






1.编写一个playbook实现Nginx的两种安装过程,安装方式可通过变量传入控制
本次部署使用三台机器
ubuntu 10.0.0.105 作为ansible管理端
Rocky8 10.0.0.32 作为部署机器
Rocky8 10.0.0.62 作为部署机器
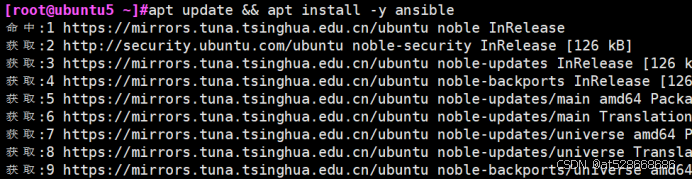
#在 ubuntu 10.0.0.105上安装ansible
apt update && apt install -y ansible
# 以/root为本次ansible工作目录
# 生成ansible配置文件,定义主机清单为./hosts
[root@ubuntu5 ~]#rz -E
rz waiting to receive.
[root@ubuntu5 ~]#ansible --version

[root@ubuntu5 ~]#vim hosts
[root@ubuntu5 ~]#cat hosts
10.0.0.32
10.0.0.62
# 添加ansible主机连接部署机器的ssh-key验证(皆使用root账号)
ssh-keygen
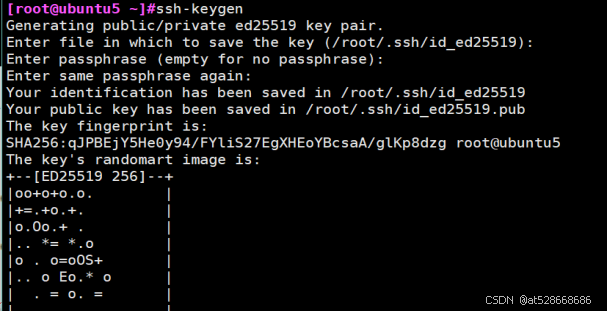
ssh-copy-id 10.0.0.32
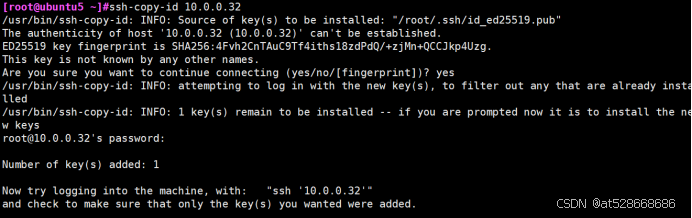
ssh-copy-id 10.0.0.62
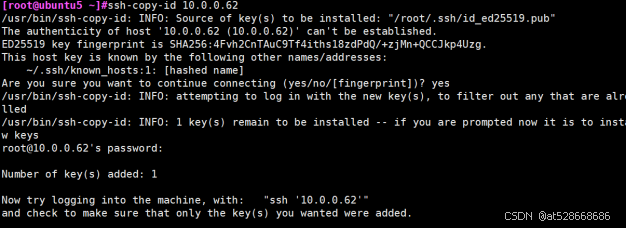
# 检查查看清单中的主机
[root@ubuntu5 ~]#ansible --list all
hosts (2):
10.0.0.32
10.0.0.62
# 测试主机连通
[root@ubuntu5 ~]#ansible all -m ping
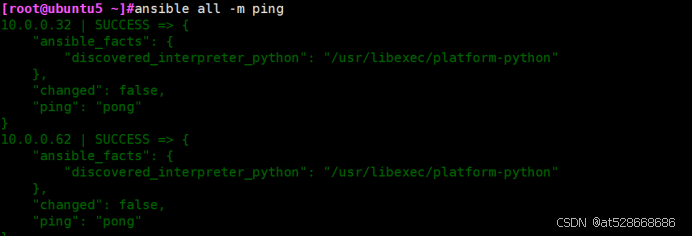
1/实现ansible包安装nginx
#创建包安装nginx的install_nginx.yml文件
[root@ubuntu5 ~]#vim install_nginx1.yml
[root@ubuntu5 ~]#cat install_nginx1.yml
- hosts: 10.0.0.32
vars:
nginx_version: "1.20.1"
url: "http://nginx.org/download/nginx-{{ nginx_version }}.tar.gz"
install_dir: "/usr/local/src/"
tasks:
- name: Install Nginx
yum:
name: nginx
state: present
notify:
- restart nginx
- name: start nginx
service:
name: nginx
state: started
enabled: yes
#运行playbook
[root@ubuntu5 ~]#ansible-playbook install_nginx1.yml
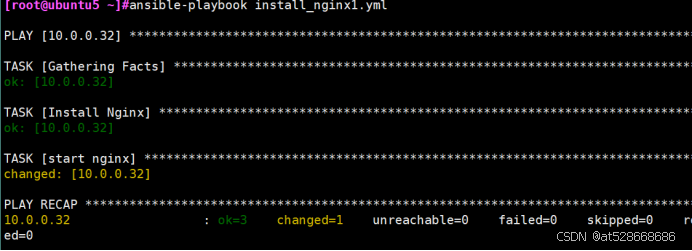
#在rocky10.0.0.32上查看
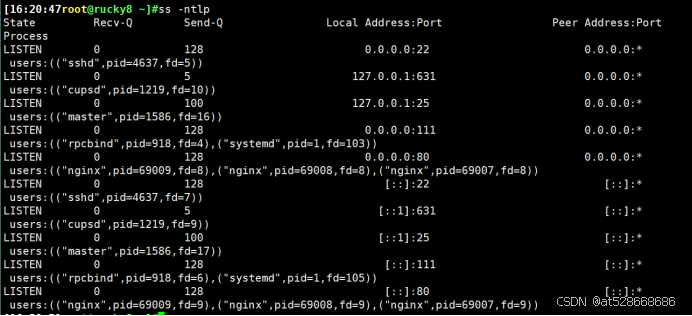
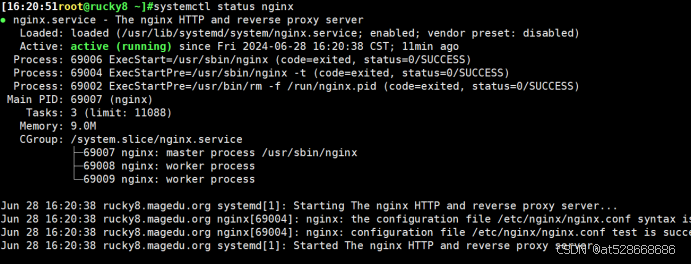
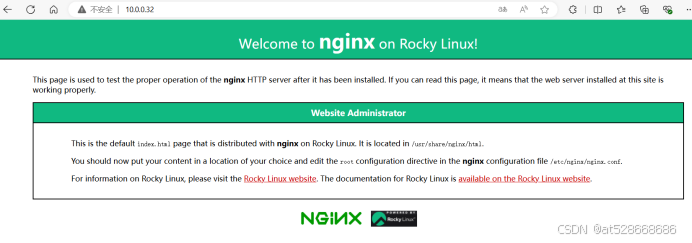
用IP地址:10.0.0.32访问网站(成功)
2/实现ansible翻译安装nginx
#创建编译安装nginx的install_nginx2.yml文件
[root@ubuntu5 ~]#vim install_nginx2.yml
[root@ubuntu5 ~]#cat install_nginx2.yml
- hosts: 10.0.0.62
vars:
nginx_version: "1.22.1"
nginx_download_url: "http://nginx.org/download/nginx-{{ nginx_version }}.tar.gz"
install_dir: "/usr/local/src/"
tasks:
- name: Install NGINX dependencies
# rocky dependencies packages
# gcc make pcre-devel openssl-devel
yum:
name:
- gcc
- make
- pcre-devel
- openssl-devel
- zlib-devel
- perl-ExtUtils-Embed
state: present
- name: Download Nginx souuece code
get_url:
url: "{{ nginx_download_url }}"
dest: "/tmp/nginx-{{ nginx_version }}.tar.gz"
mode: '0644'
- name: get Nginx souece
unarchive:
src: "/tmp/nginx-{{ nginx_version }}.tar.gz"
dest: "{{ install_dir }}"
remote_src: yes
creates: "{{ install_dir }}/nginx-{{ nginx_version }}"
- name: Configure Nginx
command: "./configure --prefix=/etc/nginx --sbin-path=/usr/sbin/nginx --conf-path=/etc/nginx/nginx.conf --error-log-path=/var/log/nginx/error.log --http-log-path=/var/log/nginx/access.log --with-pcre --with-http_ssl_module"
args:
chdir: "{{ install_dir }}/nginx-{{ nginx_version }}"
creates: "{{ install_dir }}/nginx-{{ nginx_version }}/Makefile"
- name: Build Nginx
shell:
cmd: make
args:
chdir: "{{ install_dir }}/nginx-{{ nginx_version }}"
- name: Install Nginx from source
shell:
cmd: make install
args:
chdir: "{{ install_dir }}/nginx-{{ nginx_version }}"
- name: run nginx
shell:
cmd: "{{install_dir}}/nginx-{{ nginx_version }}/objs/nginx"
#运行playbook
[root@ubuntu5 ~]#ansible-playbook install_nginx2.yml
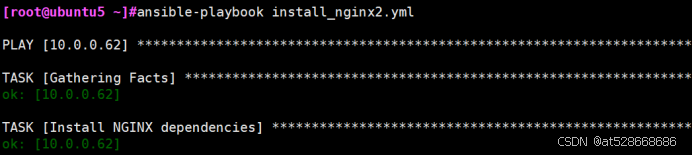
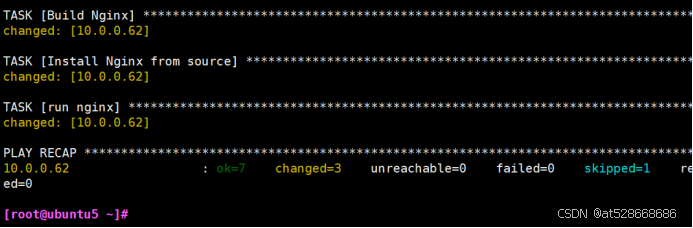
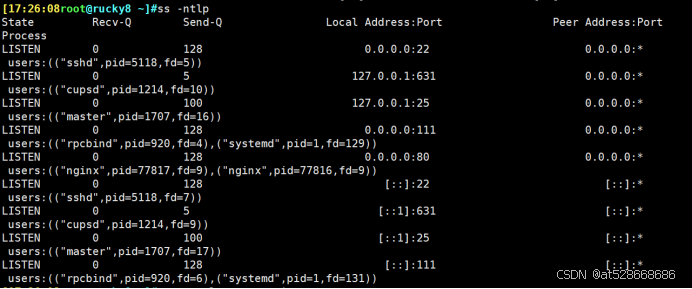
#在rocky10.0.0.62上查看
[17:26:08root@rucky8 ~]#ss -ntlp
[17:26:50root@rucky8 ~]#ps aux | grep nginx

[17:27:10root@rucky8 ~]#ps aux

用IP地址:10.0.0.62 访问网站(成功)
2.总结http协议版本和工作原理
1) HTTP协议版本

HTTP/0.9
- 发布时间:1991年
- 特点
- 只支持GET请求
- 没有请求头和响应头的概念
- 服务器发送简单的HTML文件,不支持多媒体内容
HTTP/1.0
- 发布时间:1996年5月
- 特点
- 引入了方法(GET、POST、HEAD)、状态码、请求头、MIME和响应头等概念
- 对多媒体内容提供支持(通过Content-Type头)
- 缺乏持久连接,每次请求/响应交互后,创建的TCP连接都会关闭
HTTP/1.1
- 发布时间:1997年1月
- 特点
- 支持持久连接(Connection: keep-alive),可以在一个TCP链接上发送多个HTTP请求。大多数浏览器支持同时建立6个持久连接。
- 新增了更多的请求方法(PUT、PATCH、OPTIONS、DELETE)
- 增加了对虚拟主机的支持(通过host头部)
- 支持分块传输编码,允许动态生成的内容被逐步发送
- 引入了缓存控制机制。引入了更多的缓存控制策略例如Entity tag,If-Unmodified-Since, If-Match, If-NoneMatch等更多可供选择的缓存头来控制缓存策略
HTTP/2
- 发布时间:2015年
- 特点
- 引入了二进制帧层,替代料旧版的文本格式,提高了解析效率。头信息和数据体都是二进制,称为头信息帧和数据帧。
- 支持多路复用,在同一TCP连接上并行处理多个请求和响应。
- 实现了头部压缩,减少了冗余头信息传输。
- 允许服务器推送资源,优化了页面加载时间
HTTP/3
- 发布时间:2022年6月正式发布,使用QUIC(基于UDP协议)的新协议代替TCP
- 特点
- 低延迟连接的建立
- 改进的拥塞控制
- 无对头阻塞的多路复用
- 向前纠错
- 连接迁移
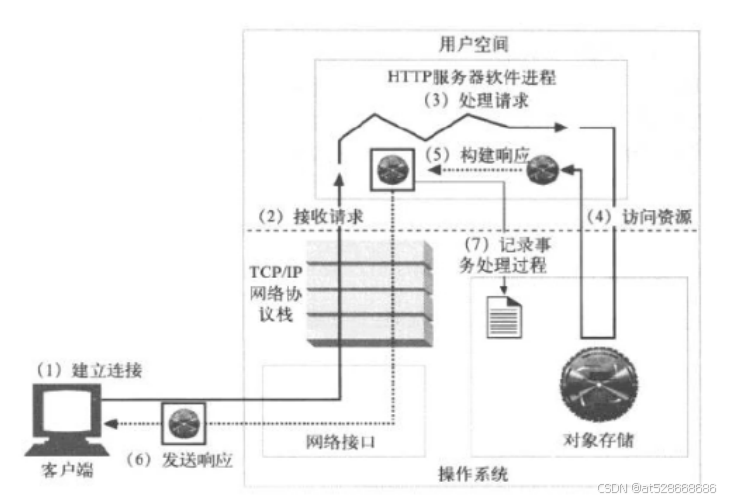
2)HTTP工作原理
-
1、建立连接:
-
接收或拒绝连接请求
-
2、接收请求:
-
接收客户端请求报文中对某资源的一次请求的过程Web访问响应模型(Web I/O)
-
3、处理请求:
-
服务器对请求报文进行解析,并获取请求的资源及请求方法等相关信息,根据方法,资源,首部和可选的主体部分对请求进行处理。
常用请求Method: GET、POST、HEAD、PUT、DELETE、TRACE、OPTIONS -
4、访问资源:
-
服务器获取请求报文中请求的资源web服务器,即存放了web资源的服务器,负责向请求者提供对方请求的静态资源,或动态运行后生成的资源
-
5、构建响应报文:
-
一旦Web服务器识别除了资源,就执行请求方法中描述的动作,并返回响应报文。响应报文中 包含有响应状态码、响应首部,如果生成了响应主体的话,还包括响应主体
-
1)响应实体:如果事务处理产生了响应主体,就将内容放在响应报文中回送过去。响应报文中通常包括:描述了响应主体MIME类型的Content-Type首部;描述了响应主体长度的Content-Length实际报文的主体内容
-
2)URL重定向:web服务构建的响应并非客户端请求的资源,而是资源另外一个访问路径
3)MIME类型: Web服务器要负责确定响应主体的MIME类型。多种配置服务器的方法可将MIME类型与资源管理起来 -
6、发送响应报文
-
Web服务器通过连接发送数据时也会面临与接收数据一样的问题。服务器可能有很多条到各个客户端的连接,有些是空闲的,有些在向服务器发送数据,还有一些在向客户端回送响应数据。服务器要记录连接的状态,还要特别注意对持久连接的处理。对非持久连接而言,服务器应该在发送了整条报文之后,关闭自己这一端的连接。对持久连接来说,连接可能仍保持打开状态,在这种情况下,服务器要正确地计算Content-Length首部,不然客户端就无法知道响应什么时候结束
-
7、记录日志
-
最后,当事务结束时,Web服务器会在日志文件中添加一个条目,来描述已执行的事务
3.总结IO模型和零复制技术的原理
IO模型
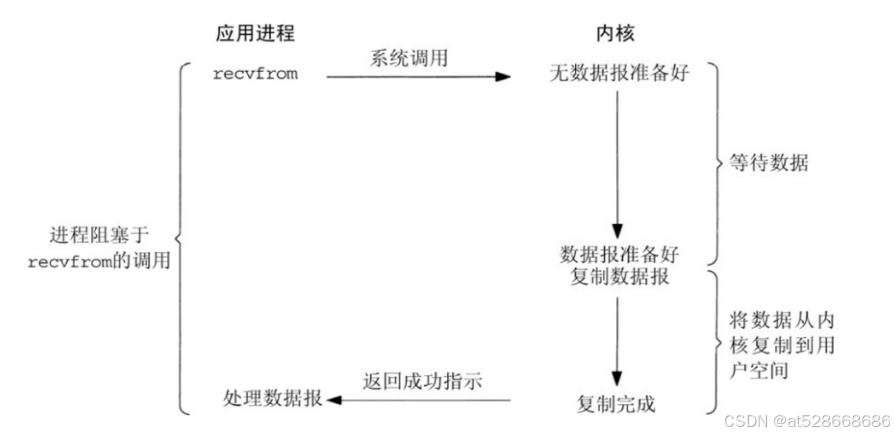
1. 阻塞IO(Blocking IO)
-
阻塞IO模型是最简单的I/O模型,用户线程在内核进行I/O操作时被阻塞。
-
用户线程通过系统调用read发起I/O操作,由用户空间转到内核空间。内核等到数据包到达后,然后将接受的数据复制到用户空间,完成read操作。
用户需要等待read将数据读取到buffer后,才继续处理接收的数据。整个I/O请求的过程中,用户线程是被阻塞的,这导致用户在发起I/O请求时不能做任何事情,对CPU的资源利用率不够。 -
优点:程序简单,在阻塞等待数据期间进程/线程挂起,基本不会占用CPU资源。
-
缺点:每个连接需要独立的进程/线程单独出来,当并发请求量大时为了维护程序,内存,线程切换开销较大。Apache的prefork使用的就是这种模式。
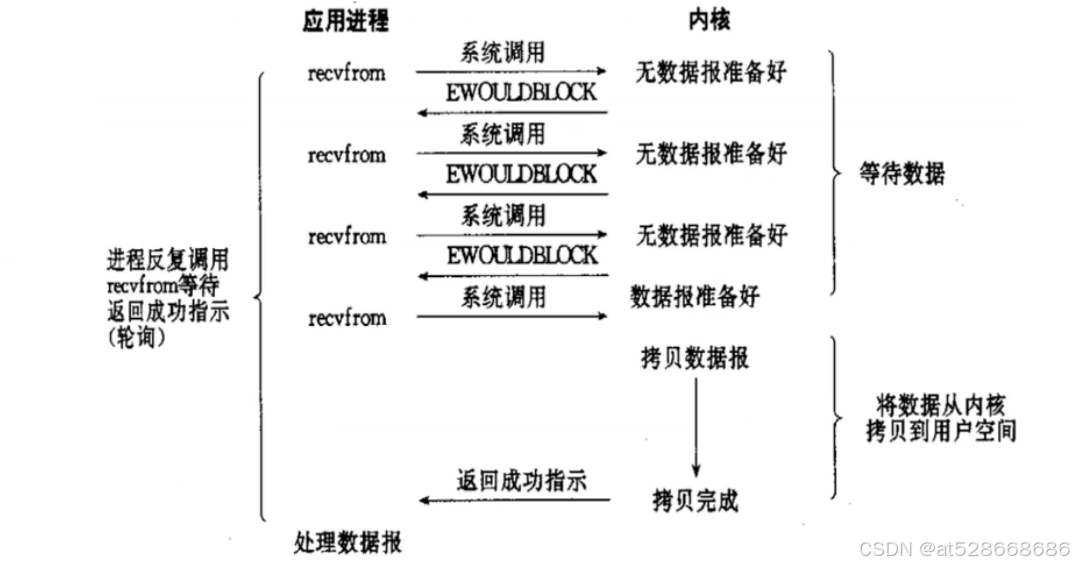
2. 非阻塞IO(Non-Blocking IO)
-
用户线程发起I/O请求时立即返回,但并未读取到任何数据,用户线程需要不断地发起I/O请求,直到数据到达后,才真正读取到数据,继续执行。
-
当应用进程系统调用recvfrom没有数据返回时,内核会立即返回一个EWOULDBLOCK错误,而不会一直阻塞到数据准备好。直到再次调用recvfrom时候,有一个数据报准备好之后,这时数据会被复制到应用进程缓冲区,于是recvfrom成功返回数据。
-
当一个应用进程这样循环调用recvfrom时,称之为轮询(polling)。这么做往往会耗费大量CPU时间,实际使用很少
-
优点:
- 提高响应性。即使数据未准备好,应用程序也不会被阻塞,可以立即得知状态并执行其他任务
- 资源利用:可以在单个线程中处理多个I/O操作,提高资源的利用率。
-
缺点:
- 效率问题。如果频繁轮询,可能会消耗大量的CPU时间,尤其是在I/O没有立即准备好的情况下。如果有大量的文件描述符都要等,那么就得一个一个的read。这会带来大量的Context Switch
3. IO多路复用(IO Multiplexing)
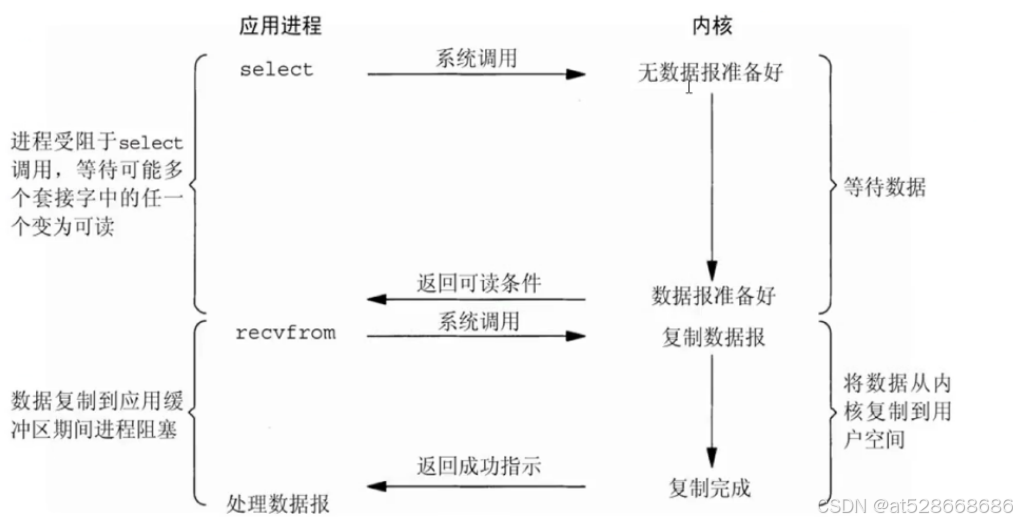
-
使用select或者poll等系统调用,允许应用程序监视多个文件描述符,以了解哪些可以执行非阻塞读写操作。
-
当I/O准备就绪时,应用程序可以做出相应的处理。
-
优点:可以基于一个阻塞对象,同时在多个描述符上等待就绪,而不是使用多个线程(每个文件描述符一个线程),这样可以大大节省系统资源
-
缺点:当连接数较少时效率相比多线程+阻塞I/O模型效率较低,可能延迟更大。因为单个连接处理需要2次系统调用,占用时间会有增加
-
I/O多路复用适用如下场合:
- 当客户端处理多个描述符时(一般是交互式输入和网络套接口),必须使用I/O复用
- 当一个客户端同时处理多个套接字时,此情况可能性很少出现
- 当一个服务器既要处理监听套接字,又要处理已连接套接字,一般也要用到I/O复用
- 当一个服务器既要处理TCP,又要处理UDP,一般要使用I/O复用
- 当一个服务器要处理多个服务或者多个协议,一般要使用I/O复用
4. 信号驱动IO(Signal-driven IO)
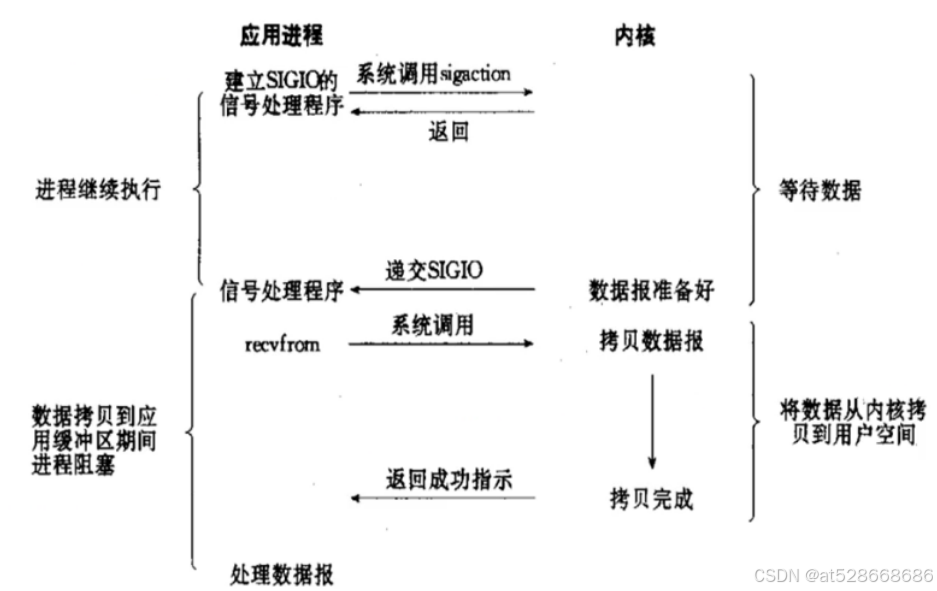
-
应用程序先告诉内核在数据准备好进行I/O时发送一个信号,然后应用程序可以继续做其他事情。
-
应用程序收到信号后,即执行实际的I/O操作
-
优点
- 异步通知:内核会在数据准备好时发送信号,无需不断地轮询检查。
- 线程并没有在等待数据时被阻塞,内核直接返回调用接收信号,不影响进程继续处理其他请求,可以提高资源的利用率
-
缺点
- 信号I/O在大量I/O操作时,可能会因为信号队列溢出导致没法通知
5. 异步IO(Asynchronous IO)
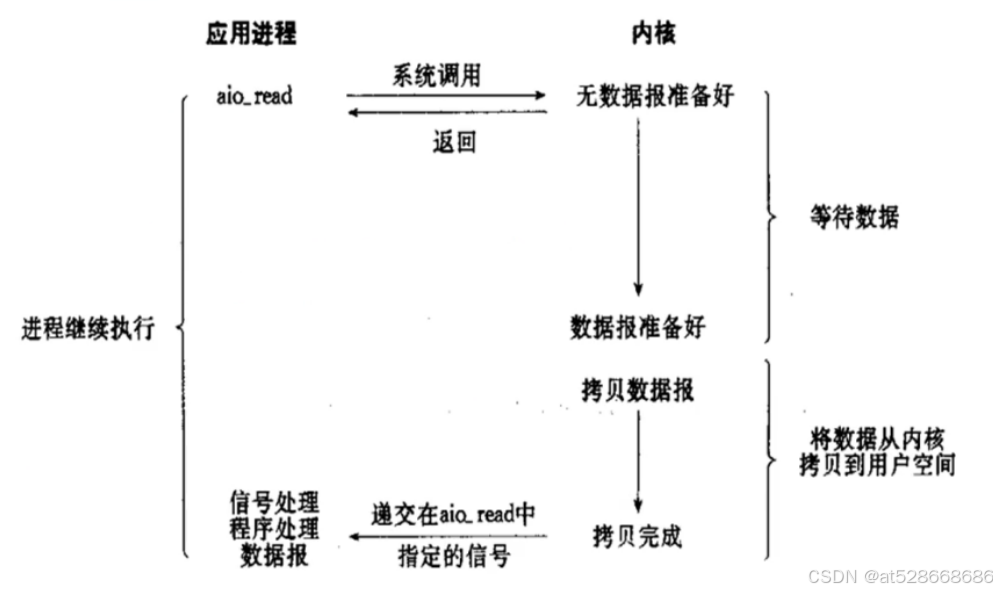
-
应用程序发起I/O操作请求后可以立即开始执行其他任务。
-
I/O操作在后台进行,一旦数据准备就绪并且操作完成,应用程序会收到通知。
-
优点
- 异步I/O能够充分利用DMA特性,让I/O操作与计算重叠
- 真正的异步:应用程序发起I/O请求后立即返回,无需等待数据准备就绪,内核会自行处理整个I/O操作
- 高效率:应用程序可以继续执行工作,直到I/O完成信号发出,这样可以最小的CPU消耗来完成I/O
-
缺点
- API复杂:异步I/O的API往往更加复杂,对错误处理的要求也比同步I/O严格
- 实现依赖:异步I/O的支持程度取决于操作系统的实现,不同操作系统间可能存在差异
零复制技术
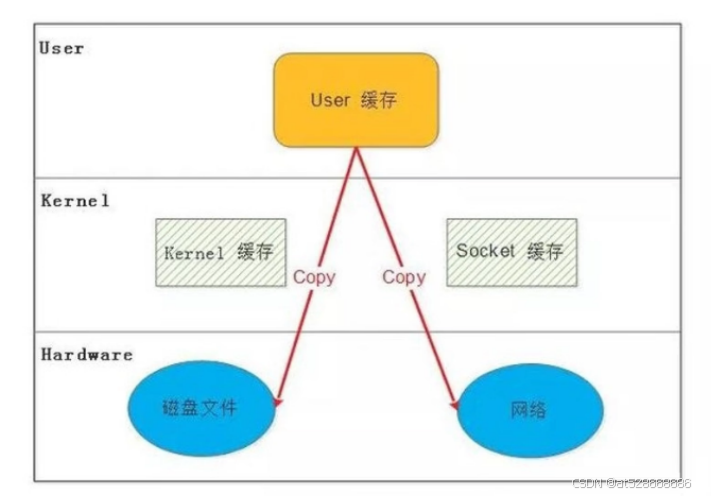
传统的Linux系统的标准I/O接口(read、write)是基于数据拷贝的,也就是数据都是copy_to_user或者copy_from_user。这样做的好处是通过中间缓存的机制,减少磁盘I/O操作。但坏处也很明显:大量的数据拷贝、用户态和内核态的频繁切换,会消耗大量的CPU资源,严重影响数据传输的性能。统计表明,在Linux协议栈中,数据包在内核态和用户态之间的拷贝所用的时间甚至占到了数据包整个处理流程时间的57.1%
零复制技术是一种减少CPU拷贝操作,提高数据传输效率的技术,在文件传输和网络通信中尤为重要。其原理基本上是避免在用户空间和内核空间之间进行不必要的数据复制
-
传统数据传输
- 数据从磁盘读到内核空间的缓冲区,然后复制到用户空间缓冲区,再从用户空间缓冲区复制回内核空间的网络缓冲区,最终通过网络发送出去。
- 这个过程中涉及多次CPU拷贝,消耗资源。
-
零复制技术
- 通过像sendfile这样的系统调用,可以直接从内核空间缓冲区将数据发送到网络,省去了数据在用户空间的中转
- 内存映射(memory-mapped file)和DMA(direct memory access)技术也可以实现零复制。
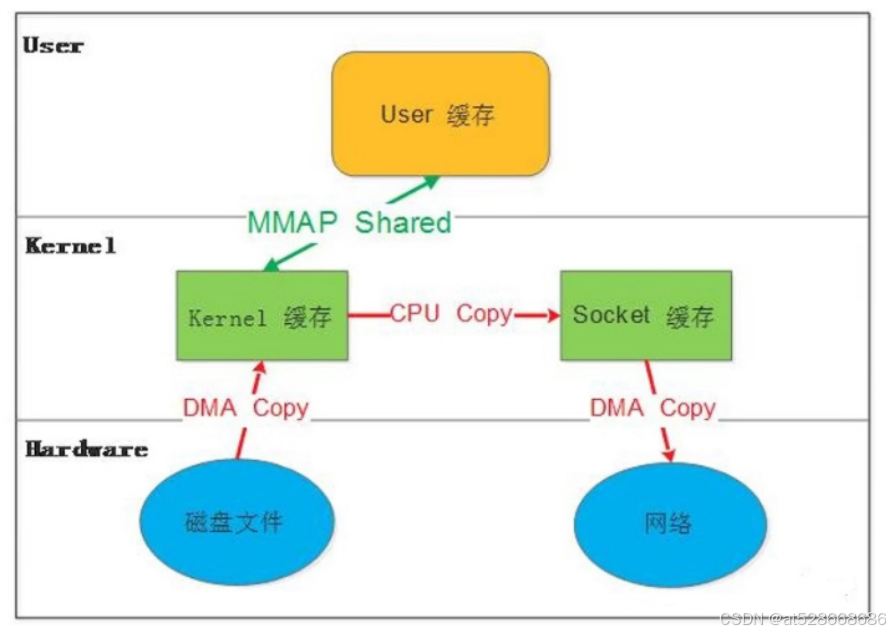
零拷贝就是上述问题的一个解决方案,通过尽量避免拷贝操作来缓解 CPU 的压力。零拷贝并没有真正做到“0”拷贝,它更多是一种思想,很多的零拷贝技术都是基于这个思想去做的优化















 262
262











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









