验时,两个网络是同时开始在同一设备上运行的,在任意相同时刻时,DenseNet达到的准确率都要更高,可以印证论文中的说法,但是在同epoch的情况下,DenseNet还是要慢的多的,训练的总计算量还是更多的

如图:左边是DenseNet201,右边是ResNet8
六、结论
1.论文的研究思路
这篇论文的研究思路感觉比较朴素,通过对一些流行的案例进行了分析,找出了他们的共同点,然后对这个的共同点进行放大,进行实验之后发现确实有一些优点,再根据实验结果去分析验证优点的原理,这种研究方法很通用
2.DenseNet vs ResNet
那么ResNet和DenseNet比到底哪个好呢,首先这两个网络最本质的区别就是一个是前者是,后者是
,然后后者最突出的效果就是特征复用,进而能一定程度上避免过拟合和提高参数效率。
所以针对CIFAR10这种很容易过拟合的小数据集,DenseNet能通过避免过拟合来最终提高准确率
而针对大的不容易过拟合的数据集,例如上面的SVHN,两者准确率就没有差距了,所以在大模型上的效果还有待验证
















 362
362

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











