






一、概念:
1、结构化和非结构化数据
结构化数据:固有的键值对
非结构数据:没有固定的键值对,没有明确的映射关系
所以就可以理解下面这句话:hive是由facebook开源用于解决海量结构化日志的数据统计项目。
2、Hive是基于Hadoop文件系统上的数据仓库架构,它为数据仓库的管理提供了许多功能:数据ETL(抽取、转换和加载)、数据存储管理和大型数据集的查询和分析能力。
RDBMS(关系型数据库)
OLTP(联机事务处理过程):一组事务同时去执行,低延迟,查询为主。
ACID(原子性、一致性、隔离性、持久性)
OLAP(联机分析处理过程):以数据仓库为基础,高延迟,分析为主。
3、Hive定义了类SQL语言-Hive QL(HQL),允许用户进行和SQL相似的操作,它可以将结构化的数据文件映射为一张数据表,并提供简单的SQL查询功能,同时允许开发人员方便的使用MR操作,可以将SQL语言转换为MR任务运行。
二、官网:

三、ETL
E:Extract 数据抽取
T:Transform 数据转换
L:Load数据装载
ETL是将业务系统的数据经过抽取、清洗转换之后,装载到数据仓库的过程。目的是将分散、零乱、标准不统一的数据整合到一起。例如项目日志信息、数据爬虫信息等。就可以提供决策分析依据了。
数据抽取:把不同的数据源数据抓取过来,存到某个地方。
数据清洗:过滤哪些不符合要求的数据或修正数据之后再进行抽取。不完整数据:比如信息缺失。错误数据:日期格式不正确、日期越界、字符串出现空格等重复数据:需要去重等
数据转换:不一致的数据进行转换,比如一个职工有职工号和人事号,学生有身份证号和学号等
常见ETL工具:Oracle的OWB、SQL Server的DTS、SSIS服务、Informatic等等,工具可以快速建立起ETL工程,屏蔽了复杂的编码任务、提高了速度,降低了难度,但是缺少灵活性。
SQL方法优点是灵活,提高了ETL效率,但是编码复杂,对技术要求高。
Hive结合了前面两种的优点。
四、安装Hive
可参考之前安装Hive的文档教程《CentOS6.5-Hadoop2.7.3安装hive-2.1.1》。
也可以进入官网参考
找到Getting Started Guide

选择Running Hive


五、常用命令
安装完成后我们进入hive

在官网上有命令使用的文档

文档内容

我们使用一些命令:
查看数据库show databases;

创建数据库show database 库名

可以查看HDFS上

使用数据库use 库名

创建表的数据类型,我们可以查看官网

就可以找到所有的数据类型了

创建表的时候,如果字段是关键字,则需要加反飘号`(Tab键上面)。
那关键字有哪些?

比如

报错
FAILED: ParseException line 2:0 Failed to recognize predicate 'date'. Failed rule: 'identifier' in column specification

所以我们改为:

但是我们依然不建议使用关键字,尽量去避免,不要使用。我们修改下字段名


这其中有两个小细节:第一CTRL+L清屏 第二从记事本复制表语句的时候前面不要有空格,否则会报错,Display all 528 possibilities? (y or n)。
我们再看数据加载

我们尽量不要使用insert、update、delete,我们可以使用load,所以我们点击load

LOAD DATA [LOCAL] INPATH 'filepath' [OVERWRITE] INTO TABLE tablename [PARTITION (partcol1=val1, partcol2=val2 ...)]
如果加Local表示Linux本地的数据文件
如果不加Local,表示HDFS上的数据文件
我们在Linux上准备一个数据文件

我们先加载数据
load data local inpath '/data/hivetest/stu_info_local' into table gjz_error;

我们查看数据,数据全部是NULL,因为hive默认的分隔符是^A,也就是001,而我们的分隔符是一个tab键。

我们把分隔符改为^A(先按Ctrl+V,再按Ctrl+A)

然后我们重新导入数据,发现数据已经导入了


我们再将数据文件上传到HDFS上


创建数据表


我们导入数据


此时我们查看HDFS上,发现原来的数据也不在了

但是数据已经加载到hive了
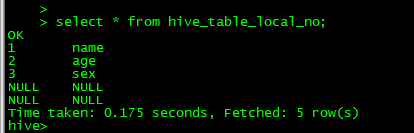
另外数据文件已经在新的目录下了

所以不加local是剪切移动的过程,而加local是复制的过程。
前面的问题:如果我们的数据不是默认的分隔符,即不是^A该怎么办呢?
我们准备文件

准备数据,将数据分隔符改为\t

我们看官网上这个部分
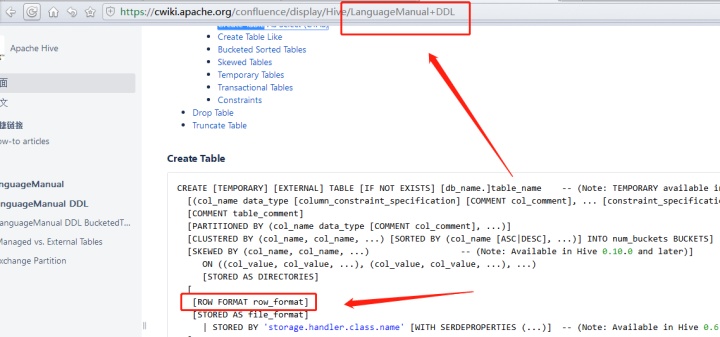
我们重新建表,加入数据
create table hive_table_local_format(
id int,
name string
)row format delimited fields terminated by '\t'

Hive在HDFS文件系统上的结构
我们在test库下面创建表

导入数据

我们查看
/user/hive/warehouse/test.db/hive_table_local_format

我们可以得到

元数据库开始是derby,只能开启一个客户端,再开启一个会话启动会报错,所以我们改变了元数据库为Mysql,其中可选的是:

我们创建一个数据库
create database stu_test

使用数据库并创建表

我们准备一个论坛数据文件

将文件上传到HDFS上
我们先创建两个目录

我们把数据上传



我们加载数据到hive中
在加载之前我们可以看到,我们看到stu_test中没有数据

我们加载数据


我们再加载第二个数据


注:我们会发现,自动重命名了。
我们查看我们表的信息:
- show create table
- desc [extended][formatted] table
- 元数据库

或者

或者

或者

我们查看Tals

修改表名
官网


我们修改一个表试一下

给表添加一个列


alter table table_name add columns (age int);

添加注释也在这个部分

清除数据
Truncate table table_name

注意不会删除元数据

Hive的日志文件配置文件

目录修改为hive.log.dir=/opt/bigdata/hive/logs

我们可以在hive-site.xml.template找到下面两个属性,这两个属性可以帮助我们在日志中显示数据和列名,将属性添加到hive-site.xml中
<property>
<name>hive.cli.print.current.db</name>
<value>false</value>
<description>Whether to include the current database in the Hive prompt.</description>
</property>
<property>
<name>hive.cli.print.header</name>
<value>false</value>
<description>Whether to print the names of the columns in query output.</description>
</property>

我们添加到配置中,下次重启进入就可以看到日志了

一些常用的命令
官网的位置

就可以看到命令了

比如:
quit exit 退出客户端
set 临时设置属性 可以参考Mysql中设置编码等方式去理解。另外set也可以用户查看参数的属性。

显示所有函数show functions;

我们可以查询函数的使用比如max
Desc function max;

Desc function extended case;

Hive可以用java写成函数,使用add jar就可以添加使用

也可以将python脚本添加进来,使用add file

!感叹号的方式可以查看Linux上的文件

dfs方式可以查看HDFS上的文件















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









