






反代服务器取得内容缓存到本地,然后加速返回给客户端。
缓存命中率高 可以极大的缓解后端服务器压力。影响nginx
一般nginx作为负载均衡器,不会让nginx反向代理去缓存。而是让缓存服务器去缓存。
1.web服务
2.反代
3.伪四层

nat只负责转发过去
但是代理是转述 需要修饰的
nginx既要当成服务端接受用户请求
也要当成客户端去访问互联网
可以理解用户请求的具体信息
并且可以缓存到本地
代理需要监听在套接字上,并且理解这个协议。
代理就是双面人

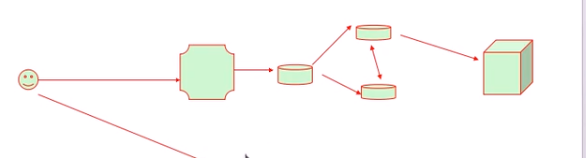
后端真实主机


 nginx代理服务器
nginx代理服务器


这个作为反向代理服务器
自己配置一个虚拟主机

自己不是web服务器 所以不需要root
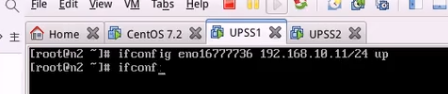
直接反代到后端主机
直接反代即可
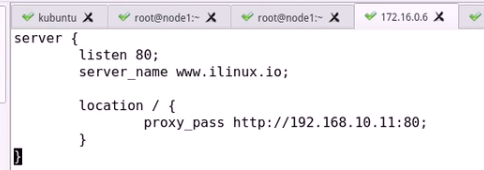
注意:如果后端代理有多个虚拟主机
proxy_pass就基于ip+端口+或者主机名



如果直接访问Ip就是代理服务器本身的


本机的包是从代理服务器发送过来的

在启动一个新的后端服务器

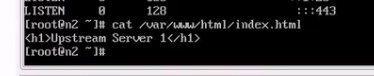
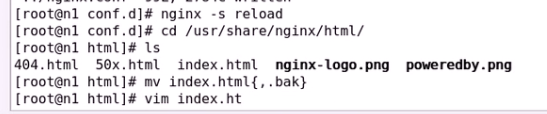
默认发布页面

这个缓存图片


希望图片到第二台服务器



网关联系不到后端服务器
可能是没有启动

有了这个功能 动静分离就没问题了


不加/意思是只要访问/下的比如/index.html就补充到80后面192.16.10.11/index.html

表示只是把/admin/和图片代理了

后端主机添加目录/admin/


就是把整个路径传到后面去了

添加/
以为访问/admin/的时候会替换为后端主机/下的内容

这种加不加没有区别

正则无法替换
如果在80后面加/就会nginx -t语法错误
ngx_http_proxy_module模块:
The ngx_http_proxy_module module allows passing requests to another server.
1、proxy_pass URL;
Context: location, if in location, limit_except
注意:proxy_pass后面的路径不带uri时,其会将location的uri传递给后端主机;
server {
...
server_name HOSTNAME;
location /uri/ {
proxy http://hos[:port];
}
...
}
http://HOSTNAME/uri --> http://host/uri
proxy_pass后面的路径是一个uri时,其会将location的uri替换为proxy_pass的uri;
server {
...
server_name HOSTNAME;
location /uri/ {
proxy http://host/new_uri/;
}
...
}
http://HOSTNAME/uri/ --> http://host/new_uri/
如果location定义其uri时使用了正则表达式的模式,或在if语句或limt_execept中使用proxy_pass指令,则proxy_pass之后必须不能使用uri; 用户请求时传递的uri将直接附加代理到的服务的之后;
server {
...
server_name HOSTNAME;
location ~|~* /uri/ {
proxy http://host;
}
...
}
http://HOSTNAME/uri/ --> http://host/uri/;
意思就是请求时什么 后面就必须时补在后面的而不是替换
一般用户访问后端知识服务器 代理服务器构建后发给后端服务器 后端真实服务器不知道是客户是谁
所以代理服务器可以修改报文首部 就是发往后端服务端的首部的值 添加客户首部IP
或者响应报文发给客户端的首部
2、proxy_set_header field value;
设定发往后端主机的请求报文的请求首部的值;Context: http, server, location
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; 实际用这个

后端抓包看包的首部信息

该日志格式


本来时%h也就是代理服务器的IP值
现在更换为上面定义的变量 就是客户端的IP
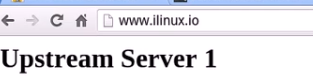
可以看到真正的客户端IP

ngx_http_headers_module模块
还可以更改代理服务器响应给客户端的时候
送给客户端的
ngx_http_headers_module模块
The ngx_http_headers_module module allows adding the “Expires” and “Cache-Control” header fields, and arbitrary fields, to a response header.
向由代理服务器响应给客户端的响应报文添加自定义首部,或修改指定首部的值;
1、add_header name value [always];
添加自定义首部;
add_header X-Via $server_addr;
add_header X-Accel $server_name;


代理还可以启动缓存进行加速哦~~

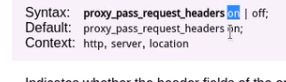
这个是代理服务器发送客户端报文允许哪些首部是可以发送过去的
代理还可以启动缓存进行加速哦~~
到后端取回来后放在本地磁盘
直接两个网络IO变成了一个磁盘IO

缓存还是文件路由哈希格式 更快 从右而左截取路由编码
找文件首先哈希 然后找很快 在内存哈希表
而后端真实的服务器还是遍历根目录
缓存空间需要先定义 哪个路径proxy_pass需要缓存 直接调用即可
只有get,head才需要缓存中查看 Post,put,delete不需要
shift+F5强刷 不读取缓存
服务器端也可以发送报文说不需要缓存
缓存空间有限
后端服务器宕机 缓存不新鲜了
nginx不是高档的 只有varnish才可以缓存的很得体 高效的缓存机制
nginx varnish装载同一台主机 解决网络IO延迟
nginx启动缓存功能
3、proxy_cache_path
定义可用于proxy功能的缓存;Context: http
proxy_cache_path path [levels=levels] [use_temp_path=on|off] keys_zone=name:size [inactive=time] [max_size=size] [manager_files=number] [manager_sleep=time] [manager_threshold=time] [loader_files=number] [loader_sleep=time] [loader_threshold=time] [purger=on|off] [purger_files=number] [purger_sleep=time] [purger_threshold=time];
4、proxy_cache zone | off;
指明要调用的缓存,或关闭缓存机制;Context: http, server, location
5、 proxy_cache_key string;
缓存中用于“键”的内容;
默认值:proxy_cache_key $scheme$proxy_host$request_uri;
6、proxy_cache_valid [code ...] time;
定义对特定响应码的响应内容的缓存时长;
定义在http{...}中;
proxy_cache_path /var/cache/nginx/proxy_cache levels=1:1:1 keys_zone=pxycache:20m max_size=1g;
定义在需要调用缓存功能的配置段,例如server{...};
proxy_cache pxycache;
proxy_cache_key $request_uri;
proxy_cache_valid 200 302 301 1h;
proxy_cache_valid any 1m;
放在http中 在默认配置中写
定义缓存路径(磁盘空间) levels顶级子目录级别 设置三级 每级16个 keys_zone内存分配多大空间 size 10M
max_size磁盘空间最多2g 其他默认

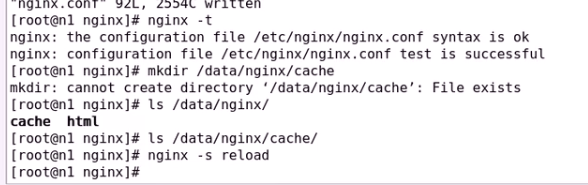
按需创建
调用缓存

调用缓存名字
定义缓存内容类型
以及定义缓存参数
proxy_cache_key定义缓存的Key 有默认的值
对那种方法调用缓存
最少时间缓存项访问次数
use_stale 对于后端服务器处于什么问题下缓存哪些内容什么情况下还可以使用


网页访问主页
这就是文件路由
 可以看到相应信息
可以看到相应信息

nginx也需要处理动态服务请求
nginx无法内建php模块
处理动态的页面只有fpm-server
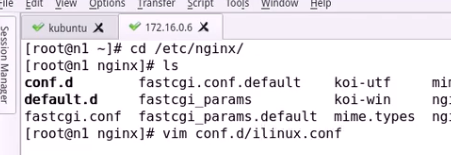
找一台主机运行fpm nginx反代给后端 基于fastcgi_module反代给后端fastcgi模块 作为客户端
而fast_proxy_pass则是作为http客户端
所以构建lnmp

所以这就是三级结构
本地 只要不是.php结尾
.php就是用fastcg协议i反代给后端 fpm-server
加载完毕运行结果响应给前端主机
需要基于驱动访问数据 基于mysql协议去访问Mysql server
lnmp
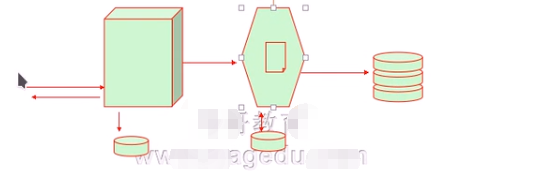
fcgi server 需要接受请求还要处理并发 还要运行压力很大
所以不如使用AP 代替 aapche工作模式 event preforx worker

但是Mysql读取数据很慢
也可以给数据库缓存 memcache 专门的缓存服务器 内存级别
基于内存缓存 支持的数据结构太简单 所以被redis碾压 还支持数据存储


还可以搞个动静分离 静态的专门去处理静态的页面
搭建lnmp
一台主机nginx 处理静态内容
php内容发送给fpm-server
一台主机安装apahce + php

php-fpm server + mysql
但是phpMY 有静态有动态 所以放在动态的主机也不容易配置

配置fpm-server
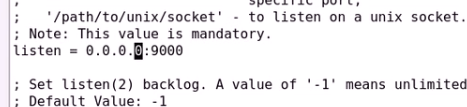
不然别的主机连接不进来了

允许所有连接

定义进程数
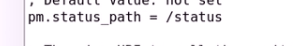
健康状态检测也启动

因为进程属组是apache

php需要文件保存会话 用户信息等
所以该文件用户也应该是apache

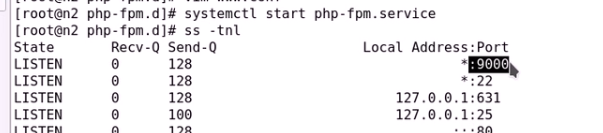
n1主机设置作为前端nginx
前面已经设置了很多

为了避免冲突

新建一个
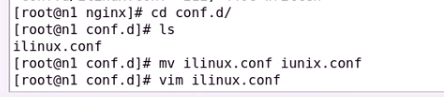
index设置主页
需要fastcgi_module作为客户端进行反代

前面说到作为代理服务器 代理服务器会隐藏很多客户端信息
但是[php服务器需要用户信息 生成对应的内容
所以有一文件用来可以展示给php的客户端信息
定义把什么参数传输给后端主机


脚本名称
当客户端请求一个脚本时候需要把脚本名称传递到后端

但是用户访问的脚本名字 fastcgi如何获取到该脚本呢 ?
所以需要有绝对路径 但是一般不在这个 文件中修改

分别是fastcgi自己的主页
脚本名称对应再fastcgi服务器下的脚本所在位置
Include表示其他的变量从xx文件获取
 第一个location就是静态内容
第一个location就是静态内容
第二个location就是动态内容 表示.php都转发
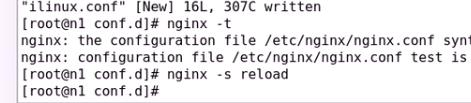

fpm主机p
献给nginx配置静态页面


通过php连接mysql
php主机
vim /etc/my.cnf.d/server.cnf





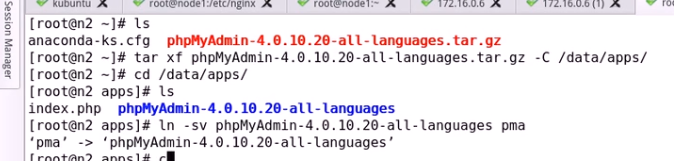

 随机数
随机数

不是.php结尾
所以访问index.php 就是主页 但是没有图片 因为是静态内容
所以拷贝到nginx主机上


同样放到默认的根页面下

所以正常 这也就意味着资源包括静态和动态的话都需要一份

因为动静分离了 数据库用户root 密码就是安全设置设置的那个

继续优化 nginx不处理静态内容 全部proxy_pass给一个专门处理静态页面的服务器
继续添加主机



更改默认的根



报错了 查看进程发现httpd服务启动着



前端主机配置




可以看到请求了各种各样的图片文件

当然了fastcgi还可以启动缓存优化

指定路径下 几级优化
客户端压测一下 随便找一个另外的主机 172.16.0.67


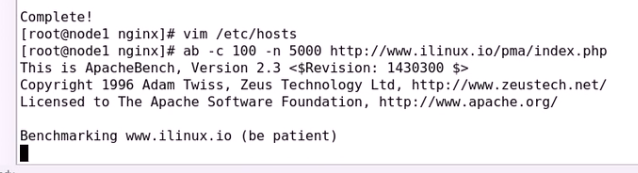
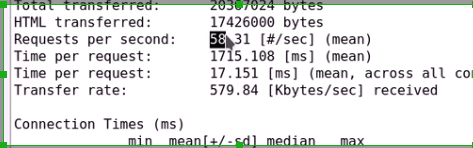
压测非常慢非常慢
因为是动态页面
所以尝试fastcgi的缓存功能

在http上下文添加
 需要进行调用
需要进行调用



先curl生成缓存



查看还是没有缓存生成内容
可能生成私有信息
先注释掉缓存


对默认页面缓存

启动缓存


速度大大提高
10、fastcgi_keep_conn on | off;
请求的时候保持连接打开


可以发现速度还是提升了



因为http协议和fastcgi协议并不完全兼容,所以很多变量的值向后方传递需要重新赋值
都可以实现缓存 1.定义缓存 2.调用缓存

主要就是讲解了两个反代模块
nginx实现七层负载upstream实战
nginx工作在strem模块下就可以负载均衡四层的 其实就是stream下的upstream负载均衡tcp.udp协议请求的
nginx七层是工作在http的upstream模块 http的upstream负载http请求 上有主机的方式
stream本身是反代 想要负载均衡就需要upsteam
haproxy既可以负载均衡也可以代理

如果后端是两台动态服务器
用户请求分发到另外一台主机之前的会话也没有了
所以可以会话粘性:
根据用户自身浏览行为 动态服务器本身可以会话缓存
一旦负载均衡
同一用户轮询 之前的会话信息就没有了
解决
1.会话粘性 lvs: sh算法 或者persistence 基于源地址实现的
2.对应应用层可以基于cookie绑定
但是一台服务器宕机了,session丢失
3.应该客户端无状态请求 会话集群 所有后端主机额外做集群
高性能的存储专门存储session 最好是内存级别的(memcache,redis)
连接后端存储主机实现数据的增删改查
memcache一旦宕机数据就没有了
redis可以持久
但是还是单点

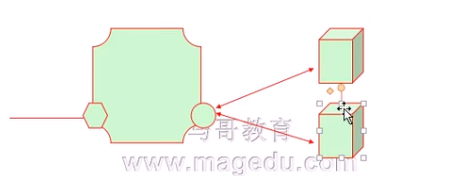
nginx是虚拟主机 访问不同的资源去后端不同的主机 静态资源去静态资源服务器 动态资源去动态资源服务器
但是如果后端有2个静态/动态资源服务器呢???? 可以在nginx的upstream定义为一组服务器
所以反向代理的时候可以指向一组 组自己有自己的挑选算法(类似于lvs)

一个虚拟主机的不同的location对应不同的组
web负载均衡集群

nginx的upstrem模块自带健康检查功能,后端主机故障可以自动摘除~
但是nginx又单点了 所以可以加上keepalibed
server在http中是虚拟主机,在upstream中是后端真实主机





前端主机

先前的配置先备份一下,先配置简单的


这是虚拟主机
在默认配置页定义upstream



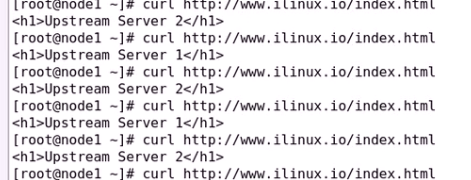
这就是负载均衡集群
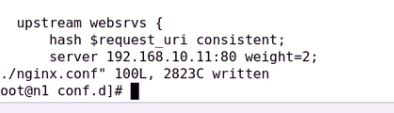
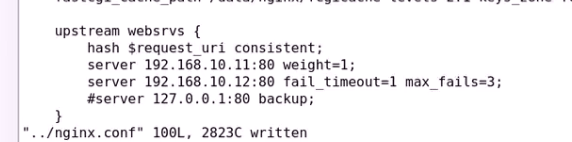
还可以定义权重等等
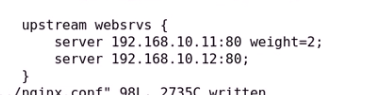

先轮询 至少都一边 然后再加权
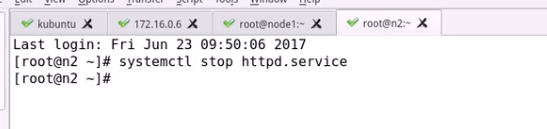




意思就是超时1次认为失败 最多失败三次就干掉
当两个服务器都down
设置去访问默认主页
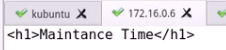
两个都挂了就上

两台主机都停止服务
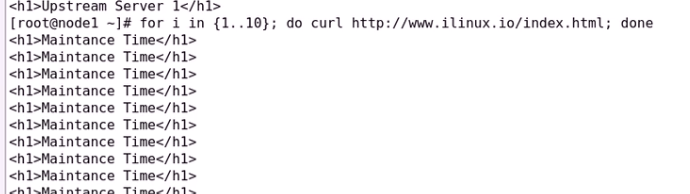
再次开启服务
还可以伪装down了实际并没有 类似于灰度测试下
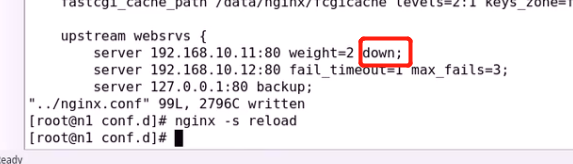

再次去掉down恢复正常
也支持sh会话粘性
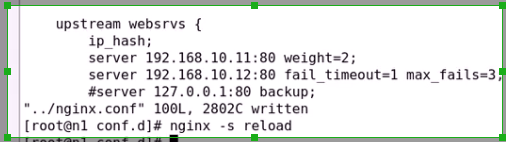
添加ip_hash
下面的backup需要注释

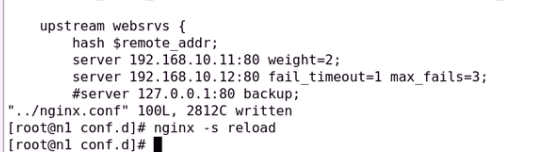
hash cookie就会把cookie当键
haproxy还支持很多种 讲haproxy会讲
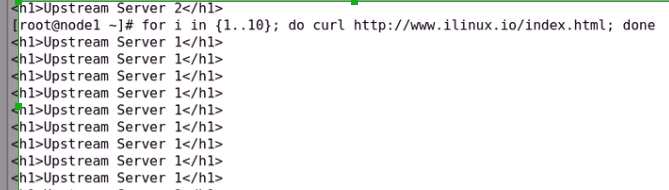
吧来自同一个用户发往同一个请求

一致性哈希!!
uri一定 适应与反代服务器
用uri的哈希值模2^32次方 范围就在0~ 2^32-1
同理对服务器ip地址做哈希计算 也取模
顺时针找离他近的服务器

当一个服务器宕机了
只影响一小段
但是如果服务器计算哈希离得很近很近

所以虚拟节点解决哈希环偏离
加盐 一个加五十个盐 那么3个节点150个点


这个就是自带虚拟节点的一致性哈希
多生成页面


分别生成20个页面
对于同一个uri第一次绑定后面肯定都在一个服务器

ngx_http_upstream_module模块
The ngx_http_upstream_module module is used to define groups of servers that can be referenced by the proxy_pass, fastcgi_pass, uwsgi_pass, scgi_pass, and memcached_pass directives.
1、upstream name { ... }
定义后端服务器组,会引入一个新的上下文;Context: http
upstream httpdsrvs {
server ...
server...
...
}
2、server address [parameters];
在upstream上下文中server成员,以及相关的参数;Context: upstream
address的表示格式:
unix:/PATH/TO/SOME_SOCK_FILE
IP[:PORT]
HOSTNAME[:PORT]
parameters:
weight=number
权重,默认为1;
max_fails=number
失败尝试最大次数;超出此处指定的次数时,server将被标记为不可用;
fail_timeout=time
设置将服务器标记为不可用状态的超时时长;
max_conns
当前的服务器的最大并发连接数;
backup
将服务器标记为“备用”,即所有服务器均不可用时此服务器才启用;
down
标记为“不可用”;
3、least_conn;
最少连接调度算法,当server拥有不同的权重时其为wlc;
4、 ip_hash;
源地址hash调度方法;
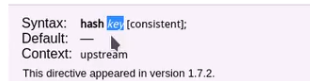
5、hash key [consistent];
基于指定的key的hash表来实现对请求的调度,此处的key可以直接文本、变量或二者的组合;
作用:将请求分类,同一类请求将发往同一个upstream server;
If the consistent parameter is specified the ketama consistent hashing method will be used instead.
示例:
hash $request_uri consistent;
hash $remote_addr;
6、keepalive connections;
为每个worker进程保留的空闲的长连接数量;
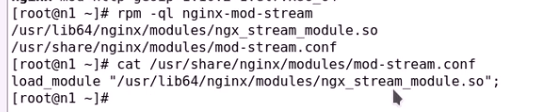 前面http服务的负载均衡都在http{}里面写的 只能用来负载http服务
前面http服务的负载均衡都在http{}里面写的 只能用来负载http服务
其余所有四层的代理都应该放在stream模块中
自己无法处理四层服务 所以server必须都有真实的代理
包括http服务本身也可以在四层调度

举了例子ssh服务

吧http的都删除了

监听ssh服务 首先监听在22922
监听用户发过来的ssh服务


这个时候就是四层反向代理

当然也可以代理web服务

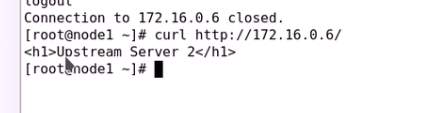
定义负载均衡

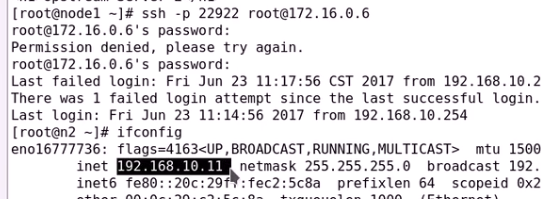

web好验证
轮询的





 只给一个数据库创建mydb
只给一个数据库创建mydb

可以发现也是轮询的
关闭一个数据库服务
发现也是有健康检查功能哦
keepalived

一般需要奇数个 通过选举选出新的leader
怎么把A干掉
ABC在电源交换机上
这个电源交换机可以通过网络交换信号
多数的方可以干掉节点
BC选择谁是Leader 向电源交换机发信号 切断A的电源 或者闪一下A的电源
让故障节点不要去访问资源–FENCE
共享存储前面添加一个信号 A要是干掉
共享存储的需要屏蔽A的信号 不让A去访问资源
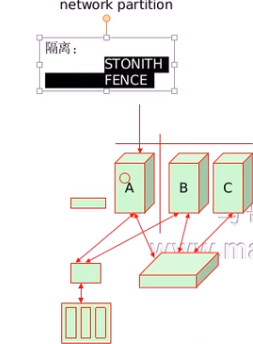
只有一方才可以代表集群工作称为quorum机制
投票选举是否大于半数
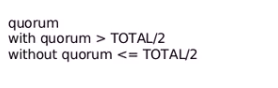

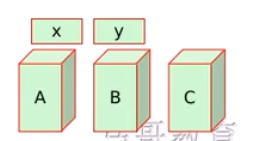
N个节点 M个服务
每个资源的倾向不同 x资源首先倾向于A。y资源倾向于B
在资源节点定义
A服务出问题优先到C
以上是heartbeat
和keepalived不同

每个内网主机网关都指向虚拟VIP
多个路由器虚拟为一个虚拟路由器,通过VIP向外提供服务
这就是vrrp协议
路由网卡有优先级高低,谁高Vip就在谁身上的
keepalived实现了软件上就可以支持vrrp协议
vip配置在优先级高的主机上
keepalied进程在用户空间上,有几个主机就有几个keepalived进程。还支持健康检查
 IPVS wrapper生成规则 删除宕掉的机器
IPVS wrapper生成规则 删除宕掉的机器
核心组件:
vrrp stack 实现vrrp协议的
ipvs wrapper 生成ipvs规则的
checkers 健康状态检测工具
控制组件:配置文件分析器
IO复用器
内存管理组件
keepalived监控进程状态 但是万一自己的vrrp stack进程和checkers进程都挂了
所以有watchdog 用来监控进程的进程
通常是个硬件设备 在主板上
内核驱动这个设备金控内核级进程

真正的通信是mac地址
VIP飘逸了 客户端缓存的都是已经宕机的mac
所以不会再次发起解析请求 还是发给原来的主机
所以就需要虚拟MAC地址
再次广播 自己问VIP的MAC地址是什么
免费ARP
其他主机自动更新本地MAC 就是新的路由!!!!

优先级高的如果正常了 是否需要抢回VIP

可以配置不同的虚拟路由支持不同的服务的优先级主机不同

如果又来了一个keepalive说自己是最高优先级
但是不可信的
所以需要认证 组播的

keepalived:
vrrp协议的软件实现,原生设计的目的为了高可用ipvs服务:
基于vrrp协议完成地址流动;
为vip地址集群的节点生成ipvs规则(在配置文件中预先定义);
为ipvs集群的各RS做健康状态检测;
基于脚本调用接口通过执行脚本完成脚本中定义的功能,进而影响集群事务;(nginx,haproxy等需要)
组件:
核心组件:
vrrp stack
ipvs wrapper
checkers
控制组件:配置文件分析器
IO复用器
内存管理组件
HA Cluster的配置前提:
(1) 各节点时间必须同步;
ntp, chrony
(2) 确保iptables及selinux不会成为阻碍;
(3) 各节点之间可通过主机名互相通信(对KA并非必须);
建议使用/etc/hosts文件实现;
(4) 确保各节点的用于集群服务的接口支持MULTICAST通信;
D类:224-239;

关闭iptabels
关闭firewalld服务
放行多播信息即可



多播功能需要打开

keepalived安装配置:
CentOS 6.4+ 随base仓库提供;
程序环境:
主配置文件:/etc/keepalived/keepalived.conf
主程序文件:/usr/sbin/keepalived
Unit File:keepalived.service
Unit File的环境配置文件:/etc/sysconfig/keepalived



分别是全局配置
VRRP配置
LVS配置
配置文件组件部分:
TOP HIERACHY
GLOBAL CONFIGURATION
Global definitions
Static routes/addresses
VRRPD CONFIGURATION
VRRP synchronization group(s):vrrp同步组;确保吧VIP放在同一个节点的主机上
VRRP instance(s):每个vrrp instance即一个vrrp路由器;
LVS CONFIGURATION
Virtual server group(s)
Virtual server(s):ipvs集群的vs和rs;


组播地址

默认smtp是开启的
配置语法:
配置虚拟路由器:
vrrp_instance <STRING> {
....
}
专用参数:
state MASTER|BACKUP:当前节点在此虚拟路由器上的初始状态;只能有一个是MASTER,余下的都应该为BACKUP;
interface IFACE_NAME:绑定为当前虚拟路由器使用的物理接口;
virtual_router_id VRID:当前虚拟路由器的惟一标识,范围是0-255;
priority 100:当前主机在此虚拟路径器中的优先级;范围1-254;
advert_int 1:vrrp通告的时间间隔;
authentication {
auth_type AH|PASS
auth_pass <PASSWORD>
}
virtual_ipaddress {
<IPADDR>/<MASK> brd <IPADDR> dev <STRING> scope <SCOPE> label <LABEL>
192.168.200.17/24 dev eth1
192.168.200.18/24 dev eth2 label eth2:1
}
track_interface {
eth0
eth1
...
}
配置要监控的网络接口,一旦接口出现故障,则转为FAULT状态;
nopreempt:定义工作模式为非抢占模式;
preempt_delay 300:抢占式模式下,节点上线后触发新选举操作的延迟时长;
 VIP 配置绑定在哪个接口上interface
VIP 配置绑定在哪个接口上interface
同一个虚拟路由器的id需要一样
默认1秒向外通告一次 自己的优先级和心跳信息等
pass只要是一样的即可
虚拟VIP格式
ip 指明在eno16xxx设备上 别名


多个地址的多播地址一样 就在一个域内
只要一样的即可

默认抢占式


node1优先级高 所以会抢占



同理 主节点关闭服务 VIP又飘逸回去
可以看到多播信息 一秒钟发送一个
 通过查看多播地址的信息查看抓包情况
通过查看多播地址的信息查看抓包情况
 1秒一个 host指定主机地址
1秒一个 host指定主机地址
备用节点也可以收到

关闭node1

node2自己通告 可以看到优先级
再次开启node1 的服务

这就是vRRp
双主模型—主备和备主
再高一个虚拟路由器
不同的密码
这个虚拟路由器配置node2的优先级高,优先级低

给node2复制





可以看到两组都在通报



都变成优先级高的了

man keepalived.conf
配置和演练
通知脚本的使用方式:
示例通知脚本:
#!/bin/bash
#
contact='root@localhost'
notify() {
local mailsubject="$(hostname) to be $1, vip floating"
local mailbody="$(date +'%F %T'): vrrp transition, $(hostname) changed to be $1"
echo "$mailbody" | mail -s "$mailsubject" $contact
}
case $1 in
master)
notify master
;;
backup)
notify backup
;;
fault)
notify fault
;;
*)
echo "Usage: $(basename $0) {master|backup|fault}"
exit 1
;;
esac
脚本的调用方法:
notify_master "/etc/keepalived/notify.sh master"
notify_backup "/etc/keepalived/notify.sh backup"
notify_fault "/etc/keepalived/notify.sh fault"

文本粘贴进去



-p保留权限

Node1 和node2都先保留一份keepalved双主模型的
然后把keepalived只保留一个虚拟路由
:.,$d


man keepalived.conf
添加几条新参数

脚本的调用方法:
notify_master "/etc/keepalived/notify.sh master"
notify_backup "/etc/keepalived/notify.sh backup"
notify_fault "/etc/keepalived/notify.sh fault"




开启一个节点

 发现没有发送邮件
发现没有发送邮件


node1抢占

但是纳闷的是邮件没有发送出来

都加上双引号
停止服务 开启服务(node2)

node1开启

就是因为引号的问题 没有把后面的参数识别 所以需要加上
后续可以把这个通知脚本 使用python写等等 网上有多种
默认keepalived是为lvs设计的
lvs规则在两个keepalived上都有
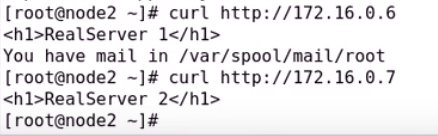
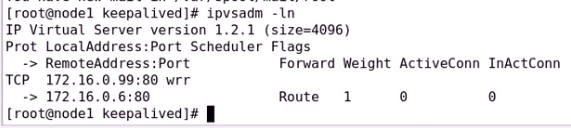
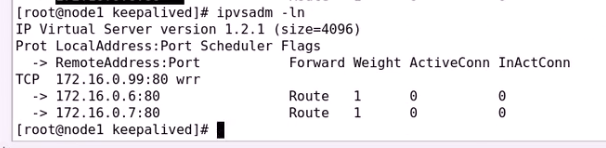
再次开启两个RS 172.16.0.6 和172.16.0.7

时间同步




都开启






定义虚拟服务器
配置后端主机都down了访问页面




虚拟服务器:
配置参数:
virtual_server IP port |
virtual_server fwmark int
{
...
real_server {
...
}
...
}
常用参数:
delay_loop <INT>:服务轮询的时间间隔;
lb_algo rr|wrr|lc|wlc|lblc|sh|dh:定义调度方法;
lb_kind NAT|DR|TUN:集群的类型;
persistence_timeout <INT>:持久连接时长;
protocol TCP:服务协议,仅支持TCP;
sorry_server <IPADDR> <PORT>:备用服务器地址;
real_server <IPADDR> <PORT>
{
weight <INT>
notify_up <STRING>|<QUOTED-STRING>
notify_down <STRING>|<QUOTED-STRING>
HTTP_GET|SSL_GET|TCP_CHECK|SMTP_CHECK|MISC_CHECK { ... }:定义当前主机的健康状态检测方法;
}

判断后端主页校验码是否一样 这种要求更严格

nb_get_retry 3 重试3次
delay_before_retry :重试之前的延迟时长;
connect_timeout :连接请求的超时时长;


node2配置也是一样的

两边都先关闭服务




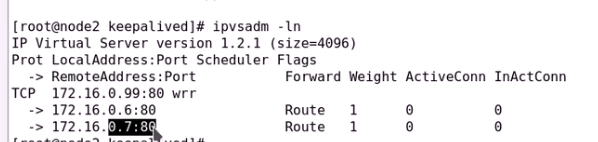

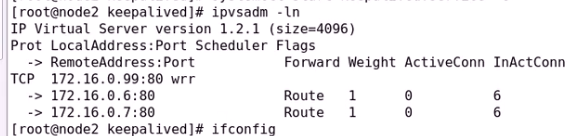
ipvs规则两边都有
只是谁有VIP谁提供服务

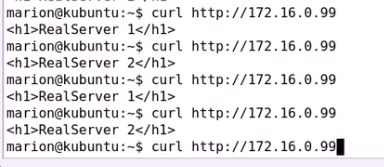



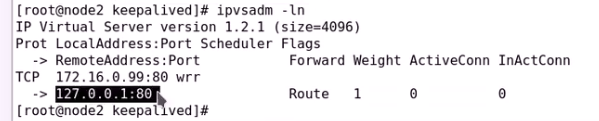
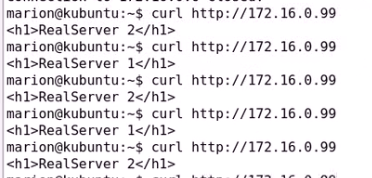
curl就是默认主页了

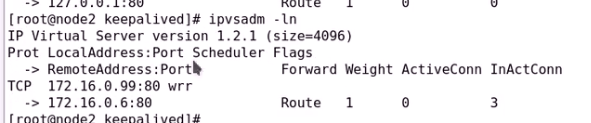
服务都开启就又成功了
都关闭keepalived服务 配置双主模型

之前备份的文件

.,$ w >> /etc/xx
成功追加了

node2同样追加进去





没有98是因为98没有使用别名

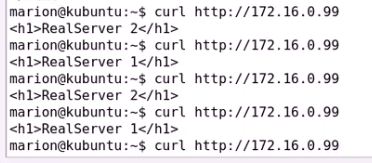

是nginx主页

因为没有定义98是VIP 也没有定义98 是集群服务

后端RS需要给lo:1上添加98为vip
配置文件再添加一组98
比较麻烦 先不定义了
使用TCP检测


开启服务

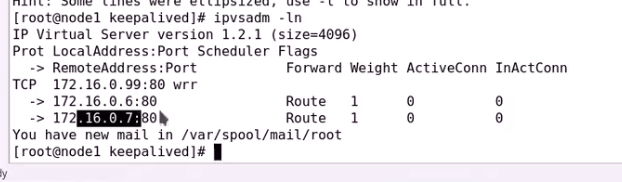
0.7主机是TCP检测方式

健康状态检测成功
TCP方法也很简单
real_server可以通过notify_up 或者down发邮件去检测
当然可以使用zabbix监控更好
keepalived与nginx实现高可用故障转移实战
使用keepalived高可用nginx

lvs比较麻烦
所以多使用Nginx或者haproxy工作在四层代理
nginx代理
外部网卡做成流动地址,通过VIP接受用户请求
后端请求也只响应给nginx的内网地址即可
后端主机使用私网地址
nginx两个接口
keepalived在Nginx主机做
重新开始配置
两台nginx主机 都是 一个对外接口 一个对内Ip


内部的RS 使用一台主机即可 虚拟为多台
所以需要添加多个IP


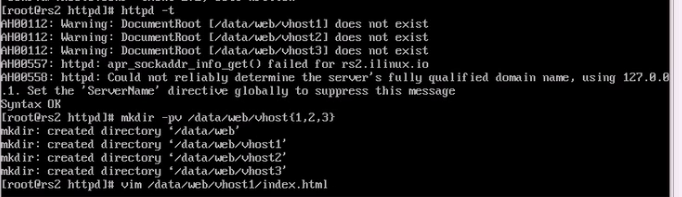
编辑默认主页
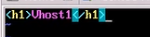
三个一样

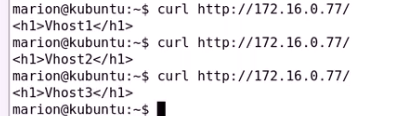
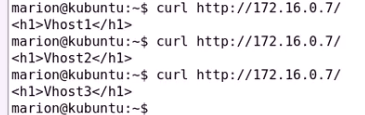
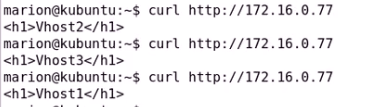
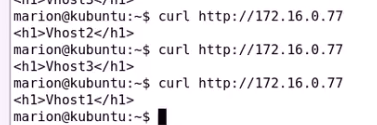
测试虚拟主机

只要确保俩个nginx服务启动着(类似于lvs的规则) VIP飘逸过来即可使用
keepalived调用外部的辅助脚本进行资源监控,并根据监控的结果状态能实现优先动态调整;
分两步:(1) 先定义一个脚本;(2) 调用此脚本;
vrrp_script <SCRIPT_NAME> {
script ""
interval INT
weight -INT
}
track_script {
SCRIPT_NAME_1
SCRIPT_NAME_2
...
}
检测脚本检测
如果检测失败了 立刻减去权重
通过脚本监控完成资源转移
主不下线 降权 就可以把VIP给备节点了


两个节点都安装
嫌麻烦,可以把上面的keepalived文件复制过来


把地址修改下


脚本也复制过去
期待通过脚本完成VIP转移 而不是直接停掉服务 比如生产中主节点需要更新临时下线
脚本先定义后调用
调用在vrrp_instance里面
判断down文件是否存在 存在错误退出 不存在正确退出
脚本失败了 降权 -10 小于备用节点即可
1秒检测一次
跟踪脚本结果 tract_script







删除脚本又回来了


可以借助脚本监控Nginx服务


nginx做反代服务





先手动测试下能否成功



现在定义谁是主节点谁就开启nginx服务
备用节点就把Nginx服务关闭
就在notify.sh脚本中添加


现在查看Ip发现Node1 是keepalived节点 VIP在



所以通过外部的通知脚本完成辅助功能
删除down



所以这个就是通知脚本的作用
通过通知脚本的建立来降低优先级权重实现VIP漂移到备节点
备节点成为主节点后执行notify master 激活 开启nginx服务 并且发送邮件
但是一般别让nginx服务停掉





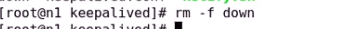
nginx会自动状态检测
添加脚本监控Nginx进程完成降级










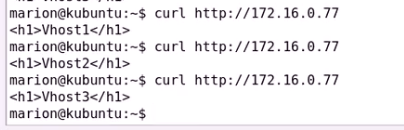


干掉nginx 或者开启http冲突
看能否转走VIP
两边都修改

多失败几次
都停掉keepalived服务





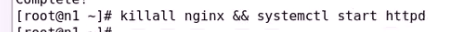

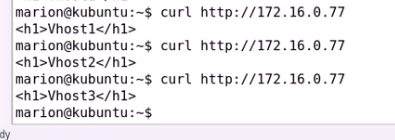
地址转移

nginx

可以发现启动不起来nginx服务
因为转成备用节点 已经触发了
需要手动开启




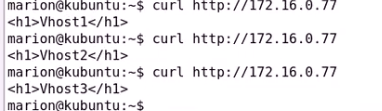

先关闭 确保80端口没有倍监听

优先级也降低了


删除down也回不来 因为自己是96 对方是100了
高可用nginx
双主模型






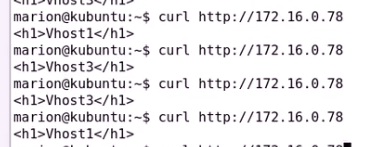
node1拿到77的地址 node2拿到78的地址

尝试dns主机名解析到这两个VIP即可
检测健康


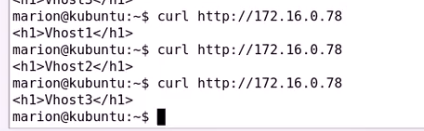
这就是keepalived高可用Nginx 生产中常用
还可以高可用haproxy哦
或者mysql的高可用
















 2857
2857











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









