






In [8]:
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
import time
In [2]:
temp_data = pd.read_csv("./IMDB-Movie-Data.csv")
data = temp_data["Runtime (Minutes)"].values
num_bins = (data.max()-data.min())//5
x_ticks = range(data.min(),data.max()+5,5)
plt.figure(figsize=(20,8),dpi=80)
plt.hist(data,num_bins)
plt.xticks(x_ticks)
plt.grid(alpha=0.4,linestyle="--")
plt.show()
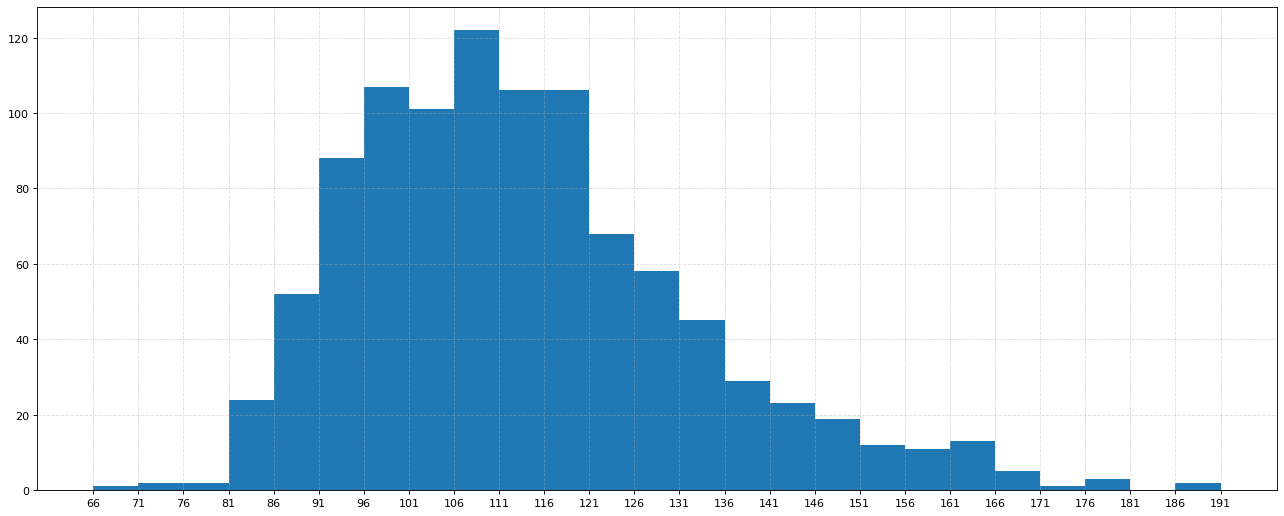
In [3]:
#尝试一下将头尾的数据结合到一起
num_bins_2 = [66] + list(range(81,171,5))+[192] #可以把这里的bins理解为刻度,最后取到192是为了把最大值191包含进去,左闭右开
plt.figure(figsize=(20,8),dpi=80)
plt.hist(data,num_bins_2)
plt.xticks(num_bins_2)
plt.grid(alpha=0.6,linestyle="--")
plt.show()

对字符串进行分裂及统计¶
In [17]:
temp_list = temp_data["Genre"].str.split(",")
genre_set = set([i for j in temp_list for i in j])
#构造全为0的,以类名为列索引的DataFrame
count_frame = pd.DataFrame(np.zeros(shape=(temp_list.shape[0],len(genre_set))),columns=genre_set)
#start = time.process_time()
#for i in range(temp_list.shape[0]):
# count_frame.loc[i,temp_list[i]] = 1
#end = time.process_time()
#print(end-start)
#这种方法性能更高,不需要遍历
#start = time.process_time()
for genre in genre_set:
count_frame.loc[temp_data["Genre"].str.contains(genre),genre] = 1
#end = time.process_time()
#print(end-start)
sum_frame = count_frame.sum()
sum_frame = sum_frame.sort_values()
plt.figure(figsize=(20,8),dpi=80)
plt.bar(sum_frame.index,sum_frame.values,width=0.6,color='orange')
plt.show()

利用groupby进行分组统计¶
In [5]:
read_data = pd.read_csv("./starbucks_store_worldwide.csv")
group_data = read_data.groupby(by="Country")
#group_data为DataFrameGroupBy类型,取出来的groupData为DataFrame类型
#for groupName,groupData in group_data:
# print(groupName,"\n",type(groupData),"\n",groupData,"\n"+"*"*100)
count_group_data = group_data.count()#count_group_data为DataFrame类型
count_group_data = count_group_data["Brand"]#此时Country列已经变为行索引了,随便取出数据完整的一列,series类型
print(count_group_data.head())
In [6]:
#多条件分组
#中国各省份的店铺数量
group_data_1 = read_data.groupby(by=["Country","State/Province"])#条件顺序分先后
count_group_data_1 = group_data_1.count()#复合索引的dataframe
data = count_group_data_1["Brand"]["CN"]
plt.figure(figsize=(20,8),dpi=80)
plt.bar(data.index,data.values,color="orange")
plt.show()
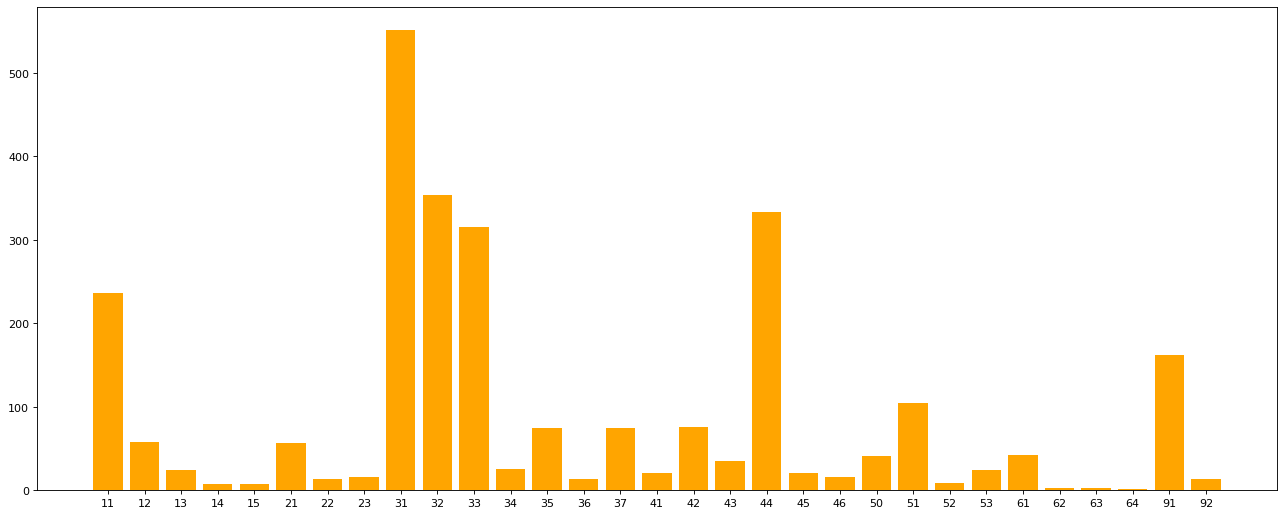
In [7]:
#店铺数量排前十的国家
data = read_data.groupby(by="Country").count()["Brand"].sort_values(ascending=False)[:10]
plt.figure(figsize=(20,8),dpi=80)
plt.bar(data.index,data.values,color="orange",width=0.5)
plt.show()
















 386
386











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









