







原文阅读:【巨人肩膀社区·博客·分享】一文彻底搞懂ZooKeeper选举机制
1. ZooKeeper 集群
ZooKeeper 是一个高性能分布式的开源协调服务,用于构建分布式应用程序和服务。 一个 ZooKeeper 集群通常由多个 ZooKeeper 服务器组成,这些服务器分布在不同的物理节点上。在集群中,每个服务器都知道其他服务器的存在,并且彼此协调工作以提供一致性和可用性。主要原理如下:
•写请求: 在 ZooKeeper 集群中,每个服务器可能处于三种状态之一:Leader、Follower 和 Observer。Leader 负责处理客户端的写请求,并将更新广播给其他服务器;而 Follower 和 Observer 则负责接收更新并复制数据。当一个 ZooKeeper 服务器启动或者 Leader 失效时,集群中的服务器会通过一种选举算法选出新的 Leader,以确保系统的可用性。
•数据同步: ZooKeeper 使用 ZAB(ZooKeeper Atomic Broadcast)协议来确保数据的一致性和可靠性。当 Leader 收到写请求时,它会将请求转发给所有的 Follower,并等待大多数 Follower 确认写操作,然后再将写操作应用到本地状态。这种方式确保了数据的一致性,并且即使在部分服务器故障的情况下,系统仍然可以继续工作。
•读请求: 客户端可以通过连接到任意一个 ZooKeeper 服务器来访问集群,一旦连接建立成功,客户端就可以向任意一个服务器发送读写请求。如果客户端连接的是 Follower 或 Observer,那么它会被重定向到 Leader,并在 Leader 上执行操作。
•Watch 机制: ZooKeeper 提供了 Watch 机制,允许客户端在节点状态发生变化时接收通知。客户端可以在节点上设置 Watch,当节点的状态发生变化时,ZooKeeper 会向客户端发送通知,客户端可以据此执行相应的逻辑。
2. 选举机制
半数机制(过半机制):2n + 1,安装奇数台。
10台服务器:3台。
20台服务器:5台。
100台服务器:11台。
台数多,好处:提高可靠性;坏处:影响通信延时。
说明:
SID:服务器ID。用来唯一标识一台ZooKeeper集群中的机器,每台机器不能重复,和myid一致。
ZXID:事务ID。ZXID是一个事务ID,用来标识一次服务器状态的变更。在某一时刻,集群中的每台机器的ZXID值不一定完全一致,这和ZooKeeper服务器对于客户端“更新请求”的处理逻辑有关。
Epoch:每个Leader任期的代号。没有Leader时同一轮投票过程中的逻辑时钟值是相同的。每投完一次票这个数据就会增加
2.1 第一次启动选举
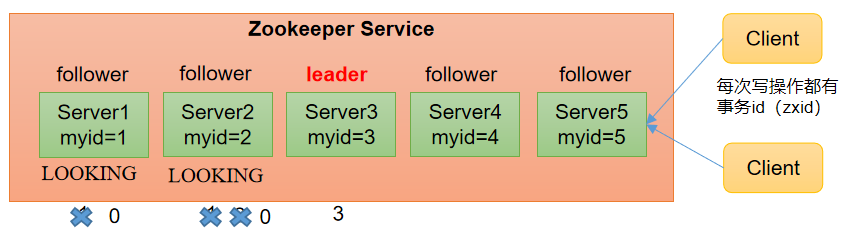
(1)服务器1启动,发起一次选举。服务器1投自己一票。此时服务器1票数一票,不够半数以上(3票),选举无法完成,服务器1状态保持为LOOKING;
(2)服务器2启动,再发起一次选举。服务器1和2分别投自己一票并交换选票信息:此时服务器1发现服务器2的myid比自己目前投票推举的(服务器1)大,更改选票为推举服务器2。此时服务器1票数0票,服务器2票数2票,没有半数以上结果,选举无法完成,服务器1,2状态保持LOOKING
(3)服务器3启动,发起一次选举。此时服务器1和2都会更改选票为服务器3。此次投票结果:服务器1为0票,服务器2为0票,服务器3为3票。此时服务器3的票数已经超过半数,服务器3当选Leader。服务器1,2更改状态为FOLLOWING,服务器3更改状态为LEADING;
(4)服务器4启动,发起一次选举。此时服务器1,2,3已经不是LOOKING状态,不会更改选票信息。交换选票信息结果:服务器3为3票,服务器4为1票。此时服务器4服从多数,更改选票信息为服务器3,并更改状态为FOLLOWING;
(5)服务器5启动,同4一样当小弟。
2.2 非第一次启动
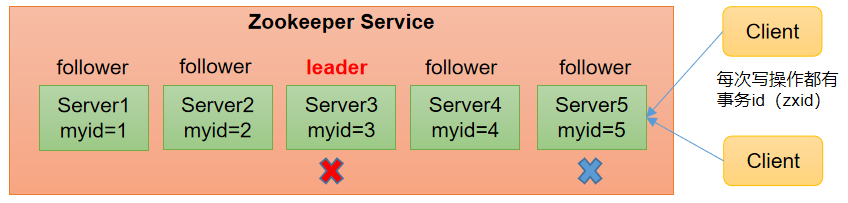
(1)当ZooKeeper集群中的一台服务器出现以下两种情况之一时,就会开始进入Leader选举:
•Leader 故障: 当前的 Leader 出现故障或不可用时,需要选举一个新的 Leader 来接管领导权,以确保系统的正常运行。这种情况下,其他 ZooKeeper 服务器会通过一种选举算法选出新的 Leader。
•新节点加入: 当新的 ZooKeeper 服务器加入集群时,需要选举一个 Leader 来维护集群的状态和数据一致性。新节点会参与选举,并且如果选举成功,它可能成为新的 Leader。
•集群初始化: 在集群初始化阶段,当第一个 ZooKeeper 服务器启动时,它会尝试成为 Leader。如果此时没有其他节点加入集群,那么它就会成为唯一的 Leader。
(2)而当一台机器进入Leader选举流程时,当前集群也可能会处于以下两种状态:
•集群中本来就已经存在一个Leader。机器试图去选举Leader时,会被告知当前服务器的Leader信息,对于该机器来说,仅仅需要和Leader机器建立连接,并进行状态同步即可。
•集群中确实不存在Leader。
假设ZooKeeper由5台服务器组成,SID分别为1、2、3、4、5,ZXID分别为8、8、8、7、7,并且此时SID为3的服务器是Leader。某一时刻,3和5服务器出现故障,因此开始进行Leader选举。
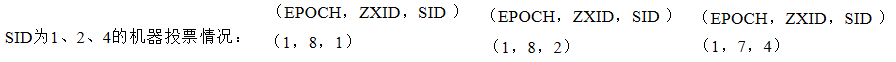
选举Leader规则:
①EPOCH大的直接胜出
②EPOCH相同,事务id大的胜出
③事务id相同,服务器id大的胜出
3. Follower(跟随者)和Candidate(候选者)节点区别
在Zookeeper中,Follower(跟随者)和Candidate(候选者)节点是Zookeeper集群中不同角色的节点,它们在集群中扮演着不同的角色和责任。
Follower节点(跟随者):
•Follower节点是Zookeeper集群中的普通节点,它们的主要责任是参与Leader选举和数据同步。
•Follower节点跟随Leader节点,对客户端的读请求进行处理,并与Leader节点保持数据同步。
•Follower节点只能接收来自Leader节点的消息,并不能主动发起消息。
Candidate节点(候选者):
•Candidate节点是在进行Leader选举时,从Follower节点中选出的临时候选节点。
•候选者节点在Leader选举期间参与投票,如果获得了大多数Follower节点的选票,就会成为新的Leader节点。
•候选者节点会在选举超时时间内等待Follower节点的投票结果,如果在超时时间内没有获得足够的选票,就会重新成为Follower节点。
总的来说,Follower节点是普通节点,负责数据同步和处理客户端的读请求;而Candidate节点是在Leader选举期间临时产生的候选者,参与选举过程,有可能成为新的Leader节点。
















 469
469

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









