







目录
1、数据集介绍
需要识别的数字已经使用图形处理软件,处理成具有相同的色彩和大小:宽高是32像素x32像素的黑白图像。尽管采用本文格式存储图像不能有效地利用内存空间,但是为了方便理解,我们将图片转换为文本格式。
详细数据介绍参看:KNN算法实现手写数字识别
2、代码实现
# -*- coding: UTF-8 -*-
import numpy as np
from os import listdir
from sklearn.svm import SVC
"""
将32x32的二进制图像转换为1x1024向量。
Parameters:
filename - 文件名
Returns:
returnVect - 返回的二进制图像的1x1024向量
"""
def img2vector(filename):
# 创建1x1024零向量
returnVect = np.zeros((1, 1024))
# 打开文件
fr = open(filename)
# 按行读取
for i in range(32):
# 读一行数据
lineStr = fr.readline()
# 每一行的前32个元素依次添加到returnVect中
for j in range(32):
returnVect[0, 32 * i + j] = int(lineStr[j])
# 返回转换后的1x1024向量
return returnVect
"""
手写数字分类测试
"""
def handwritingClassTest():
# 测试集的Labels
hwLabels = []
# 返回trainingDigits目录下的文件名
trainingFileList = listdir('trainingDigits')
# 返回文件夹下文件的个数
m = len(trainingFileList)
# 初始化训练的Mat矩阵,测试集
trainingMat = np.zeros((m, 1024))
# 从文件名中解析出训练集的类别
for i in range(m):
# 获得文件的名字
fileNameStr = trainingFileList[i]
# 获得分类的数字
classNumber = int(fileNameStr.split('_')[0])
# 将获得的类别添加到hwLabels中
hwLabels.append(classNumber)
# 将每一个文件的1x1024数据存储到trainingMat矩阵中
trainingMat[i, :] = img2vector('trainingDigits/%s' % (fileNameStr))
clf = SVC(C=200, kernel='rbf')
clf.fit(trainingMat, hwLabels)
# 返回testDigits目录下的文件列表
testFileList = listdir('testDigits')
# 错误检测计数
errorCount = 0.0
# 测试数据的数量
mTest = len(testFileList)
# 从文件中解析出测试集的类别并进行分类测试
for i in range(mTest):
# 获得文件的名字
fileNameStr = testFileList[i]
# 获得分类的数字
classNumber = int(fileNameStr.split('_')[0])
# 获得测试集的1x1024向量,用于训练
vectorUnderTest = img2vector('testDigits/%s' % (fileNameStr))
# 获得预测结果
# classifierResult = classify0(vectorUnderTest, trainingMat, hwLabels, 3)
classifierResult = clf.predict(vectorUnderTest)
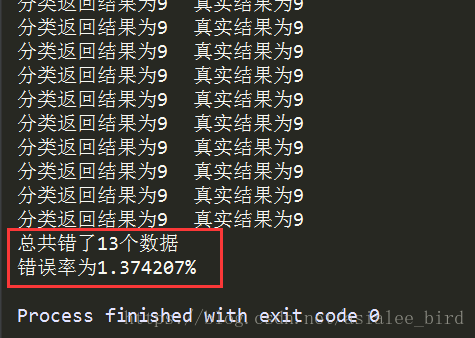
print("分类返回结果为%d\t真实结果为%d" % (classifierResult, classNumber))
if (classifierResult != classNumber):
errorCount += 1.0
print("总共错了%d个数据\n错误率为%f%%" % (errorCount, errorCount / mTest * 100))
if __name__ == '__main__':
handwritingClassTest()3、运行结果
4、普遍使用准则
n为特征数,m为训练样本数。
(1)如果相较于m而言,n要大许多,即训练集数据量不够支持我们训练一个复杂的非线性模型,我们选用逻辑回归模型或者不带核函数的支持向量机。
(2)如果n较小,而且m大小中等,例如n在1-1000 之间,而m在10-10000之间,使用高斯核函数的支持向量机。
(3)如果n较小,而m较大,例如n在1-1000之间,而m大于50000,则使用支持向量机会非常慢,解决方案是创造、增加更多的特征,然后使用逻辑回归或不带核函数的支持向量机。
值得一提的是,神经网络在以上三种情况下都可能会有较好的表现,但是训练神经网络可能非常慢,选择支持向量机的原因主要在于它的代价函数是凸函数,不存在局部最小值。
机器学习基础学习目录
1、机器学习入门总结
机器学习项目实战
本人博文NLP学习内容目录:
一、NLP基础学习
二、NLP项目实战
交流学习资料共享欢迎入群:955817470(群一),801295159(群二)


















 1259
1259

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











